Types of Generative AI: Complete Classification
Generative AI refers to a subset of deep learning models designed to create new, original content—such as text, images, code, or audio—by learning the underlying patterns and distributions of large training datasets rather than simply classifying or predicting existing data.
Understanding the Generative AI Paradigm
At its mathematical core, artificial intelligence has historically been dominated by discriminative modeling. Discriminative models learn the conditional probability distribution P(Y|X)—the probability of an output Y given an input X. Their primary function is to draw decision boundaries in high-dimensional space, separating classes for tasks like image recognition, spam detection, or churn prediction.
Generative AI, however, fundamentally shifts this paradigm by focusing on the joint probability distribution P(X, Y) or the marginal probability distribution P(X). Instead of drawing a boundary between "dog" and "cat," generative models learn the dense, multi-dimensional distribution of features that constitute a "dog." By sampling from this learned latent space, the model can synthesize entirely novel data points that share the statistical properties of the original training set but have never existed before.
Understanding the different types of generative AI requires examining them through two distinct lenses: the underlying foundational architectures (the technical mechanisms) and the output modalities (the type of data generated). By mastering both, software engineers and data scientists can effectively select, tune, and deploy the correct algorithms for complex enterprise applications.
Types of Generative AI by Technical Architecture
The rapid advancement of generative AI is driven by several distinct neural network architectures. Each architecture utilizes different mathematical principles to encode representations and sample new data.
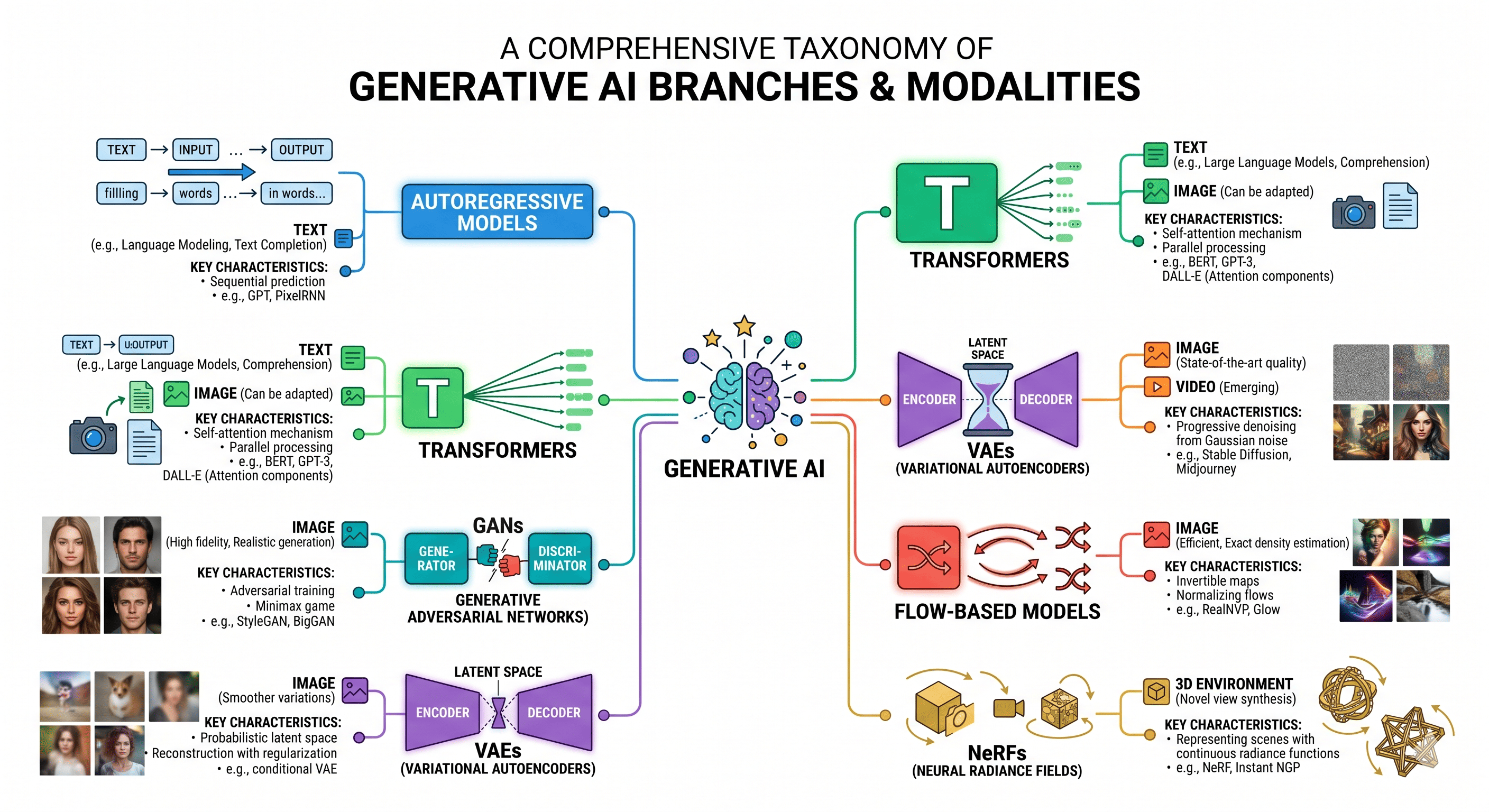
1. Transformer Models
Transformers, introduced by Vaswani et al. in 2017, have become the de facto standard for natural language processing and are increasingly utilized in vision and audio generation. Unlike earlier Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs) that processed data sequentially, Transformers process entire sequences in parallel.
The core innovation of the Transformer is the Self-Attention Mechanism. Self-attention allows the model to weigh the importance of different elements in an input sequence dynamically, regardless of their positional distance.
