Amazon Kendra
Overview
AWS Kendra is a highly accurate and intelligent search service that enables your users to search unstructured and structured data using natural language processing and advanced search algorithms. It returns specific answers to questions, giving users an experience that's close to interacting with a human expert. It is highly scalable and capable of meeting performance demands, tightly integrated with other AWS services such as Amazon S3 and Amazon Lex, and offers enterprise-grade security.
Introduction to Amazon Kendra
A widespread tool known as The Amazon Forecast is an intelligent search engine powered by machine learning (ML). For users' websites and applications, Amazon Kendra reimagines business searches so that users' employees and customers can easily find the information they require, even if it is dispersed across numerous locations and content repositories within the organization. With Amazon Kendra, users can stop sifting through heaps of unstructured data and instead find the appropriate responses to their questions whenever they need them. There is no need to set up servers, train, or deploy machine learning models since Amazon Kendra is a fully managed service. Use natural language inquiries and essential keywords to acquire the information you need. Whether it's a text excerpt, FAQ, or PDF file, Amazon Kendra will offer a detailed response from within. Amazon Kendra provides recommendations up front rather than requiring the user to sift through extensive lists of papers in quest of specific solutions. A service that provides intelligent search capabilities for websites and applications is often referred to as Amazon Kendra. Thanks to this service, employees can quickly locate the information they need even when it is spread across multiple places and get the correct responses to their questions whenever they need them.
- Amazon Kendra is a machine learning-powered intelligent search service. Kendra reinvents enterprise search for your websites and applications so that your employees and customers can simply discover the content they need, even if it is spread across many locations and content repositories inside your organization.
