Introduction to PyTorch Lightning
Overview
PyTorch Lightning is an open-source Python library that makes it easier to conduct deep learning research by decoupling the research side from the engineering side.
It eliminates the need for writing a lot of deep learning boilerplate code and enables developers and researchers from academia to build systems that are readable, reproducible, and robust while enabling them to focus on what is the most important in terms of research. In this article, we will introduce PyTorch Lightning, focussing on these aspects of building scalable software systems while highlighting why PyTorch Lightning is a useful library to include in any deep learning practitioner's toolkit.
Introduction to Pytorch Lightning
PyTorch is one of the most popular deep learning libraries that is heavily used in industry and academia and is often the preferred choice by academicians and researchers for conducting deep learning research or for building deep learning-based systems due to its easy-to-use pythonic API that offers just the right amount of abstraction and accessibility to the most common low-level layers used in most deep learning architectures.
Despite its highly pythonic interface with easy access to low-level components that enable practitioners to implement novel architectures in it super easily, it still includes writing a lot of boilerplate code to leverage advanced things like multi-GPU training, 16-bit precision, and TPU training.
"PyTorch Lightning" does away with just that.
PyTorch Lightning is a high-level interface for PyTorch that organizes PyTorch code in a manner that is easy to maintain and scale and is also supported on distributed hardware in a much easier way compared to how it is supported in plain PyTorch, thus keeping the model's hardware agnostic.
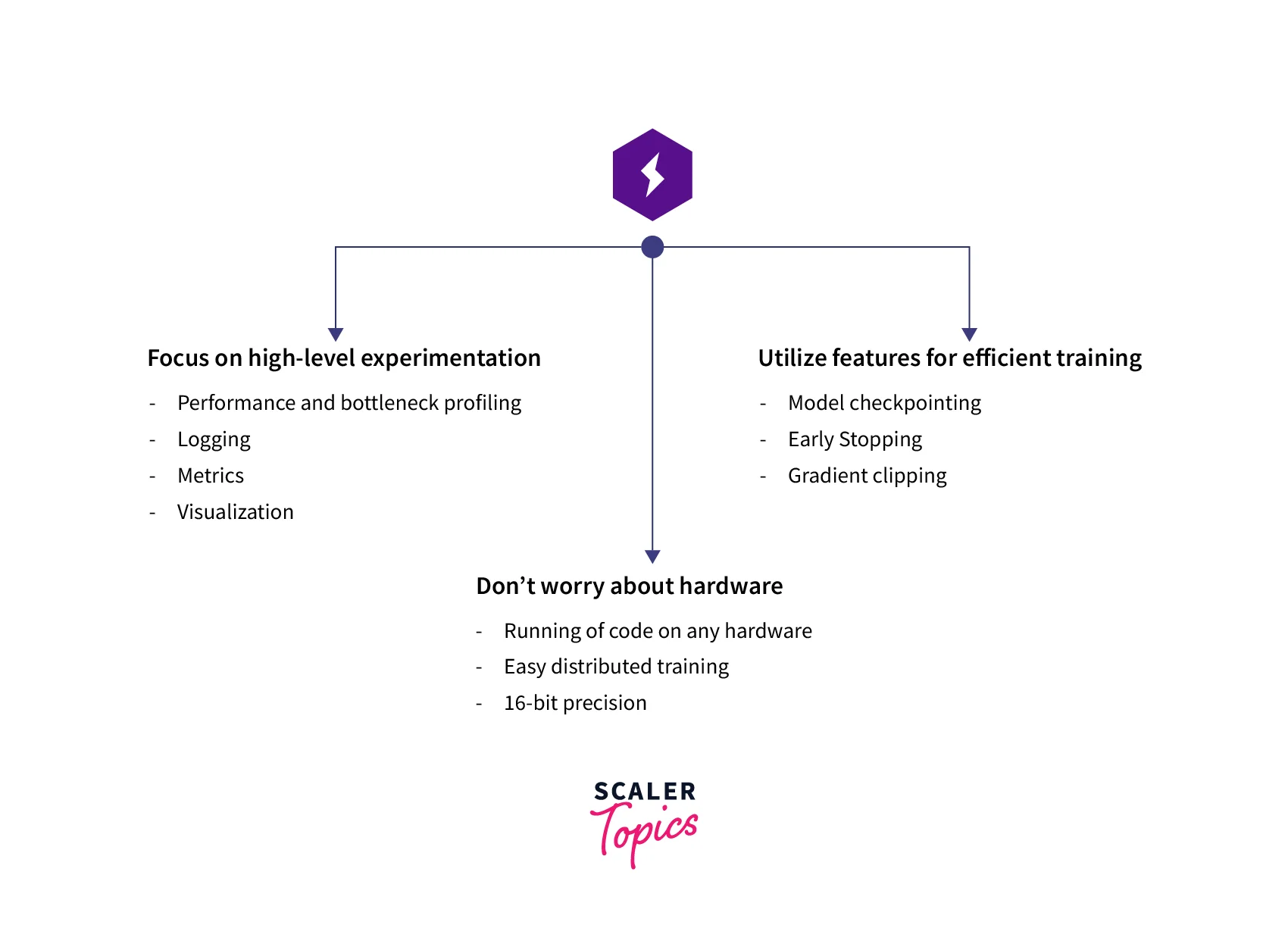
This way Pytorch Lightning makes it super fast to iterate on research experiments with code written in plain PyTorch only - no need to learn a new language. It mainly works by refactoring the PyTorch code in a more organized and readable manner allowing developers to -
- Run their code on any hardware
- Use a Performance & bottleneck profiler
- Checkpoint models easily
- Leverage 16-bit precision
- Run distributed training
- Automatically Log the metrics using third-party loggers
- Visualize the training and testing details
