What is LLM in Generative AI? Complete Guide
What is LLM in generative AI? A Large Language Model (LLM) is a specialized subset of generative AI designed to understand, process, and generate human-like text. Built on Transformer architectures and trained on massive datasets, LLMs predict subsequent tokens to perform complex natural language processing tasks.
Understanding the Basics: What is LLM in Generative AI?
When software engineers and data scientists discuss modern artificial intelligence, the terms "Generative AI" and "LLM" are frequently, yet incorrectly, used interchangeably. To answer "what is LLM in generative AI," one must establish the hierarchy of these technologies. Generative AI is the overarching category of artificial intelligence focused on creating novel data outputs—this includes text, images, audio, video, and synthetic datasets. Generative models map inputs from a latent space to a target distribution, enabling them to generate realistic samples.
A Large Language Model (LLM) is a specific implementation of generative AI dedicated entirely to language tasks. Where generative AI relies on various architectures like Diffusion Models for images (e.g., Midjourney) or Generative Adversarial Networks (GANs) for video, LLMs rely almost exclusively on the Transformer architecture to process sequential text data. They are "large" because their parameter counts range from billions to trillions, requiring highly distributed computing clusters for training. In short, all LLMs are generative AI, but not all generative AI systems are LLMs.
Stop learning AI in fragments—master a structured AI Engineering Course with hands-on GenAI systems with IIT Roorkee CEC Certification
AI Engineering Course Advanced Certification by IIT-Roorkee CEC
A hands on AI engineering program covering Machine Learning, Generative AI, and LLMs - designed for working professionals & delivered by IIT Roorkee in collaboration with Scaler.
Enrol Now
The Relationship Between Generative AI and Large Language Models
To build robust AI-driven applications, developers must understand the precise functional boundaries between generalized generative AI and Large Language Models. Generative AI dictates the broader capability of an algorithm to synthesize net-new artifacts rather than just classify or predict numerical outcomes based on historical data. Conversely, an LLM specializes in tokenizing text, computing vector embeddings, and determining the probabilistic likelihood of a word sequence.
When architecting software solutions, you will select an LLM if your core requirement involves text summarization, code generation, translation, or sentiment analysis. If your system requires generating non-textual assets, you must rely on broader generative AI models.
| Feature | Generative AI (General) | Large Language Models (LLMs) |
|---|---|---|
| Definition | AI that generates novel content across various formats. | A specialized AI model focused purely on text and tokenized sequences. |
| Output Formats | Images, Audio, Video, 3D Models, Text. | Text, Code snippets, JSON, structured data derived from text. |
| Core Architectures | Diffusion Models, GANs, VAEs, Transformers. | Transformer Architecture (specifically Decoder-only or Encoder-Decoder). |
| Use Cases | Image synthesis, music generation, synthetic data creation. | Chatbots, translation, text summarization, code completion. |
| Example Models | Midjourney, Stable Diffusion, DALL-E, Sora. | GPT-4, LLaMA 3, Claude 3, Mistral. |
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Large Language Models Explained: Underlying Architecture
To truly have large language models explained technically, one must dissect the architectural foundation that makes them possible: the Transformer. Before 2017, Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks dominated natural language processing. However, these models processed data sequentially, meaning they suffered from a "vanishing gradient" problem over long sequences and could not be parallelized efficiently on GPUs.
The introduction of the Transformer architecture revolutionized this paradigm. By discarding recurrence entirely and relying solely on a mechanism called "Self-Attention," Transformers can process entire sequences of text simultaneously. This parallel processing capability allows for training on unfathomably massive datasets. The architecture maps words into high-dimensional vector spaces (embeddings), allowing the model to understand semantic relationships through mathematical proximity.