- You can prevent searching through troves of unstructured data and instead find the right answers to your inquiries when you need them with Amazon Kendra. Because Amazon Kendra is a fully managed service, there are no servers to set up and no ML models to create, train, or deploy.
How Does It Work?
Your application gets search functionality from AWS Kendra. It intelligently offers pertinent information to your consumers while indexing your papers directly or via your third-party document repository. A searchable index of documents of many forms, such as plain text, HTML files, Microsoft Word documents, Microsoft PowerPoint presentations, and PDF files, can be made using Amazon Kendra. Other services are integrated with AWS Kendra. To help consumers with their inquiries, you may leverage AWS Kendra search to power Amazon Lex chatbots. You can use an Amazon Simple Storage Service bucket as a data source for Amazon Kendra to connect to and index your documents. Additionally, you can configure resource rights or access policies using AWS Identity and Access Management.
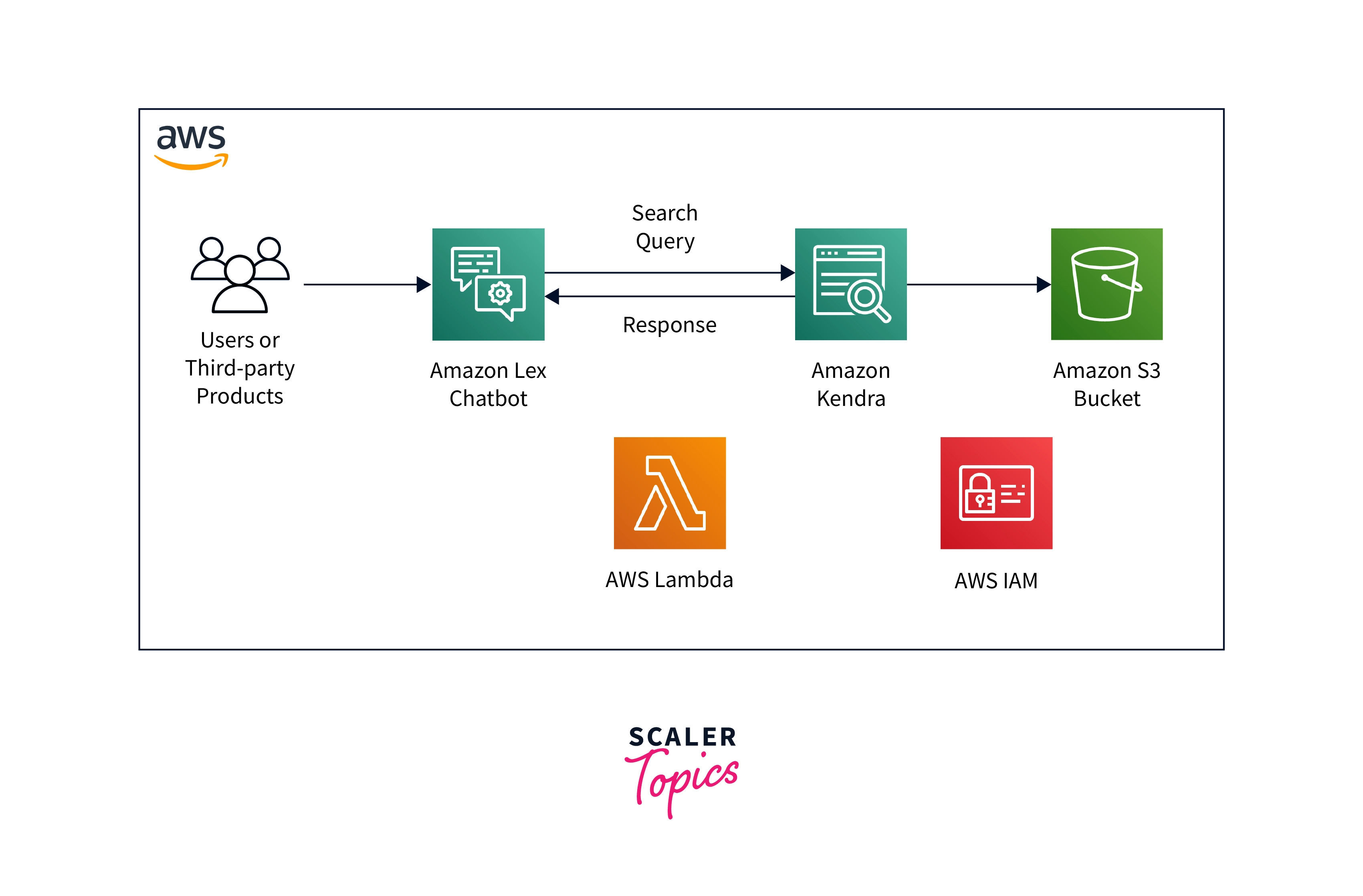
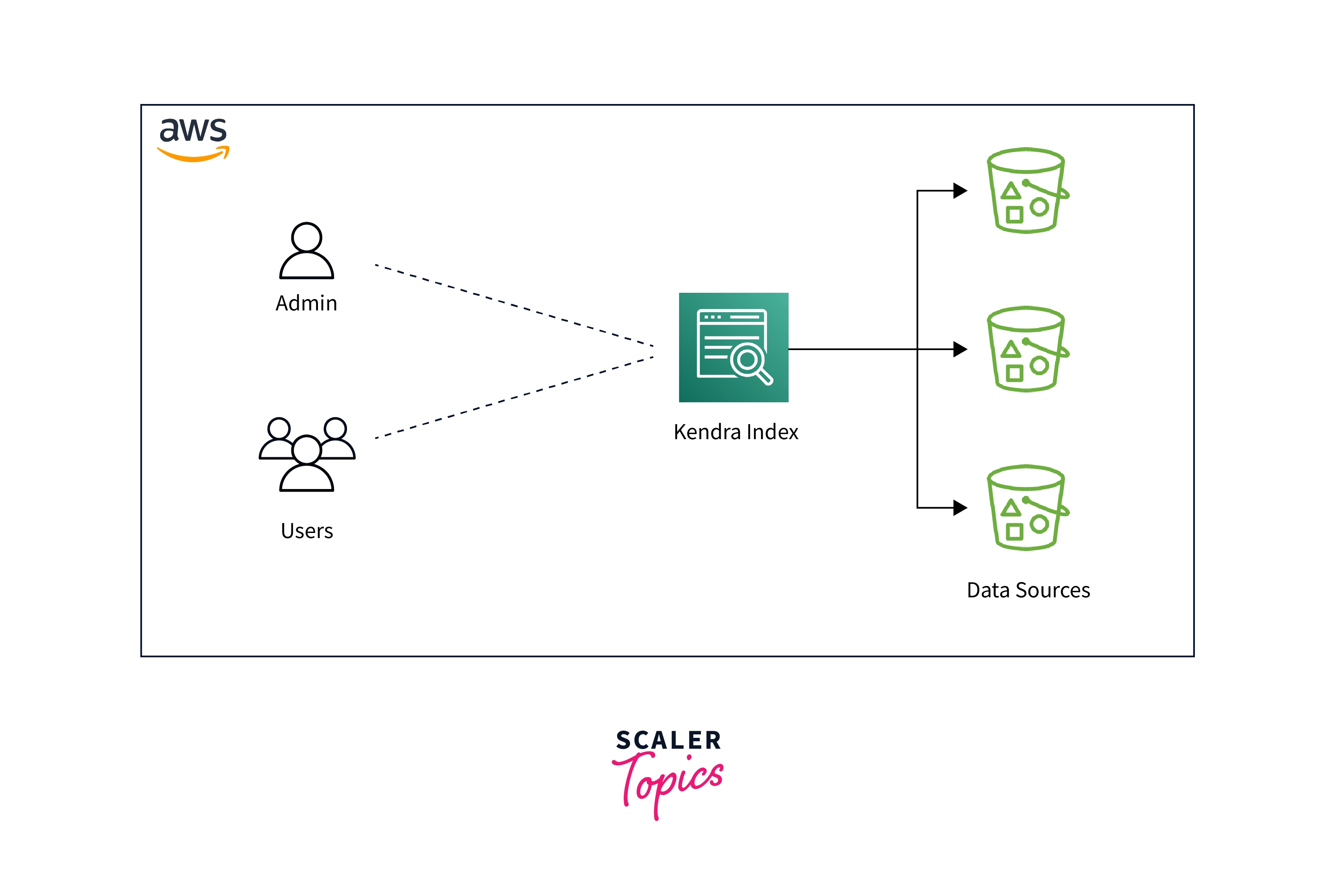
The following components are present in Amazon Kendra:
- A searchable index that keeps your documents in one place.
- A data source to which Amazon Kendra connects and stores your files. To keep your index current with your source repository, you can automatically synchronize a data source with an Amazon Kendra index.
- An document addition API for adding documents directly to an index.
Both the interface and the API are available for using Amazon Kendra. Indexes can be created, modified, and removed. In addition to permanently deleting all of your document information on Amazon Kendra, deleting an index also deletes all of its data source connectors.
Concepts
Index
Your documents' contents are stored in an index, which is organized so you may search through them. Depending on how you save your documents, you can add them to the index in various ways in AWS Kendra.
- A data source connection is used to index your documents from a repository, such as an Amazon S3 bucket or a Microsoft SharePoint site if you keep your documents there.
- If you don't keep your documents in a repository, you can directly index them using the BatchPutDocument API.
