Types of Prompt Engineering: Zero-Shot, Few-Shot, Chain-of-Thought & More
The primary types of prompt engineering are methods for structuring input to a Large Language Model (LLM) to elicit a desired response. These techniques range from providing no examples (Zero-Shot) to multiple examples (Few-Shot), and extend to advanced methods like Chain-of-Thought which guide the model's reasoning process.
Prompt engineering has emerged as a critical discipline within software engineering and applied AI. As Large Language Models (LLMs) like GPT-4, Llama 3, and Claude 3 become increasingly integrated into software stacks, the ability to communicate with them effectively and reliably is paramount. This communication is not a matter of casual conversation but a technical skill involving the precise construction of instructions, context, and examples. Understanding the different types of prompt engineering is analogous to a programmer understanding different data structures; each is a tool suited for a specific class of problems. This guide provides a systematic and technically rigorous exploration of the fundamental and advanced prompt engineering methods that every developer working with LLMs should master.
Stop learning AI in fragments—master a structured AI Engineering Course with hands-on GenAI systems with IIT Roorkee CEC Certification
AI Engineering Course Advanced Certification by IIT-Roorkee CEC
A hands on AI engineering program covering Machine Learning, Generative AI, and LLMs - designed for working professionals & delivered by IIT Roorkee in collaboration with Scaler.
Enrol Now
Foundational Prompting Techniques: In-Context Learning
The most fundamental prompt engineering methods leverage a core capability of transformer-based LLMs known as In-Context Learning (ICL). ICL is the model's ability to learn a new task or pattern at inference time, solely based on the information provided within the prompt's context window. Unlike fine-tuning, ICL does not update the model's weights. Instead, it uses the provided examples as an analogical guide to shape the subsequent output. The following techniques represent a spectrum of ICL, varying in the number of examples provided to the model.
Zero-Shot Prompting
Zero-shot prompting is the most basic form of interaction with an LLM. It involves instructing the model to perform a task without providing any prior examples of how to complete it. The model is expected to understand and execute the task based entirely on its vast pre-trained knowledge. This method relies on the model's ability to generalize from the patterns it learned during training to a novel, unseen task specified in the prompt.
Core Principle: Direct instruction without demonstration.
Use Cases:
- Simple Classification: Categorizing text into broad categories like Positive, Negative, or Neutral.
- Summarization: Condensing a piece of text into a shorter summary.
- Translation: Translating text from one language to another.
- General Question-Answering: Answering factual questions where the answer is likely contained within the model's training data.
Example: Sentiment Analysis A zero-shot prompt for sentiment analysis would be direct and to the point.
In this example, the model correctly infers the task and the desired output format ("Positive") without a single example. Its success is contingent on the task being simple enough to be understood from the instruction alone.
One-Shot Prompting
One-shot prompting enhances the basic instruction by providing a single, high-quality example. This single demonstration helps the model understand the nuances of the task, including the expected output format, tone, and level of detail. It is particularly effective for tasks where the desired structure is specific and might not be immediately obvious from a zero-shot instruction.
Core Principle: Instruction with one demonstration.
Use Cases:
- Format-Specific Generation: Converting data from one format to another (e.g., natural language to JSON).
- Style Transfer: Rewriting text in a specific style (e.g., formal to informal).
- Simple Code Correction: Fixing a minor syntax error in a code snippet.
Example: JSON Formatting Suppose you need an LLM to extract specific entities from a text and format them as a JSON object. A one-shot prompt provides a clear template.
The single example effectively constrains the model's output to the exact JSON structure required.
Few-Shot Prompting
Few-shot prompting extends the one-shot concept by providing multiple examples (typically two to five). This approach is powerful for more complex or nuanced tasks where a single example is insufficient to capture the full pattern. By observing several input-output pairs, the model can better infer the underlying logic, handle edge cases, and produce more consistent results.
