Project: Train a Speech Recognition Model from a Pre-trained Model Wav2Vec
Overview
Speech recognition is converting spoken words into written or machine-readable text. Speech recognition systems can be used for various applications, including automated transcription of spoken language, voice-based assistants, and voice-controlled devices.
Wav2Vec is a machine learning technique that converts audio waveform data into a numerical representation, or vector, which can then be used to train a model to recognize speech.
What are We Building?
In this article, we will build an end-to-end automatic speech recognition system that takes speech waveform and predicts the corresponding text. For creating the algorithm, we will use Wav2vec to directly predict words from the audio waveform or the MFCC features.
Pre-requisites
We must know a few concepts to create the speech recognition model beforehand.
Key Terms related to Automatic Speech Recognition:
- Speech recognition:
The process of converting spoken words into written or machine-readable text. - Acoustic model:
A machine learning model that maps audio data to text transcriptions. - Language model:
A machine learning model that predicts the likelihood of a sequence of words in a given language. - End-to-end speech recognition:
A system that performs speech recognition directly from audio data to text transcriptions without needing separate acoustic and language models.
The LibriSpeech Dataset
The LIbriSpeech dataset is a collection of audio files and corresponding transcriptions of spoken English used for training and evaluating speech recognition models. It consists of approximately 1000 hours of audio data, divided into training, validation, and test sets.
What is wav2vec 2.0?
Wav2vec 2.0 is a machine learning technique for training end-to-end speech recognition models. It converts audio waveform data into a numerical representation or vector that can be used to train a model to recognize speech. Wav2vec 2.0 is an improvement on the original wav2vec algorithm and allows for the training of end-to-end speech recognition models, which can directly transcribe audio data into text without needing separate acoustic and language models.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
The Architecture of wav2vec 2.0
Wav2vec 2.0 uses a convolutional neural network (CNN) to extract features from audio data and a transformer-based model to process the features and predict transcriptions. The CNN processes the audio data in small chunks or frames, and the transformer model processes the output of the CNN in a self-attention mechanism to capture long-range dependencies in the data.
Self-Supervised Learning
Wav2vec 2.0 is a self-supervised learning algorithm, which means it can learn from data without explicit labels or supervision. Instead, it uses the structure of the audio data itself as the supervision signal rather than relying on external labels. This allows wav2vec 2.0 to learn from large amounts of unlabeled data, which can be difficult and time-consuming to annotate manually.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Similarity with Word2vec
Wav2vec 2.0 is similar to the word2vec algorithm, which converts words into vectors that can be used to train natural language processing models. Both algorithms use a neural network to extract features from their respective input data (audio for wav2vec and text for word2vec) and use these features to predict labels or outcomes. The key difference is the input data they operate on and the labels they predict (transcriptions for wav2vec and words for word2vec).
How Are We Going to Build This?
To build the speech recognition model using Wav2vec, we will download the Wav2vec model and the LibriSpeech dataset. This dataset is used as a validation dataset. Finally, we will use a decoder, particularly a greedy approach-based decoder, to convert the probability distribution of the predictions into text.
Final Output
The final output of the speech recognition model is obtained by decoding the output probability distribution using a greedy decoder; the results are as follows:
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Requirements
We will require the following libraries to build the speech recognition model:
- torch
- torchaudio
- matplotlib
We will use these libraries to download the dataset, load the pertained Wav2vec model, and visualize the features.
Turn Learning into Career Growth
Building the Speech Recognition Model with Wav2Vec
We will first prepare the imports and dataset paths to construct the speech recognition model. Next, we will create the Wav2ve feature extraction pipeline. Then we will load the LibriSpeech dataset and extract features from the waveform using the extract_features() function.
Preparation
First, we import the necessary packages.
The device stores information about the computing unit present at the time, whether it be a cpu or gpu.
Creating a Pipeline
To create the pipeline, we use a pre-trained version of the Wav2vec model, which is fine-tuned for automatic speech recognition tasks.
The bundle object provides the interface to use functions such as extract_features() and get_labels().
Loading Data
We use the torchaudio.datasets.LIBRISPEECH class to load the LibriSpeech dataset.
The LibriSpeech class returns an instance of the Dataset class, which provides a convenient way to access the data. In addition, you can loop over the dataset and retrieve individual samples using the indexing operator ([]).
Then we split the dataset in train and test dataset using torch.utils.data.random_split and perform an 80-20 split.
The train_dataset returns the following data:
- Waveform
- Sample Rate
- Transcript
- Speaker ID
- Chapter ID
- Utterance ID
Extracting Acoustic Features
First, we extract the sample's waveform from the train_dataset, and then use the extract_features() function to extract the acoustic features. Then we plot the first four transformer features using the imshow() function provided by matplotlib.

Feature Classification
The model used here is an end-to-end speech classification module, which means the model sequentially performs the feature extraction and classification in a single step. Then the classification result is plotted along with the class labels.
