Node.Clustering in Node JS
Overview
Node.js has become quite popular in recent years. It has also been able to attract big companies like LinkedIn, Netflix and eBay. This shows its architectural power and efficiency. Scaling an application's performance is an important step in supporting the growing number of clients. In Node.js, Clustering is a technique that allows the utilization of hardware based on a multicore processor.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Introduction
Node.js, by default, follows the single threaded event loop based architecture. Even if the computer has more than one CPU core, Node.js does not use all of them by default. It only uses one CPU core for the main thread that handles the event loop. So, for example, if you have a four-core system, Node will only use one of them by default.
Suppose two requests come at the same time; in that case, the event loop will be able to take on only one of them, and the other one will go to the queue. Hence to handle a large number of users at the same time one core isn’t sufficient. To handle such a heavy load, we need to launch a cluster of such Node.js processes and hence make use of multiple cores.
Node.js comes bundled up with a cluster module. The cluster module permits the creation of child processes, that are copies of your program operating concurrently on the same server port. Each child process possesses an event loop, V8 instance and memory. There is a parent process routing traffic to these child processes. To communicate with the parent processes, the child processes employ interprocess communication.
Hence while using the cluster module, you will have four copies of your program in case of a 4-core machine. This will allow you to handle four times the normal traffic at the same speed. Therefore clustering is capable of giving a performance boost to your Node.js application.
The Need of Clustering
Node.js has single threaded event loop architecture. This means that there is one single thread that receives all the requests. This does not mean that your Node.js application cannot make use of multiple cores. To make use of multiple cores, a cluster of processes is started to handle the load. The cluster module is required to set up a cluster and make use of the numerous processors.
Scalability is needed when an application’s clients grow. The application must be updated so as to support a large number of users and provide a good experience to all of them. Clustering acts as a load-balancing and parallel processing service.
The performance of the application gets a major boost when the load is shared among the multiple cores of the application. Most systems these days feature multiple cores. Hence the cluster module must be used to get the best performance from the application.






How does the Node.js cluster module work?
Node.js cluster module can be said to provide the load balancing server. The load of the application is distributed by the parent process to the child processes that are running on a shared port. Suppose a large synchronous operation is being handled. The event loop takes up the synchronous part of all the processes. This will make the other requests go to the queue. This will take a lot of time to process those requests. Hence the multiple processes can reduce the wait time and improve the performance.
When multiple processes are running, then there are other processes that can work on the incoming requests if one process is engaged in a heavy CPU-intensive process. This will also ensure the utilization of multiple cores. Thus, the cluster module enables load sharing among the child processes and prevents the application from stopping.
There is a parent or a master process available that manages the load to the child processes. The master process listens to a process. There are two ways in which the traffic is routed. One is based on the round-robin technique. In this, the load is equally shared among the child processes. The second method involves the sending of work to the interested child processes.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Advantages of using clustering in Node.js
There are a number of different advantages in using clusters in Node.js :
- Because the Node.js programme may use all of the CPU resources available (most PCs nowadays have a multi-core CPU), the processing burden will be distributed to these cores. As load balancing is done and all CPU cores are fully utilised. Multiple single threaded processes will be created, and this will improve the throughput of the system (measured in requests per second).
- As there are many processes ready to receive incoming requests, allowing multiple requests to be processed concurrently. Even if there are blocking or lengthy jobs, only one worker is impacted, and other workers can continue to handle other requests. Until the blocking process is completed, your Node.js application will not stop responding as it would have previously.
- Having a number of worker processes allows the software to be updated with little or no downtime. They may be recycled/restarted one at a time because there are many workers. This implies that one child process can smoothly replace another, and there will never be a moment when all the workers are inactive. As you can see, this quickly enhances an update's speed and efficiency.
- If a launched process dies unexpectedly or on purpose, a new process can be started immediately as a replacement for the process that died with no need of manual interruption or any delay.
- The use of numerous cores for execution improves application performance of the application.
- The wastage of hardware resource is drastically reduced by the utilization of the full potential of the processor.
- There is no need to create an extra dependency because all work is managed by the NodeJs module.