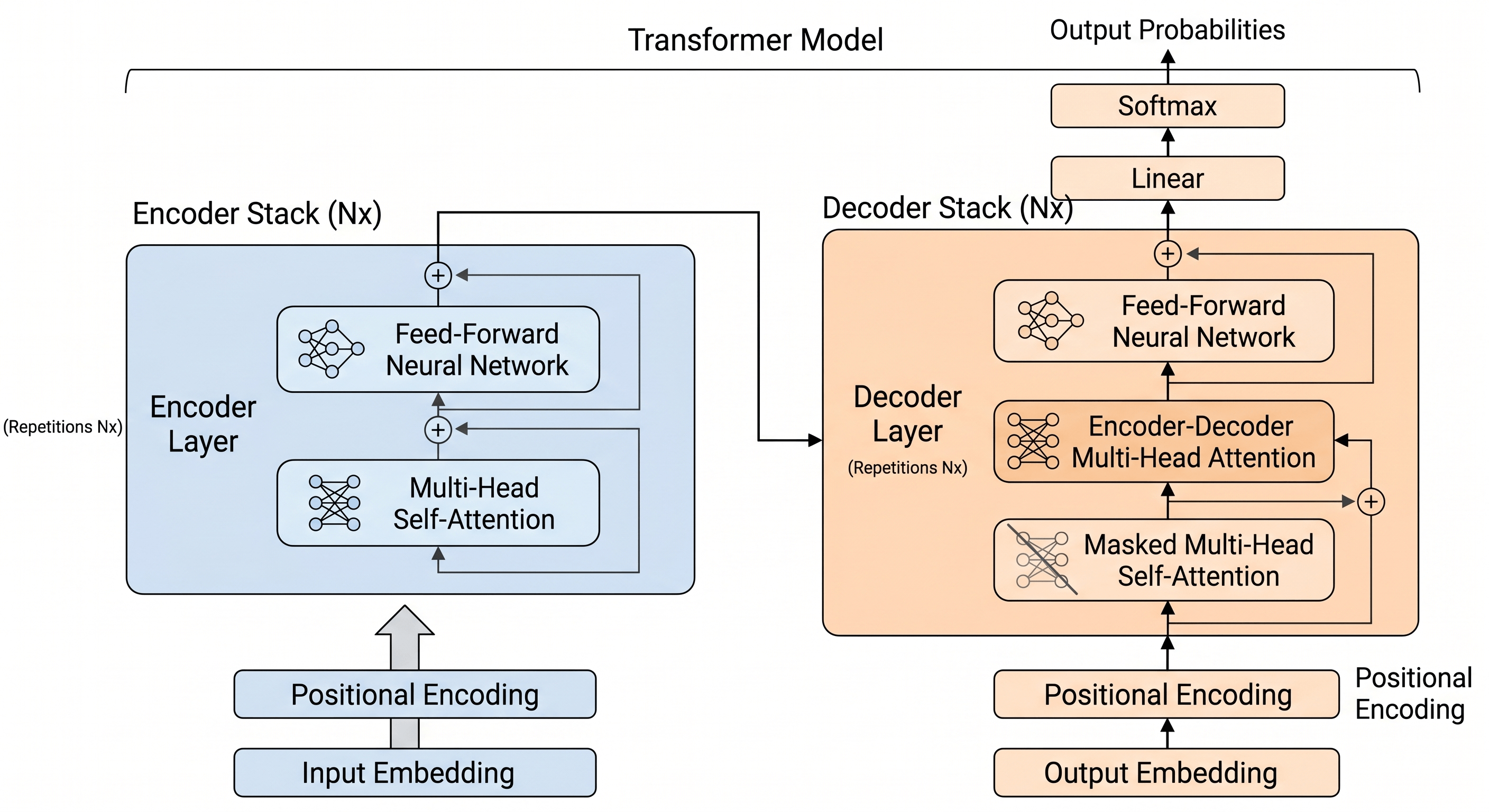
The Transformer Structure
Transformers consist of two primary blocks: Encoders and Decoders.
