HTTP Basics in NodeJs
Overview
Today sharing information and communicating with others has become so easy, all thanks to the world wide web (www). The Hypertext Transfer Protocol is a fundamental element of www . It is the medium with which all the elements of the www communicate and hence facilitates the sharing of data. Hence HTTP basics have a big role in making data accessible to all internet users. HTTP is one of the most popular application protocols, and hence its knowledge is very important to understand the basics of networking.
Introduction
HTTP, known as the hypertext transfer protocol, is the protocol used by the world wide web to facilitate the communication of data. It is based on request and response. In other words, it acts as the language that the client and server use to communicate with each other. Every time we open a link or click a button on any website, our browser creates an HTTP request. This request is sent to the server. The server answers with a response to the client which is displayed by the browser in some form (like an image or video). This is the basic request-response cycle. After the cycle has ended, the client disconnects the connection.
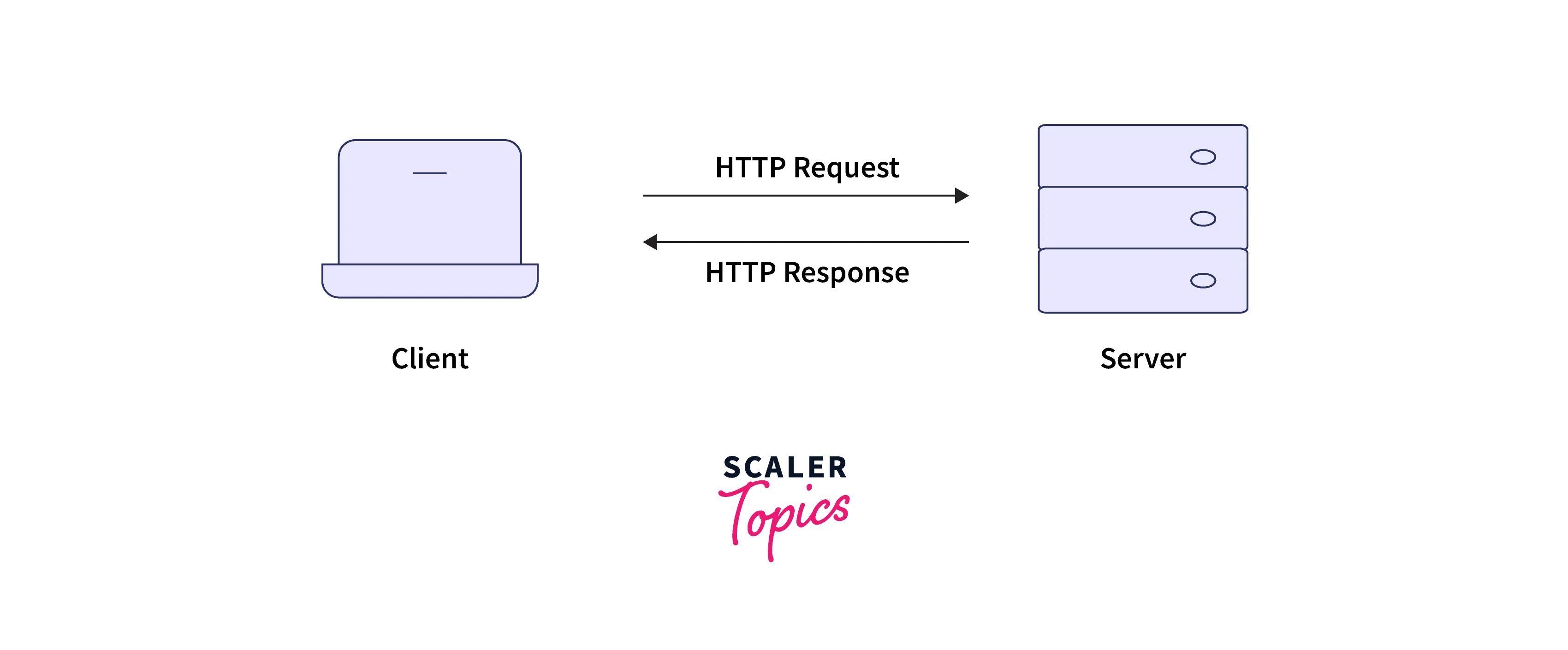
Hence HTTP is a connectionless protocol. HTTP basics define the set of rules for sharing files videos, text, sound, images, and other multimedia files - over the web. HTTP is a stateless and generic protocol. Being stateless means that the current request has no information about the previous requests. HTTP is generic because it can be used for other purposes by the extension of its components.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Brief History of HTTP
The HTTP protocol, developed by Tim Berners Lee and his team at CERN, has undergone several evolutions since 1989.
