What is Decision Trees in Machine Learning?

Overview
A decision tree is an essential and easy-to-understand supervised machine learning algorithm. In a decision tree, the training data is continually divided based on a particular parameter. There are two entities in decision trees in AI: decision nodes and leaves. The leaves specify the decisions or the outcomes, and the decision nodes determine the threshold for data split. In this article, we will delve into decision trees in machine learning.
Introduction
Decision trees in AI is a supervised machine learning algorithm that categorizes or predicts based on how a previous set of questions was answered. A model is a form of supervised learning, which means that the model is trained and tested on a dataset that contains the desired categorization based on a set of variables. The decision tree may only sometimes provide a clear answer or decision. Instead, it may present options to a data scientist for making an informed decision. Decision trees in AI imitate human thinking, so generally, the results are easily interpretable and explainable.
Different Types of The Decision Tree in Machine Learning
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Classification Tree
What is a classification tree?
Classification problems are the most commonly used form of decision trees in AI. Classification is a supervised machine learning problem in which the model is trained to classify whether a data sample belongs to a known object class. Models are trained to assign known class labels to processed data. The model learns the classes through processing labeled training data in the training part of the machine learning lifecycle.
A model must understand the features that categorize a data point into different class labels to solve a classification problem. Examples of classification are the classification of documents, image recognition software, or email spam detection.
A classification tree is a way of structuring a model to classify objects or data. The leaves or endpoints of the branches in a classification tree are the class labels, the point at which the branches stop splitting. The classification tree is generated incrementally, with the overall dataset being broken down into smaller subsets. It is used when the target variables are discrete or categorical, with branching usually happening through binary partitioning. For example, each node may branch on a yes or no answer. Classification trees are used when the target variable is categorical or can be given a specific category, such as yes or no. The endpoint of each branch is one category.
Regression Tree
Regression is also a supervised machine learning problem but is designed to forecast or predict continuous values, such as predicting house prices or stock price changes. In addition, it is a technique to train a model to understand the relationship between independent variables and an outcome. Regression models are also trained on labeled training data from the supervised class of machine learning models.
Regression models are trained to learn the relationship between output and input data. Once the relationship is learned, the model can forecast outcomes from unseen input data. The use cases for these models include predicting future trends in a range of settings and filling gaps in historical data. Examples of a regression model may consist of forecasting house prices, future retail sales, or portfolio performance of stocks in finance. Decision trees in AI that deal with continuous values are called regression trees. Similar to a classification tree, the dataset is incrementally broken into smaller subsets. The regression tree will create dense or sparse data clusters to which new and unseen data points can be applied. It’s worth noting that regression trees can be less accurate than other techniques for predicting continuous numerical outputs.
Popular Attribute Selection Measures
Entropy, also called Shannon Entropy, is denoted by H(S) for a finite set S and measures the amount of uncertainty or randomness in data.
Intuitively, it tells us about the predictability of a particular event. For example, consider a coin toss whose probability of heads is 0.5 and the probability of tails is 0.5. Here the Entropy is the highest possible since there’s no way of determining the outcome. Alternatively, consider a coin with heads on both sides, the Entropy of such an event can be predicted perfectly since we know beforehand that it’ll always be headed. In other words, this event has no randomness; hence its Entropy is zero. In particular, lower values imply less uncertainty, while higher values imply high uncertainty.
Information Gain
Information gain is called Kullback-Leibler divergence, denoted by IG(S, A) for a set S is the effective change in Entropy after deciding on a particular attribute A. It measures the relative change in Entropy concerning the independent variables.
Where, IG(S, A) is the information gained by applying feature A. H(S) is the Entropy of the entire set. At the same time, the second term calculates the Entropy after applying the feature A, where P(x) is the probability of event x.
