Manipulating and Displaying Structured Data
Overview
A homogeneous array of integers can often appropriately represent our data, but this is not always the case. Structured arrays are NumPy array subsets. We use dtype not only in generating a structured array, but it also tells us about the names of the fields, the data type of each field, and the percentage of the memory block each field occupies. Thus, knowing Manipulating Data Types in Numpy is useful when dealing with structured arrays.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Introduction
Before we begin, we'll presume you've successfully installed Python on your machine and are familiar with the NumPy library's fundamentals, notably the numpy.dtype() function. It is strongly advised that you read the official documentation before continuing if you have any doubts regarding the numpy.dtype() function.
You could be attempting to modify or display NumPy structured data types while not knowing what they are. Before we begin with the conversions, let's define NumPy structured arrays in the first place. If you've previously done so, skip ahead to "Manipulating and Displaying Structured Data Types in NumPy."
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
NumPy Structured Arrays
Consider the following scenario: there are only five people on the planet. All we know about them is their names and ages. Lists are the most straightforward approach to storing this information. However, it is not the best technique and is incredibly memory inefficient. NumPy structured arrays come in handy here.
A structured data type is used to build Numpy Structured Array. A structured data type might have several types, each with its own name. Numpy Structured Array can store and access the same data effectively. It does this by storing the full array as a contiguous array in the same memory space.
Let's build a Numpy Structured Array with a Structured data type.
Note: Jupyter Notebook has been used over here and is the preferable IDE
Code:
Output :
The above code creates an empty Structured Array, which can be understood and shown as follows:
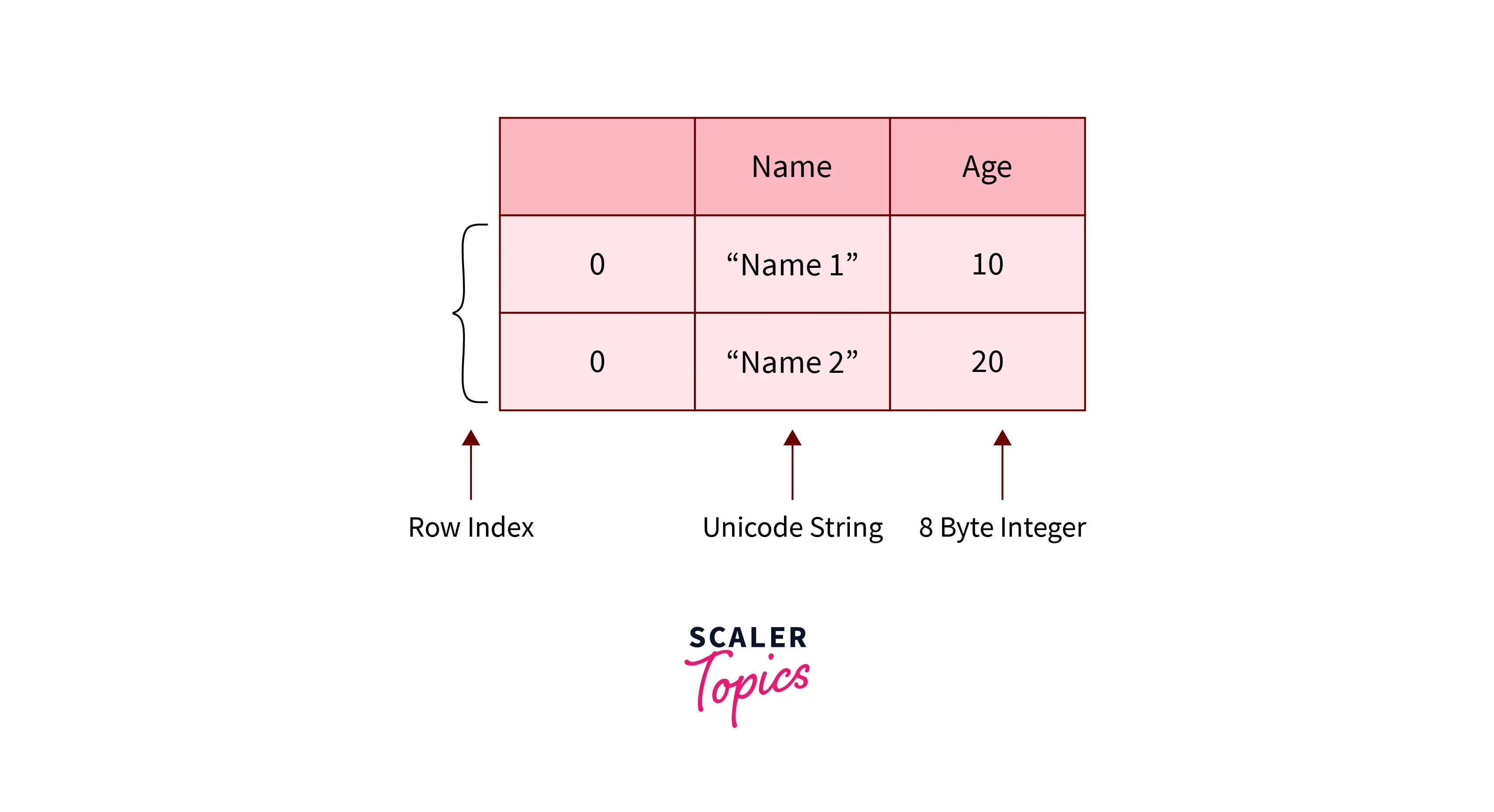
Now that you have a basic grasp of what NumPy structured arrays are and how to create them, let's look at how to manipulate and display NumPy Structured Data types.