- Implement Early stopping and a lot more!
Who created Pytorch Lightning?
PyTorch Lightning was created by William Falcon during his Ph.D. AI research at NYU CILVR and Facebook AI Research. The library is specially designed for professional researchers and Ph.D. students working on AI research.
PyTorch Lightning aims to make cutting-edge deep learning research easier and more accessible than ever by making state-of-the-art AI research techniques (like TPU training, mixed precision training, etc.) trivial to include in deep learning pipelines.
How to Install PyTorch Lightning
To install PyTorch lightning, the following commands can be used from the terminal -
- using pip software package manager, use -
- using conda software package manager, use -
The PyTorch Lightning Workflow
The workflow of PyTorch Lightning is organized in the form of classes meant to handle different parts of a deep learning pipeline - this allows us to do away with a lot of boilerplates in plain PyTorch while enabling the use of reusable and reproducible code.
There are two main classes that any PyTorch Lightning Workflow deals with - the custom lightning DataModule and a custom LightningModule.
The former deals with accessing, downloading, and preparing data while the latter deals with model definition, training, validation, testing loops, and other training components like the optimization algorithm, etc.
We will look more into these classes shortly.
There is also another important class called the Trainer class that binds together all of the components and facilitates automation of certain parts of the deep learning project pipeline, thus allowing us to do away with the boilerplate code.
Let us first look at modules in plain PyTorch, after which we will compare it to one of the classes we mentioned - Lightning Module.
The PyTorch nn.Module Class
nn.Module is the base class for creating any custom neural network class in PyTorch - all custom model classes must inherit from this base class.
As an example, to create a Generative Adversarial Network or GAN in PyTorch that consists of a generator part that creates fabricated data that is meant to mimic a set of real data and another part called discriminator that is meant to differentiate between the real and fabricated data, we will typically create two classes inheriting from the base class nn.Module as depicted in the representation below.