Mathematically, the self-attention mechanism computes an output using Query (Q), Key (K), and Value (V) matrices. The attention score is calculated as: Attention(Q, K, V) = softmax((Q K^T) / √d_k) V where d_k is the dimension of the key vectors, used as a scaling factor to prevent vanishing gradients during the softmax operation.
Transformers typically rely on an autoregressive generation strategy (in decoder-only models like GPT) where the network predicts the probability of the next token based on all previously generated tokens: P(x_n | x_1, x_2, ..., x_n-1).
Stop learning AI in fragments—master a structured AI Engineering Course with hands-on GenAI systems with IIT Roorkee CEC Certification
AI Engineering Course Advanced Certification by IIT-Roorkee CEC
A hands on AI engineering program covering Machine Learning, Generative AI, and LLMs - designed for working professionals & delivered by IIT Roorkee in collaboration with Scaler.
Enrol Now
To illustrate the technical implementation, here is a foundational PyTorch representation of a scaled dot-product self-attention block:
2. Generative Adversarial Networks (GANs)
Introduced by Ian Goodfellow in 2014, GANs operate on a game-theoretic architecture where two neural networks are trained simultaneously in a zero-sum game.
- The Generator (G): Takes random noise from a latent space (z) and attempts to synthesize data (G(z)) that perfectly mimics the true data distribution.
- The Discriminator (D): Takes both real data (x) from the training set and fake data (G(z)) from the generator, attempting to classify which is real and which is synthesized.
The networks are locked in a min-max adversarial objective: min_G max_D V(D, G) = E_x[log D(x)] + E_z[log(1 - D(G(z)))]
The generator continuously updates its weights to maximize the discriminator's error rate, while the discriminator updates to minimize it. Training theoretically concludes when the system reaches a Nash Equilibrium, where the generator produces perfect synthetics and the discriminator guesses with a 50% probability.
While GANs produce highly photorealistic images and operate with fast inference times, they are notoriously difficult to train. Engineers frequently encounter mode collapse—a scenario where the generator finds a single output that consistently fools the discriminator and ceases exploring the rest of the latent space, resulting in a lack of output diversity.
3. Variational Autoencoders (VAEs)
VAEs are probabilistic generative models that approach data synthesis through the lens of Bayesian inference. Unlike standard autoencoders that compress data into a fixed vector, VAEs map inputs into a continuous, probabilistic latent space.
A VAE consists of two networks:
- Encoder: Maps input data X to a latent distribution, defined by a mean vector (μ) and a standard deviation vector (σ).
