Preventing Hallucinations in Generative AI: Techniques and Best Practices
In the context of preventing hallucinations in generative AI models, the primary goal is to ensure outputs are factually accurate, consistent, and grounded in verifiable data sources. This involves a multi-layered approach combining data-centric strategies, model-tuning techniques, and robust inference-time interventions to mitigate the generation of plausible but fabricated information.
Generative Artificial Intelligence, particularly Large Language Models (LLMs), has demonstrated an extraordinary capacity for content creation, summarization, and complex problem-solving. However, this power is accompanied by a significant challenge: the tendency for these models to "hallucinate." A hallucination, in this context, refers to the generation of information that is factually incorrect, nonsensical, or untethered from the provided source material. While these outputs can be convincingly fluent and grammatically correct, their lack of fidelity poses a critical barrier to deploying generative AI in high-stakes applications like enterprise knowledge management, medical diagnostics, and financial analysis. This article provides a comprehensive technical overview of why hallucinations occur and explores the engineering techniques and best practices to mitigate them, ensuring the development of more reliable and trustworthy AI systems.
Stop learning AI in fragments—master a structured AI Engineering Course with hands-on GenAI systems with IIT Roorkee CEC Certification
AI Engineering Course Advanced Certification by IIT-Roorkee CEC
A hands on AI engineering program covering Machine Learning, Generative AI, and LLMs - designed for working professionals & delivered by IIT Roorkee in collaboration with Scaler.
Enrol Now
Understanding the Root Causes of Generative AI Hallucinations
To effectively address the problem, it is imperative to first understand its origins. Hallucinations are not random glitches; they are emergent properties stemming from the fundamental architecture and training methodologies of modern generative models. Understanding these root causes is the first step in the context of preventing hallucinations in generative AI models.
Probabilistic Nature of Transformer Architectures
At their core, LLMs based on the Transformer architecture are sophisticated next-token predictors. During generation, the model does not "know" facts in the human sense. Instead, it calculates a probability distribution over its vocabulary for the next token, given the preceding sequence of tokens. It then samples from this distribution to construct its response. This process, while powerful for generating coherent text, is inherently probabilistic, not deterministic. The model's objective is to generate a statistically likely sequence, which does not always equate to a factually correct one.
Gaps and Biases in Training Data
LLMs are trained on vast corpora of text and code scraped from the internet. This data is inherently flawed—it can be outdated, contain misinformation, reflect societal biases, or have significant gaps in its coverage of niche topics. When a model is prompted with a query for which it has insufficient or conflicting training data, it may attempt to "fill in the gaps" by generating a plausible-sounding but entirely fabricated response. This is analogous to an interpolation error, where the model confabulates information to connect disparate data points it has learned.
The "Curse of Knowledge" and Encoding Failures
While LLMs encode a tremendous amount of world knowledge into their parameters (weights), this knowledge is not stored in a structured, queryable format like a database. Specific, less-common facts may be weakly encoded or difficult to retrieve. This "Curse of Knowledge" means that even if a fact was present in the training data, the model might fail to access it accurately during inference, opting instead to generate a more generic or common, but incorrect, piece of information that has a higher statistical probability.
Misinterpretation of Ambiguous Prompts
The quality of a model's output is highly dependent on the quality of its input. Vague, ambiguous, or poorly constrained prompts give the model excessive creative latitude. Without clear instructions or sufficient context, the model's probabilistic generation process is more likely to stray from factual accuracy and enter the realm of confabulation. It may misinterpret the user's intent and generate a response that is coherent but contextually inappropriate or factually wrong.
A Taxonomy of Hallucination Prevention Techniques
Mitigating hallucinations requires a holistic strategy that addresses the entire AI development lifecycle, from data preparation to model inference. These techniques can be broadly categorized into data-centric, model-centric, and prompt-centric (or inference-time) strategies. Effectively implementing these methods is the most critical part in the context of preventing hallucinations in generative AI models.
Data-Centric Strategies
The foundation of any reliable AI model is high-quality data. Data-centric approaches focus on improving the information the model learns from and has access to.
- Data Curation and Cleaning: This is the most fundamental step. It involves rigorously filtering pre-training and fine-tuning datasets to remove low-quality content, misinformation, and identifiable biases. Techniques include using content classifiers, fact-checking against trusted sources, and ensuring a balanced representation of topics to prevent knowledge gaps.