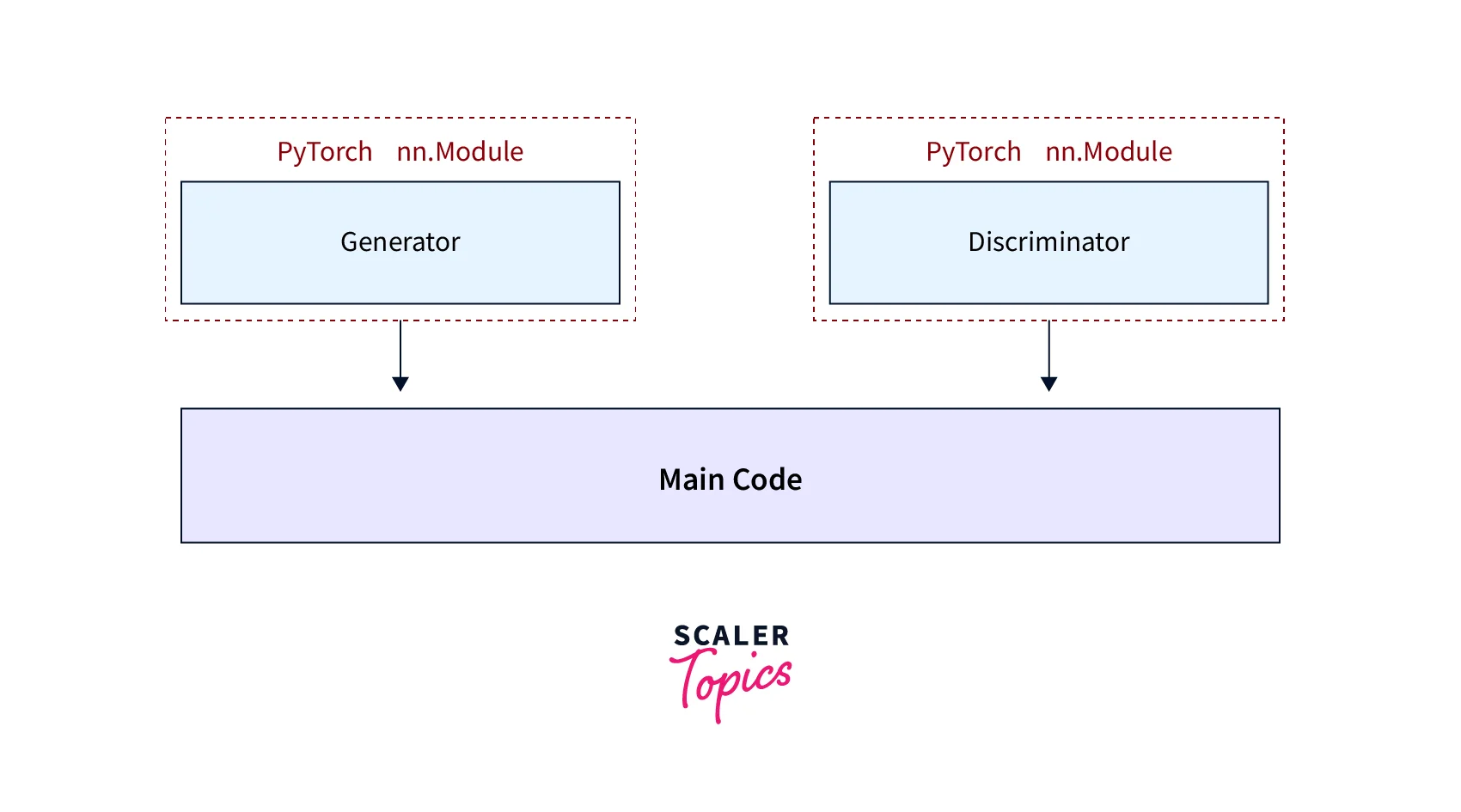
We will define separate instances for the generator and discriminator in our main code.
Let us now look at how the scenario changes in PyTorch Lightning.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
The LightningModule
This is one of the classes we talked about that is used in the lightning workflow to organize the code in an efficient and reusable manner.