Core Principle: Instruction with multiple demonstrations to establish a clear pattern.
Use Cases:
- Complex Classification: Categorizing text into fine-grained or custom-defined labels.
- Structured Data Extraction: Pulling multiple, complex fields from unstructured text.
- Code Generation: Generating boilerplate code based on a few examples of function signatures and docstrings.
Example: Code Comment Classification Imagine you want to classify code comments into three categories: Header, BugFix, or Refactor. This custom task is ideal for a few-shot approach.
The multiple examples help the model distinguish between a fix, a structural improvement, and file-level metadata, a distinction that would be difficult to convey with zero-shot or one-shot prompting. The quality, diversity, and order of the examples in a few-shot prompt can significantly impact performance.
Advanced Reasoning and Decomposition Techniques
While in-context learning excels at pattern recognition, it can falter on tasks that require multi-step reasoning, such as arithmetic problems, logic puzzles, or strategic planning. Advanced prompting techniques address this by explicitly encouraging the model to decompose a problem into intermediate steps, articulate its reasoning process, and explore multiple potential solutions. These methods transform the LLM from a simple pattern-matching engine into a more robust reasoning engine.
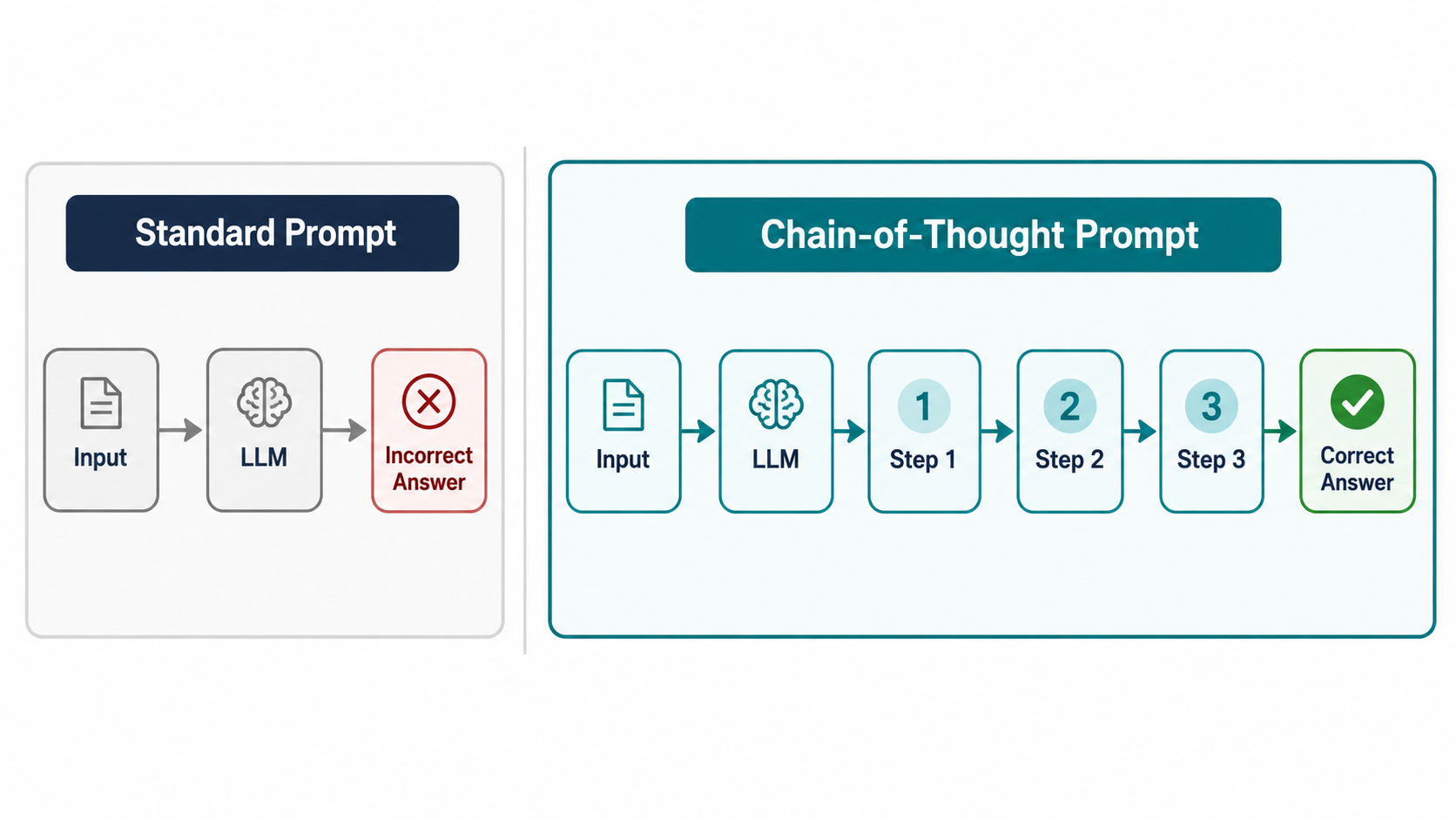
Chain-of-Thought (CoT) Prompting
Chain-of-Thought (CoT) prompting is a groundbreaking technique that improves an LLM's performance on complex reasoning tasks. Instead of providing examples with only the final answer, CoT prompts include examples where the intermediate reasoning steps are explicitly written out. By observing these "thought processes," the model learns to generate its own chain of thought before arriving at a final answer, which significantly reduces errors in arithmetic, commonsense, and symbolic reasoning tasks.
