What is Deep Learning?
You have always wondered how Google translates an entire web page to a different language in a matter of seconds or how shopping applications like Amazon and Flipkart show suggestions for future purchases, all of this is a product of deep learning but the question is What is Deep Learning?
Deep Learning is a subset of machine learning that uses artificial neural networks to imitate the working of the human brain. In deep learning, an algorithm is implemented to make computers learn to perform classification/regression tasks on complex data which can be either structured (tabular datasets) or unstructured (i.e. images, text, or sound). These algorithms can achieve state-of-art accuracy that can even surpass human-level performance sometimes.
Deep Learning vs Machine Learning

| Machine Learning | Deep Learning |
|---|---|
| Machine Learning is a superset of Deep Learning. | Deep Learning is a subset of Machine Learning. |
| In this human intervention is required to identify and code the applied features based on the data. | While here, deep learning models try to learn those features without any additional human intervention. |
| These models can be trained on lower-end machines without much computing power in less time. | These models require much more computation power and more time to train due to the complexity of the mathematical calculations involved in the algorithms |
| Algorithms used here tend to parse data in folds (section or a sample of data), then those folds are combined to come up with a result. | Deep learning systems look at an entire problem dataset in one fell swoop. |
| The two broad categories of machine learning are Supervised and Unsupervised learning. | Deep learning is mainly based on a layered structure of neurons called an artificial neural network. |
| Since it is mainly used for structured (Excel files or SQL database) data, the output is usually a numeric value like classification or regression. | Mainly used for unstructured data, the output is usually diverse like a score, an element, a classification, or simply a text. |
| Applications are medical diagnosis, statistical prediction, classification, prediction, and fraud detection. | Applications are virtual assistants, shopping & entertainment, facial recognition, language translations, pharmaceuticals, and computer vision. |
Choosing between Machine Learning and Deep Learning
When choosing between Machine Learning (ML) and Deep Learning (DL), consider the following key factors:
- Data Availability: DL requires large amounts of data to perform well, while ML can work with smaller datasets. If you have limited data, ML might be more appropriate.
- Computational Resources: DL generally demands more computational power and resources (like advanced GPUs) due to its complex models. If resources are limited, ML models are often more feasible.
- Problem Complexity: For complex tasks like image and speech recognition, DL often outperforms ML due to its ability to learn high-level features from data. For simpler tasks, ML might be sufficient and more efficient.
- Interpretability: ML models are usually easier to interpret and understand than DL models. If transparency and understanding model decisions are crucial (e.g., in healthcare or finance), ML might be preferable.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
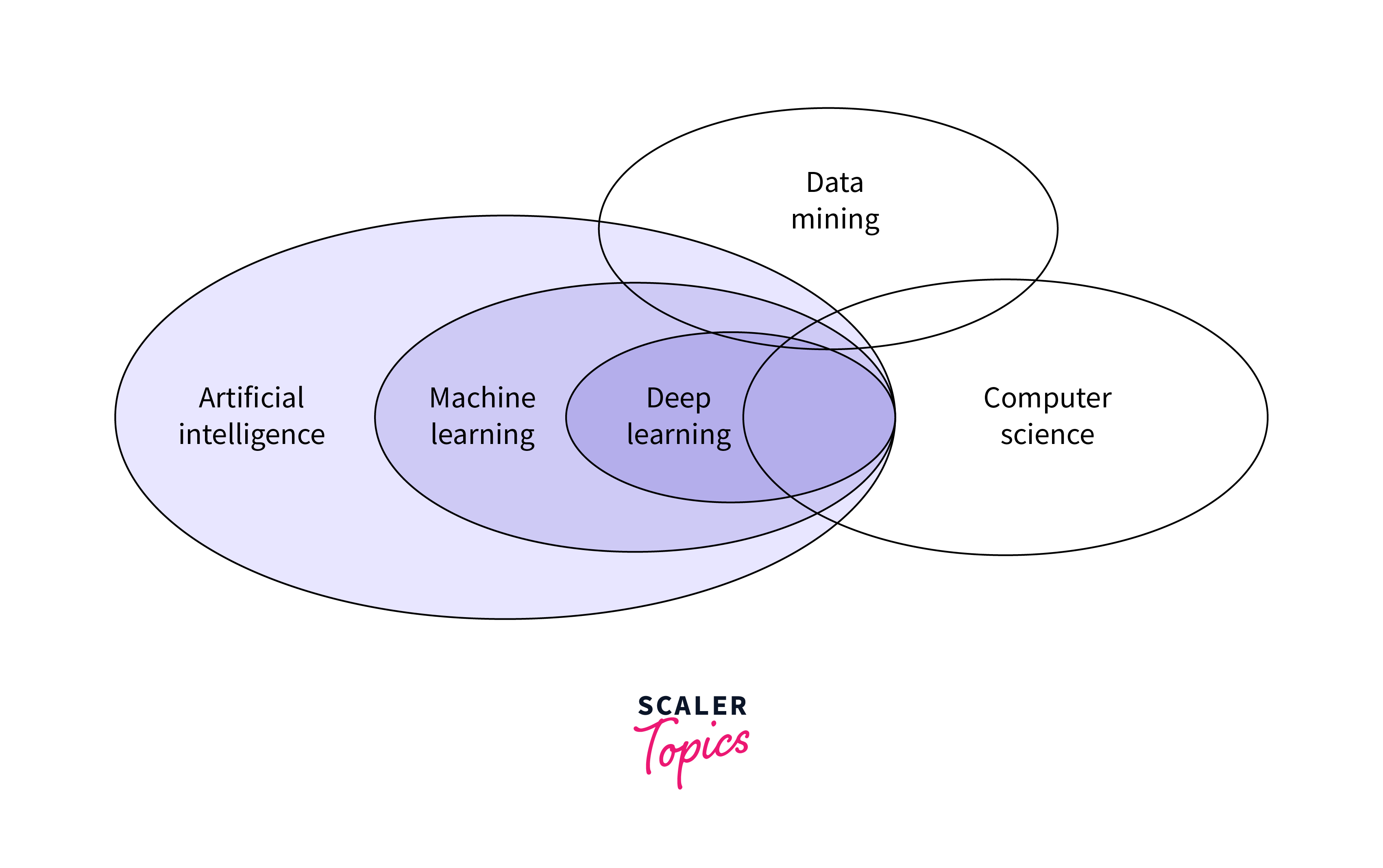
Venn Diagram to Understand AI/ML/DL
Here's a Venn diagram representing the relationships between AI, ML, and DL:
Why Deep Learning Matters?
Deep learning, a subset of machine learning and artificial intelligence, is significant for several reasons:
- Advanced Pattern Recognition: Deep learning algorithms excel in identifying complex patterns in large datasets. This capability is crucial in fields like image and speech recognition, where nuanced patterns are key.
- Automation and Efficiency: It automates and improves the efficiency of processes across various industries. For example, in manufacturing, deep learning can predict equipment failures, and in healthcare, it can assist in diagnosing diseases from medical images.
- Handling Unstructured Data: Deep learning is adept at processing and interpreting unstructured data, such as text, images, and audio. This ability is vital for applications like natural language processing and computer vision.
- Personalization and Recommendation Systems: Deep learning powers personalized user experiences through recommendation systems used by platforms like Netflix and Amazon, enhancing user engagement and satisfaction.
- Continual Learning and Improvement: Deep learning models can continuously learn and improve from new data, making them increasingly effective over time. This aspect is essential for adapting to evolving patterns and needs in various domains, from finance to autonomous vehicles.
How Does Deep Learning Work?
Neuron derives its name and meaning from the neuron in the brain. It can be seen as an on/off switch that either passes the input data to the next layer or blocks the information. In terms of Deep Learning, it is referred to as an artificial neuron or perceptron.