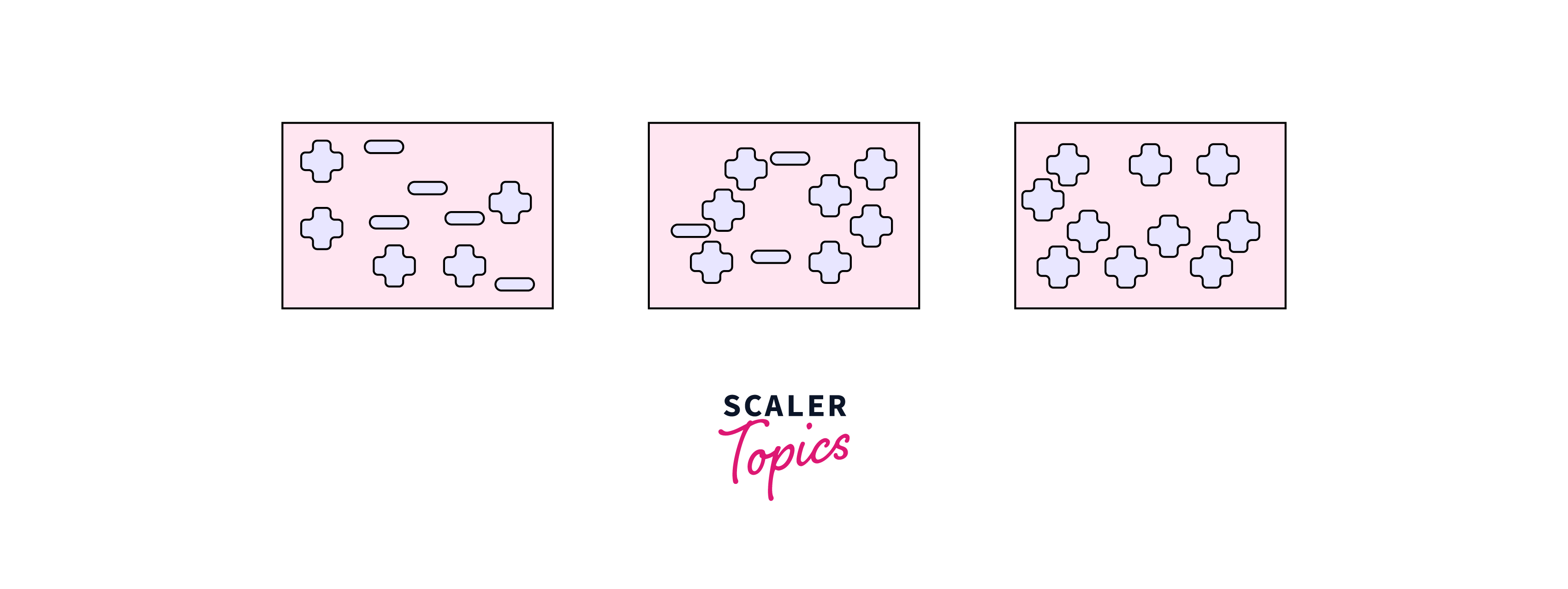
In the figure above, we only have data from one class for node three. On the other hand, in node 1, we need more information than the other nodes to describe a decision. So, by the above, the information gain in node 1 is higher. The most polluted nodes require more information to convey.
Turn Learning into Career Growth
Gini Index
Gini Index is a metric to measure how often a randomly chosen element would be incorrectly identified. It means an attribute with a lower Gini index should be preferred. Sklearn supports “Gini” criteria for Gini Index, and it takes the “Gini” value by default. The Formula for the calculation of the Gini Index is given below:
where, is the percentage of class in a node.
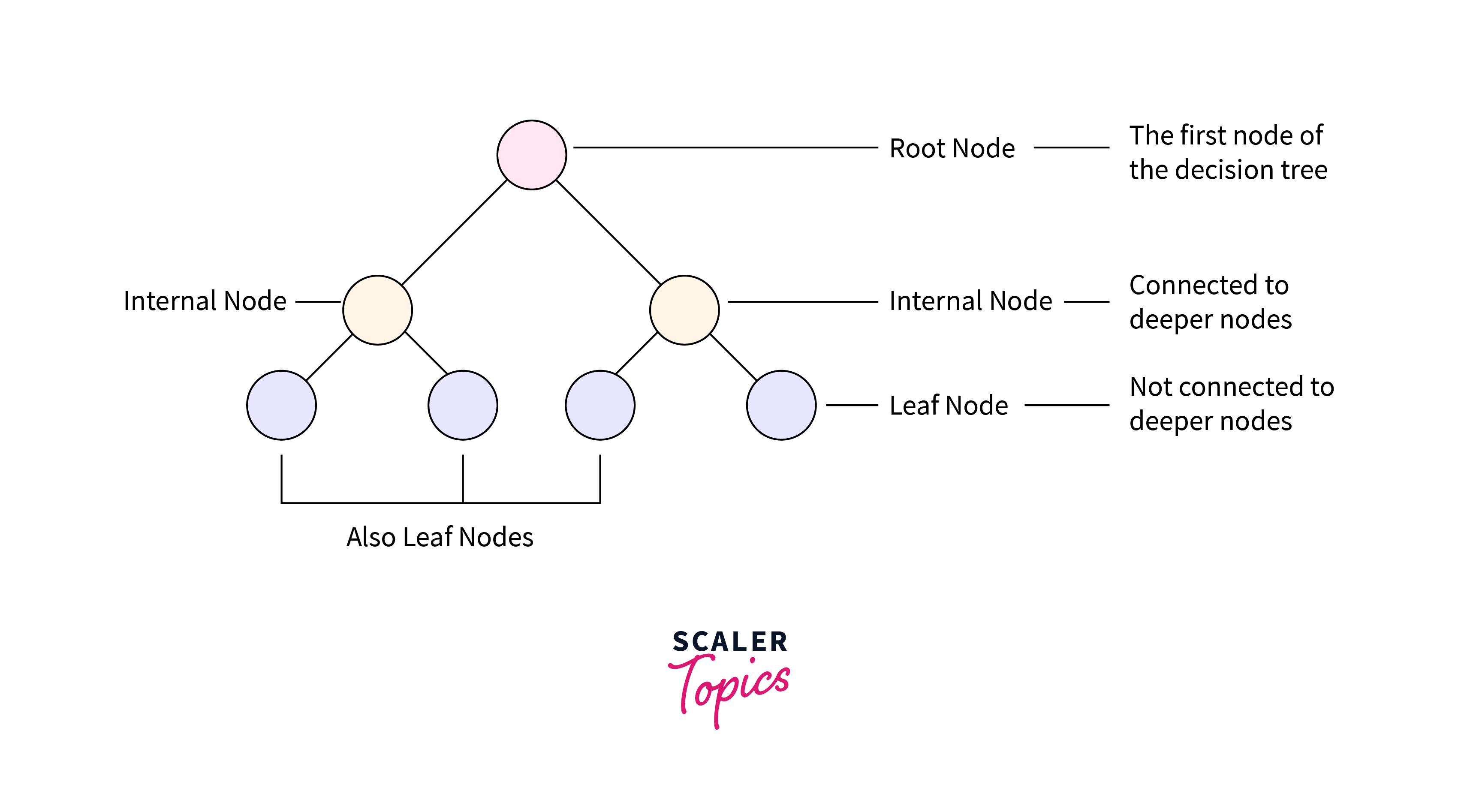
Key Terms Of A Decision Tree
Following are some critical hyper-parameters of a decision tree:
- Root node: The base or starting point of the decision tree.
- Splitting: The process of dividing a node into multiple sub-nodes.
- Decision node: When a sub-node is further split into additional sub-nodes.
- Leaf node: When a sub-node does not further split into additional sub-nodes, it represents possible outcomes.
- Pruning: The process of removing sub-nodes of a decision tree.
- Branch: A subsection of the decision tree consisting of multiple nodes.
How Can An Algorithm Be Represented As A Tree
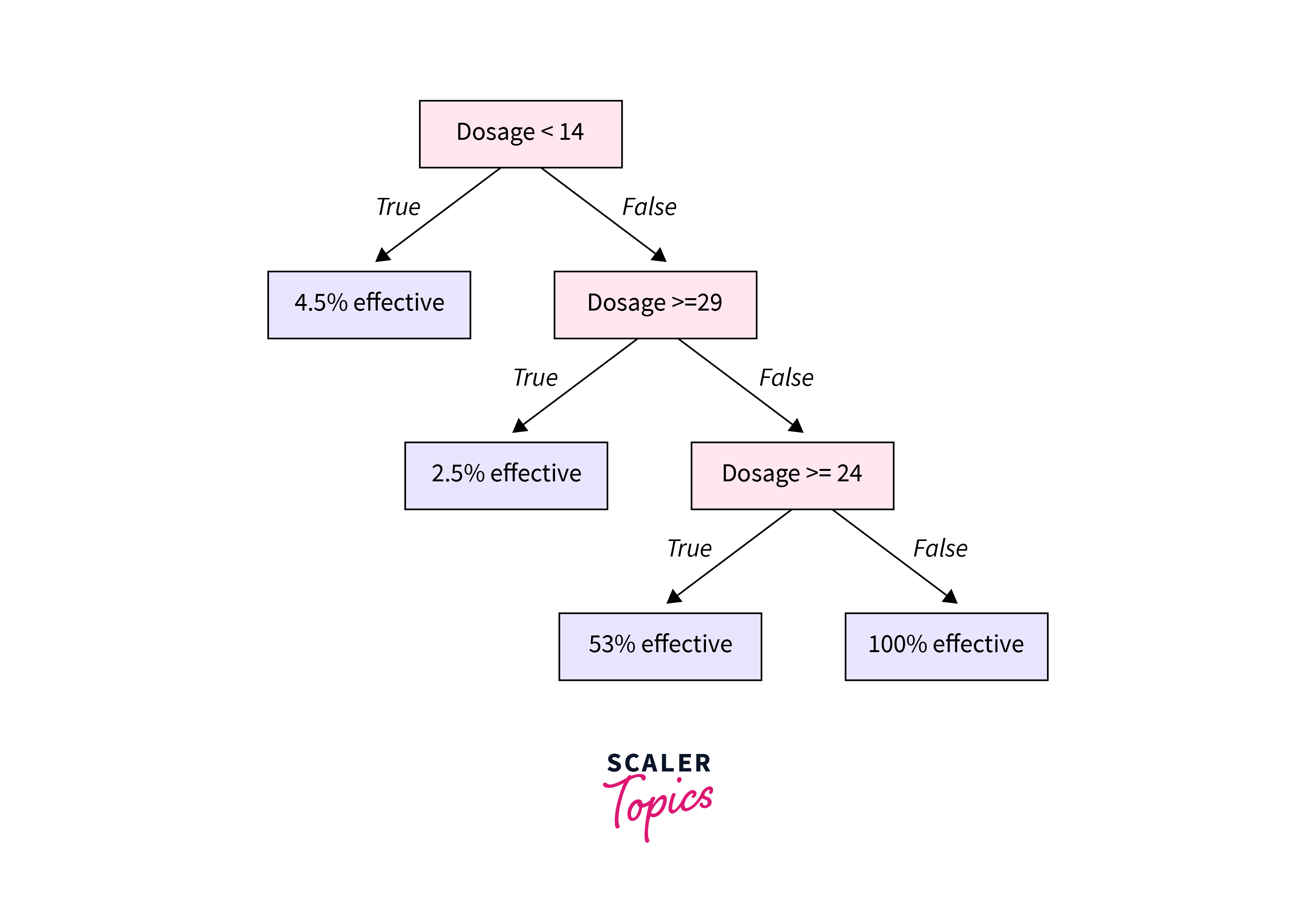
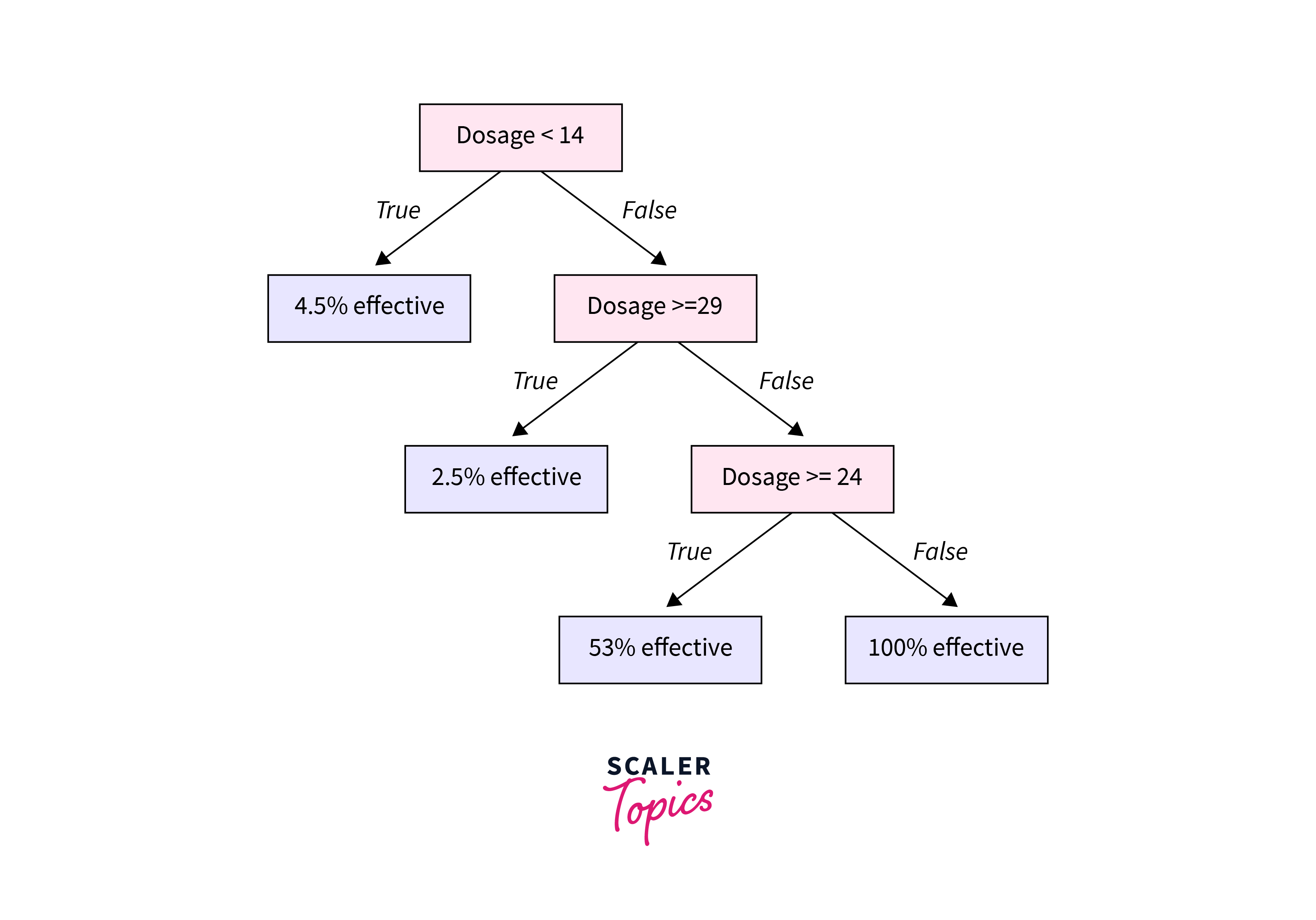
A decision tree resembles a tree. The base of the tree is the root node. From the root node flows a series of decision nodes that depict decisions to be made. The decision nodes are leaf nodes that represent the consequences of those decisions. Each decision node represents a question or split point, and the leaf nodes