Phases of Compiler
Overview
A compiler is software that translates the code written in one programming language to another. Ex, g++ from GNU family of compilers, PowerBASIC, etc.
The purpose of a compiler is to enable its user to write programs in a certain language that is user-friendly and convenient. The compiler then converts the program into another program of a language that is more close to the machine and more efficient. In compilation, there are many phases of the compiler.
Phases of Compiler
Following are the six phases of compiler:
1. Lexical Analysis:
In the first phase in the compiler, lexical analysis receives as input the source code of the program. Lexical analysis is also referred to as linear analysis or scanning. It's the process of tokenizing.
Lexer scans the input source code, one character at a time. The instant it identifies the end of a lexeme, it transforms the lexeme into a token. The input is transformed in this manner into a sequence of tokens. A token is a meaningful group of characters from the source which the compiler recognizes. The lexical analyzer then passes these tokens to the next phase in the compiler.
Scanning only eliminates the non-token structures from the input stream, such as comments, unnecessary white spaces, etc. The program that implements lexical analysis is known as a lexer, lexical analyzer, or scanner.

2. Syntax Analysis:
Syntax analysis, the second phase in the compiler, receives as input the stream of tokens, corresponding to which it produces a parse tree as output. Syntax analysis is also referred to as parsing. The parse tree is generated with the help of pre-determined grammar rules of the language that the compiler targets.
The syntax analyzer checks whether or not a given program follows the rules of context-free grammar. If it does, then the syntax analyzer creates the parse tree for the input source program.