The lighting module class handles (essentially reorganizes) the following components of a deep learning pipeline -
- The model or system of models
- The optimizer(s)
- The train loop
- The validation loop
- The test loop
- The prediction loop
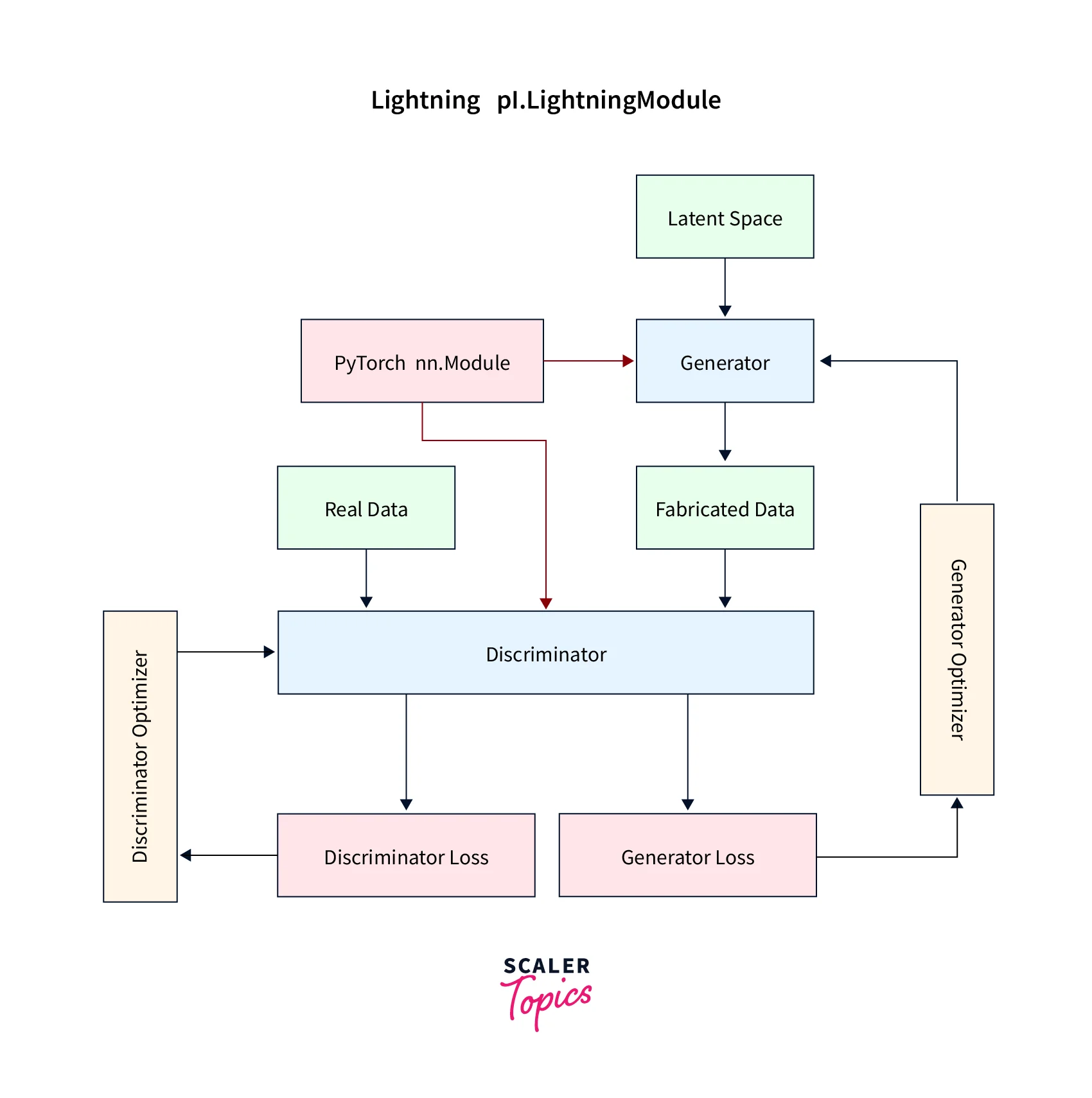
A reliable method in the custom lightning module class handles the above components.
This way, the otherwise scattered code for the training loop, the optimizer instance, etc., is now organized in one class.
We can create our custom Lightning Module by inheriting from the base class pl.LightningModule.
Later in the article, we will look at the components of Lightning Module using an example of coding a GAN network.
Before that, we will look at the second main class in the PyTorch Lightning Workflow called the LightningDataModule.