- Encoders: Process the input text to build a contextual understanding. Models like BERT (Bidirectional Encoder Representations from Transformers) are encoder-only, making them excellent for classification and sentiment analysis.
- Decoders: Autoregressively generate output text by predicting the next token based on previous tokens. Modern LLMs like the GPT (Generative Pre-trained Transformer) series are predominantly decoder-only architectures, optimized for generative capabilities.
Self-Attention Mechanism
The core of the Transformer is the self-attention mechanism, which determines how much "focus" or "weight" a word in a sentence should place on every other word, regardless of their positional distance.
Computationally, this is achieved by creating three vectors for each token: Query (Q), Key (K), and Value (V). The attention score is calculated by taking the dot product of the Query and Key matrices, scaling it, applying a softmax function to normalize the values into probabilities, and multiplying the result by the Value matrix.
Expressed mathematically in plain text: Attention(Q, K, V) = softmax((Q * K^T) / √(d_k)) * V
Here, d_k represents the dimension of the key vectors. Scaling by the square root of d_k prevents the dot products from growing too large, which would push the softmax function into regions with extremely small gradients.
Master structured AI Engineering + GenAI hands-on, earn IIT Roorkee CEC Certification at ₹40,000
AI Engineering Course Advanced Certification by IIT-Roorkee CEC
A hands on AI engineering program covering Machine Learning, Generative AI, and LLMs - designed for working professionals & delivered by IIT Roorkee in collaboration with Scaler.
Enrol NowTransform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Positional Encoding
Because Transformers process all tokens simultaneously rather than sequentially, they inherently lack an understanding of word order. To resolve this, positional encodings are injected into the input embeddings. These are calculated using sine and cosine functions of different frequencies, allowing the model to derive the relative and absolute position of each token in the sequence.
How Are Large Language Models Trained?
Training an LLM is an exercise in massive-scale distributed computing, often requiring thousands of GPUs running continuously for months. The training pipeline is highly structured and split into distinct phases, each serving a specific purpose in transforming a statistical word-calculator into a helpful, conversational AI agent.
Phase 1: Unsupervised Pre-Training
In this initial phase, the model is exposed to a vast corpus of text scraped from the internet, books, code repositories, and articles. This dataset typically comprises trillions of tokens. The training objective is simple: next-token prediction. Given a sequence of text, the model must predict the probability distribution of the subsequent word.
During pre-training, the model learns grammar, syntax, factual knowledge, reasoning capabilities, and even coding languages. However, the resulting "base model" is not an assistant; it is merely a document completer. If you prompt a base model with "What is the capital of France?", instead of answering "Paris," it might continue the pattern by outputting "What is the capital of Germany?". Optimization is typically achieved using the Cross-Entropy Loss function, updating billions of parameters via backpropagation.
Phase 2: Supervised Fine-Tuning (SFT)
To convert the base model into a useful conversational agent, developers apply Supervised Fine-Tuning. This involves retraining the model on a smaller, highly curated dataset of instruction-response pairs (e.g., Prompt: "Summarize this article," Response: "[Summary]"). SFT alters the model's weights so that it understands it should fulfill user instructions rather than just continuing the text.
Phase 3: Reinforcement Learning from Human Feedback (RLHF)
Even after SFT, a model might generate correct but unhelpful, toxic, or improperly formatted responses. RLHF aligns the model's behavior with human preferences.
- Reward Modeling: Humans rank multiple model-generated responses to a single prompt based on quality. A separate neural network (the Reward Model) is trained on these rankings to score responses automatically.
- Proximal Policy Optimization (PPO): The LLM generates responses, and the Reward Model scores them. The LLM then updates its internal policy using a reinforcement learning algorithm (typically PPO) to maximize the reward score. This step restricts the LLM from generating toxic content and makes its tone helpful and safe.
Real-World Applications and Use Cases of LLMs in Generative AI
The integration of Large Language Models into enterprise architectures is actively reshaping software engineering, data analysis, and digital communications. Because LLMs act as advanced reasoning engines, developers can expose their capabilities via APIs to automate complex workflows that previously required human cognition.