- Knowledge Grounding: Grounding is the process of linking a model's responses to verifiable external knowledge sources. Instead of relying solely on the parametric knowledge encoded during training, the model is provided with relevant, real-time information to base its answers on. This is the core principle behind more advanced architectures like RAG.
Model-Centric Strategies
These techniques involve modifying the model's training or fine-tuning process to explicitly discourage hallucinations.
- Instruction-Tuning and RLHF: After initial pre-training, models are often fine-tuned on datasets of "instructions" and desired outputs. Reinforcement Learning from Human Feedback (RLHF) takes this a step further. In RLHF, human reviewers rank multiple model outputs for a given prompt based on criteria like helpfulness and honesty. A reward model is trained on these rankings, and then the LLM is fine-tuned using reinforcement learning (e.g., PPO - Proximal Policy Optimization) to maximize this reward. This process explicitly penalizes factually incorrect or hallucinatory outputs.
- Uncertainty Quantification: A significant way to reduce hallucinations in LLMs is to make them aware of their own confidence levels. If a model can recognize when it is uncertain, it can be prompted to state its uncertainty rather than fabricating an answer. Techniques include:
- Verbalized Uncertainty: Training the model to output phrases like "I do not have sufficient information to answer that" when its internal confidence score is low.
- MC Dropout: Using Monte Carlo Dropout at inference time to generate multiple outputs for the same prompt. High variance among these outputs suggests high model uncertainty.
Prompt Engineering and Inference-Time Strategies
These strategies are applied when the model is being used (at inference time) and are among the most powerful tools for developers.
-
Retrieval-Augmented Generation (RAG): RAG is a state-of-the-art technique for grounding LLM responses. Instead of directly asking the LLM a question, the user's query is first used to search a private, curated knowledge base (e.g., a vector database of company documents). The most relevant documents are retrieved and injected into the LLM's prompt as context. The LLM is then instructed to answer the user's original question based solely on the provided context. This dramatically reduces hallucinations by forcing the model to rely on verified information rather than its internal parametric memory.
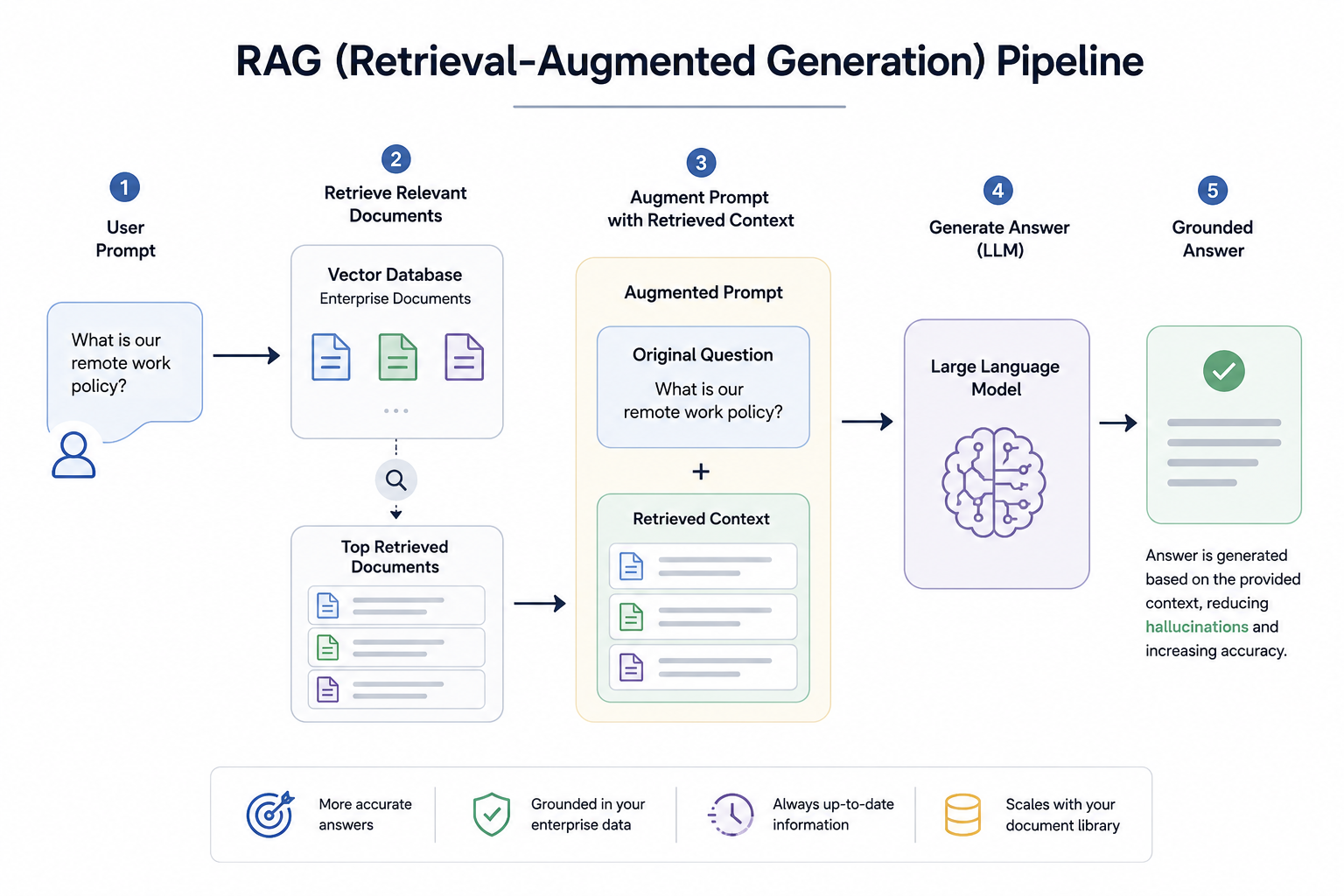
A simplified RAG workflow can be conceptualized as:
Become the Ai engineer who can design, build, and iterate real AI products, not just demos with an IIT Roorkee CEC Certification