- Decoder: Samples a point (z) from this latent distribution and reconstructs the data into X'.
To allow the model to backpropagate gradients through the stochastic sampling process, VAEs employ the Reparameterization Trick: z = μ + ε * σ where ε is random noise sampled from a standard normal distribution N(0, 1).
The loss function of a VAE (Evidence Lower Bound, or ELBO) balances two objectives: minimizing the reconstruction error (ensuring the output matches the input) and minimizing the Kullback-Leibler (KL) divergence between the learned latent distribution and a standard Gaussian distribution.
While VAEs are mathematically elegant and generate highly diverse outputs with smooth latent space interpolations, their generated images often suffer from blurriness compared to the crisp outputs of GANs.
4. Diffusion Models
Diffusion models represent the current state-of-the-art in image and audio generation, having largely superseded GANs for text-to-image tasks. They are inspired by non-equilibrium thermodynamics.
The architecture operates in two distinct Markov chain phases:
- Forward Process (Diffusion): Iteratively adds Gaussian noise to an input image over T time steps until the image is completely destroyed, resulting in pure isotropic Gaussian noise.
- Reverse Process (Denoising): A neural network—typically a U-Net architecture—is trained to reverse this process, predicting the exact amount of noise added at step t-1 so it can be subtracted.
By starting with pure random noise and iteratively applying the denoising network conditioned on text embeddings (often via Cross-Attention layers), Diffusion models synthesize highly detailed, coherent images.
While diffusion models do not suffer from mode collapse and offer exceptional training stability, they require significant computational power and suffer from slow inference speeds, as the reverse process must sequentially step through the denoising phases (often 50 to 1000 steps).
5. Normalizing Flow Models
Flow-based generative models explicitly learn the data distribution by applying a sequence of invertible mathematical transformations.
Starting with a simple base distribution (like a standard Gaussian), a normalizing flow applies a series of bijective (invertible) functions. Because the transformations are bijective, the exact log-likelihood of the data can be calculated and maximized directly using the change-of-variables formula.
Unlike GANs (which cannot compute likelihoods) or VAEs (which optimize a lower bound), flow-based models offer exact log-likelihood estimation and perfect reconstruction. However, enforcing the architectural constraint of invertibility restricts the capacity of the neural network, often requiring massively deep networks to match the visual fidelity of VAEs or Diffusion models.
Master structured AI Engineering + GenAI hands-on, earn IIT Roorkee CEC Certification at ₹40,000
AI Engineering Course Advanced Certification by IIT-Roorkee CEC
A hands on AI engineering program covering Machine Learning, Generative AI, and LLMs - designed for working professionals & delivered by IIT Roorkee in collaboration with Scaler.
Enrol Now6. Neural Radiance Fields (NeRFs)
NeRFs represent a breakthrough in 3D generative AI. While not strictly "generative" in the same unconditioned sense as a GAN, generative extensions of NeRFs synthesize entirely novel 3D environments from sparse 2D image inputs.
A NeRF utilizes a fully connected multilayer perceptron (MLP) to represent a continuous 3D scene. The input is a 5D coordinate comprising spatial location (x, y, z) and viewing direction (θ, φ). The model outputs the volume density and emitted RGB radiance at that spatial location. By utilizing classic volume rendering techniques (tracing rays through the scene to calculate pixel colors), NeRFs generate hyper-realistic novel views of 3D objects with perfect view-dependent lighting and shadows.
Types of Generative AI by Content Modality
While understanding the underlying architectures is critical for AI engineers, the application layer of Generative AI is best classified by the modalities it outputs. The versatility of foundation models allows them to bridge complex data types seamlessly.
1. Text Generation (Large Language Models)
Text generation represents the most widely adopted facet of generative AI. Driven entirely by highly scaled Transformer architectures, Large Language Models (LLMs) are trained on massive corpora of human text.
Through self-supervised learning (predicting masked words or next words), these models learn syntax, semantics, logic, and factual representations. Text generation encompasses several advanced engineering techniques:
- Prompt Engineering & Few-Shot Learning: In-context learning where models generate desired outputs based on conditioning prefixes without altering model weights.