HTTP 0.9
The HTTP’s basics first version, later named HTTP 0.9, was extremely simple.
It had the following features :
- Request - Response protocol
- It was ASCII based. The request was a character string terminated by a carriage return.
- Designed to transfer hypertext documents
- The connection is closed after every request.
Here is a short example of the request and response of HTTP 0.9 :
Request:
GET/index.html
Response:
After this connection is closed.
HTTP/1.0
After the development of the web browser, the HTTP basics have also evolved to support richer metadata, content types, etc.
The features of HTTP 1.0 are :
- Requests can have multiple newline-separated headers.
- The response object has a status code at its start.
- The response object has newline-separated headers.
- The response object is no longer limited to only hypertext.
- The connection is closed after every request.
Request:
GET /index.html HTTP/1.0
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/533.2 (KHTML, like Gecko) Chrome/6.0
Response: 200 OK
Date: Wed, 21 Sep 2022 16:03:34 GMT
Server : gws
Content-Type: text/html






HTTP/1.1
HTTP 1.1 was the first standardized version of HTTP. It came with a lot of optimizations.
The HTTP 1.1 has the following features :
- The request has encoding, charset, and cookie metadata.
- A connection can be reused; this saves time.
- Pipelining was added. Now a request can be sent before the response of the previous has been received.
- Chunked responses and caching mechanisms were introduced.
- Multiple domains can be hosted on single IP.
Request
GET /index.html HTTP/1.0
Accept-Encoding: gzip, deflate, br
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/533.2 (KHTML, like Gecko) Chrome/6.0
Connection: Keep-Alive
Response:
HTTP/2
With the increase in complexity of web pages over time, the overhead for HTTP basics has increased. Google implemented a protocol SPDY to overcome the problem of web page load latency by increasing the content's responsiveness and using compression, multiplexing, and prioritization.
The HTTP 2 has the following improvements over HTTP 1.1 :
- It is a binary protocol rather than a text protocol. This helps in optimizations.
- Parallel requests can be made without blocking the messages behind (known as multiplexing).
- Compression of headers is done to reduce duplication of data.
- The server can populate the client cache with the help of server push.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
How HTTP Works?