Core Principle: Demonstrate the reasoning process, not just the final result.
Use Cases:
- Multi-step arithmetic problems.
- Commonsense reasoning puzzles.
- Symbolic manipulation and logic problems.
- Extracting implicit information from a text.
Example: Multi-step Word Problem Consider a standard prompt vs. a CoT prompt for a word problem.
Standard Few-Shot Prompt (Prone to Error):
A model might incorrectly answer 10 (5+2+3) because it fails to perform the multiplication step.
Chain-of-Thought Prompt (More Robust):
Expected CoT Output: Roger started with 5 balls. He bought 2 cans, and each can has 3 balls, so he got 2 * 3 = 6 new balls. In total, he now has 5 + 6 = 11 tennis balls. The answer is 11.
Become the Ai engineer who can design, build, and iterate real AI products, not just demos with an IIT Roorkee CEC Certification
AI Engineering Course Advanced Certification by IIT-Roorkee CEC
A hands on AI engineering program covering Machine Learning, Generative AI, and LLMs - designed for working professionals & delivered by IIT Roorkee in collaboration with Scaler.
Enrol NowBy showing the breakdown, the model learns to perform the intermediate calculation (2 * 3 = 6) before the final addition.
 ]
]
Zero-Shot CoT
While powerful, crafting detailed few-shot CoT examples can be labor-intensive. Zero-Shot CoT is a remarkably simple yet effective alternative discovered by Kojima et al. (2022). It involves appending a simple phrase like "Let's think step by step." to the end of a zero-shot prompt. This simple instruction is often sufficient to trigger the model's latent reasoning capabilities, causing it to generate a chain of thought on its own without any examples.
Core Principle: Explicitly instruct the model to reason methodically.
Use Cases:
- Rapidly prototyping solutions for reasoning tasks.
- Applications where creating detailed few-shot examples is impractical.
- General-purpose problem-solving where the reasoning structure is not known in advance.