- You upload the FAQs from the bucket for those that must be kept in an Amazon Kendra (Amazon S3) container.
Index Fields
You can map the fields in an index to the document's attributes. The document title, body text, last modified date, and other features found in your documents' structure are a few examples of attributes. Additionally, you can add your unique properties, like the figure's description or the business unit it belongs to. Your index's structure is provided by the index fields that you map to the characteristics of your documents. AWS Kendra uses the fields to search your documents. You can utilize the data in the field for searching after mapping it to your document properties.
You can map the following 15 reserved fields in Amazon Kendra to the properties of your document:
- _authors- A list of the author(s) who contributed to the document's content.
- _category - A classification that assigns a document to a particular group.
- _created_at - The ISO 8601 formatted date and time the document was created. For instance, the ISO 8601 date-time format for March 25, 2012, at 12:30 PM (plus 10 seconds), in Central European Time, is 2012-03-25T12:30:10+01:00.
- _data_source_id- The name of the data source that the document is located in.
- _document_body—The content of the document.
- _document_id-A unique identifier for the document.
- _document_title—The title of the document.
- _excerpt_page_number-A PDF file's page number where the document extract can be found. You cannot use this characteristic if your index was made before September 8, 2020; you must re-index your documents.
- _faq_id-If these are the questions and answers from a FAQ, give them a special designation.
- _file_type-The document's file format, such as PDF or DOC.
- _last_updated_at-The date and time the document was last modified in ISO 8601 format. For instance, in Central European Time, the ISO 8601 date-time format for March 25, 2012, at 12:30 PM (plus 10 seconds), is 2012-03-25T12:30:10+01:00.
- _source_uri-The URL of the document's location. For instance, the document's URI on a business website.
- _version—An identifier for the specific version of a document.
- _view_count—The number of times that the document has been viewed.
