PyTorch API for Distributed Training
Overview
As the field of deep learning grows in terms of the sizes of the architectures, the number of model parameters, and the data required to train them, computational efficiency is the foremost factor that needs to be considered before setting the pipeline for training. To this end, PyTorch has dedicated APIs to leverage multiple GPUs for training neural networks. In this article, we will be studying PyTorch distributed training using DataParallel and DistributedDataParallel.
Pre-Requisites
The article assumes that the reader is familiar with the following -
- Defining custom dataset classes in PyTorch.
- Defining custom model architecture classes in PyTorch.
- Writing custom training loops in PyTorch.
Introduction
With the advent of advanced hardware devices and increased computing support, deep learning has seen massive success in recent years. Training the models is the key component of building systems based on deep neural networks, and it requires heavy computation given the billion parameter architectures being released by the industry and academia today.
Often, it is difficult to train our model on a single hardware device for many reasons, like slow training speed, the inability of the GPUs to support the required batch size of data at once, or the heavy size of the models.
Even when training on a single GPU is possible, we want to leverage all the available hardware to train our models efficiently.
In such cases, we could leverage distributed training to spread our workload across multiple devices, thus allowing us to conduct fast and efficient calculations.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Commonly Used APIs in the torch. distributed
The torch.distributed package provides PyTorch support and communication primitives for multiprocess parallelism across several computation nodes running on one or more machines, enabling researchers and practitioners to parallelize their computations across processes and clusters of machines easily.
Let us first understand some of the basic APIs provided by the package.
Send and Recv API
Point-to-point communication is defined as the transfer of data from one process to another and is useful when we want more fine-grained control over the communication between our worker processes.- send and recv functions are what enable this, as can be seen in the code snippet below -
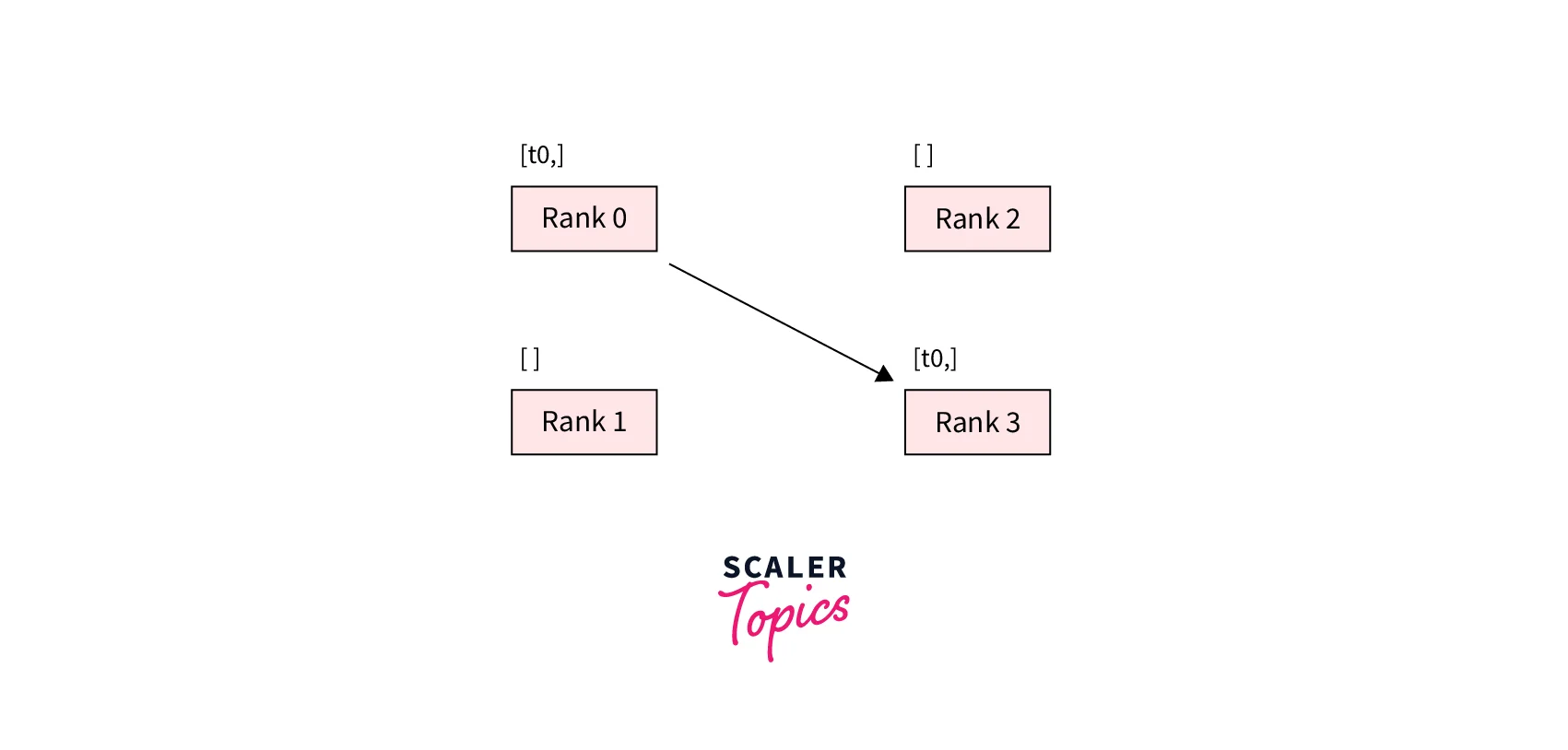
send/recv functions are blocking, meaning both processes stop until the communication is completed.