The LightningDataModule
The LightningDataModule is meant to deal with the following 5 steps in the data processing part of the deep learning pipeline:
- Download and tokenize
- Clean and save to a disk
- Load inside Dataset
- Apply transforms
- Wrap inside a DataLoader**
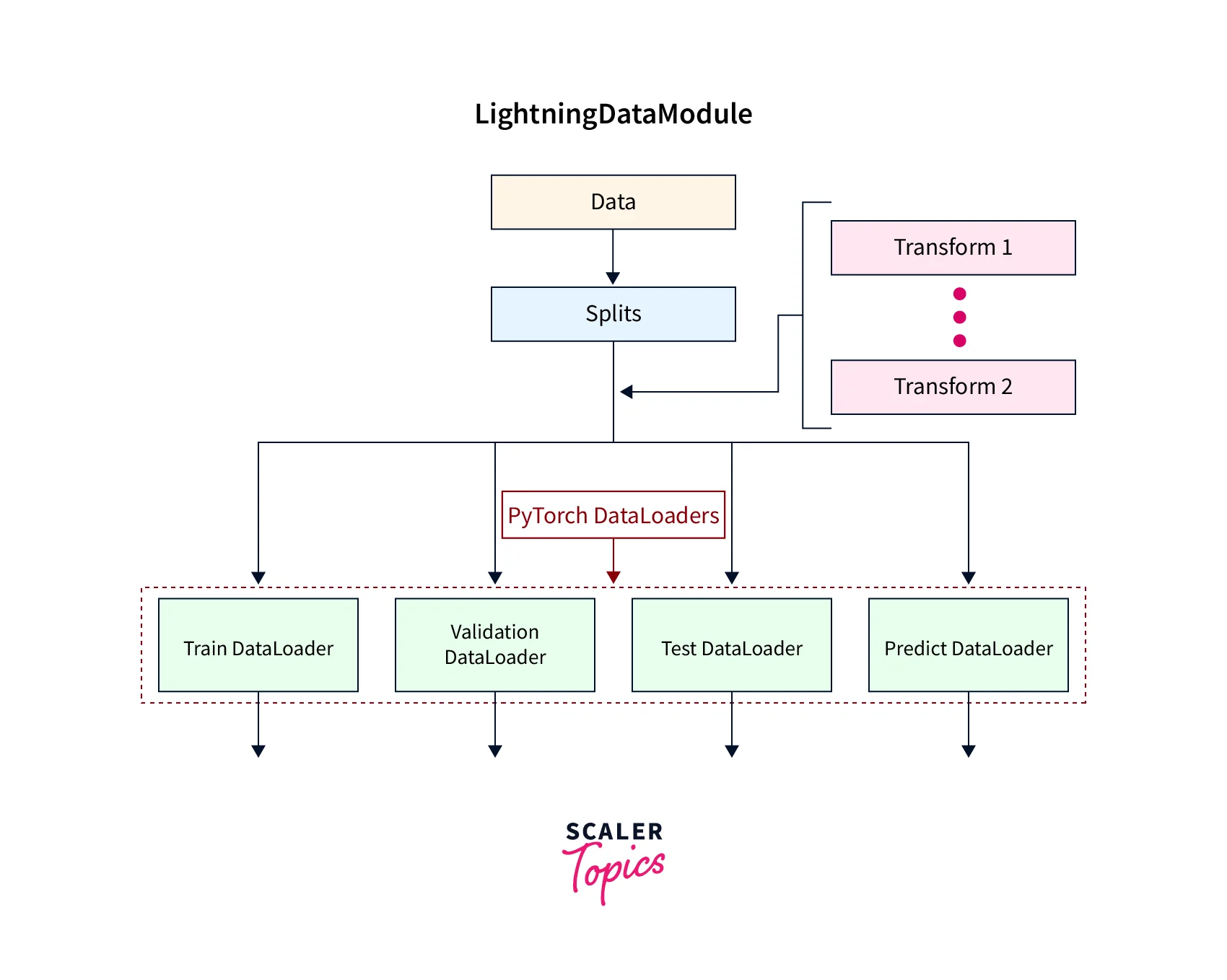
Using this, we have a centralized data processing object that is robust and reusable in the sense that it can exactly duplicate a dataset with the same splits and transforms.
The following code example shows an example of a custom LightningDataModule class for the MNIST dataset.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
The Trainer Class
While the LightningModule handles the model architecture, the optimizer, and the definition of the training, validation, and test loops, and the LightningDataModule handles the data loading and processing part of the pipeline, we have yet another class in PyTorch Lightning called the Trainer class that takes all of the components together and automates the rest of the pipeline.
It also offers other features like passing the callbacks, defining hyperparameters like the maximum number of epochs to train the model for, passing the logger instance, and so on.
Trainer allows us to customize every aspect of training via flags. Later in the article, we will demonstrate how the Trainer class trains the models defined in PyTorch Lightning.
Hooks in PyTorch Lightning
PyTorch Lightning also offers a lot of built-in hooks for easily configuring our model and data pipeline. While in this article, we do not go into the depth of what hooks are and how they can be used in PyTorch Lightning, you can refer to the official docs for more details.
How to Code a GAN with PyTorch Lightning
Using different methods, let us demonstrate using an example of all the steps organized in the Lightning Module.