Natural Language Generation and SEO Content
In marketing and content strategy, LLMs are heavily utilized for bulk content generation, semantic SEO optimization, and localization. By analyzing search intent, LLMs can generate comprehensive articles, dynamically adjust tone, and structure H2 and H3 tags perfectly for web crawlers. Furthermore, localization engines use LLMs to translate technical documentation into dozens of languages, maintaining context far better than traditional rigid Machine Translation (MT) systems.
Sentiment Analysis and Data Extraction in Finance
In the financial sector, latency and informational accuracy are critical. Financial analysts leverage LLMs for algorithmic sentiment analysis. Unlike older Natural Language Processing models that only flagged words as "positive" or "negative," an LLM understands nuanced financial context. For example, it can read a dense 10-K report or a Federal Open Market Committee (FOMC) transcript and determine whether the overall sentiment implies impending inflation or a dovish economic policy. Developers frequently build pipelines that feed live news streams into an LLM to generate continuous sentiment scores, which are then passed into quantitative trading algorithms.
Turn Learning into Career Growth
Code Generation and Automated Debugging
LLMs are deeply integrated into modern Integrated Development Environments (IDEs) via tools like GitHub Copilot and Codeium. Because their pre-training data includes millions of GitHub repositories, they excel at boilerplate generation, writing unit tests, and refactoring legacy code.
Developers can easily integrate LLM capabilities into their applications using standard API calls. Here is an example in Python demonstrating how a developer might prompt an LLM to perform sentiment analysis on financial data using the OpenAI API:
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Risks, Ethics, and Limitations of LLMs
Despite their transformative potential, Large Language Models carry significant architectural and functional limitations. Engineering teams must design system architectures that mitigate these flaws, particularly when deploying to production environments where unpredictable software behavior is unacceptable.
The Hallucination Problem
Because LLMs are probabilistic models predicting the next most likely token, they do not inherently possess a concept of factual "truth." When an LLM lacks the specific data required to answer a prompt, it will often generate a highly confident but entirely fabricated response—a phenomenon known as hallucination. In software systems, this non-determinism requires mitigation strategies such as grounding the model via Retrieval-Augmented Generation (RAG), which forces the model to cite specific facts retrieved from a trusted database before answering.
The degree of hallucination can be partially controlled via inference parameters:
- Temperature: Controls the randomness of the token selection. A temperature of 0.0 results in highly deterministic, repetitive outputs (best for coding or JSON extraction), while higher values (e.g., 0.8) increase creativity but also the likelihood of hallucination.
- Top-P (Nucleus Sampling): Restricts the model to choosing only from a subset of tokens whose cumulative probability exceeds a certain threshold (p).
High Computational Complexity and Memory Constraints
The self-attention mechanism at the core of the Transformer architecture has a time and space complexity of O(N²), where N is the length of the input sequence. This means that if you double the length of the prompt, the computational cost quadruples.
This creates severe limitations on the model's "Context Window"—the maximum number of tokens it can process in a single prompt. To process long documents, the model must store the Key and Value matrices in memory (known as KV Caching). For large batches or long context windows, KV cache memory requirements can quickly exceed the VRAM of standard enterprise GPUs (e.g., NVIDIA A100 or H100), creating bottlenecks in production inference.
Data Privacy, Bias, and Security
Since LLMs are trained on vast swaths of internet data, they inadvertently absorb human biases, proprietary code, and potentially sensitive information. If a user inputs proprietary source code or PII (Personally Identifiable Information) into a public LLM prompt, that data may be captured by the host company to retrain future models. As a result, enterprise developers are increasingly turning to self-hosting open-weight models (like LLaMA 3 or Mistral) inside Virtual Private Clouds (VPCs) to ensure strict data governance.