that stem from a decision node represent the possible answers. Leaf nodes sprout from decision nodes like a leaf sprout on a tree branch. This is why we call each subsection of a decision tree a “branch.” Let’s take a look at an example of this. You’re a golfer and a consistent one at that. On any given day, you want to predict your score in two buckets: below par or over par.
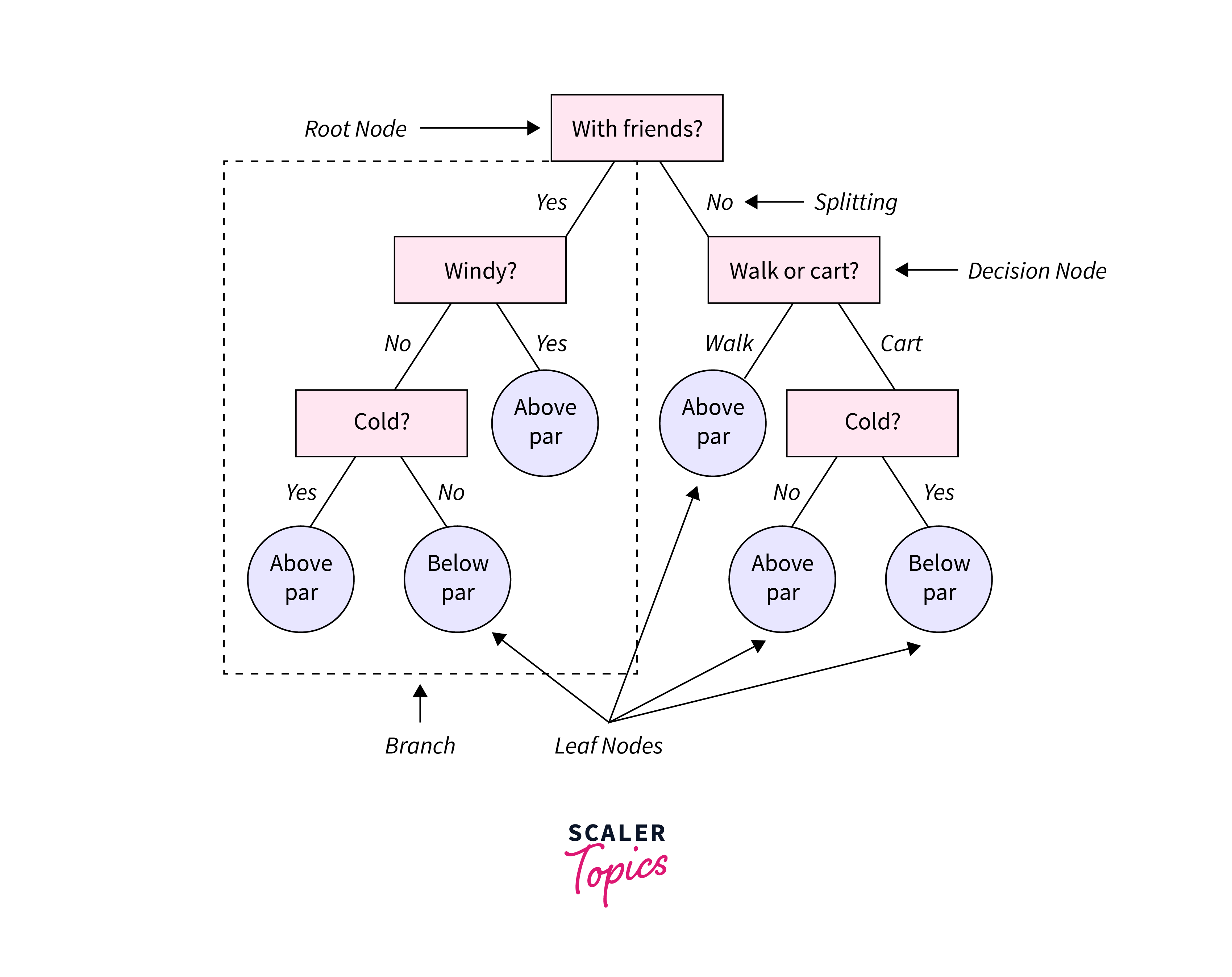
Decision Tree Variables and Design:
In the golf example, each outcome is independent because it does not depend on the outcome of the previous coin toss. On the other hand, dependent variables are influenced by events before them. Building decision trees in AI involves construction, in which you select the attributes and conditions that produce the tree. Then, the tree is pruned to remove irrelevant branches that can inhibit accuracy. Pruning involves spotting