On the other hand, their immediate counterparts called isend and irecv which we will look at next are different.
isend and irecv API isend and irecv are counterparts of send and rcv and, unlike them, are non-blocking in nature, which means that the script continues its execution and the methods return a Work object upon which one can choose to wait(), as can be seen in the code snippet below -
reduce, all_reduce, gather, all_gather, … (APIs listed here) A group is defined as a subset of all our processes. To communicate across all processes in a group, PyTorch offers several functions executed on all processes by default and known as collectives. For example, the dist.all_reduce(tensor, op, group) collective can be used to obtain the sum of all tensors on all processes.
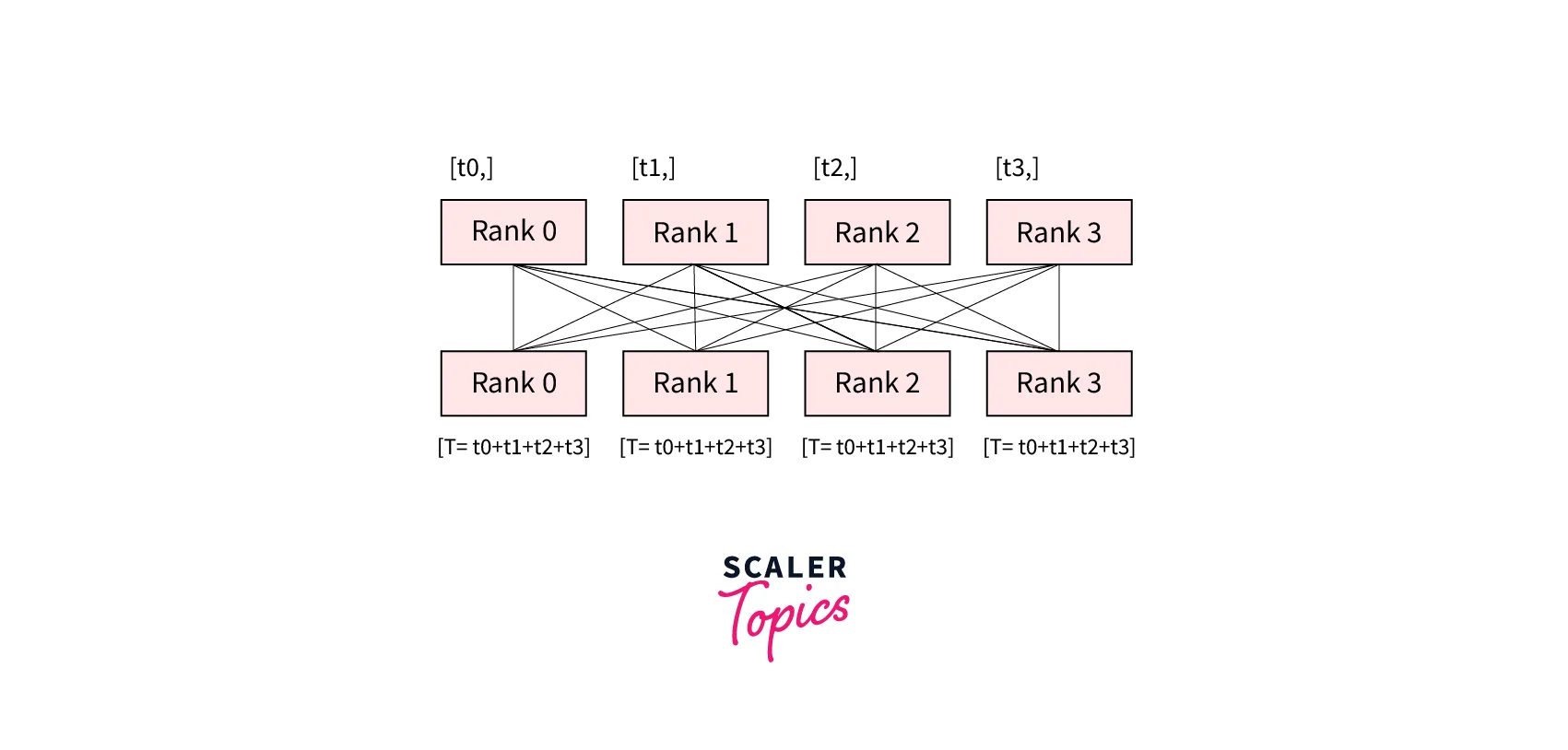
Other such collectives are as follows -
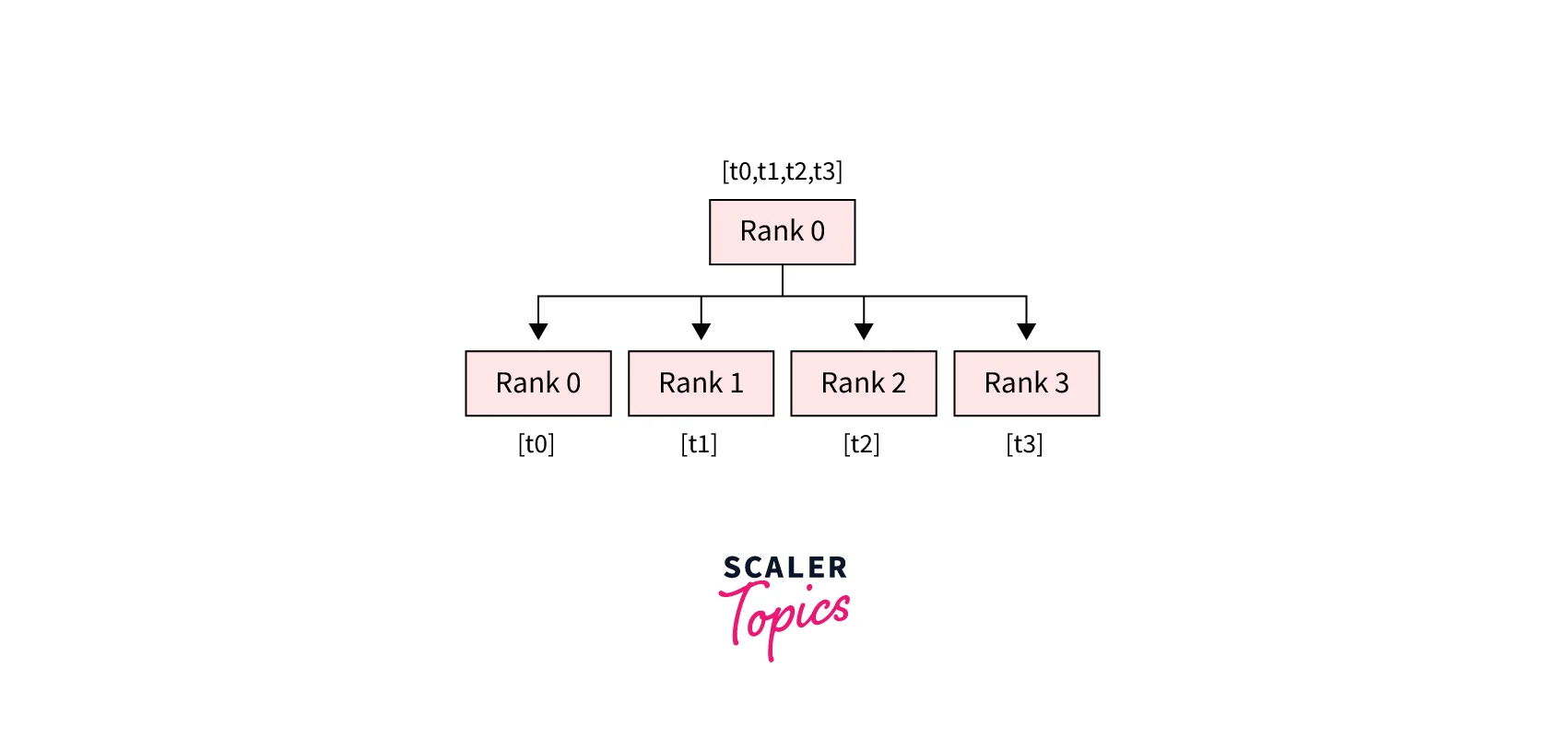
- dist.scatter(tensor, scatter_list, src, group): Copies the ith tensor scatter_list[i] to the ith process.
- dist.gather(tensor, gather_list, dst, group): Copies tensor from all processes in dst.
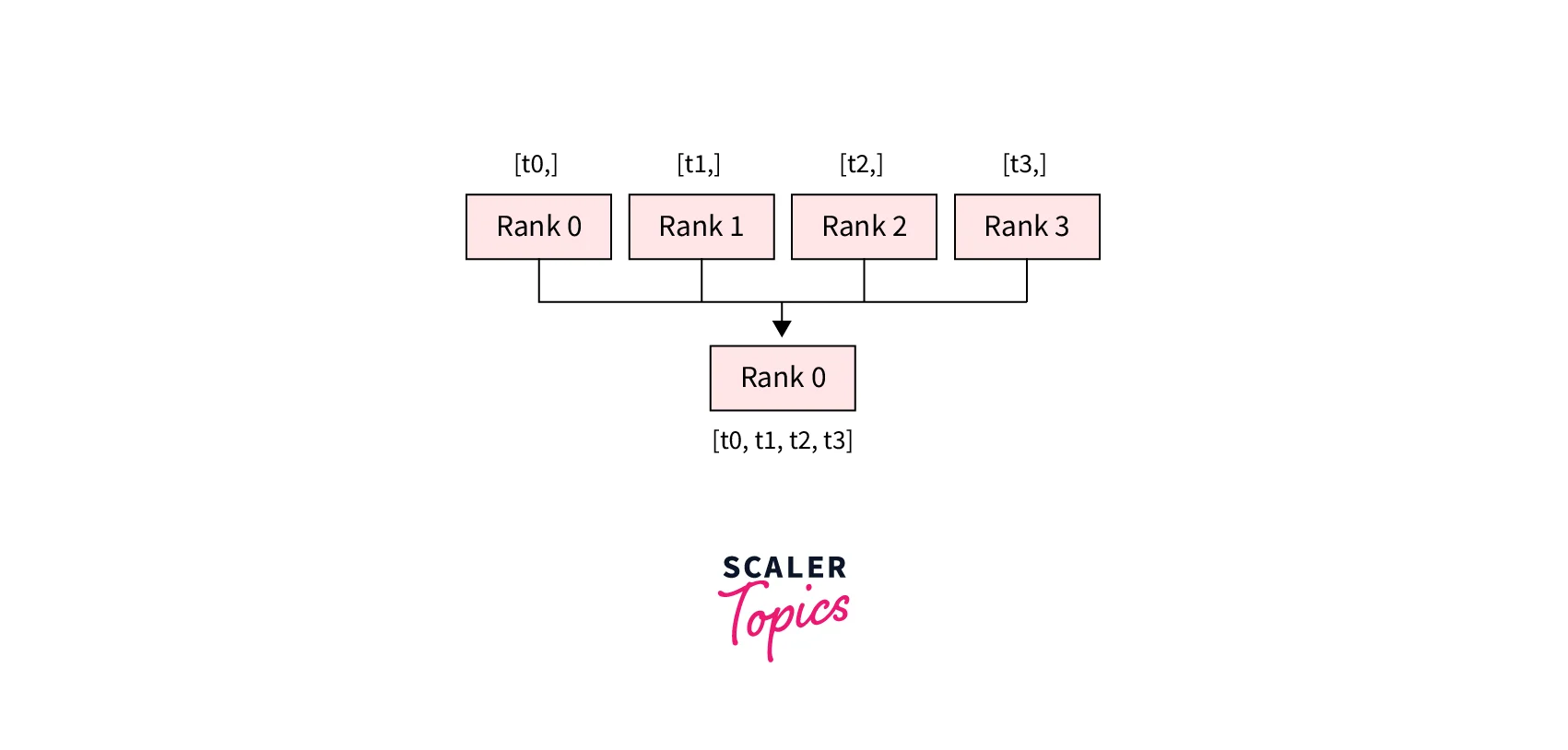
- dist.reduce(tensor, dst, op, group): Applies op to every tensor and stores the result in dst.