Cluster Properties and Methods
| Method | Description |
|---|---|
| fork() | Creates a new worker, from a master |
| settings | Returns an object containing the cluster's settings |
| disconnect() | Disconnects all workers |
| exitedAfterDisconnect | Returns true if a worker was exited after disconnect, or the kill method |
| isMaster | Returns true if the current process is master, otherwise false |
| id | A unique id for a worker |
| kill() | Kills the current worker |
| isConnected | Returns true if the worker is connected to its master, otherwise false |
| worker | Returns the current worker object |
| isWorker | Returns true if the current process is worker, otherwise false |
| workers | Returns all workers of a master |
| isDead | Returns true if the worker's process is dead, otherwise false |
| process | Returns the global Child Process |
| schedulingPolicy | Sets or gets the schedulingPolicy |
| send() | sends a message to a master or a worker |
| setupMaster() | Changes the settings of a cluster |
Turn Learning into Career Growth
Example
Now let us have a look at how you can use the cluster module to improve the performance of our application. We will create two applications, one with clustering and one without clustering.
Before starting to create your application, check whether your system has Node.js installed.
Setting up a simple NodeJS Express Server :
Make a new directory, clustering-node.js with the help of the below command :
Now switch to the newly created directory by the following command :
Now to initialise a Node.js project execute the following command in the terminal :
A series of questions will be asked regarding the project. After answering the questions, you will notice a package.json file in the directory containing all the information you entered.
Now install express using node package manager
After successful completion express and its version will be shown in the dependencies section of the package.json file.
Now create a file called without-clustering.js. In this file you will write the code for the application without the use of clustering. Now your folder structure will be as follows :
Now write the following code in the without-clustering.js file :
In the above code snippet, firstly, the express framework has been imported, and an instance of express has been created. The instance is made to run on PORT 3000.
Two HTTP GET endpoints have been created for the / and nocluster paths. The GET API endpointat /nocluster path has a complex operation that is performed at every request. A loop with 9^7 iterations which is equal to4782969(a large value).
The pow() operation is performed in every iteration, and the result is added every time to a result variable. The result variable is logged and also sent in the response.
The time between the start and the completion of the complex operation is also logged out. The complex operation was designed to simulate a blocking and CPU-intensive operation.
Now run the express application by the following command in the terminal :
The terminal will give output similar to the following :
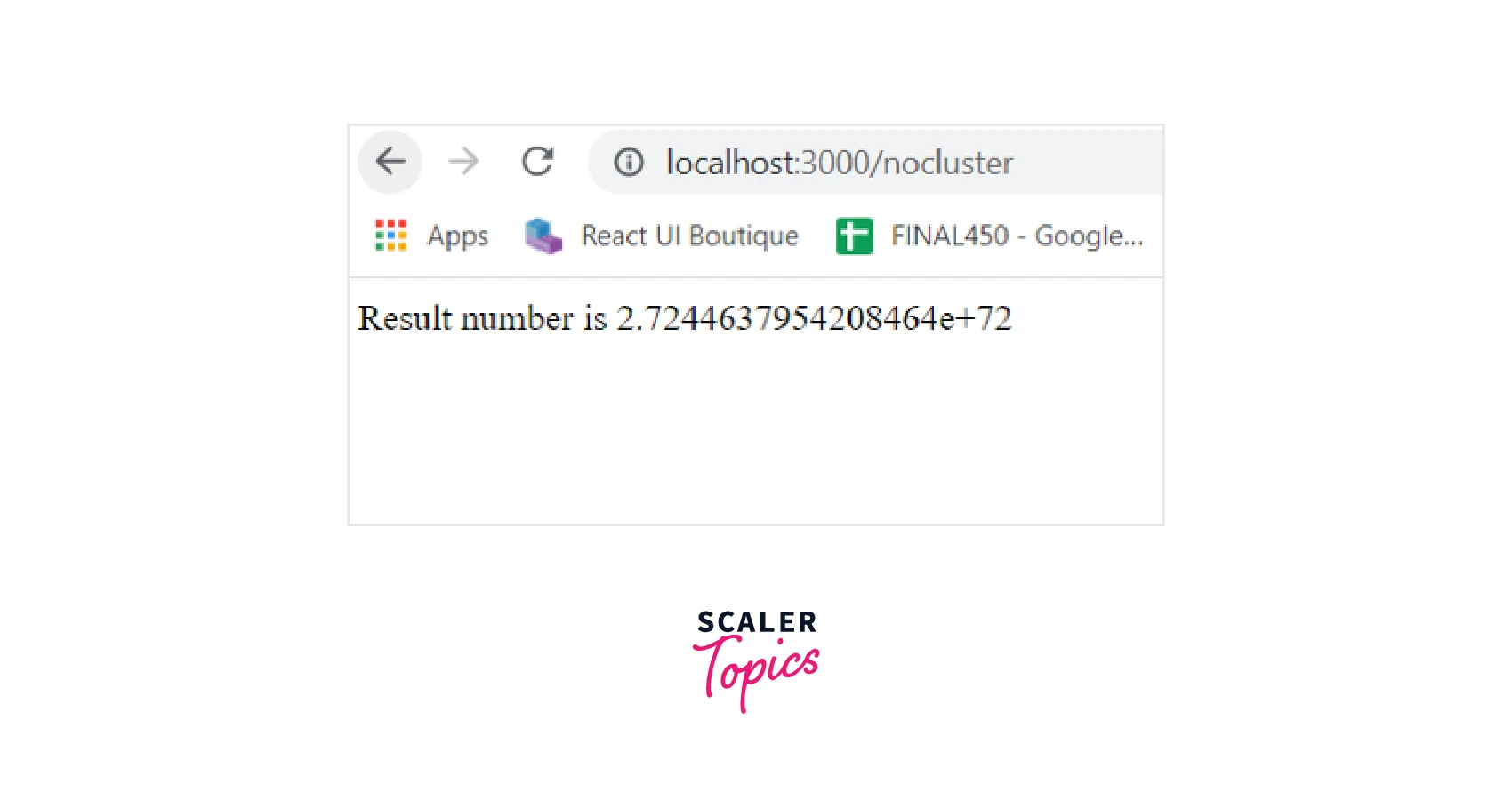