outliers, data points far outside the norm, that could throw off the calculations by giving too much weight to rare occurrences in the data. The temperature might not be critical when it comes to your golf score, or there was a day when you scored poorly that threw off your decision tree. As you explore the data for your decision tree, you can prune specific outliers like your one bad day on the course. You can also prune entire decision nodes, like temperature, that may be irrelevant to classifying your data. Well-designed decision trees present data with few nodes and branches. You can draw a simple decision tree by hand on a piece of paper or a whiteboard. More complex problems, however, require the use of decision tree software.
When To Stop Growing A Tree?
A dataset generally has multiple features, and therefore, while growing a decision tree, at each level, we get a large number of splits, which in turn gives a large tree. Such trees can turn out to be very complex and might lead to overfitting. So, it is important to decide when to stop growing the tree. One way of doing this is to limit the number of training inputs to be used on each leaf. For example, we can use a minimum of 10 passengers to reach a decision (satisfactory or unsatisfactory travel) and ignore any leaf that uses less than ten passengers. Another way is to set the maximum depth of the decision tree model. Maximum depth refers to the longest path from a root to a leaf.
Pruning
Pruning is a method that is used to prevent the decision tree in AI from overfitting and improve its accuracy and generalization power. It involves removing the branches of the decision tree that uses features with low importance. In this manner, we diminish the complexity of the tree and prevent it from overfitting.