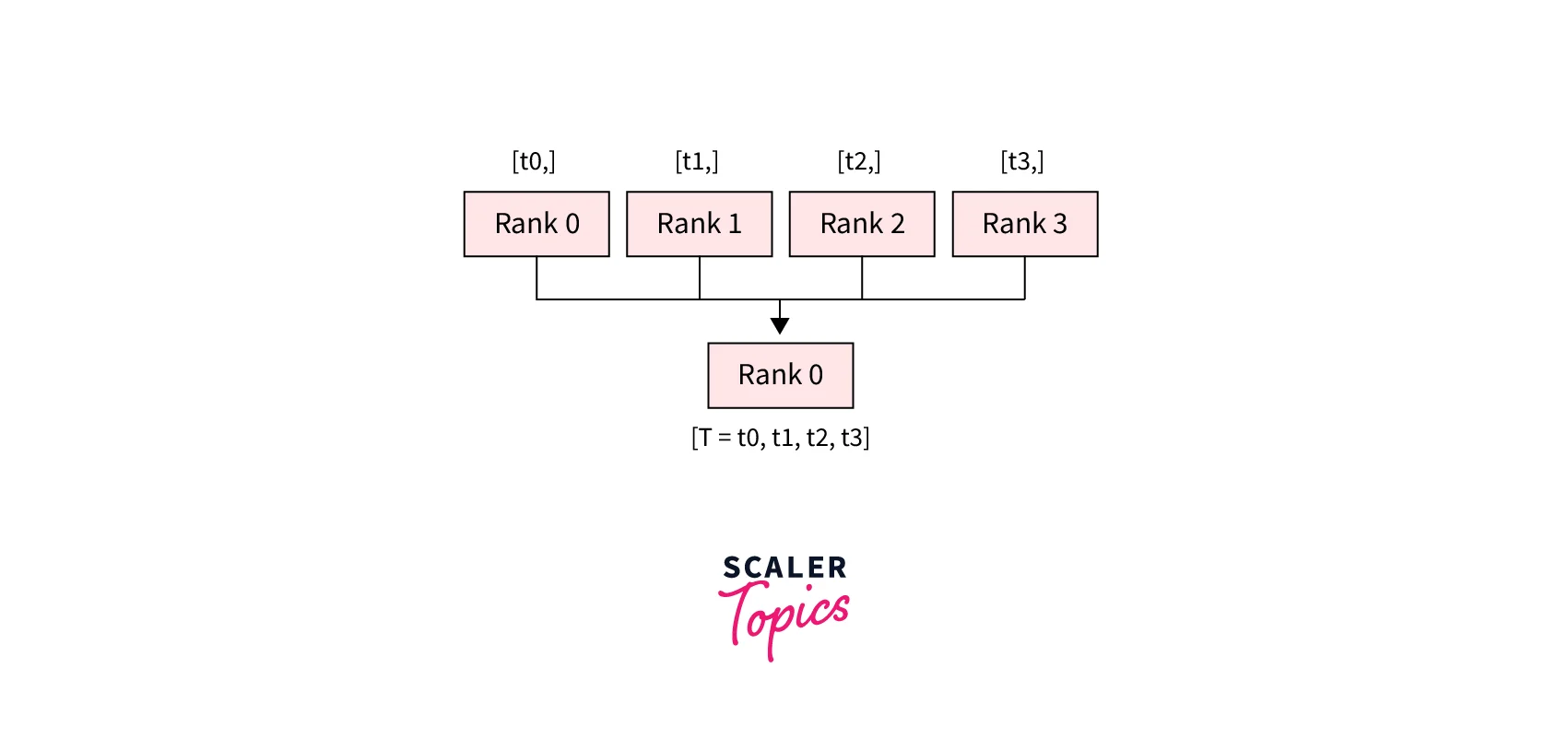
- dist.broadcast(tensor, src, group): Copies tensor from src to all other processes.