Manipulating and Displaying Structured Data Types
We can operate on a structured array once it has been generated from a structured data type. Now that we've generated one, let's look into the details of how to manipulate and display data types within NumPy structured arrays.
Using an example, let's say we have the following:
Code :
The abbreviated string format codes used to assign dtypes to structured arrays over here may appear confusing, but they are based on clear and simple logic. The first (optional) letter is < or >, which signifies "little-endian" or "big endian," and sets the significant bit ordering standard. The following letter indicates the data type: characters, bytes, ints, floating points, and more. The final character or characters reflect the object's size in bytes.
In this case, the data type we just constructed may be used to store data with two fields, the first of which is age, which can store a 32-bit integer, and the second of which is income, which can store a 32-bit floating point value. In the preceding example, the characters "i4" and "f4" stand for "4-byte (or 32-bit) integer" and "4-byte (or 32-bit) floating point integers," respectively.
In this scenario, we knew what our headers were. What if we come across a situation where we are unaware of them or wish to modify them to meet our needs? Let's dig a little deeper.
Turn Learning into Career Growth
Accessing through the Names and Fields of the dtype
A NumPy structured datatype's field names may be found in the names property of the dtype object:
Code:
Output :
The field names can be changed by setting a series of strings that have the same length as the names attribute.
Code:
Output:
The dtype object also includes a dictionary-like function called fields, which has keys that are the field names and values that are tuples that contain the dtype and byte offset of every field.
Code:
Output :
For unstructured arrays, the names and field properties will both be None. To account for dtypes with 0 fields, the preferred approach to test if a dtype is structured is using if dt.names are not None instead of if dt.names .
Byte Offsets and Alignment
We saw in the last example that the dtype object also has a dictionary-like function called fields, which has keys that are the field names and values that are tuples that include the dtype and byte offset of every field. We know what dtype means. Therefore, now let us try to figure out what we meant by byte offset. Offset, in general, indicates the location of a chunk of data in relation to another place. The byte offset is the number of bytes beginning at zero.
Now that we've covered the basics of byte offset, let's look at how NumPy handles it and what it means in the value of the dictionary returned by the field method.
Depending on whether align=True was supplied as a keyword argument to numpy.dtype, NumPy employs a way to automatically establish the field byte offsets and overall item size of a structured data type.
NumPy will compress the fields together so that each field begins at the byte offset where the preceding field is finished, and the fields are continuous in memory if the keyword parameter alignment is set to False. Consider the following example:
Code:
Output:
In some circumstances, aligned structures might enhance performance at the expense of greater datatype size. Consider the scenario when align=True is set: numpy pads the structure in the same manner that mostly C compilers pads a C-struct. Padding bytes are placed between fields so that the byte offset of each field is a multiple of the alignment, which is generally equal to the field's size in bytes for basic data types. The structure will additionally have tail padding added such that the item size is a multiple of the alignment of the biggest field.
Code:
Output:
Note that if offsets were provided via the optional offsets key in the dictionary-based dtype specification, setting the keyword argument to align to True will check that every field's offset is a multiple of its size and that the item size is a multiple of the biggest field size, and will throw an error if they are not.
Field Titles
You should now understand the concepts of Byte Offsets and Alignment. Let us now talk about Field titles. So, what precisely is a field title? Fields may have an accompanying title, an alternative name that is occasionally used as an extra description or alias for the field, in addition to field names. The field title, like a field name, can be employed to index an array.
When employing the list of tuples method of dtype specification, the field name can be supplied as a tuple of two strings rather than a single string, which will contain the field's title and field name. Consider the following example to help comprehend it:
Code:
Output:
When employing the first form of the list of tuples standard, the titles can be provided as an additional 'titles' key, as stated above. When adopting the second technique, dictionary-based specification, which is often discouraged due to readability issues, the title can be given by supplying a 3-element tuple (datatype, offset, title) rather than a normal 2-element tuple. Consider the following example:
Code :
Output:
We learned in the section Manipulating and Displaying Structured Data Types that the dtype.fields function produces a dictionary with titles as keys if any of the titles have been used. This basically implies that a field having a title will appear twice in the fields dictionary. That, however, is not the case. The field title will be added as a third element to the tuple values for these fields. It is advised to loop through the fields of a dtype employing the names attribute of the dtype since it will not list titles and because it maintains the field order, whereas the fields attribute may not. For example:
Code:
Output:
This brings us to the conclusion of our article. Kudos! You should have by now understood how to manipulate and display structured data types in NumPy.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Conclusion
This article taught us :
- In the case of structured type, data type informs us about the names of the fields, the data type of every field, and the portion of the memory block occupied by each field.
- The names property of the dtype object may be used to find or update the field names of a NumPy structured data type.
- The dtype object also has a dictionary-like function called fields, which has keys that are the field names and values that are tuples containing the dtype and byte offset of every field.
- If the keyword parameter aligns is set to False, NumPy will compress the fields together such that each field begins at the byte offset where the preceding field ended, and the fields are continuous in memory; otherwise, if align is set to True, it will not.
- In addition to field names, we may provide an alternative name in the field title, which is occasionally used as an additional description or alias for the field.