We will be doing this for the MNIST Dataset.
Turn Learning into Career Growth
The Discriminator and The Generator
First, let us construct our discriminator as a subclass of nn.Module. The architecture consists of a simple CNN with two convolutional layers with max-pooling layers followed by one fully connected network - this maps 28x28 single channeled digit images from the MNIST set as real or fake.
The generator is similarly constructed as a subclass of nn.Module. The input data points are input from a latent space which we then feed into a linear layer that contains 7 * 7 * 64 output nodes that are used to create 7x7 images with 64 feature maps.
Then transposed convolutions are used for learnable upsampling that ultimately collapse the data into a 28x28 single channeled image using a final convolutional layer.
We will now use these two to create the custom lightning module class.
Initialization
The model architecture, along with other hyperparameters, are defined in the init method, like so:
We also defined two other methods to calculate the forward pass of the generator and to define the loss function.
Training Step
The Lightning module allows us to define the training loop within it so that the code is now organized in the same class where the architecture is defined. Using the training_step method, we can define the training loop as -
Define Optimizers
The optimization algorithm is also included in the same class under the method configure_optimizers, like so -
Note that we can define more than one optimizer under this method.
Callbacks
There are several built-in callback utilities offered by PyTorch Lightning, a full list of which is available here.
Callbacks automate unnecessary code like early stopping, model checkpointing, etc.
For example, to enable the automatic saving of a model checkpoint, we could initialize it and pass it to the Trainer class, like so -
We can also define our custom callbacks by subclassing the base class Callback, like so -
Loggers
PyTorch Lightning provides several third-party loggers, a full list of which is available here, that can be used to automatically log metrics with a few lines of code, like so -
Here we pass an instance of the TensorBoardLogger to the Trainer class, which we will look into in detail next.
Trainer
Apart from the components we defined above, the Trainer automates everything once we’ve organized your PyTorch code into a LightningModule. It also allows overriding any key part we don’t want to get automated.
We now take all of the components together and use them with the trainer to set things up, like so -
We defined our Trainer instance with the necessary arguments as defined above. We also instantiated our custom data module and lightning module classes to create two instances now used to call the fit method of the trainer instance, which allows it to deal with the training of the model automatically.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Benefits of Using PyTorch Lightning
This section lets us understand the benefits of using PyTorch Lightning over plain PyTorch to develop deep learning projects.
1. Readability
With LightningModule and DataModule being defined for specific parts of a deep learning pipeline, it is much easier to navigate through a repository using PyTorch Lightning for developing deep learning projects as we will know where exactly to look at to understand the data source. For example, the data transformations to understand the model architecture and the optimization algorithm is used, and so on.
2. Robustness
With most of the heavy engineering training details being handled by the Trainer class in PyTorch Lightning, we can do away with common bugs like setting the correct hardware device, leveraging all available GPUs for training, etc. - this makes our code robust and less prone to errors.

3. Reproducibility and Reusability
By wrapping up all the major components of a deep learning pipeline into classes, PyTorch Lightning ensures that the code is easy reusable and reproducible as it is not spread across several files like how is the case with plain PyTorch codes.
4. Hardware Agnostic
PyTorch Lightning makes it super easy to use different hardware like GPUs, TPUs or other accelerators without a need to refactor the code a lot or write complicated code to support specific hardware for the computations. It even allows us to implement our custom accelerators.
5. Deep Learning Best Practices
The trainer class in PyTorch Lightning allows us to include Deep learning Best Practices and utilities like early stopping, Learning rate scheduling, Mixed Precision, Checkpointing, Stochastic Weight Averaging, etc.. Directly from it, I was using a single line of code.

Ready to master deep learning? Our Free PyTorch for Deep Learning Certification Course is your key to success in AI and machine learning.
Conclusion
- In this article, we first got an introduction to PyTorch Lightning and understood the need to include it in our deep learning toolkit.
- We then learn to install PyTorch Lightning and then move to learn its components of it.
- We learned about the LightningModule, the LightningDataModule, and the Trainer class and understood how each manifests in the modeling pipeline.
- We also walked through a full code example where we code a GAN in PyTorch and then learned to reorganize the PyTorch code into a PyTorch Lightning workflow.
- Lastly, we explored the benefits of using PyTorch Lightning in organizing our deep learning projects.