Example: Logic Puzzle
Expected Zero-Shot CoT Output: `Let c be the number of chickens and w be the number of cows. We are given two pieces of information:
- The total number of animals is 15: c + w = 15
- The total number of legs is 42. Chickens have 2 legs and cows have 4 legs: 2c + 4w = 42
We have a system of two linear equations. From equation (1), we can express c as c = 15 - w. Now, substitute this into equation (2): 2(15 - w) + 4w = 42 30 - 2w + 4w = 42 30 + 2w = 42 2w = 12 w = 6
So, there are 6 cows. Now find the number of chickens using c = 15 - w: c = 15 - 6 c = 9
There are 9 chickens and 6 cows. Let's check: 9 chickens + 6 cows = 15 animals. 92 + 64 = 18 + 24 = 42 legs. The solution is correct. The final answer is 9 chickens and 6 cows.`
Tree of Thoughts (ToT)
Tree of Thoughts (ToT) extends the linear, sequential nature of CoT into a more general problem-solving framework. Proposed by Yao et al. (2023), ToT allows an LLM to explore multiple reasoning paths simultaneously. At each step of the problem, the model can generate several different "thoughts" or next steps, creating a tree of possibilities. The model then uses a self-evaluation or search mechanism (like breadth-first or depth-first search) to decide which paths are most promising and prune the unhelpful ones.
Core Principle: Explore and evaluate multiple reasoning branches in parallel.
Use Cases:
- Complex planning tasks with multiple possible strategies (e.g., writing a complex algorithm).
- Creative tasks where multiple ideas need to be explored.
- Problems that require backtracking or correcting initial assumptions.
Graph of Thoughts (GoT)
Graph of Thoughts (GoT) is a further generalization of ToT. It models the reasoning process not as a linear chain or a tree, but as a graph. This allows for more complex thought processes where reasoning paths can be merged, creating cycles and allowing insights from one branch to influence another. For example, the solution to one sub-problem might be reused in multiple other reasoning paths. This structure is more analogous to how humans solve highly complex, interconnected problems.
Core Principle: Model reasoning as a graph of interconnected and mergeable thoughts.
Use Cases:
- Systems design and complex project planning.
- Scientific discovery and hypothesis generation.
- Any problem where sub-solutions are interdependent and can be combined in novel ways.
Techniques for Output Refinement and Control
Beyond generating a correct answer, engineers often need to ensure the output is reliable, adheres to specific constraints, and can be improved through feedback. The following techniques provide mechanisms for enhancing the quality and precision of LLM responses, moving from single-shot generation to more robust and controlled production systems.
Self-Consistency Prompting
Self-consistency is an ensemble method that builds on Chain-of-Thought prompting to improve accuracy. Instead of generating a single response, the same CoT prompt is sent to the model multiple times, but with a non-zero temperature setting. Temperature is a parameter that controls the randomness of the output; a higher temperature leads to more diverse responses. By generating several different reasoning paths, you can then select the final answer that appears most frequently among the outputs. This approach is highly effective because a problem often has multiple valid reasoning paths, and if several different paths converge on the same answer, that answer is much more likely to be correct.
Core Principle: Generate multiple diverse reasoning chains and select the most common answer (majority vote).
Use Cases:
- Arithmetic and mathematical reasoning where accuracy is critical.
- Logical deduction and multiple-choice question answering.
- Any application where the cost of an incorrect answer is high.
Conceptual Implementation:
Iterative Prompting
Iterative prompting is a conversational, multi-turn approach that mirrors human problem-solving. It involves starting with an initial prompt, analyzing the model's output, and then providing a follow-up prompt to refine, correct, or expand upon the previous response. This creates a feedback loop where the user and the LLM collaborate to progressively build toward a high-quality final output. This method is fundamental to how tools like ChatGPT are used effectively.
Core Principle: Refine the output through a sequence of conversational prompts and feedback.
Use Cases:
- Code Generation and Refactoring: Generating initial code and then asking for optimizations, bug fixes, or added features.
- Creative Writing: Developing a story by asking the model to expand on characters, plot points, or descriptions.
- Complex Analysis: Asking an initial high-level question and then using subsequent prompts to drill down into specific details.