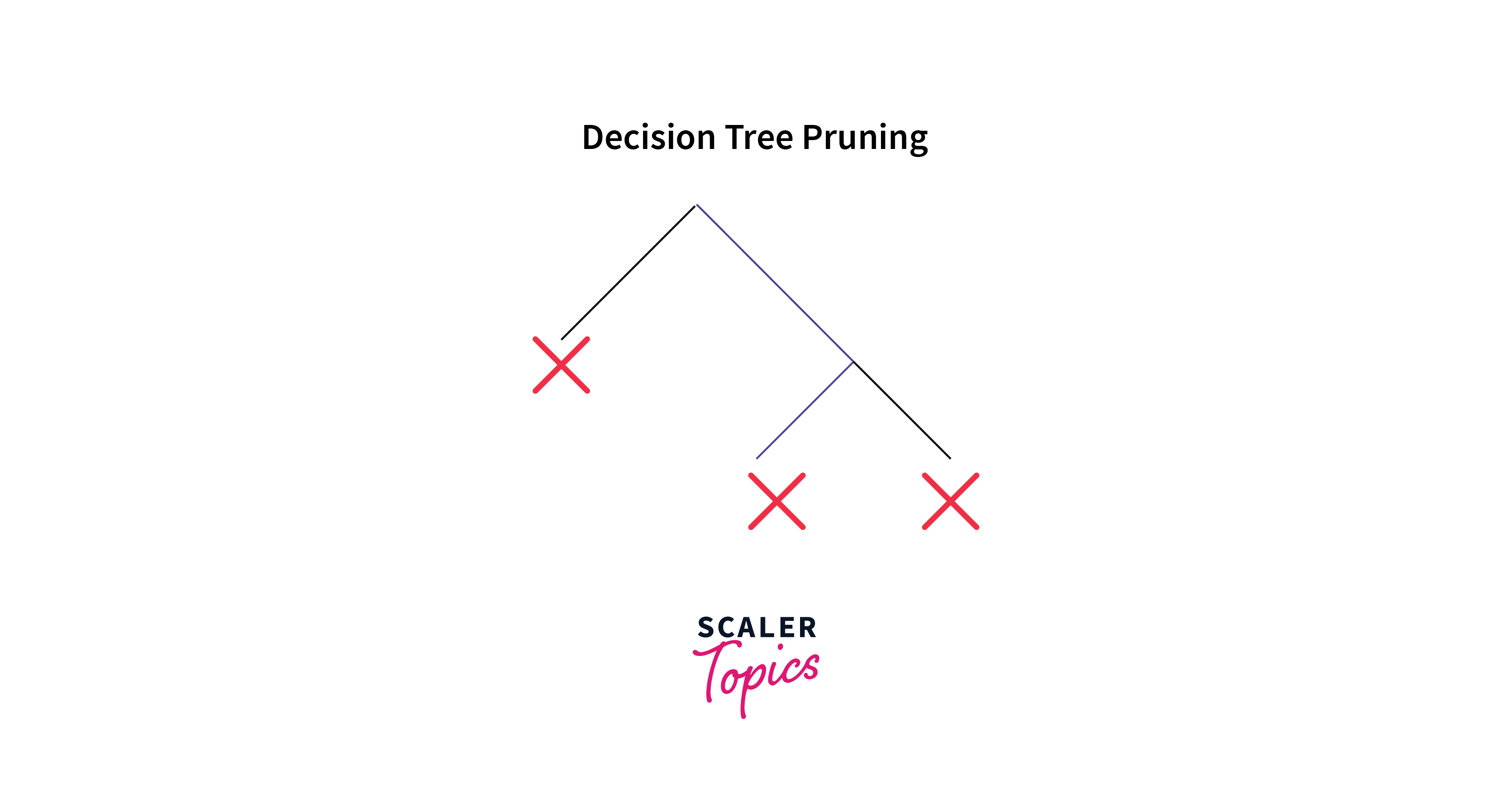
Pruning can start at either the root or the leaves. The simplest pruning method starts at leaves and removes each node with the most popular class in that leaf if it doesn't deteriorate accuracy. It is also termed reduced error pruning. However, there are also more sophisticated pruning methods. One is the cost complexity pruning, where a learning parameter (alpha) is used to determine whether nodes can be removed based on the sub-tree size. This is also known as the weakest link pruning.
Applications of Decision Trees
Decision trees in AI are widely used for supervised machine learning applications, especially classification. Decision trees in AI help categorize results where attributes can be sorted against a known criterion or a combination of criteria to determine the final category. In addition, decision trees are used to map. Following are some applications of decision trees.