Now open http://localhost:3000/nocluster in any browser. The browser will show the following response :
The terminal of the Node server will show the following response :
Adding Clustering to the NodeJS Express Server :
Now create a with-clustering.js file and write the following code in the file to create a cluster :
In the above code snippet, the cluster module has been imported. The require(‘os’).cpus().length is used to get the number of CPU cores available on the system. Firstly it is checked whether the cluster process is a master or a worker. If the process is a master process, then child processes equal to the number of cores are forked. If it is a worker process, then it will call the start() function.
The start() function contains a copy of the express application that we had created without clustering. In the /cluster GET endpoint, the blocking operation has been defined.
The program will perform the same computation as before, but this time creation of child processes will be done, and they all will run on the same port 3001. The fork() method is used to create child processes.
The fork() technique is used to start the worker processes. A ChildProcess object is returned that has an integrated data transmission connection for message passing between the child and its parent.
The express application has been made to run on the PORT 3001. Now run the code by the following command in the terminal :
A similar output will appear depending on the number of cores in your machine :
Note - One of the best practices is not to generate more workers than the number of available logical cores since this would result in scheduling overhead.
Now open http://localhost:3001/cluster in any browser. The browser will show the response the same as before.
In the terminal, you will see a response like this :
As eight cores were present hence eight child processes, each on port 3001, were created. The clustered version will be able to handle more number of concurrent requests, and the overall processing time will be less.
Node.js is all about speed and efficiency. Enroll in our Free Node JS certification course and discover how to build lightning-fast applications that impress users.
Conclusion
- Node.js, by default, follows the single threaded event loop based architecture.
- Node.js comes bundled up with a cluster module. The cluster module permits the creation of child processes.
- Each child process is a copy of your program and possesses an event loop, V8 instance and memory.
- Clustering acts as a load-balancing and parallel processing service.
- When multiple processes are running then there are other processes that can work on the incoming requests, if one process is engaged in a heavy CPU-intensive process.
- The performance of the application gets a major boost when the load is shared among the multiple cores of the application.
- There is a parent or a master process available that manages the load by routing traffic toto the child processes.
- There are two ways in which the traffic is routed. One is based on the round-robin technique. The other involves the sending of work to the interested child processes.