Let's understand this process by taking an example of how the browser interacts with the server :
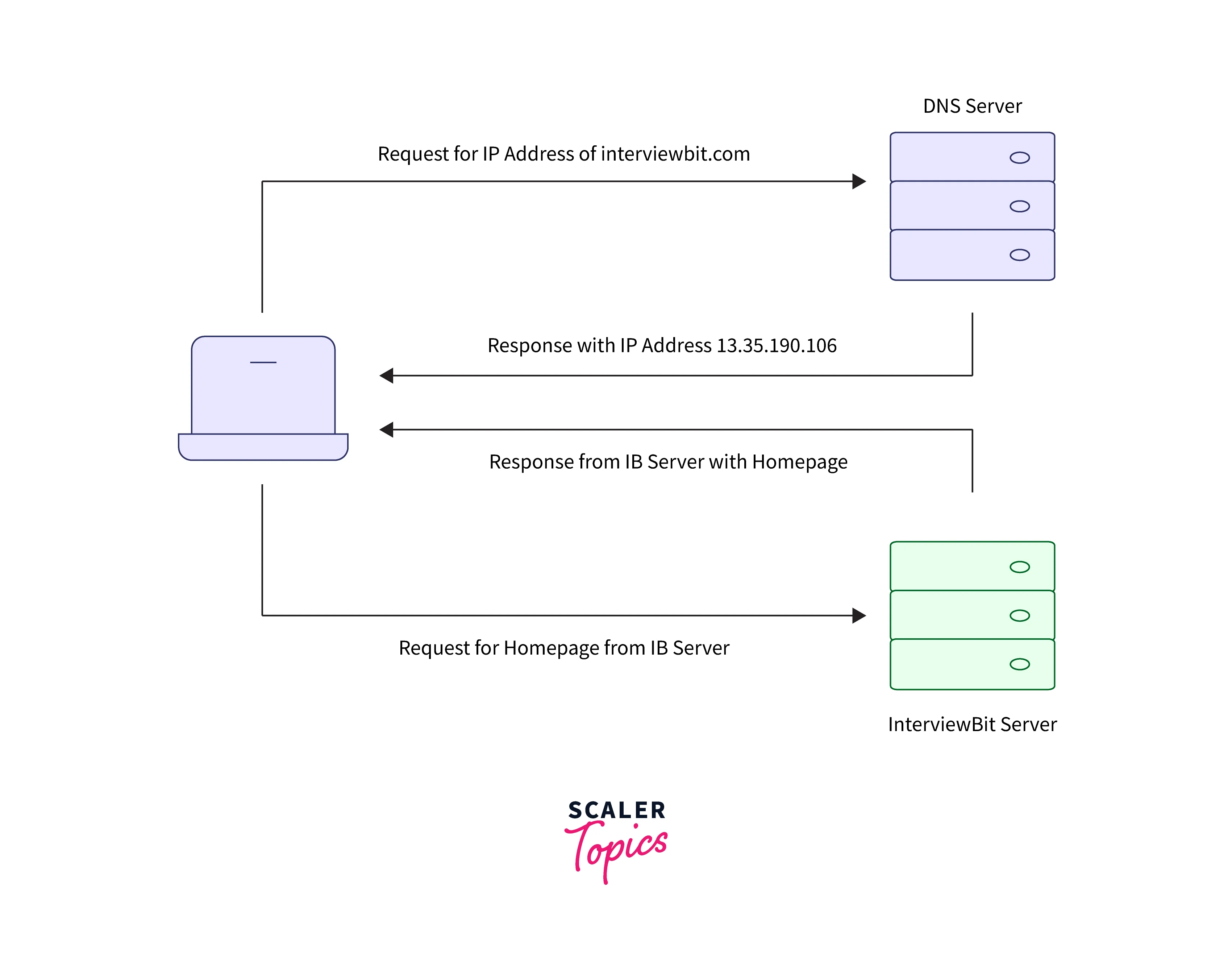
- The user enters the URL (uniform resource locator) of any file or any website, and the browser sends the request to the DNS (domain name system) server.
- The DNS server looks in the mapping (website URL and the IP address) and returns the IP address of the web server.
- Then the browser sends over an HTTP or HTTPS request to the web server’s IP address, which was provided by DNS.
- Then the server responds with the data that is files or the webpage and the connection is closed.
- Then the browser renders the information provided by the server.
- To fetch another resource, the entire request-response cycle is repeated.
Architecture of HTTP :
The HTTP basics protocol is based on the client-server architecture where web browsers, robots, and search engines act as the clients and the web server acts as the server.
The client-server architecture, also known as the network computing model and resembles the request-response pattern, is a network application that breaks down workload and tasks that are present with the same system or need to communicate within the network. The purpose of the client-server framework is the same as the distributed computing systems as all the computers (nodes) are doing independent tasks.
