Regex Filtering with Pandas
Overview
In Python, Pandas can be considered a widely used tool for data manipulation tool due to its functionalities. A Pandas module called Regex makes it convenient to retrieve information from large data. In this article, we will discuss the various methods going over Regex filtering using Pandas.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Introduction
In practical scenarios, data frames are large, with thousands of rows and columns. In this case, it becomes difficult to manually scan the entries and get the required value, row, or column. Here, regex filtering comes into play. Regex can be used with data frames and series both, thus making it a disposable asset.
The most common use case of regex filtering is search engines like Google, Bing, etc. In this case, we type phrases, and they are processed by these search engines where they 'filter' or look for these particular phrases on the web. Other applications are searching files in Operating Systems, searching for text in editors, authenticating information, and others.

What is Regex?
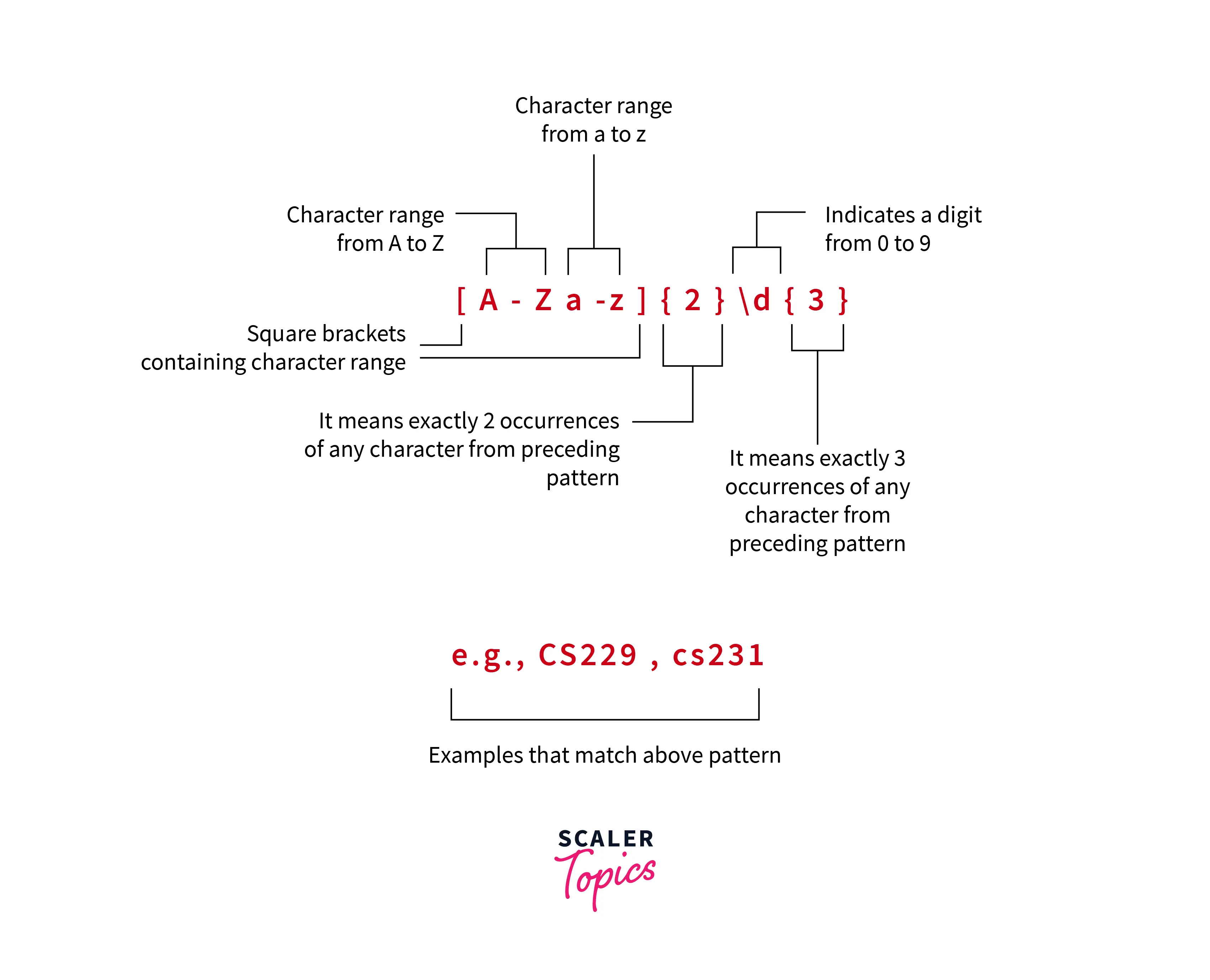
Regex is Regular Expressions - it is a set of characters arranged sequentially to form a pattern, a string that is used to extract data matching the pattern, in turn filtering the data. Regex filtering in Pandas is supported in the 're' module. To know more about Regex, go to - {link to regex blog}
Turn Learning into Career Growth
Examples of Regex
Regex can be utilized for both strings and extensive datasets.
Let us consider the below dataset -
| Number | Month |
|---|---|
| 1 | January |
| 2 | February |
| 3 | March |
| 4 | April |
| 5 | May |
| 6 | June |
| 7 | July |
| 8 | August |
| 9 | September |
| 10 | October |
| 11 | November |
| 12 | December |
Now,
- To filter months starting with 'M', we use 'M.*', here the Asterix represents selecting all words with the occurrence.