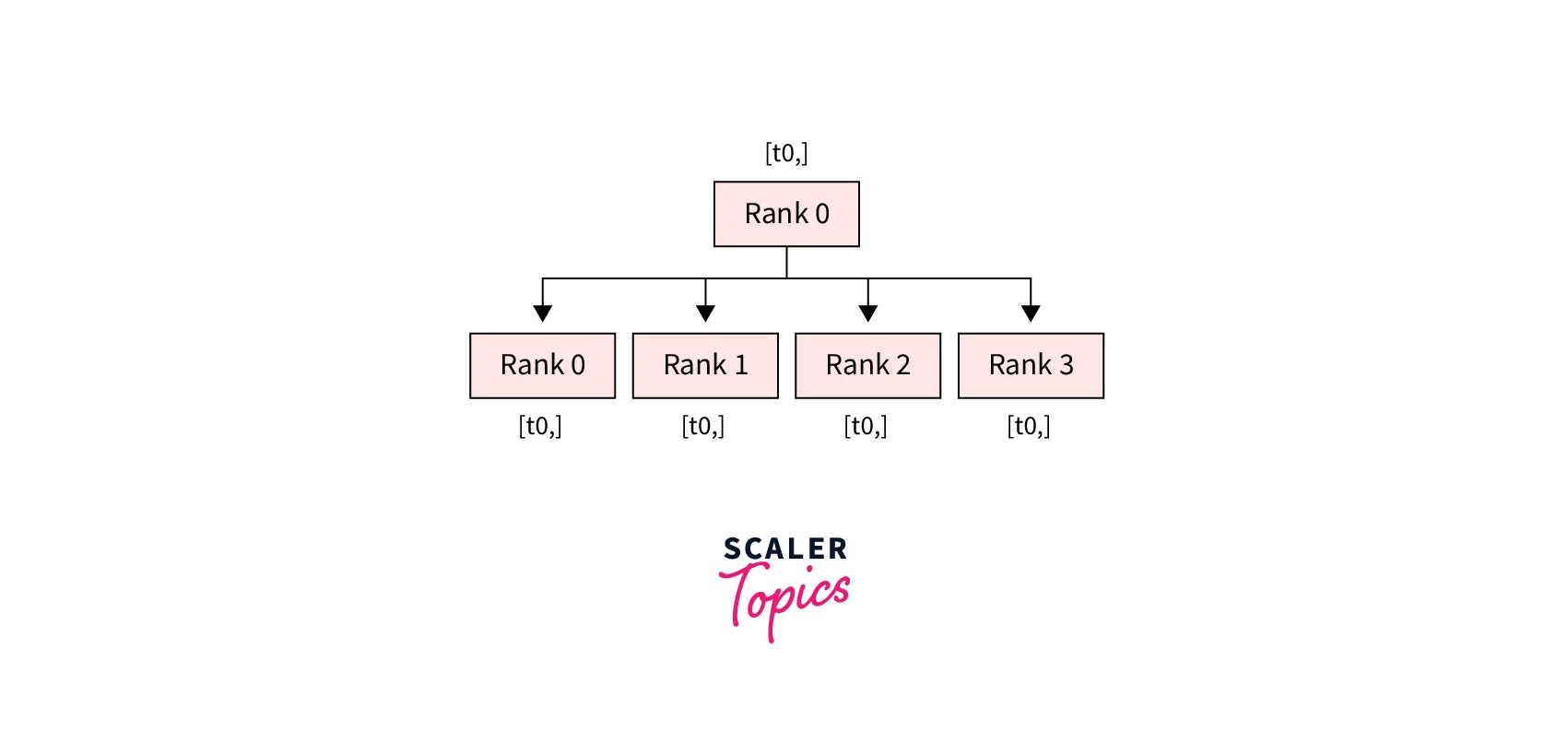
- dist.all_gather(tensor_list, tensor, group): Copies tensor from all processes to tensor_list, on all processes.
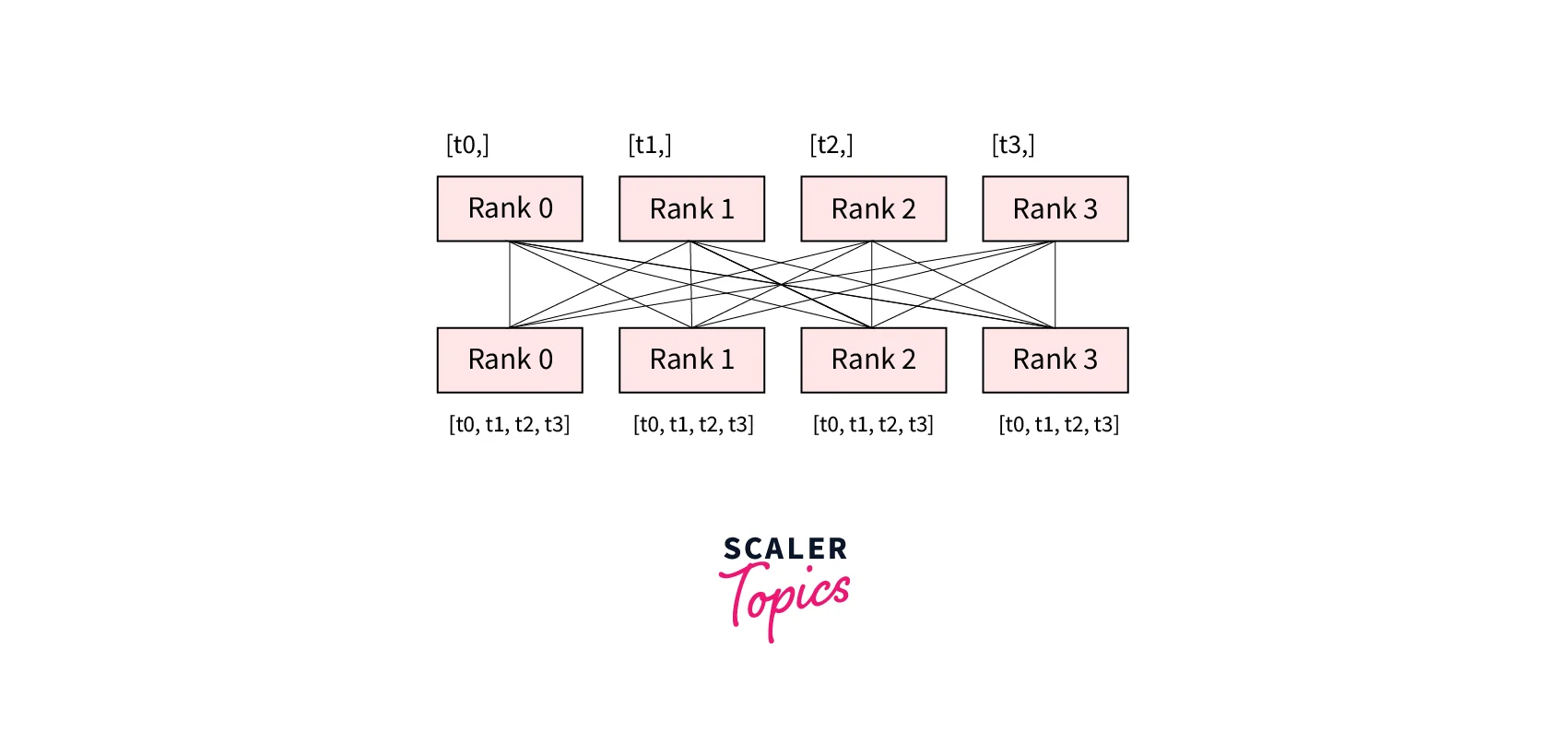
- dist.barrier(group): Blocks all processes in a group until each one has entered this function.