AI Engineering Course Advanced Certification by IIT-Roorkee CEC
A hands on AI engineering program covering Machine Learning, Generative AI, and LLMs - designed for working professionals & delivered by IIT Roorkee in collaboration with Scaler.
Enrol Now- Chain-of-Thought (CoT) and Self-Correction Prompts: CoT prompting encourages the model to break down a problem into intermediate steps before providing a final answer. By instructing the model to "think step-by-step," its reasoning process becomes more explicit and less prone to logical leaps that lead to hallucinations. Self-correction extends this by having the model generate an initial response and then, in a subsequent step, critique its own answer for factual inaccuracies and revise it.
Advanced Techniques to Reduce Hallucinations in LLMs
For enterprise-grade applications where accuracy is non-negotiable, developers can implement more sophisticated, system-level controls.
Fact-Checking and Verification Layers
This involves building an external software module that acts as a post-processing step for the LLM's output. Before a response is shown to the end-user, this layer can:
- Extract Key Claims: Parse the LLM's generated text to identify verifiable factual claims (e.g., names, dates, statistics).
- Cross-Reference: Automatically query these claims against a trusted knowledge base, internal database, or a search engine API.
- Score and Annotate: Score the response for factual accuracy and either flag hallucinations for review or provide citations and corrections directly to the user.
Contrastive Decoding
Contrastive Decoding is an inference-time algorithm designed to improve the coherence and factual integrity of generated text. It operates by contrasting the output probabilities of a large, expert model with those of a smaller, "amateur" model. The final token selection is biased towards tokens that the expert model strongly prefers but the amateur model does not. This discourages the model from falling into generic, repetitive, and often factually shallow patterns (e.g., "as a large language model..."), pushing it towards more specific and substantive content.
Knowledge Graph Integration
Integrating LLMs with structured Knowledge Graphs (KGs) provides a robust framework for grounding. While RAG retrieves unstructured text, a KG provides structured entities and their relationships (e.g., (Company: Scaler, is_a, EdTech Platform)). An LLM can be trained to query the KG to retrieve facts, validate its own generated statements against the graph's structure, and ensure its outputs are consistent with a pre-defined, factual world model.