- For filtering the months ending with 'ber', we use '[$ber]', here the brackets are used for defining the set of characters required, and the dollar symbol depicts words ending with.
How to Filter Using Regex?
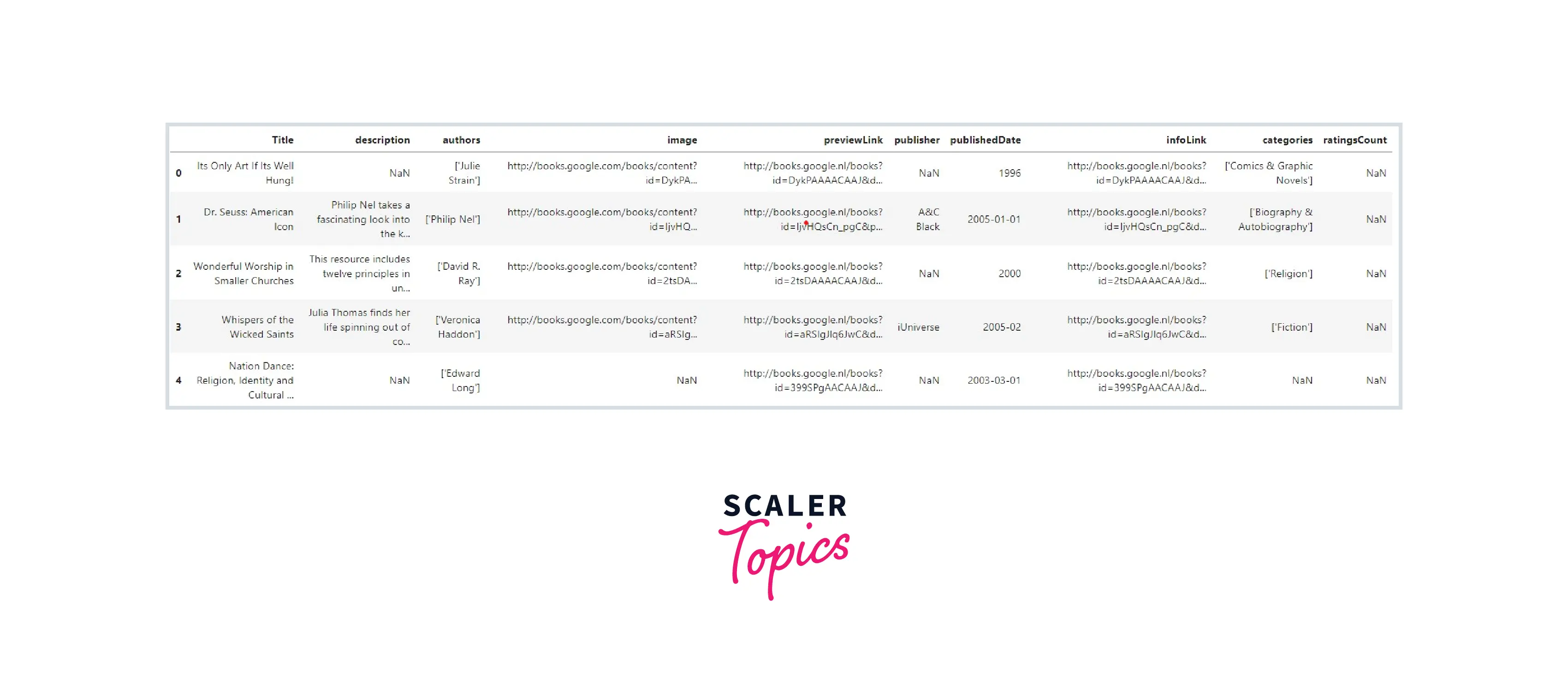
Now that we have a firm understanding of regex, let us try to apply it to a dataset - the Amazon book reviews dataset on Kaggle.
Output:
Now let us review more important functions:
-
Using str.match() -
As the name suggests, this function is used to check the similarities or the common attributes between two strings or a string in a dataset. In other words, it uses Regex Filtering to match values.
Example 1 -
Output:
Example 2 -
Output:
-
Using extract() -
Extract function in Regex Filtering outputs groups having a defined value in the form of a pattern.
Example 1 -
Output:
Example 2 -
Output:
-
Using count() -
As the name implies, the count function quantifies the instances of a specific expression using Regex.
Example 1 -
Output:
Example 2 -
Output:
-
Using findall() -
The findall function, as its term suggests, uses regex to retrieve every instance of the specified expression.
Example 1 -
Output:
Example 2 -
Output:
-
Using contains() -
Contains method checks for the existence of a value in the given expression and returns a boolean value.
Example 1 -
Output:
Example 2 -
Output:
Conclusion
- In this article, we have covered the fundamentals of regex, which is a string that is used to extract data that matches a pattern made up of a series of characters organized successively.
- Text editors and search engines are where regex filtering is most widely implemented along with other applications.
- String Matching is used to find similarities between two strings, whereas containing returns a boolean value based on the existence of the pattern in the given string or dataframe.
- Extraction is the return of the desired pattern within the string.
- The number of occurrences of a given pattern or string is returned using Count.
- To find all the patterns or substrings present, we use findall.