PyTorch Distributed Training
Before understanding PyTorch distributed training, let us first briefly revise what a training loop in PyTorch looks like.
A typical training loop for a deep-learning model looks like the following -
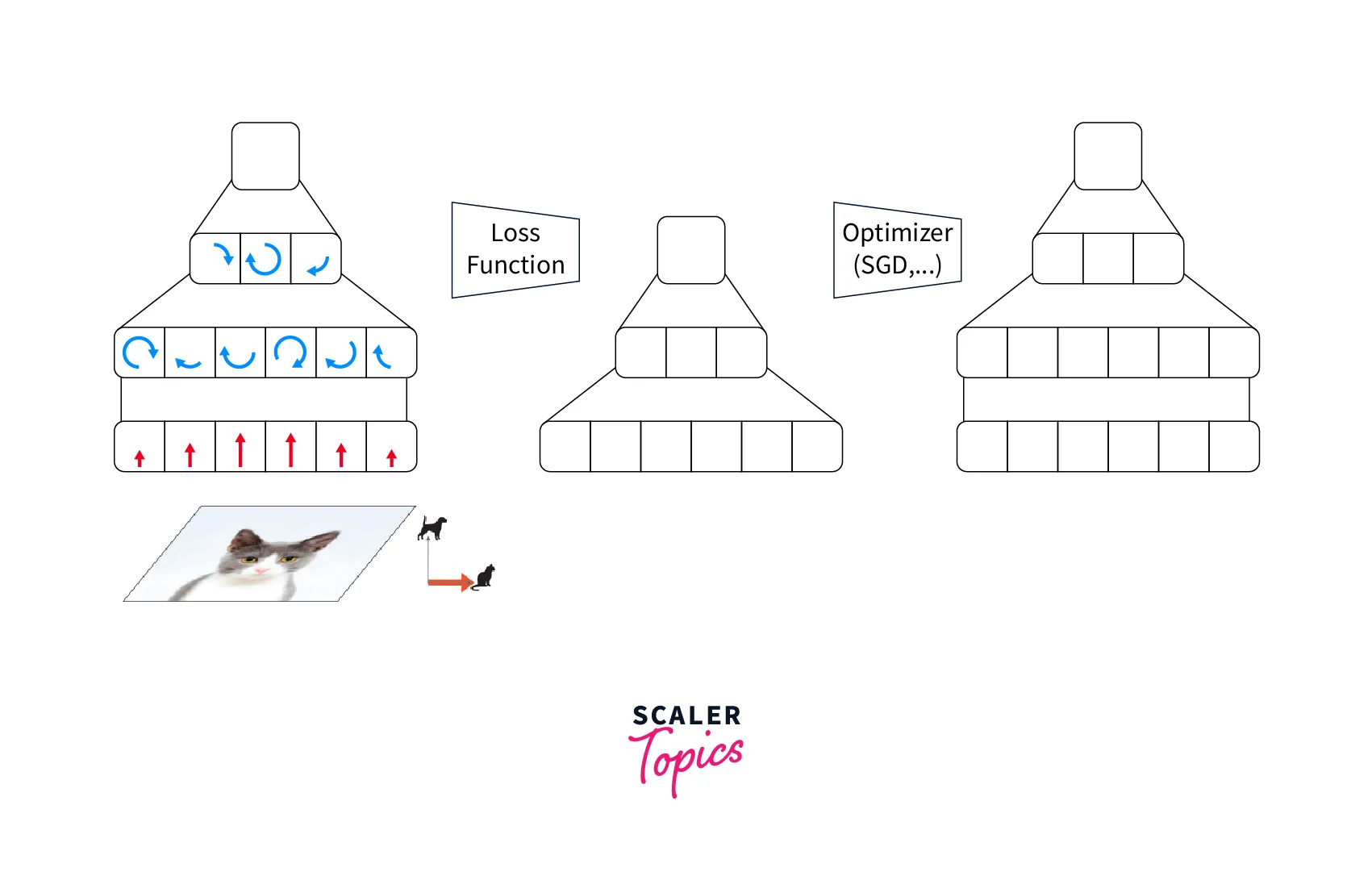
The four major steps are as laid below -
- The neural network model processes the forward pass input.
- The loss function is calculated - compare the model predictions with the true labels.
- The backward pass - use the loss calculated in step 2 to calculate the gradients for each parameter using back-propagation.
- Optimizer step - update The parameters based on the calculated gradients.