The phase of syntax analysis is also known as hierarchical analysis, or parsing. The program that is responsible for performing syntax analysis is referred to as a parser. During parsing, the parser determines the syntactic validity of the source program.

3. Semantic Analysis:
In the third phase in the process of compilation, semantic analysis checks if the parse tree that it receives as input, abides by the rules of the language which the compiler targets. The semantic analyzer also records all the identifiers, their types, expressions, etc. The semantic analysis phase generates as output the annotated tree syntax.
The semantics of a language make its constructs such as tokens and syntax structures meaningful. Semantics enables interpreting symbols, their types, and the relations among them. Semantic analysis determines if the syntax structure of the source code has any meaning or not.
There are certain rules set by the grammar of the target language that is evaluated during semantic analysis. Semantic analysis performs scope resolution, type checking, array-bound checking.

Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
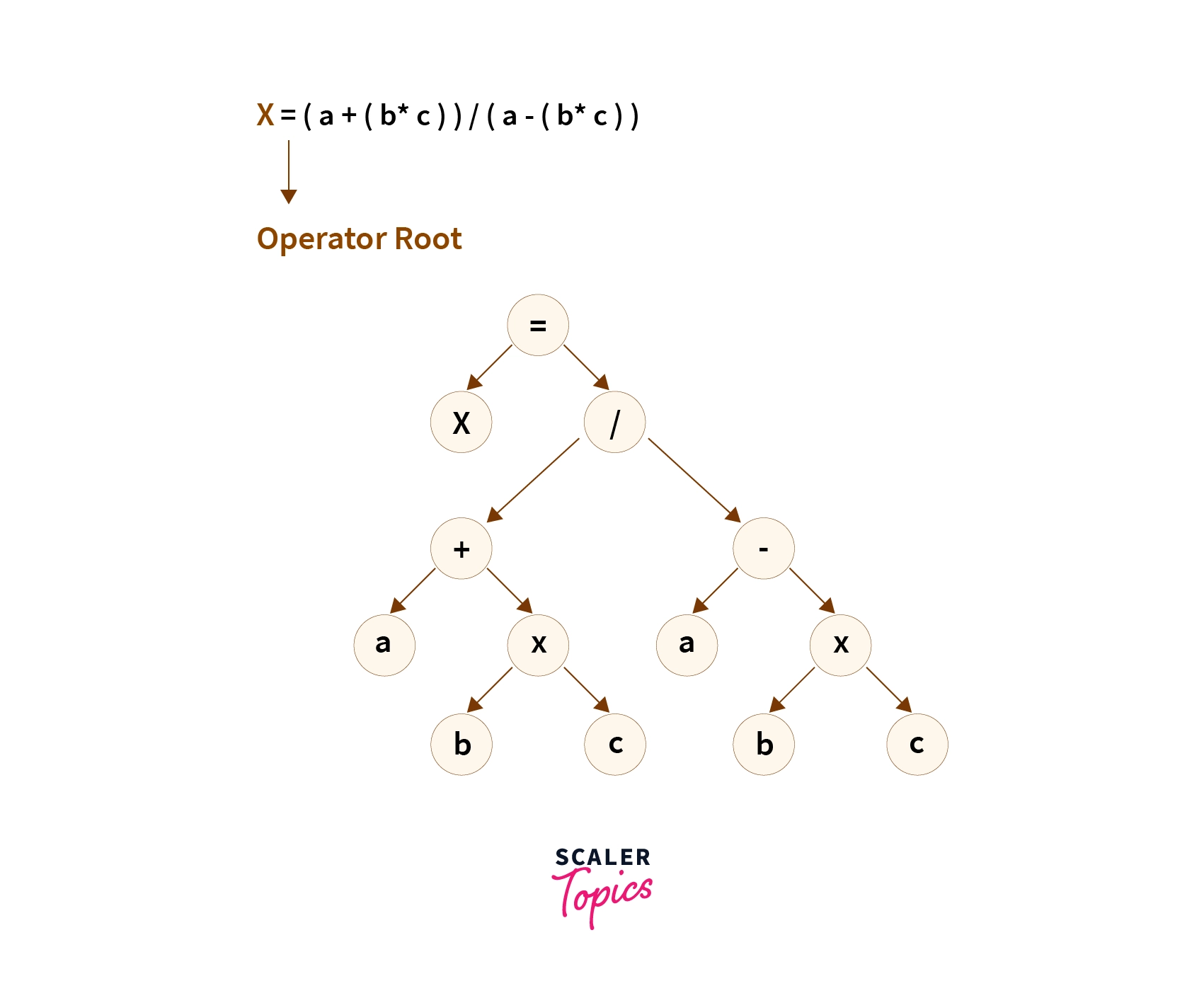
4. Intermediate Code Generation
Intermediate code generation is the fourth phase in the process of compilation, during which the input source code is transformed into an intermediate form. This generated intermediate code lies in the range between the high-level language (in which the original initial input source program was written) and the low-level machine language such as assembly. The intermediate code is generated in a manner such that it becomes quite easy for a user to translate it into the target machine code. It can be represented using various notations techniques such as postfix notation, directed acyclic graph, syntax tree, three-address codes, quadruples, triples, etc. Intermediate code does not need a full compilation every time it needs to be run on different machines.