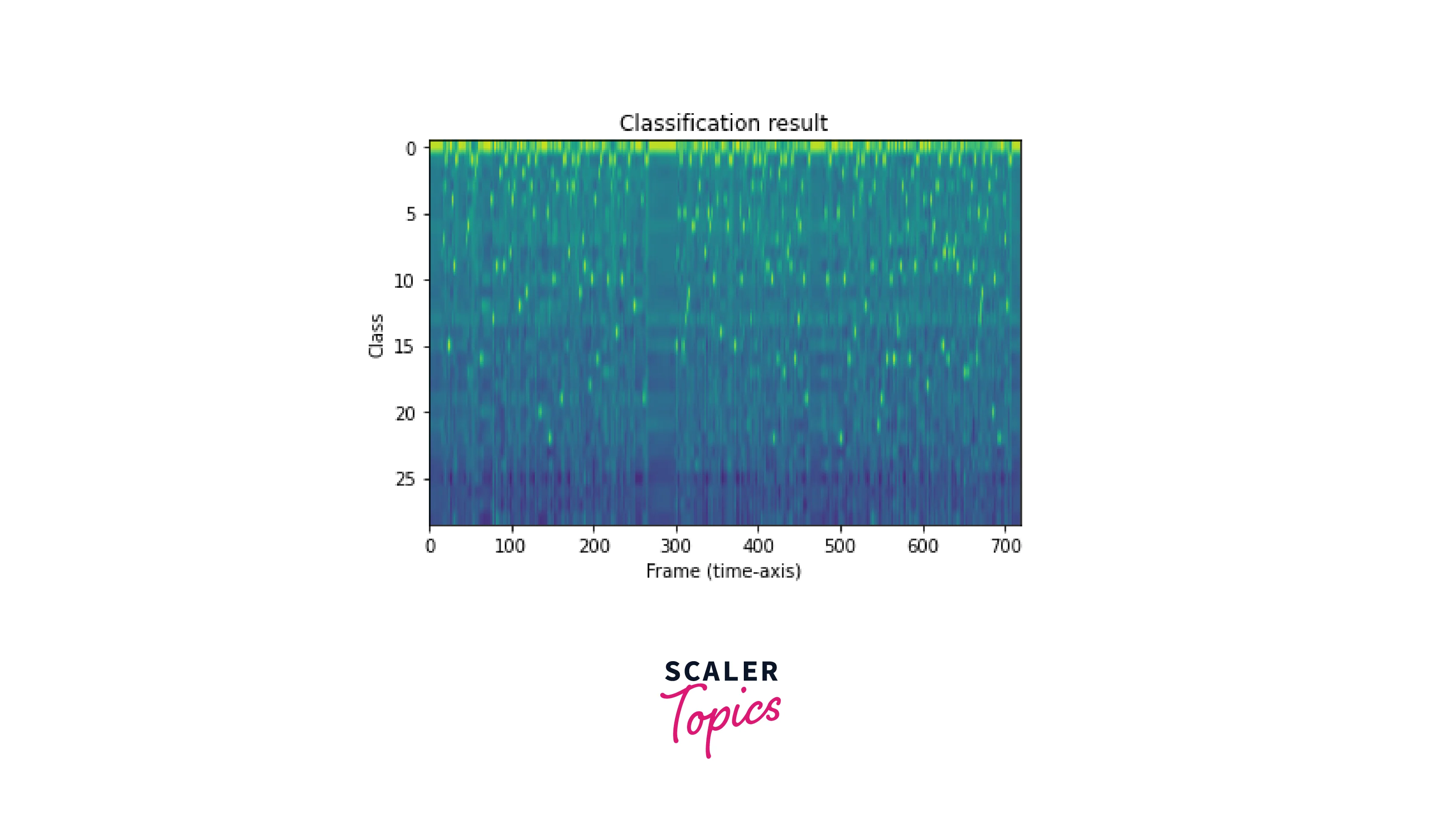
Generating Transcripts
To convert the generated class probabilities of labels to a transcript, we perform 'decoding'.
Decoding can be performed using various techniques, such as word dictionaries and language models. This article uses the greedy approach to iterate over all possible hypotheses.
The transcript obtained is as follows.
What's Next?
Till now, we have learned how to use their trained Wav2vec model to perform inference on the LibriSpeech dataset, and we also fine-tune the model for further tasks. To perform the training, we use the following code:
Here ClassificationModel is a placeholder for the speech recognition model you want to fine-tune. You can define this model on your own or train a pre-existing model. There are many different ways to create the model, and you can use a CNN-based or RNN-based model or even transformer networks.
Conclusion
In this article, we focussed on the following topics:
- First, we understood the meaning of automatic speech recognition and the Wav2vec algorithm.
- Next, we built a pipeline to load the model and execute functions such as feature extraction using the extract_features() function.
- We built a dataloader for the LibriSpeech dataset using the torchaudio.datasets.LIBRISPEECH class.
- Next, we build a greedy approach-based decoder to convert the label probabilities to a transcript.
- Finally, we learned how to create and fine-tune a custom classification model for other tasks.