Turn Learning into Career Growth
DataParallel
With torch.DataParallel, the training workload is distributed over multiple GPUs on a single machine. The following representation shows in detail how DataParallel works -
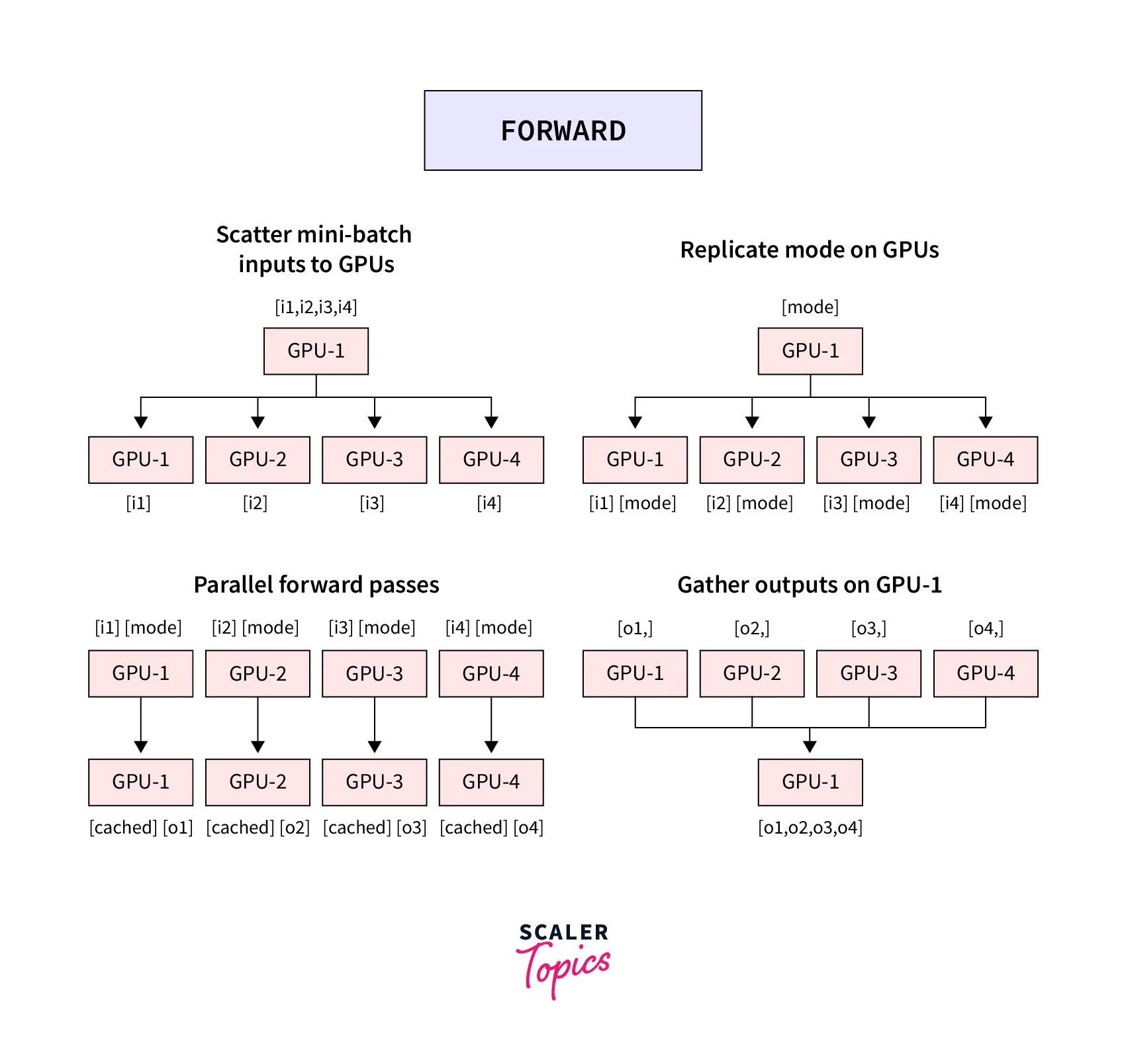
In steps, the pipeline looks like this -
- First, the mini-batch is split on GPU:0
- After this, min-batches are split and moved to all different GPUs
- The model is copied to all GPUs
- Forward pass is performed on all the different GPUs
- Compute loss using the model outputs on GPU:0, and send the losses over to the different GPUs. Calculate the gradients of the loss wrt model parameters on each GPU.
- Sum up the calculated gradients on GPU:0 and use the optimizer to update the model parameters on GPU:0
Let us next see an example of the torch.nn.DataParallel API.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Example of DataParallel
In this section, we will build a convolutional neural network to predict the images in the MNIST dataset and train the model by using the torch.nn.DataParallel API.
For this, let us first import all the dependencies like so -
We will now define our custom model class to build a very simple CNN architecture with ReLU activations and max pooling layers, like so -
After this, let us define a simple function called to train for training the model using a torch. nn.DataParallel, like so -
DistributedDataParallel
DistributedDataParallel uses multi-processing to spawn separate processes on each of the GPUs hence leveraging the full parallelism support across GPUs. This means the machine has a single process per GPU, and each process controls each model copy. The GPUs can be on the same node or across multiple nodes.
The important point to note here is that "Only the gradients are passed between the processes/GPUs."