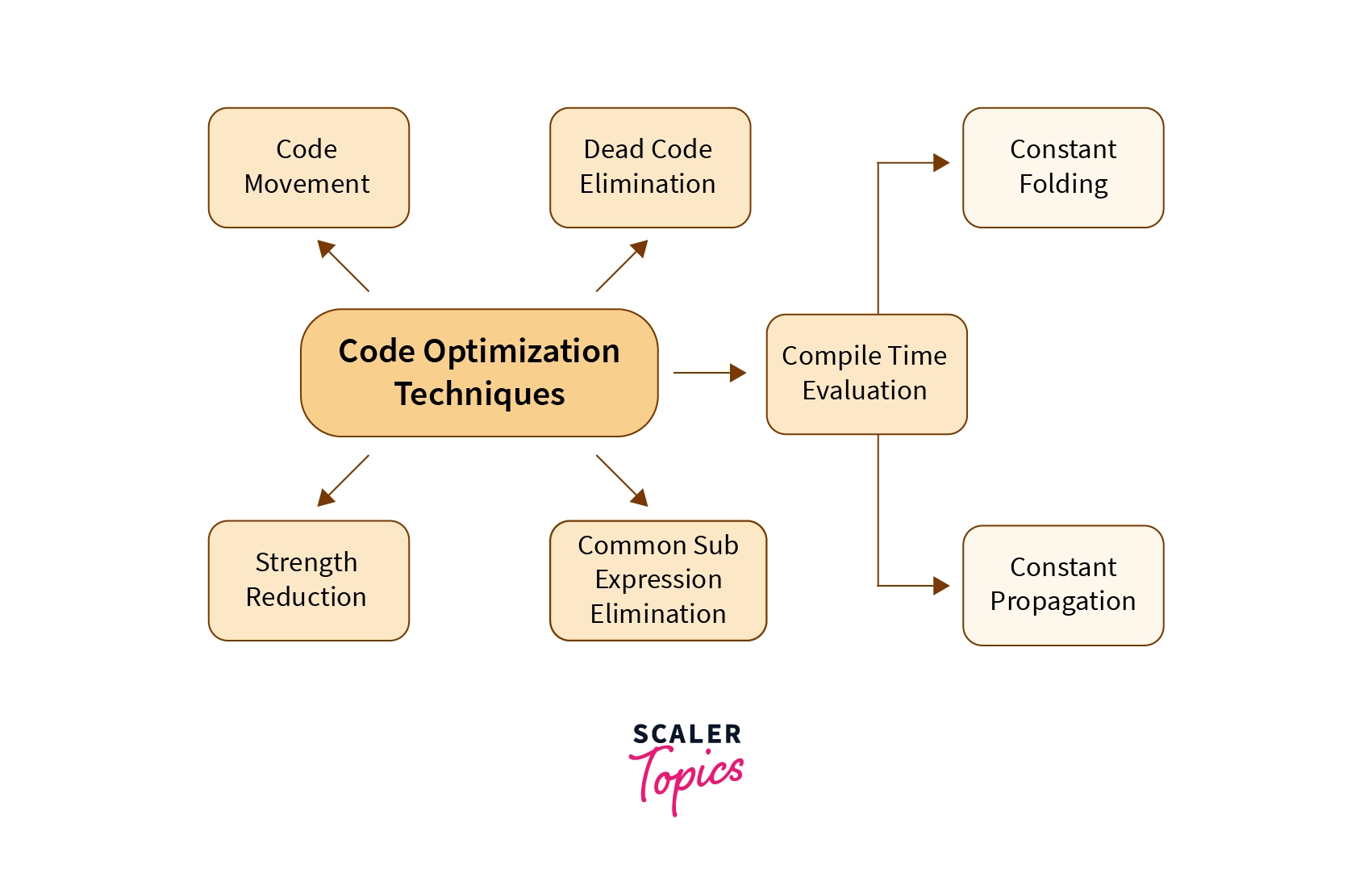
5. Code Optimization
This phase alters the intermediate code it receives as input such that the program output becomes relatively more efficient in terms of both runtime and memory consumption. These changes include, but are not limited to, removing unnecessary parts of code, appropriately arranging the lines of code.
Code optimization may or may not be dependent on the machine. In machine-independent optimization, the compiler takes in the intermediate code and changes a part of the intermediate code such that there is no involvement of any CPU registers and absolute memory locations.
Machine-dependent optimization is done after the target code has been generated. The code is changed as per the architecture of the target machine. This optimization involves CPU registers and absolute memory references.
6. Code Generation
In the sixth and the final phase of the compiler, code generation receives as input the optimized intermediate code and translates the optimized intermediate code into the target machine language. This phase involves assembly language usage to convert optimized code into target machine format. Target code could be either machine code or assembly code. Each line in optimized code is mapped to several lines in machine/assembly code.
Error Handling Routine
Error Handling routine detects errors, reports them to the user, and follows some recovery plan to handle the errors. Errors are denoted by blanks in the symbol table. An error could be either of the following two kinds:
1. Run time:
These errors occur during the program execution. The common reasons behind them occurring are incorrect system parameters, invalid input data, lack of enough memory to run the program, a memory conflict with another program, logical errors such as division by zero, etc.