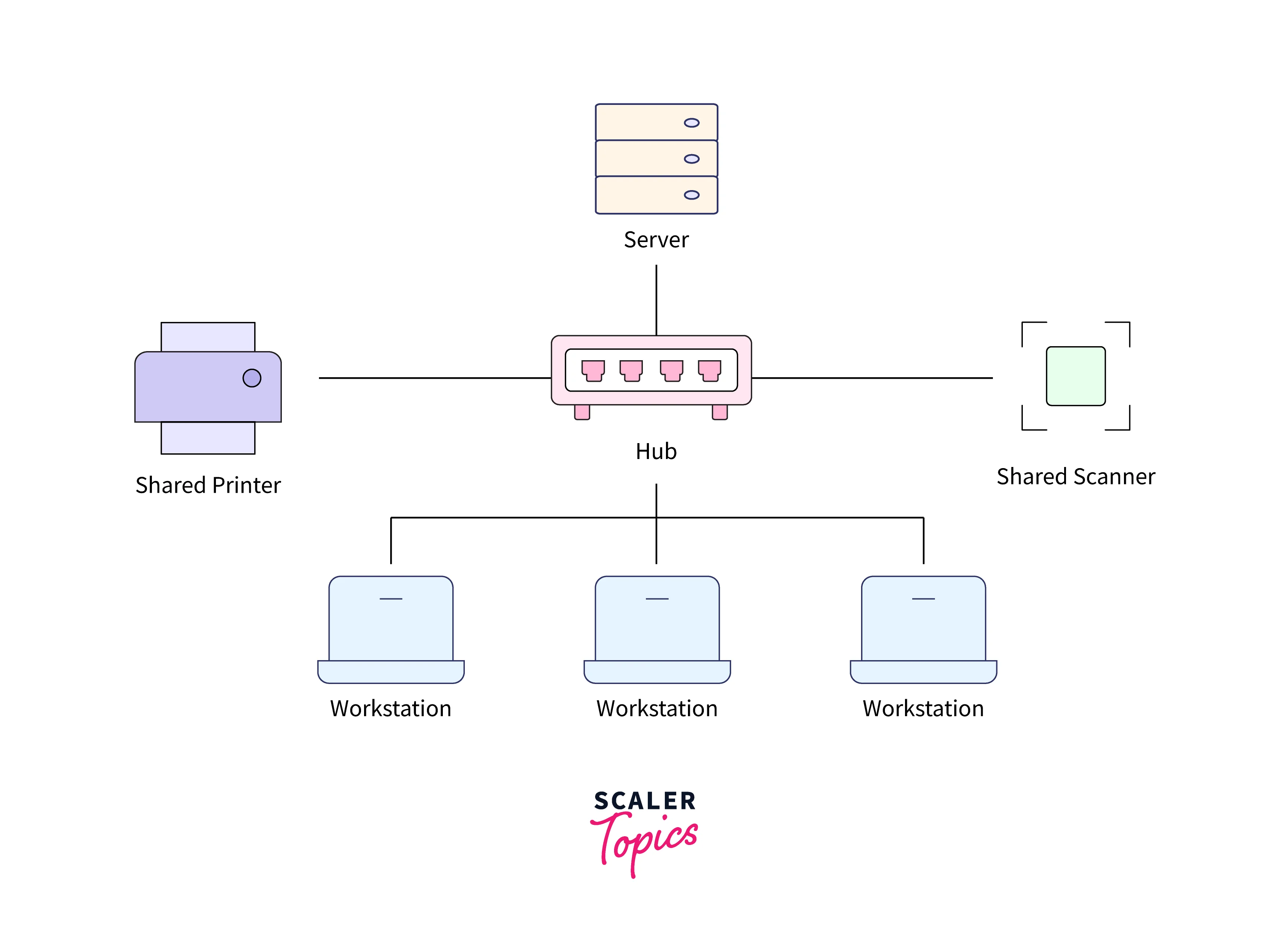
Thus the essential client-server architecture components are:
- Workstations (clients): A workstation is a system of users that is sometimes also named the client's computer. The client's computer generally acts as the front end and provides an interface to the user
For example – Visiting any website, you request the webpage from its domain. So here you are acting as a client.