Evaluating and Measuring Hallucinations
To effectively reduce hallucinations in LLMs, it is essential to be able to measure them. There is no single, perfect metric; a combination of automated and human-in-the-loop evaluation is typically required.
| Metric / Method | Description | Pros | Cons |
|---|---|---|---|
| Self-Consistency | Generate multiple responses for the same prompt using a non-zero temperature. The most frequently occurring answer is considered the most likely to be correct. | Simple to implement; effective for reasoning tasks. Reduces reliance on a single, potentially flawed generation path. | Computationally expensive. Does not guarantee factual accuracy, only consistency in the model's most probable output. |
| Fact-Checking APIs | Use external, automated fact-checking services or search APIs to verify claims made in the generated text. | Provides objective, external validation. Can be automated in a CI/CD pipeline for model evaluation. | Reliant on the coverage and accuracy of the external API. May struggle with niche or newly emerging topics. |
| Human Evaluation (User Feedback) | Collect direct feedback from users (e.g., thumbs up/down, corrections) on the factual accuracy of model responses. | The gold standard for perceived quality and accuracy. Captures nuances that automated systems miss. | Slow, expensive, and difficult to scale. Subject to human subjectivity and bias. |
| Model-Based Evaluation | Use a more powerful "judge" LLM (like GPT-4) to evaluate the factual accuracy of a "candidate" LLM's output against a reference answer or source document. | More scalable than human evaluation. Can be prompted to check for specific types of hallucinations. | The "judge" LLM can also hallucinate. Performance is capped by the capabilities of the evaluator model. |
The Future of Trustworthy Generative AI
The field of AI is actively researching novel architectures and training paradigms to build inherently more factual models. Key areas of future development include:
- Self-Correcting Models: Models that can actively seek out new information to verify their statements, identify their own knowledge gaps, and correct their responses in real-time without human intervention.
- Traceability and Citations: Future models will likely be designed to provide precise citations for every claim they make, linking back to the specific documents or data sources used to formulate the answer.
- Compositional Generation: Instead of generating text in a single, monolithic pass, models may learn to compose answers by calling on specialized, verifiable "tools" or functions, such as a calculator, a database query engine, or a code interpreter.
Conclusion
Hallucinations in generative AI are a complex problem rooted in the probabilistic nature of LLMs and the imperfections of their training data. While they cannot be eliminated entirely, a systematic and multi-layered engineering approach can drastically reduce their frequency and impact. The key lies in shifting from a model-only paradigm to a systems-level one. By combining high-quality data, robust grounding techniques like RAG, careful prompt engineering, and continuous evaluation, developers can build AI applications that are not only powerful but also reliable and trustworthy. The journey to fully solve this challenge is ongoing, but these techniques represent the current best practices in the context of preventing hallucinations in generative AI models.
FAQs
Q1: Can hallucinations be completely eliminated in generative AI? No, not with the current generation of probabilistic models. Hallucinations are an inherent byproduct of how these models generate text by predicting the most likely next word. The goal of the techniques described is not complete elimination but significant mitigation—to reduce the frequency and severity of hallucinations to an acceptable level for a given application.
Q2: Is fine-tuning a model on my own data enough to prevent hallucinations? Fine-tuning on high-quality, domain-specific data can certainly help reduce hallucinations in an LLM, as it aligns the model's knowledge with your specific context. However, it does not solve the underlying problem. The model can still hallucinate about topics not covered in your data or misremember facts from its original pre-training. For high-stakes applications, fine-tuning should be combined with a grounding technique like RAG.
Q3: How does Retrieval-Augmented Generation (RAG) differ from traditional fine-tuning? Fine-tuning modifies the model's internal weights by training it on new data. It's a process of "teaching" the model new knowledge, which is computationally intensive and needs to be repeated as the knowledge evolves. RAG, in contrast, does not change the model's weights. It is an inference-time technique that provides the model with up-to-date, relevant information as context within the prompt, allowing it to "read" the information and formulate an answer. RAG is generally easier to keep current, as one only needs to update the external knowledge base.
Q4: What is the role of temperature and top-p sampling in controlling hallucinations? Temperature and top-p are sampling parameters that control the randomness of the model's output. A lower temperature (e.g., 0.1) makes the model more deterministic, causing it to pick the most likely tokens. This can reduce creative or nonsensical hallucinations but may also lead to more repetitive text. A higher temperature increases randomness, which can be good for creative tasks but may increase the risk of factual hallucinations. For factual Q&A systems, it is generally recommended to use a low temperature to prioritize the most probable (and often most factual) output.