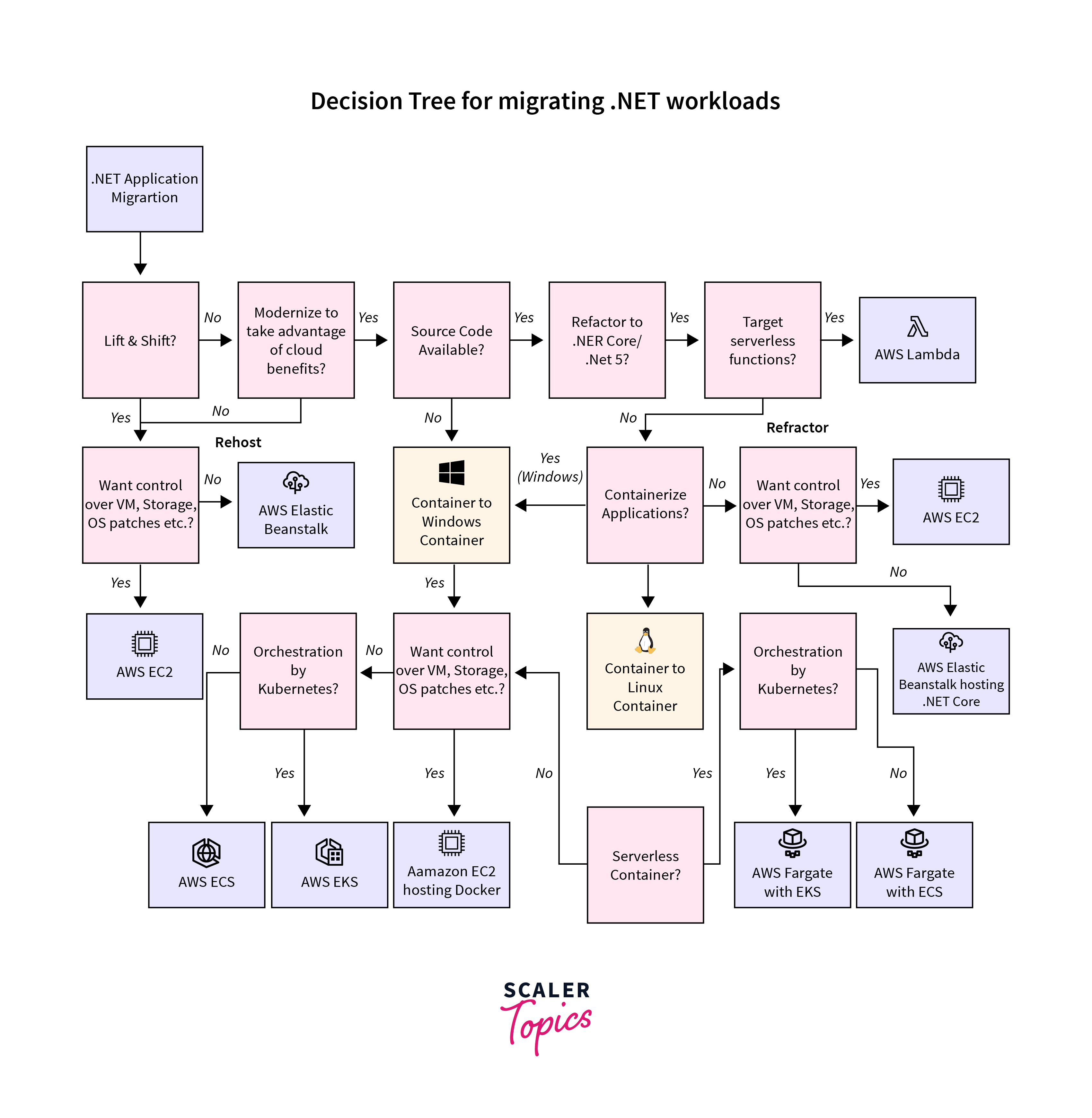
Mitigating .NET Workloads
A decision tree can is used to find the recommended migration or modernization path for .NET legacy applications based on different requirements. Rather than an “all-in” approach, one can also consider making this decision on an application-by-application evaluation. It will help in cost control and optimization quicker.
Customer Recommendation Engines
Customers buying certain products or categories are generally inclined to buy something similar to those they have already bought or viewed. Recommendation engines are important in that context. For example, they can be used to push the sale of mobile screen guards after someone has purchased a mobile. Recommendation engines can be structured using decision trees, using the decisions taken by customers over time and creating nodes based on those decisions.
Identifying Risk Factors for Depression
A study conducted in 2009 in Australia tracked a cohort of over 6,000 people and whether or not they had a major depressive disorder over four years. The researchers took inputs like tobacco use, alcohol use, employment status, etc., to create a decision tree that can be used to predict the risk of a major depressive disorder. Medical decisions and diagnoses rely on multiple inputs to understand a patient and recommend the best way to treat them based on a conjunctive decision from these inputs. Therefore, a decision tree application like this can also be a valuable tool to healthcare providers when assessing patients for multiple other healthcare use cases.
Conclusion
- Decision tree in AI is an important and simple algorithm.
- In this article, we have covered different decision trees, how to construct a tree, when to stop a tree, and Different types of hyper-parameters in a decision tree.
- The article concludes after discussing different applications of a decision tree in AI.