Negative Prompting
Negative prompting is a technique for controlling model output by explicitly stating what to avoid. While most prominent in image generation models (e.g., "ugly, distorted hands"), it has direct applications in text generation. By providing negative constraints, you can steer the model away from undesirable topics, tones, formats, or specific keywords.
Core Principle: Specify what should not be included in the generated output.
Use Cases:
- Brand Safety: Ensuring generated content does not contain offensive language or controversial topics.
- Avoiding Clichés: Instructing a creative writing model to avoid common tropes or phrases.
- Enforcing Constraints: Generating a list of ideas that do not include previously discussed items.
Example:
This structured approach with negative constraints produces a more focused and on-brand response.
Specialized and Structural Prompting Methods
As prompt engineering matures, more sophisticated methods are being developed that integrate LLMs with external systems or impose a specific structure on the interaction. These techniques treat the LLM as a component within a larger computational framework, enabling it to access external knowledge and tools to solve more complex, real-world problems.
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is a powerful architecture that grounds an LLM's responses in external, up-to-date knowledge. Instead of relying solely on its static, pre-trained data, a RAG system first retrieves relevant information from a knowledge base (typically a vector database) based on the user's query. This retrieved information is then injected into the prompt's context along with the original query. The LLM then uses this provided context to generate its final answer.
Core Principle: Augment the prompt with relevant, externally retrieved data to produce factual and current responses.
Use Cases:
- Customer Support Chatbots: Answering questions based on a company's product documentation or knowledge base.
- Factual Q&A Systems: Answering questions about recent events or proprietary data not present in the model's training set.
- Document Analysis: Summarizing or answering questions about a specific set of documents provided by the user.
ReAct (Reason and Act)
The ReAct framework, proposed by Yao et al. (2022), combines reasoning and acting within a single prompt structure. It enables an LLM to interact with external tools (e.g., a search engine API, a calculator, a database API) to solve a problem. The model interleaves "thoughts" (reasoning steps) with "actions" (tool invocations). After executing an action, the system feeds the result (an "observation") back to the model, which then decides on the next thought and action. This loop continues until the model has gathered enough information to answer the original query.
Core Principle: Interleave reasoning traces with actions that call external tools to gather information.
Use Cases:
- AI Agents: Building autonomous agents that can browse the web, execute code, or manage files.
- Complex Question Answering: Answering questions that require up-to-the-minute information (e.g., "What was the stock price of GOOGL at market close today?").
- Data Analysis: Using an LLM to query a database, perform calculations on the results, and summarize the findings.
Reverse Prompting
Reverse prompting, sometimes called prompt discovery, inverts the typical workflow. Instead of providing a prompt to get a response, you provide a piece of text (the desired output) and ask the LLM to generate the prompt that would most likely produce it. This is a meta-technique useful for understanding user intent, optimizing prompts, and generating training data.
Core Principle: Given a desired output, generate the most effective input prompt.
Use Cases:
- Prompt Optimization: Refining a weak prompt by seeing how an LLM would formulate a better one for the same task.
- User Intent Analysis: Understanding the underlying question or need behind a user's statement.
- Generating Synthetic Data: Creating large datasets of prompt-response pairs for fine-tuning smaller models.
Comparing Prompt Engineering Methods
Choosing the right prompt engineering method depends on the task's complexity, the required accuracy, and the available computational resources. The table below provides a comparative overview of key techniques.