- Fine-Tuning & PEFT: Updating model weights for specific domains, often using Parameter-Efficient Fine-Tuning methods like LoRA (Low-Rank Adaptation) to reduce computational overhead.
- Retrieval-Augmented Generation (RAG): Bridging the model's static parametric memory with external vector databases to generate text based on real-time, proprietary data, effectively minimizing hallucination rates.
2. Image Generation
Image generation models map textual prompts or structural inputs to high-fidelity visual outputs. The dominant architecture has shifted from GANs to Latent Diffusion Models (LDMs). In an LDM, the computationally expensive diffusion process occurs not in the high-dimensional pixel space, but in a compressed, lower-dimensional latent space facilitated by a VAE.
Image generators are utilized in gaming asset creation, architectural visualization, synthetic training data generation (to train other discriminative computer vision models), and marketing content generation. Advanced implementations utilize techniques like ControlNet, which allows engineers to condition the diffusion model on specific structural maps (e.g., Canny edges, depth maps, or human pose skeletons) to enforce strict spatial control over the generated image.
3. Audio and Speech Generation
Generative audio models synthesize human speech (Text-to-Speech), musical compositions, and sound effects. Modern audio generation architectures often utilize continuous diffusion models or autoregressive transformers operating on discrete audio tokens (codebooks).
Key advancements in this space include:
- Voice Cloning: Utilizing just a few seconds of target audio to map the latent acoustic characteristics of a speaker, applying them to novel text inputs.
- MusicLM / AudioLM: Generating cohesive, multi-instrumental musical tracks at 24kHz based on complex text prompts mapping mood, tempo, and genre.
- Speech-to-Speech Translation: Generatively translating spoken audio into another language while preserving the original speaker's vocal timbre, intonation, and prosody.
4. Code Generation
Code generation models are specialized LLMs heavily fine-tuned on public source code repositories, documentation, and programming forums. These models excel at understanding the syntactic and logical structures of programming languages ranging from Python and C++ to Bash and SQL.
For software engineers, code generative AI acts as an intelligent pair programmer. It can generate boilerplate code from docstrings, refactor legacy codebases, translate code from one language to another (e.g., migrating Java to Go), and write comprehensive unit tests. Because code requires strict logical validity (unlike natural language, which tolerates ambiguity), engineers are developing neuro-symbolic techniques that combine generative neural networks with traditional static code analyzers and interpreters to verify generated code at runtime.
5. Video Generation
Video generation is the most computationally demanding modality in the generative AI taxonomy. It requires the model to not only generate high-fidelity spatial frames (like image generation) but also maintain strict temporal consistency across those frames over time.
Early video models relied on 3D convolutions or frame-by-frame autoregressive generation, which frequently resulted in morphing artifacts and physics hallucinations. Modern state-of-the-art models utilize Spatiotemporal Diffusion Transformers. These models learn physics, object permanence, and camera dynamics by tokenizing video segments into spatial and temporal patches, allowing for the generation of multi-minute, high-resolution videos from text instructions.
Generative AI vs. Predictive AI vs. Discriminative AI
To architect robust AI systems, engineers must understand exactly where generative AI fits within the broader machine learning landscape. Misapplying a generative model to a discriminative problem wastes massive computational resources, while misapplying a predictive model to a creative problem yields failure.
Below is a precise technical comparison of the three primary AI paradigms.
| Feature | Generative AI | Predictive AI | Discriminative AI |
|---|---|---|---|
| Core Objective | Learn the underlying data distribution to create new data instances. | Forecast future outcomes or trends based on historical time-series data. | Find the decision boundary between classes to categorize existing data. |
| Mathematical Focus | Joint Probability P(X, Y) or Marginal Probability P(X). | Statistical extrapolation and Regression functions. | Conditional Probability P(Y|X). |
| Output Format | High-dimensional unstructured data (Text, Images, Audio, Code). | Continuous numerical values, probabilities, or state predictions. | Discrete class labels or categorical probabilities. |
| Common Architectures | Transformers, Diffusion Models, GANs, VAEs. | ARIMA, LSTMs, Gradient Boosting (XGBoost), Random Forests. | Convolutional Neural Networks (CNNs), Support Vector Machines (SVMs). |
| Enterprise Use Case | Automating code generation, drafting legal briefs, synthesizing 3D assets. | Demand forecasting, stock market prediction, server load estimation. | Credit card fraud detection, medical image diagnosis, spam filtering. |
Prominent Generative Models Examples
To bridge theoretical taxonomy with industry application, it is crucial to examine the prominent generative models examples that currently dominate the market. These models represent the pinnacle of deep learning engineering and distributed computing.