- Servers: A server generally acts as the backend and provides a fine standardized interface to different workstations so that clients need not be aware of the specifics of the system (i.e., the software and hardware) that is providing the service.
For example - the client asks for the webpage, then the server responds with the webpage to the client.
- Networking Devices: Networking devices act as a specific medium that connects different workstations or clients to a powerful server.
For example - Networking devices used in client-server architecture have different purposes and properties ; For isolated network segmentation, bridges are used. For making a connection to a server, various workstation hubs are used.
In brief, the steps involved in the client-server model are:
- First, the client sends their request via a network-enabled device.
- Then, the network server accepts and processes the user request.
- Finally, the server delivers the response to the client.
Here at a very high level, the communication between the client and server happens over the HTTP packets. This architecture paradium worked very effectively with what others refer to as Web 2.0. Here the internet became the customer's remote environment.
Characteristics of HTTP :
HTTP is a communication protocol based on IP that facilitates the delivery of data between client and server.
- HTTP is a connectionless protocol. The client requests some specific server and waits for the response. The server parses the request and sends the response. The client and the server know each other during the current request and response. After the client disconnects, a new connection is made, and the client servers are new to each other.
- HTTP is media independent. This means that as long as both client and server know how to handle the media, it can be sent over HTTP. The type of the file must be specified in the header.
- HTTP is a stateless protocol. This means that the current request does not know previous requests. The client and server forget each other after the client disconnects. The server does not store the state of each client.
Turn Learning into Career Growth
HTTP Requests
An HTTP client sends a request to a server to fetch a resource. The request is in the following format:
- A request line.
- A series of HTTP basics headers or header fields.
- A message body (optional).
Request Line:
The structure of a request line is as follows: <Request Method><Space><Request URI><Space><HTTP version><Carriage Return>
Request Methods:
- GET: The GET method is used to fetch resources from the server. It can only retrieve data and should not have any effect on the data.
- HEAD: Similar to GET, but the status line and the header section only are transferred.
- POST: The POST method is used to send data to the server.
- PUT: Replaces all the currently stored data at the target resource with the uploaded data.
- DELETE: Deletes all the current data of the resource at the URI.
- CONNECT: Creates a tunnel to the specified server identified by URI.
- OPTIONS: Specify the communication options for the target resource.
- TRACE: Used to perform message loopback tests of a given URI.
HTTP Response
After receiving a request from the client, the server parses the request and generates a response that contains the requested file or data. The response has the following structure:
- Status Line
- Headers separated by a newline.
- An empty line
- Body of the message(Optional)
Status Line:
The status line is the first line of the HTTP response. It contains the status code and corresponding text message. <HTTP-Version> <space><Status Code> <space><Status Message><Carriage Return>
Status Codes:
The status code is a 3-digit numeric value. The status code determines the result of the request. The first digit determines the class of the response. The following are the five categories of status codes:
- 1xx: Informational This denotes that the server has received the request and is processing the request.
- 2xx: Success This means that the resource has been successfully fetched or the action is successful.
- 3xx: Redirection This denotes that the request has been redirected for further processing.
- 4xx: Client Error This means that the client has provided some invalid input or input format.