Turn Learning into Career Growth
2. Compile-time:
These errors arise during the program compilation. Common reasons are syntactic invalidity, missing file references, etc.
Following are the four ways of recovering from an error:
1. Panic Mode Recovery:
Panic mode recovery is the simplest method and prevents the parser from developing infinite loops during the recovery process. The parser rejects the input symbol one by one until one of the designated sets of synchronizing tokens such as semicolons, etc is found.
This would be sufficient if it's unlikely that multiple errors will be present within any one statement.
2. Phase Level Recovery:
In the phase level recovery method, when the parser hits an error, it makes necessary changes to the remaining input so that the parser can continue parsing. The error can be resolved by removing extra semicolons, replacing commas with semicolons, reintroducing missing semicolons, etc. When any prefix is detected in the remaining input, the prefix is replaced with some suitable string which could ensure that parsing can be continued further.
3. Error Productions:
This method can be deployed if the user is aware of common grammar-related mistakes that are found along with errors that generate erroneous constructs. When this method is incorporated, it's possible to generate error messages during parsing, and the parsing can be continued.
4. Global correction:
To recover from error-causing inputs, the parser analyzes the entire program and attempts to find the closest error-free match for it. This match is required not to be performing several insertions, deletions, and changes of tokens. This method is not found to be practical because of its high time and space complexity.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Symbol Table
It's a data structure that the compiler generates and maintains to keep track of the semantics of variables. It stores many types of information such as information about the scope and binding information of names, about instances of entities such as variables, function names, classes, etc.
The symbol table is created during syntax analysis and linear analyses and is utilized by the compiler to achieve increased efficiency during compile time. Every symbol table entry is associated with attributes that assist the compiler during several phases of the compiler.
The items stored in symbol table are - , , , , , , , and in source languages.
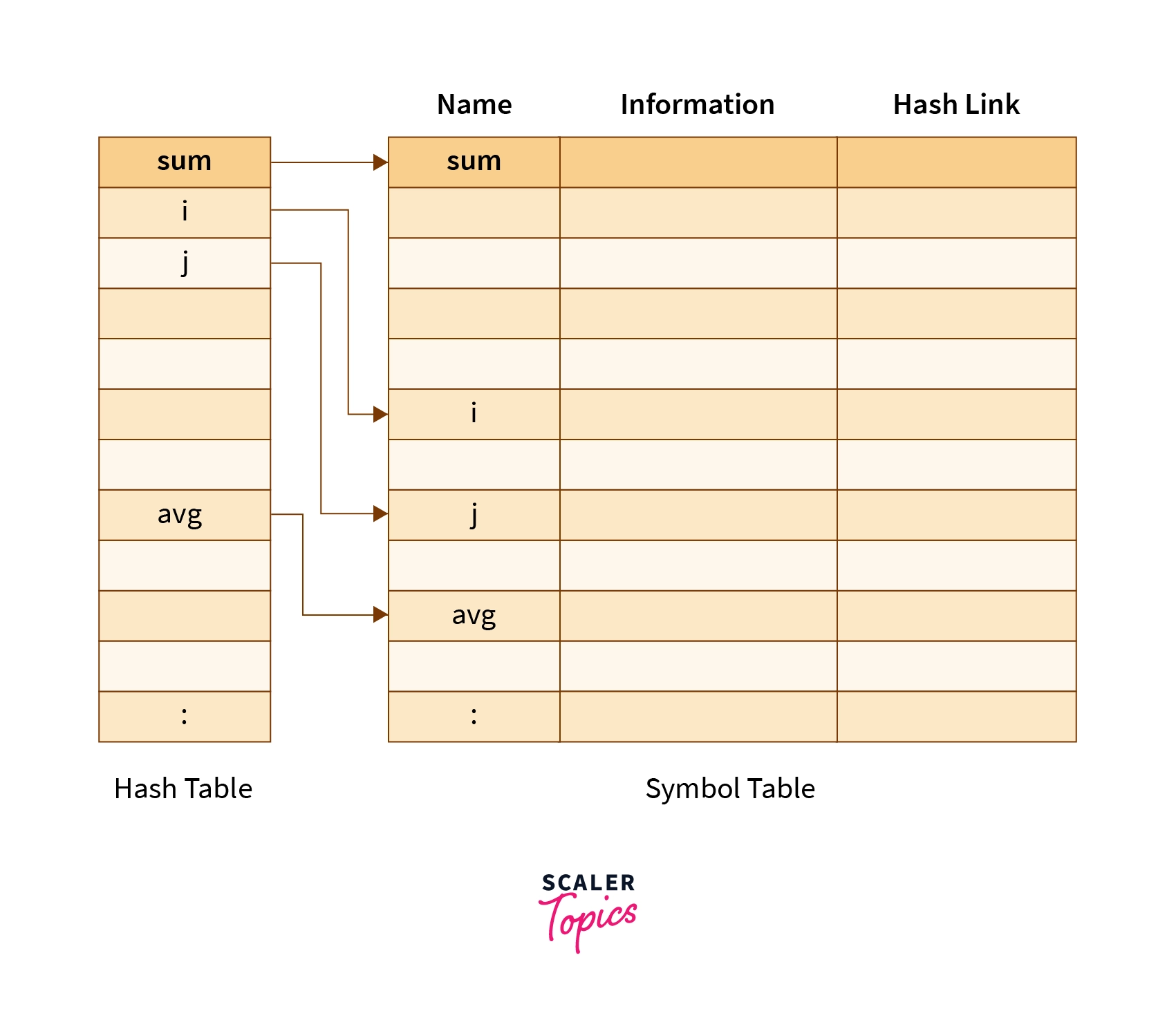
Symbol Table Management
