Distributed Training with PyTorch
Overview
With the advent of advanced hardware devices and increased computing support, deep learning has seen massive success in recent years. However, training the models is the key component of building systems based on deep neural networks. Moreover, given the billion parameter architectures released by the industry and academia today, it requires heavy computation.
To this end, the most popular deep learning libraries like PyTorch provide exceptional support to utilize all of the available hardware support for training and building deep neural models. This article introduces PyTorch distributed training and demonstrates how the PyTorch API can conduct deep learning using parallel computation distributed across multiple GPUs.
Introduction
Often, it is difficult to train our model on a single hardware device for many reasons, like slow training speed, the inability of the GPUs to support the required batch size of data at once, or the heavy size of the models.
In such cases, we could leverage distributed training to spread our workload across multiple devices, thus allowing us to conduct fast and efficient calculations.
Let us look at what distributed training is, after which we will learn about PyTorch distributed training.
What is Distributed Training?
Distributed training is a computing technique in which the workload to train a deep learning model is split up among multiple mini processors called worker nodes rather than being conducted on a single device.
The model's training then occurs parallelly in these mini-processors, speeding up the overall training process.
Distributed training can be categorized into two broad types -
- data parallelism
- model parallelism.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Data Parallelism
In data parallelism, a certain number of data partitions are made equal to the number of nodes, and the model instance is replicated on each node. Each node operates on its subset of the data.
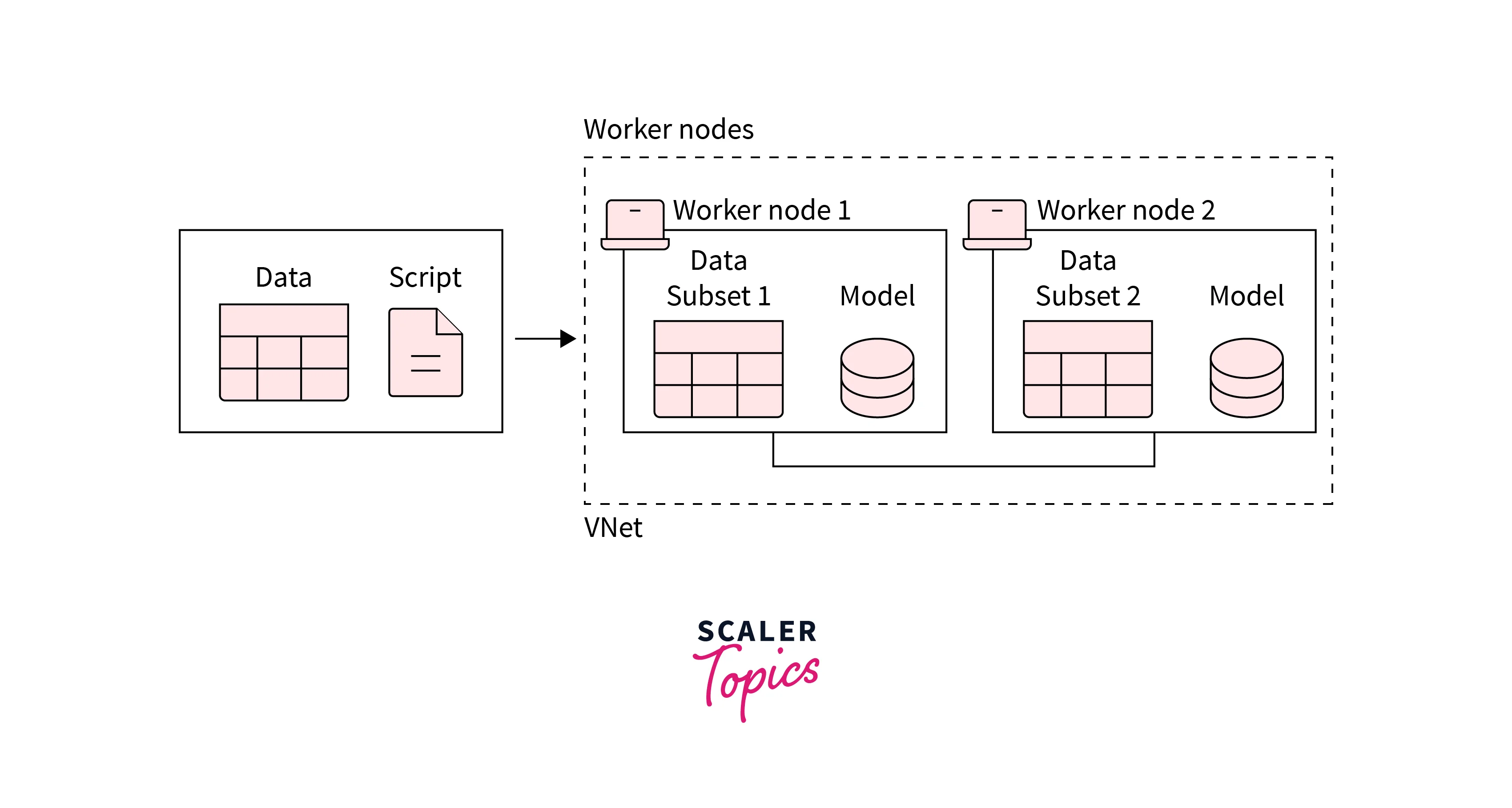
This means that each node should have enough capacity for the model to fit on it. Each node then computes its errors corresponding to the data it operates on and uses them to update the model parameters. These updates need to be communicated to other nodes so that worker nodes synchronize the model parameters, or gradients, at the end of a single computation - it is done to ensure that a consistent model is being trained.