Advanced Architectures: Extending LLM Capabilities
To overcome the inherent limitations of standard Large Language Models, the machine learning community is rapidly iterating on architectural enhancements and pipeline integrations. Understanding these advanced paradigms is critical for developers tasked with building modern AI infrastructure.
Retrieval-Augmented Generation (RAG)
Rather than fine-tuning an LLM on proprietary data—which is expensive and prone to becoming outdated—developers use Retrieval-Augmented Generation. RAG separates the knowledge base from the language model. When a user submits a query, the system first transforms the query into a vector embedding. It then searches a Vector Database (such as Pinecone, Milvus, or pgvector) for the most semantically relevant document chunks. These chunks are appended to the user's prompt as context, and the LLM synthesizes an answer based strictly on the retrieved data. This drastically reduces hallucinations and allows the model to access real-time information.
Mixture of Experts (MoE)
As models grow past a trillion parameters, running inference becomes computationally prohibitive. The Mixture of Experts (MoE) architecture solves this. Instead of activating every parameter for every prompt, an MoE model consists of multiple smaller "expert" sub-networks. When a prompt is submitted, a "router" network determines which experts are best suited to handle the request (e.g., routing math questions to a math expert, and translation to a linguistics expert). This allows for a massive total parameter count while keeping active compute costs low.
Model Quantization
Running a 70-billion-parameter LLM at standard 16-bit floating-point (FP16) precision requires approximately 140 GB of VRAM. To make LLMs deployable on consumer hardware and edge devices, engineers use Quantization. This technique compresses the model weights from 16-bit floats to 8-bit or 4-bit integers (INT8, INT4) using formats like GGUF or AWQ. While this causes a minor degradation in reasoning quality, it vastly reduces memory usage and speeds up inference latency.
The Future of LLMs and Generative AI
The trajectory of large language models is moving toward multi-modality and autonomous agents. Current state-of-the-art models are no longer purely text-based; they are natively multimodal. They can ingest an image of a UI wireframe and output the corresponding React frontend code, or listen to an audio file and generate structured meeting minutes.
Furthermore, the future belongs to "Agentic AI." Rather than passively waiting for a prompt, LLM-backed agents are being designed to operate autonomously. A developer can give an LLM an objective (e.g., "Find the memory leak in this repository, write a patch, and submit a pull request"), and the model will iteratively use tools, run code in sandboxed environments, debug its own errors, and execute the final action without human intervention.
As LLMs continue to evolve, they will transition from being mere chat interfaces to serving as the core reasoning engines embedded deeply within enterprise software architecture.
Frequently Asked Questions (FAQs)
What is the main difference between an LLM and Generative AI? Generative AI is a broad umbrella term for artificial intelligence systems capable of creating new data, including text, images, video, and audio. An LLM is a specific sub-category of generative AI focused exclusively on processing and generating sequential text and code using Transformer architectures.
What is an LLM in generative AI used for? LLMs are utilized for complex natural language processing tasks. Common use cases include semantic search, text summarization, language translation, sentiment analysis, code generation, and functioning as conversational AI assistants (chatbots).
What is a "parameter" in an LLM? A parameter is a numerical value (a weight or bias) inside the neural network that determines how input data is mathematically transformed into an output. During the training phase, these parameters are adjusted through backpropagation to minimize the model's error. Larger parameter counts generally allow models to capture more complex linguistic nuances.
Can Large Language Models be trained on private company data? Yes, developers can train or customize LLMs on proprietary data using two main methods: Supervised Fine-Tuning (SFT) for adapting the model's behavior and tone, or Retrieval-Augmented Generation (RAG) for connecting the model to a secure, real-time database without permanently altering the underlying neural network weights.
Why do Large Language Models hallucinate? LLMs hallucinate because they do not query a database of verified facts; they calculate the statistical probability of the next word in a sequence. If the model encounters a prompt outside its training distribution, it will statistically piece together a coherent, highly confident sequence of tokens that is factually incorrect.