When an identifier is found, it's entered into the symbol table. The information stored consists of name, location, form, size, scope, etc. Symbol table entries are stored in records. A record is a certain number of consecutive memory locations. Following are the various implementations of the symbol table, depending on the data structure used:
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
List
Uses pointers to create a dynamically allocated linked list. A list is easy to implement. Operations such as retrieving information, inserting entries, are efficient. Instead of a linked list, an array can also be used.
Binary Search Tree
Stores the entries in an ordered fashion. Searching is efficient. Uses pointers to create a binary tree, in the nodes of which entries are stored.
Hash Table
The position of an entry is calculated by using the concept of hashing. By some pre-determined suitable formula, a hash value is computed for the entry. Then this calculated hash value is used as a position for storing the entry. Insertion, deletion, searching are all very easy and fast. But requires a large amount of memory.
Applications of Compilers
- Compiler technology is required in implementing high-level programming languages to transform them into a low-level language that can be understood by the machine.
- Optimizing compilers help in optimizing the overall performance of the program and thus discards the inefficiency of high-level abstractions.
- Compiler technology is also useful in designing computer architectures. Earlier, compilers were created after setting up the machines. Lately, compilers have started to be built in the processor-design stage of modern computer architecture designs.
- Compiler technology also helps several application threads to run on different processors.
- Compiler technology is also used in many program translations such as binary translation, hardware synthesis, database query interpretation, etc.
Conclusion
- A compiler is software that translates the code written in one programming language to another. Ex, g++ from GNU family of compilers, PowerBASIC, etc.
- There are 6 phases in the compiler, namely, lexical analysis, syntax analysis, semantics analysis, intermediate code generation, code optimization, and code generation.
- Symbol table is a data structure that the compiler generates and maintains to keep track of the semantics of variables.
- The error Handling routine detects errors, reports them to the user, and follows some recovery plan to handle the errors.
- Errors could occur either during compile-time or run-time.
- There are four methods of recovering from an error- panic mode recovery, phase level recovery, error production, and global correction.