In the image below, these circles represent neurons that are interconnected. These are classified into different hierarchies of layers termed Input, Hidden, and Output Layers.
Deep Learning Applications
Deep learning has a wide range of applications across various sectors. Here are some notable examples:
- Image and Video Recognition: Deep learning algorithms excel at analyzing and interpreting visual data, making them ideal for applications such as facial recognition, object detection in images and videos, and even medical image analysis for disease diagnosis.
- Natural Language Processing (NLP): These models are crucial in understanding and generating human language, enabling applications like machine translation, voice-to-text transcription, sentiment analysis, and chatbots.
- Autonomous Vehicles: Deep learning is pivotal in developing self-driving cars, where it's used for tasks like real-time object detection, traffic sign recognition, and decision-making in complex driving environments.
- Personalized Recommendations: Streaming services, online shopping, and social media platforms use deep learning to analyze user behavior and preferences, providing personalized content, product recommendations, and targeted advertising.
- Predictive Analytics: In finance, healthcare, and other industries, deep learning models are used for predictive analytics, such as stock market analysis, patient outcome prediction, and even predicting maintenance needs in manufacturing.
Turn Learning into Career Growth
Components of a Deep Learning Network
- The first layer, the input layer, receives the input data and passes it to the first hidden layer.
- The hidden layers now perform the calculations on the received data. The biggest challenge here in neural networks creation is to decide the number of neurons and optimal number of hidden layers.
- Finally, the output layer takes in the inputs that are passed in from the layers before it and performs the calculations via its neurons to compute the output.

Deep learning requires a large amount of data for best results, while processing the data, neural networks can classify data with labels received from the dataset involving highly complex mathematical calculations.
For example, in Facial Recognition, the model works by learning to detect and recognize edges and lines of the face, then to more significant features, and finally, to overall representations of the face.
While representing a neural network, every node is provided with information in the form of inputs. The node then multiplies the inputs with randomly initialized weights and adds a bias value to the result. At last, nonlinear activation functions are applied to determine which neuron to fire.
Advantages and Disadvantages of Deep Learning
Deep learning, as a powerful tool in artificial intelligence, offers several advantages and also faces certain disadvantages:
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Advantages
- Handling Complex Data: Deep learning is particularly adept at processing large and complex datasets. It can identify intricate patterns and relationships in the data, which is invaluable in fields like image and speech recognition.
- Automation and Efficiency: By automating tasks that traditionally require human intervention, deep learning increases efficiency and reduces the potential for human error. This is evident in applications like predictive maintenance and medical diagnosis.
- Adaptability and Improvement Over Time: Deep learning models can improve their performance as they process more data. This continual learning aspect makes them highly adaptable to new or evolving data patterns.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Disadvantages
- Requirement for Large Amounts of Data: Deep learning models typically require extensive amounts of data to perform well. This can be a limitation in fields where data is scarce or expensive to acquire.
- Computational Intensity: These models often require significant computational resources, making them expensive and sometimes impractical for smaller organizations or less advanced systems.
- Lack of Transparency and Interpretability: Deep learning models, particularly deep neural networks, are often seen as "black boxes" due to their complexity. Understanding how they arrive at a specific decision can be challenging, which is a significant issue in critical applications like healthcare and criminal justice.
Conclusion
So to conclude, Deep learning is an Artificial Intelligence branch that mimics the workings of the human brain in processing data for use in object detection, recognizing speech, translating languages, and making decisions. Deep learning is able to learn with minimal human intervention, drawing from data that is both unstructured and structured. The first few layers in the neural network perform basic processes like feature extraction in a series of stages, similar to what the human brain seems to do. The level of complexity of such features increases through the network, with the actual decisions taking place in the last few layers. of the network structure. Deep learning models can be trained with the help of various libraries like TensorFlow, Keras, PyTorch, Fast.ai, etc.