Model Parallelism
On the other hand, model parallelism segments the model into different parts sent to different GPUs. This is handy when the full model is too big to fit on a single GPU.
Each of the GPUs runs on the same data, and different GPUs need to synchronize the shared parameters once for each forward or backward propagation step.
Each worker node operates on a particular model segment on the same training data.
We also need to ensure that the data is moved through the corresponding GPU during the forward pass.
A simple PyTorch snippet to split a model across two GPUs is as follows -
PyTorch Distributed Training
In this section, we will look at how PyTorch distributed training can be used to accelerate the training of deep learning models. We will be focussing on splitting batches of data across multiple GPUs. In case the computer has access to multiple GPUs, we want to make use of all of the computation power provided by the GPUs rather than being able to use only a single GPU at a time. To split the workload across several GPUs, PyTorch provides several ways, two of which (require a single machine) are as follows -
-
Use single-machine multi-GPU DataParallel API to use multiple GPUs on a single machine - this can be used to speed up training with minimal code changes.
-
Use single-machine multi-GPU DistributedDataParallel API - this further speeds up training but requires writing more code to set it up.
Using torch.nn.DataParallel
We use nn.DataParallel to implement data parallelism at the module level. It parallelizes the application of the given module by splitting the input across multiple GPUs by chunking in the batch dimension.
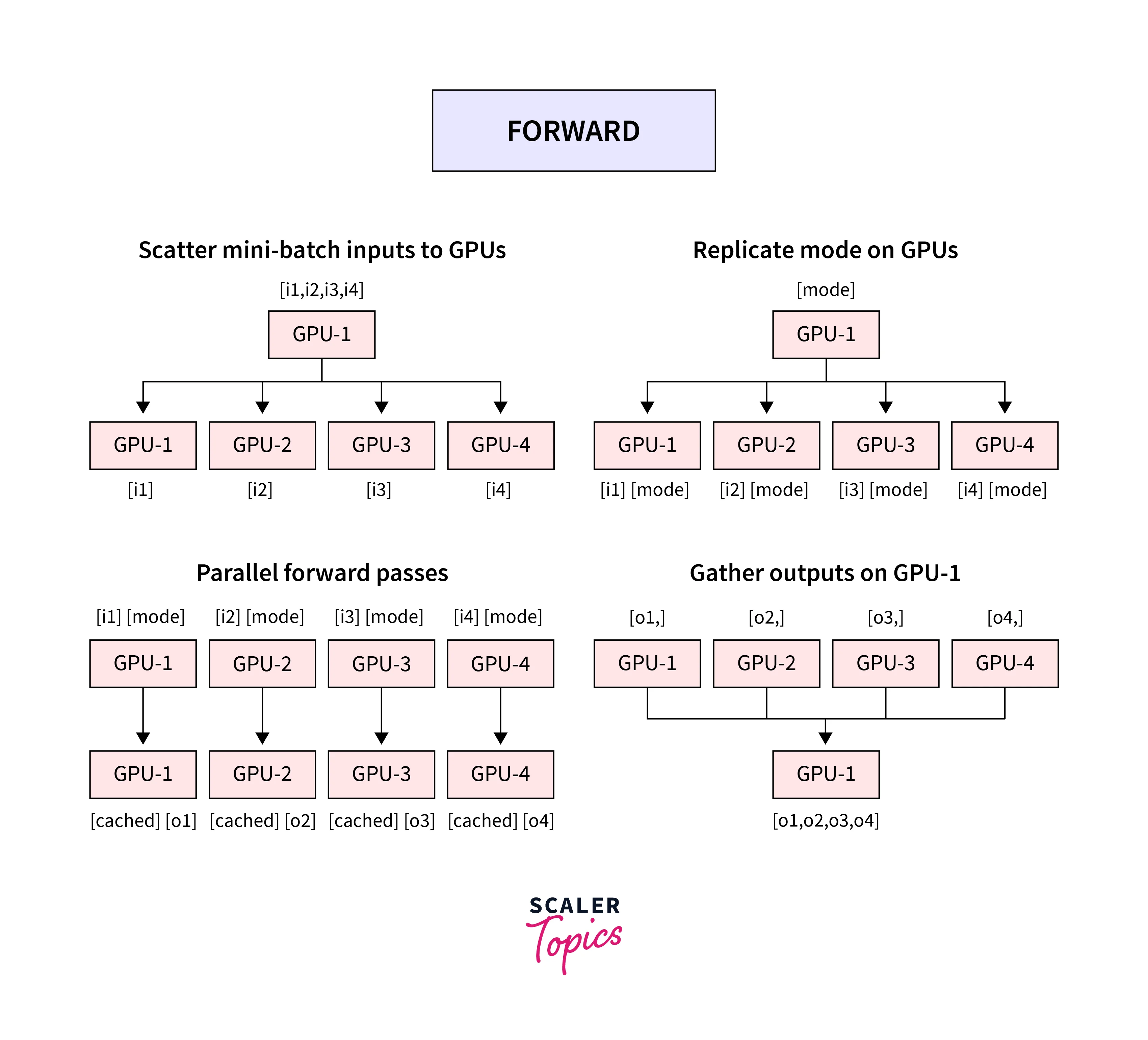
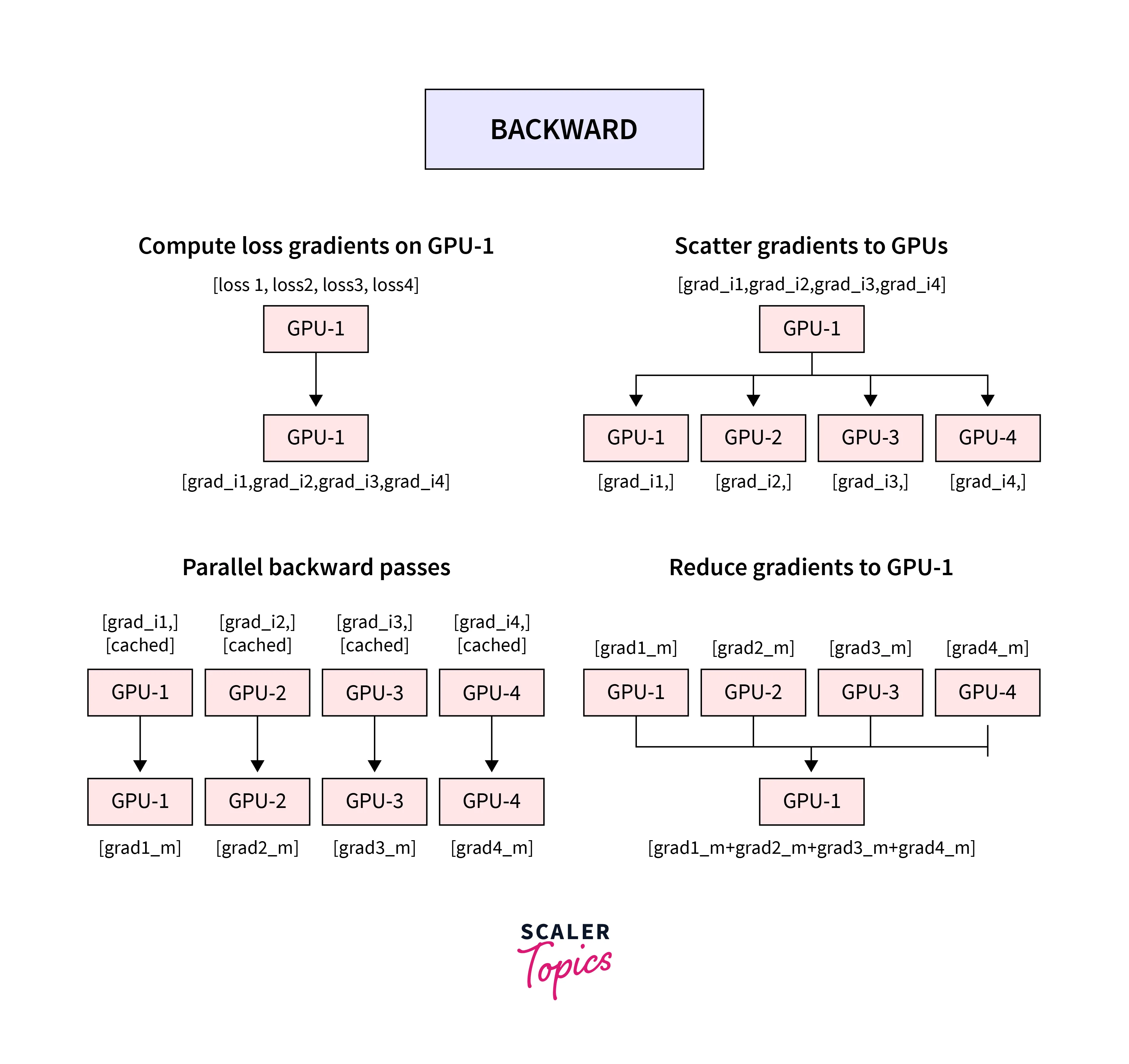