- 5xx: Server Error This denotes that some error occurred at the server's end and the server was not able to fulfill the request
Some most common status codes are :
| HTTP Status Code | Meaning |
|---|---|
| 100 | Continue |
| 101 | Switching Protocols |
| 102 | Processing |
| 103 | Early Hints |
| 200 | OK |
| 201 | Created |
| 202 | Accepted |
| 203 | Non-Authoritative Information |
| 204 | No Content |
| 301 | Permanent Redirect |
| 302 | Temporary Redirect |
| 304 | Not Modified |
| 400 | Bad Request |
| 401 | Unauthorized |
| 403 | Forbidden |
| 404 | Not Found |
| 405 | Method Not Allowed |
| 410 | Gone |
| 500 | Internal Server Error |
| 503 | Service Unavailable |
| 504 | Gateway Timeout |
| 505 | HTTP Version Not Supported |
| 511 | Network Authentication Required |
Advantages of HTTP
It is the basis of any data interaction on the Web, and it is a client-server protocol, some of its advantages are :
- Because of fewer TCP connections, the network congestion is low.
- Low use of memory and CPU because of less number of simultaneous connections.
- Wherever there are additional requirements in the application, HTTP can download extensions to display data.
- Only when the connection is established then only handshaking takes place. This reduces latency as less handshaking takes place.
- With the help of caching, the efficiency of accessibility increases significantly.
- HTTP allows pipelining.
Disadvantages of HTTP
- High Power is required to establish a connection and transfer data.
- Due to the lack of any encryption method, HTTP is less secure.
- It is not suitable for IO due to high power usage.
- Generating multiple connections for transmitting web pages creates administrative overhead.
- Being less secure, HTTP is not able to perform a genuine exchange of data.
- Even if all required data is fetched, the client does not close the connection.
Difference Between HTTP and HTTPS
One of the significant disadvantages of HTTP is that it does not use any encryption method; hence it is less secure. Security is needed in cases of financial transactions or in cases where the privacy of data is important. To overcome this, HTTPS was introduced. The ‘s’ in HTTPS stands for secure. HTTPS uses TLS or SSL to provide secure data transmission. The cryptographic protocols combined with HTTP form HTTPS.
| HTTP | HTTPS |
|---|---|
| HTTP stands for HyperText Transfer Protocol. | HTTPS stands for HyperText Transfer Protocol Secure. |
| In HTTP, URL begins with http:// | In HTTPS, URL begins with https:// |
| HTTP uses port number 80 for communication. | HTTP uses port number 443 for communication. |
| HTTP is considered to be insecure. | HTTPS is considered to be secure. |
| HTTP Works at the Application Layer. | HTTPS works at Transport Layer. |
| In HTTP, Encryption is absent. | In HTTPS, Encryption is present. |
| HTTP does not require any certificates. | HTTPS needs SSL Certificates. |
| HTTP speed is faster than HTTPS due to its simplicity. | HTTPS speed is slower than HTTP due to due to initial step of SSL handshake which is quite a bit of overhead for small requests. |
| HTTP does not improve search ranking. | HTTPS improves search ranking. |
| HTTP does not use data hashtags to secure data. | HTTPS will have the data before sending it and return it to its original state on the receiver side. |
Conclusion
- Hypertext transfer protocol (HTTP) is the protocol used by the world wide web to facilitate the communication of data.
- Hyper Text Transfer Protocol is a request-response protocol that is used to receive web pages on a client-server architecture
- HTTP basics protocol, developed by Tim Berners Lee and his team at CERN, has undergone several evolutions since 1989.
- HTTP basics protocol is based on the client server architecture where web browsers, robots, and search engines act as the clients, and the web server acts as the server.
- HTTP is a connectionless, media, and stateless protocol.
- Some of the HTTP request methods are GET, PUT, DELETE, POST, HEAD, CONNECT, and TRACE.
- HTTP responsive status code is a 3-digit numeric value that determines the result of the request.
- Five categories of reponsive codes are 1xx: Informational, 2xx: Success, 3xx: Redirection, 4xx: Client Error and 5xx: Server Error.
- HTTP has low network congestion, low use of memory, and allows pipelining.
- HTTP requires high power and is not suitable for IO because of low security.
- HTTP works on port 80 and HTTPS works on port 443.
- HTTPS has security and encryption and improves the search ranking of a webpage.