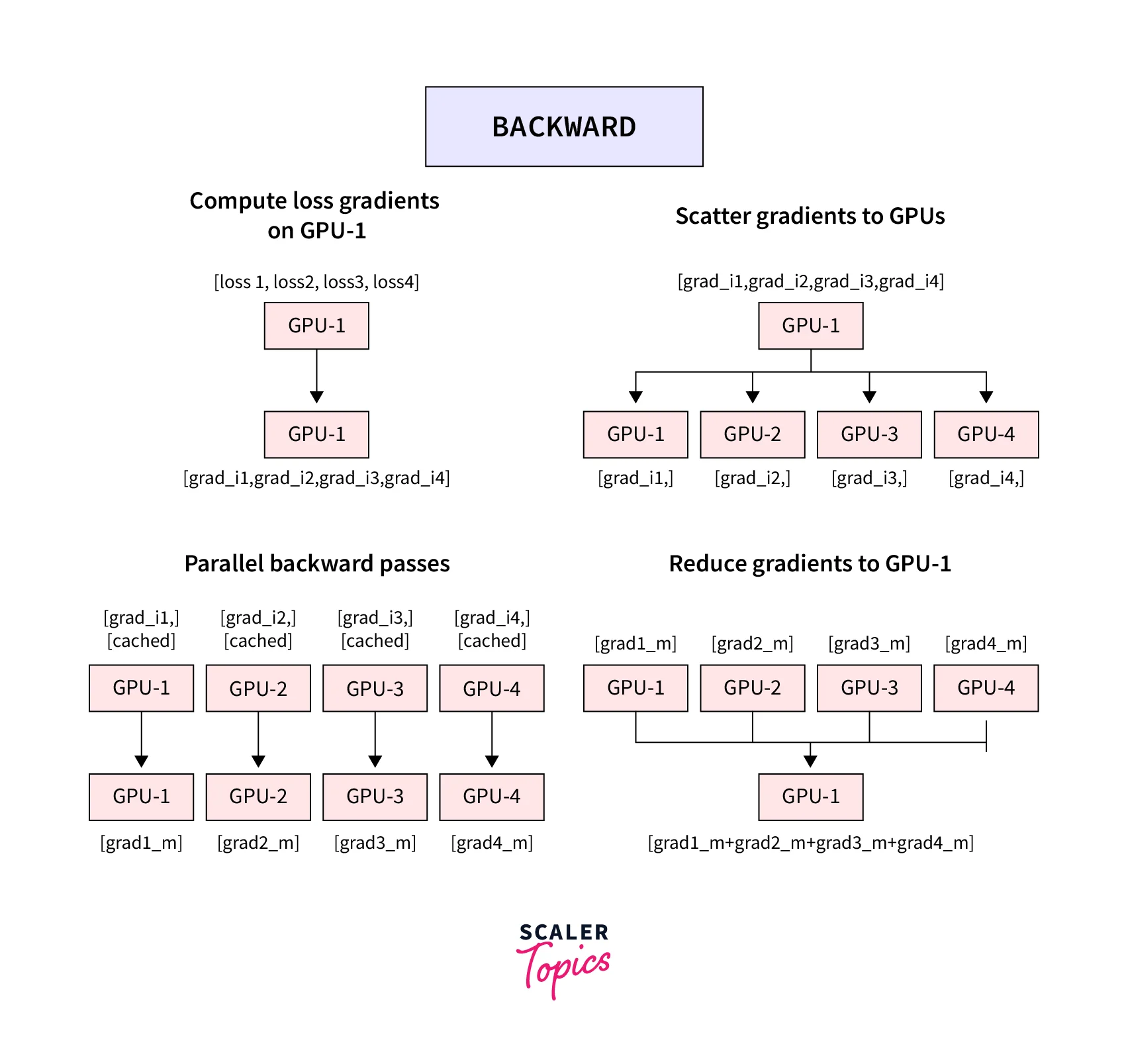
During training, each process loads its mini-batch and passes it to the GPU it is on. Each GPU performs its forward pass, and then the gradients are all-reduced across the GPUs.
Since gradients for each layer do not depend on previous layers, the gradient all-reduce can be calculated concurrently with the backward pass. Hence, at the end of the backward pass, every node receives the averaged gradients, so the model weights stay synchronized. This mode can also be used for single-machine multi-GPUs.
The steps involved in implementing DistributedDataParallel in PyTorch are as follows -
-
Initialize the backend (a full list of backend compatibility is available here. The three available backends are 'nice', 'gloo', and 'mpi' torch.distributed.init_process_group(backend="nccl")
-
Configure the GPU of each process local_rank = torch.distributed.get_rank() torch.cuda.set_device(local_rank) device = torch.device("cuda", local_rank)
-
Use DistributedSampler to distribute data to each GPU from torch.utils.data.distributed import DistributedSampler sampler = DistributedSampler(dataset) data_loader = DataLoader(dataset=dataset, batch_size=batch_size, sampler=sampler)
-
Move the model to each GPU model.to(device)
-
Wrap up the model if the torch. cuda.device_count() > 1: model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank)
Let us code an example of DistributedDataParallel.
Example of DistributedDataParallel
We will be coding all the above steps in the example below. First, we import all the dependencies and define a custom dataset class and a custom model class using the base classes nn. Module and torch.utils.data.Dataset.
We will now instantiate our dataset and the model and use the DistributedDataParallel to train the model, like so -
That was about how DistributedDataParallel can train the model across GPU devices. Let us now look at the main differences between DataParallel and DistributedDataParallel.
Difference Between DataParallel and DistributedDataParallel
-
torch.nn.DataParallel relies on a single-process multithreaded design, keeping the main process on one GPU and running a different thread on the other available GPUs. Since python's interpreter is based on GIL (Global Interpreter Lock), multithreading and hence DataParallel in PyTorch suffers from issues preventing us from going fully parallel.
-
DistributedDataParallel, on the other hand, uses multi-processing to create a process for each GPU. Thus each GPU has its dedicated process, which avoids the performance overhead caused by the GIL of Python interpreter.
-
With torch.nn.parallel.DistributedDataParallel or torch.distributed (that we will look at next), each process maintains its optimizer and performs a complete optimization step with each iteration.
This means that the gradients are gathered together and averaged across processes and are thus the same for every process; this means that no parameter broadcast step is needed, thus reducing the time spent transferring tensors between nodes.
-
With multi-processing, each process contains an independent Python interpreter, eliminating the extra interpreter overhead and “GIL-thrashing” from multithreading in a single process, model replicas, or GPUs from a single Python process.
Conclusion
This article was a hands-on tutorial to familiarize the reader with PyTorch distributed training. Let us quickly review what we studied in this article -
-
We looked at the APIs provided by the torch.distributed package, and understood the function of each.
-
We then learned about PyTorch distributed training by understanding the two major ways of implementing distributed training in PyTorch, called DataParallel and DistributedDataParallel.
-
We also implemented these two modes in PyTorch by coding up examples of both these modes and also walked through the major points of difference between DataParallel and DistributedDataParallel.