In the forward pass, each device receives a replica of the module, and thus each replica on separate devices handles a part of the input. During the backward pass, gradients from each device are accumulated into the original module to update the model weights to get the updated model on the master GPU, which In the next iteration, is again replicated on each GPU device.
The syntax of the DataParallel is as follows -
-
module (Module) – module to be parallelized
-
device_ids (list of python
or torch.device) – CUDA devices (default: all devices) -
output_device (int or torch.device) – device location of the output
All it takes to implement DataParallel in PyTorch is a single line of code, like so -
Turn Learning into Career Growth
Using torch.nn.parallel.DistributedDataParallel
Unlike nn.DataParallel, which uses multithreading in a single process, DistributedDataParallel uses multi-processing to spawn separate processes on each of the GPUs hence leveraging the full parallelism support across GPUs.
The following steps are to be followed to implement DistributedDataParallel in PyTorch -
-
Wrap the model instance in torch.nn.Parallel.DistributedDataParallel.
-
Set up the Dataloader to use distributedSampler. This is required to distribute the data efficiently across all GPUs. We can use the torch.utils.data.Distributed.DistributedSampler API for it.
-
DDP relies on c10d ProcessGroup for communications. Hence, applications must create ProcessGroup instances before constructing DDP.
-
PyTorch offers different backends viz NCCL, GLOO, MPI, and TCP for distributed training. As a rule of thumb, according to PyTorch official docs, NCCL is recommended for distributed training over GPUs and GLOO for distributed training over CPUs.
-
use torch.distributed.launch to Launch the separate processes on each GPU.
The following example shows a minimum snippet to demonstrate the use of DistributedDataParallel in PyTorch -