| Technique | Core Principle | Typical Use Case | Computational Cost | Example Requirement |
|---|---|---|---|---|
| Zero-Shot | Direct instruction without examples. | Simple classification, summarization, translation. | Low | None |
| Few-Shot | Instruction with several examples to show a pattern. | Complex classification, structured data extraction. | Low-Medium | 2-5 high-quality examples |
| Chain-of-Thought (CoT) | Demonstrate the step-by-step reasoning process. | Arithmetic, commonsense reasoning, logic puzzles. | Medium | Requires examples with detailed reasoning. |
| Self-Consistency | Majority vote from multiple, diverse reasoning chains. | High-stakes reasoning tasks requiring maximum accuracy. | High (multiple inferences per query) | Same as CoT, but run multiple times. |
| Retrieval-Augmented Generation (RAG) | Inject external knowledge into the prompt context. | Factual Q&A, enterprise search, knowledge bots. | Medium-High (includes retrieval step) | Requires a pre-populated knowledge base. |
| ReAct | Interleave reasoning with external tool actions. | AI agents, real-time data queries. | High (multiple inferences and tool calls) | Requires access to and descriptions of tools. |
Prompt Engineering vs. Fine-Tuning vs. Prompt Tuning
It is crucial to distinguish prompt engineering from other methods of adapting LLMs. While related, they operate at different levels of model customization and resource intensity.
Prompt Engineering
This involves manipulating the input (prompt) provided to a pre-trained model at inference time. No changes are made to the model's architecture or weights. It is the most flexible and cost-effective method for guiding model behavior for specific tasks.
Fine-Tuning
Fine-tuning (or instruction-tuning) involves taking a pre-trained model and continuing the training process on a smaller, domain-specific dataset. This process updates the model's weights to specialize it for a particular set of tasks. It is computationally expensive and creates a new, distinct model version.
Prompt Tuning / Parameter-Efficient Fine-Tuning (PEFT)
This is a hybrid approach that sits between prompt engineering and full fine-tuning. PEFT methods, such as LoRA (Low-Rank Adaptation), freeze the vast majority of the pre-trained model's weights and only train a small number of additional parameters. This achieves performance comparable to full fine-tuning but with a fraction of the computational cost and memory requirements.
Conclusion
The various types of prompt engineering represent a powerful and evolving toolkit for developers. From the simplicity of zero-shot instructions to the complex, agentic frameworks of ReAct, these methods provide a spectrum of control over LLM behavior. Mastery of these techniques is no longer an optional skill but a core competency for building intelligent, reliable, and effective AI-powered applications. As research progresses, we can expect the line between prompting and programming to blur further, with automated prompt generation (e.g., APE - Automatic Prompt Engineer) and more sophisticated reasoning frameworks like ToT and GoT becoming increasingly standard. The future of software development will be defined by those who can effectively structure this new form of human-AI dialogue.
FAQs
Q1: Which type of prompt engineering is best for mathematical reasoning? Chain-of-Thought (CoT) prompting is the standard starting point for mathematical reasoning, as it forces the model to articulate its intermediate steps, significantly reducing calculation errors. For applications requiring the highest accuracy, Self-Consistency built on top of CoT is the state-of-the-art approach.
Q2: Can these prompt engineering methods be combined? Yes, absolutely. In fact, many advanced applications use a combination of methods. For example, a ReAct agent might use a few-shot prompt to format its tool requests. A RAG system's final prompt to the LLM might be structured using a Chain-of-Thought format to encourage reasoning about the retrieved documents.
Q3: How does the choice of LLM affect the success of these prompting techniques? The model's underlying capability is a critical factor. More advanced techniques like Chain-of-Thought and Zero-Shot CoT are "emergent abilities" that typically only work well on very large, capable models (e.g., GPT-4, Claude 3 Opus). Simpler techniques like zero-shot or few-shot prompting may work on smaller models, but their effectiveness will be limited by the model's general knowledge and pattern recognition abilities.
Q4: Is prompt engineering a replacement for fine-tuning a model? No, they are complementary tools for different scenarios. Prompt engineering is ideal for rapid prototyping, handling a wide variety of ad-hoc tasks, and guiding models when you don't have a large training dataset. Fine-tuning is better suited for deeply specializing a model on a specific domain or style, embedding proprietary knowledge, or when you need to optimize performance and reduce prompt length (and thus latency and cost) for a high-volume, repetitive task.