Text & Multimodal Foundation Models
- GPT-4 (OpenAI): A massive autoregressive transformer relying on a Mixture-of-Experts (MoE) architecture. It represents the gold standard for logical reasoning, zero-shot code generation, and complex natural language understanding.
- Claude 3.5 Sonnet (Anthropic): A heavily optimized LLM utilizing Constitutional AI for safer alignment, known for its massive context window (allowing engineers to dump entire repositories of code into a single prompt for analysis) and superior coding capabilities.
- Llama 3 (Meta): An open-weights transformer model. Because developers have access to the model weights, Llama has become the foundation for thousands of fine-tuned enterprise models deployed in private cloud environments via techniques like Quantization (e.g., GGUF, AWQ) to reduce VRAM requirements.
Image & Visual Models
- Stable Diffusion (Stability AI): An open-source Latent Diffusion Model. Its architecture allows it to run locally on consumer-grade GPUs (e.g., NVIDIA RTX 3090/4090). Engineers frequently customize it using LoRAs to enforce specific brand styles or generate precise synthetic datasets for computer vision training.
- Midjourney: A proprietary closed-source diffusion model accessed via API or Discord, renowned for its unparalleled aesthetic alignment, photorealism, and artistic prompt adherence.
- Sora (OpenAI): A state-of-the-art text-to-video Spatiotemporal Diffusion Transformer capable of rendering complex camera trajectories, realistic fluid dynamics, and temporally consistent characters over long durations.
Audio & Code Models
- GitHub Copilot / Codex (Microsoft/OpenAI): A transformer specifically trained on tens of millions of public GitHub repositories. It integrates directly into IDEs (like VS Code), offering real-time, context-aware code completion.
- WaveNet (DeepMind): A pioneering deep generative model of raw audio waveforms. Utilizing dilated causal convolutions, it dramatically improved the naturalness of synthesized human speech, moving away from robotic concatenative Text-to-Speech systems.
Frequently Asked Questions (FAQ)
What is the fundamental difference between VAEs and GANs in generative AI? VAEs are probabilistic models that encode data into a continuous latent space and use statistical inference (maximizing a lower bound) to reconstruct data, resulting in smooth, continuous interpolations but occasionally blurry outputs. GANs rely on an adversarial game between a generator and discriminator without explicitly modeling the probability density. GANs generally produce sharper, highly photorealistic images but suffer from training instability and mode collapse.
Why have Diffusion Models largely replaced GANs for text-to-image generation? While GANs offer fast single-step inference, they are exceedingly difficult to scale on massive datasets paired with highly variable text embeddings. Diffusion models, by mathematically reducing image generation to an iterative denoising process, offer significantly more stable training dynamics and do not suffer from mode collapse. This stability allows them to scale seamlessly to datasets containing billions of image-text pairs (like LAION-5B), resulting in far superior text-to-image alignment.
What is the computational complexity of standard Transformers used in generative AI? The standard self-attention mechanism in a Transformer scales quadratically with respect to the input sequence length. The time complexity is O(N^2 * D), where N is the sequence length (number of tokens) and D is the dimensionality of the representation. This quadratic scaling is the primary engineering bottleneck preventing infinite context windows, prompting research into linear attention mechanisms, state-space models (like Mamba), and efficient key-value (KV) caching strategies.
Can generative AI be used to train predictive AI models? Yes. One of the most powerful engineering applications of generative AI is Synthetic Data Generation. When training data for a discriminative or predictive model is sparse, imbalanced, or privacy-restricted (e.g., medical records or fraudulent transactions), generative models (like tabular GANs or Diffusion models) can synthesize millions of statistically accurate, anonymized data points to augment the training set, drastically improving the performance of the predictive model.