The commented line is used in case a single node over a GPU cluster exists. To use a multi-node setup, we need to select a node as the master node and provide the master_addr argument while setting up the launch utility.
Suppose we have 2 nodes with 4 GPUs each, and the first node with the IP address 193.178.1.1 is the master node. We will need to start the launch script on each node separately, like so -
On the first node -
On the second node, use -
Note - Certain Layers, such as BatchNorm, use descriptive running stats from the whole batch of data in their computations; these can not carry out the operations independently on each GPU using only a split of the data. To this end, PyTorch provides SyncBatchNorm as a replacement module for BatchNorm that can calculate the batch statistics using the data on all GPUs; that is, it can use the whole batch spread across GPUs for its computation. The following sample demonstrates the use of SyncBatchNorm in PyTorch.
torch.nn.parallel.DistributedDataParallel vs torch.nn.DataParallel
-
torch.nn.DataParallel relies on a single-process multithreaded design, keeping the main process on one GPU and running a different thread on the other available GPUs. Since Python's interpreter is based on GIL (Global Interpreter Lock), multithreading and hence DataParallel in PyTorch suffers from issues preventing us from going fully parallel.
-
DistributedDataParallel, on the other hand, uses multi-processing to create a process for each GPU. Thus each GPU has its dedicated process, which avoids the performance overhead caused by the GIL of the Python interpreter.
-
With torch.nn.parallel.DistributedDataParallel or torch.distributed (that we will look at next), each process maintains its optimizer and performs a complete optimization step with each iteration.
This means that the gradients are gathered together and averaged across processes, thus the same for every process. No parameter broadcast step is needed, thus reducing the time spent transferring tensors between nodes.
-
With multi-processing, each process contains an independent Python interpreter, eliminating the extra interpreter overhead and “GIL-thrashing” that comes from multithreading in a single process, model replicas, or GPUs from a single Python process.
Accumulating Gradients
This technique cannot be taken as a strict example of parallel training per se. in this. Instead, we leverage that the gradients from all backward calls in PyTorch are accumulated by default - using this, we could perform the optimizer step only after gradients from a certain number of mini-batches are accumulated from several forwards passes.
This is useful to implement when the desired batch size is too big to fit on a single GPU at once, in which case we could split a mini-batch into further mini-batches that could be used to forward propagate through the network and only after all the mini-batches are done processing we make the optimizer take a step using the accumulated gradients from the forward calls.
The PyTorch implementation is simple to follow -
Here we want to be able to update the model parameters only after a batch size of 256 is processed by the model, but GPU limitations allow only a batch size of 64 to fit in the memory at once. Hence we accumulate the gradients from several backward calls before getting the optimizer to take a step.
This method does not require multiple GPUs as all the computation is done on a single GPU in succession, which also means that it takes a significant amount of time for the model to train using this technique.
Utility Functions
While inferencing from the model or during the model evaluation phase, we need to be able to collect the current batch statistics, such as losses, accuracy, etc., from all the GPUs devices and collate them together at one machine to log.
We will now discuss some functionality provided by PyTorch to sync variables across GPUs -
- torch.distributed.gather(input_tensor, gather_list, dst): Collect the specified input_tensor from all devices and place them on the dst device in gather_list.
- torch.distributed.all_gather(tensor_list, input_tensor) : used to Collect the specified input_tensor from all devices and place them in tensor_list variable on all devices.
- torch.distributed.reduce(input_tensor, dst, reduce_op=ReduceOp.SUM): used to Collect the input_tensor from all devices and reduce them using a specified reduce operation such as sum, mean, etc., while placing The final result on the dst device.
- torch.distributed.all_reduce(input_tensor, reduce_op=ReduceOp.SUM): functions Same as reduce operation, but the final result is copied to all the devices.
PyTorch torch.distributed
Having studied the above two APIs for PyTorch distributed training, let us learn more about building distributed training applications using PyTorch using the torch.distributed package.
The torch.distributed package provides PyTorch support and communication primitives for multiprocess parallelism across several computation nodes running on one or more machines, enabling researchers and practitioners to parallelize their computations across processes and cluster machines easily. The class torch.nn.parallel.DistributedDataParallel() we learned about above builds on this functionality to provide synchronous distributed training as a wrapper around any PyTorch model instance.
It supports multiple network-connected machines and requires the user to explicitly launch a separate copy of the main training script for each process.
The torch.distributed.init_process_group() function initializes the package.
Below are the three main features of the torch.distributed as of PyTorch v1.6.0 :
-
Distributed Data-Parallel Training (DDP) is a single-program multiple-data training paradigm. As we learned above, With DDP or torch.nn.parallel.DistributedDataParallel, the model is replicated on every process. Therefore, every model replica will be fed a different set of input data samples. In addition, DDP takes care of gradient communication to keep the different model replicas on separate processes in sync and overlaps it with the gradient computations to speed up training.
-
RPC-Based Distributed Training (RPC) supports general training structures that cannot fit into data-parallel training, such as distributed pipeline parallelism, parameter server paradigm, or combinations of DDP with other such paradigms.
-
The collective Communication (c10d) library offers to send tensors across processes within a group. It offers collective communication APIs and P2P communication APIs. DDP (via collective communications) and RPC (via P2P communications) are built on c10d this API is useful for such scenarios where applications would like fine-grained control since it might be desirable to compute the average values of all model parameters after the backward pass instead of using DDP to communicate gradients.
Conclusion
The following article was an introduction to PyTorch distributed training. We learned about the following points -
- We first understood what distributed training is and why it is required to build and train large deep neural networks.
- After this, we learned to accumulate gradients in PyTorch for scenarios when a single GPU is available and the specific batch size is too big to fit at once on the device.
- Next, we learn about PyTorch distributed training using the two APIs that support single machine multiple GPU training called torch.nn.parallel.DistributedDataParallel and torch.nn.DataParallel while learning about the mechanics of each via code samples in PyTorch and the differences between the two.