- _language_code (String)-The language's code that pertains to the document. If you do not choose a language, English is used by default. See Adding documents in languages other than English for additional details on supported languages, including their codes.
Additionally, you can build custom fields, which you can utilize similarly to reserved fields for facet creation, search, and display. Four different types of custom fields exist:
- Date
- Number
- String
- String list
You can add a custom field using the UpdateIndex API or the console. Like with a reserved field, you map a custom field to a document attribute after it has been created. If you use the BatchPutDocument API to add a document to the index, you could use the API to map the attributes. A metadata file with a JSON structure describing the document attributes is used to map the attributes for documents indexed from an Amazon S3 data source. You map characteristics with the console or the data source settings for documents indexed with a database or data source that permits field mapping. See Searching indexes for further details.
Searching Indexes
Use the Query API to search an Amazon Kendra index. When you use the Query API, it details the indexed documents you've used in your program.
Documents
Types of Documents
Both organized and unstructured text may be included in an index:
- Structured text
- Frequently asked questions and answers
- Unstructured text
- HTML files
- Microsoft PowerPoint presentations
- Microsoft Word documents
- Plain text documents
- PDFs
Calling the BatchPutDocument API will allow you to directly add documents to an index. Adding documents from a data source is another option. See Adding documents from a data source for further details. See Adding documents from an Amazon S3 bucket for an example that demonstrates how to add Microsoft Word documents from an Amazon S3 bucket straight to an index. Multiple documents and various document kinds may be included in an index.
HTML
Files in HTML format. Similar to a plain text file, you can add an HTML file to an index.
Plain Text
Using a data source or the BatchPutDocument API, you can add plain text files to an index. See Adding documents with the API for an example of how to add a plain text document directly to an index.
Microsoft Word Document
Binary data, data from a data source, or files from an Amazon S3 bucket can all be used to add Microsoft Word format files to an index.
Microsoft PowerPoint Document
Microsoft PowerPoint format files may be retrieved from a data source, an Amazon S3 bucket, or both to be uploaded as binary data to an index.
Portable Document Format (PDF)
A data source, an Amazon S3 bucket, or binary data can all be used to add PDF format files to an index.
Frequently Asked Questions and Answers
To respond to queries like "How tall is the Space Needle?" frequently asked questions and answers are used. Multiple questions with the same response might be specified. The questions and responses are specified in a CSV file that is kept in an Amazon S3 bucket.
See Adding questions and answers directly to an index for a good demonstration.
Document Attributes
A document is associated with specific properties in AWS Kendra. The characteristics of a document or what is contained within its structure are its attributes. For instance, each of your documents might include a title, a body of text, and an author. Additionally, you can add unique features to your documents. Custom attributes are those that you designate for your requirements. You may, for instance, add a custom attribute for the type of tax document, such as W-2, 1099, and so on, if your index searches for tax documents. A document attribute needs to be mapped to an index field before it can be used in a query. For instance, the field _document title can be mapped to the title attribute. See Mapping fields for more details. You must make an index field to which the new attribute will be mapped before you can add it. You can build index fields by using the UpdateIndex API or the console. Document properties can be used to filter results and generate faceted search suggestions. For instance, you can filter a response to only return a particular version of a document or a search to only return tax documents of the 1099 kind that are relevant to the search phrase. See Filtering queries for further details. You can manually adjust the query response using document characteristics as well. For instance, you can decide to make the title field more significant so that Amazon Kendra would give it more weight when determining which documents to return in the answer. See Tuning search relevance for further details.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Data Sources
A data source is a site or data repository that AWS Kendra connects to index your material or documents. For instance, you may set up Amazon Kendra to connect to Microsoft SharePoint and crawl and index your documents there. You can also index by giving Amazon Kendra the URLs for your web pages. A data source and an AWS Kendra index can be synchronized automatically. Any documents added, modified, or removed from the data source are added, updated, or deleted from the index.
Sources of supported data include:
- Alfresco
- Amazon S3 buckets
- Amazon RDS for MySQL, Amazon RDS for PostgreSQL, Amazon Aurora MySQL, Amazon Aurora PostgreSQL databases
- Amazon Kendra Web Crawler
- Amazon WorkDocs
- Amazon FSx
- Atlassian Confluence
- Box
- Custom data sources
- Dropbox
- GitHub
- Google Workspace Drives
- Jira
- Microsoft OneDrive
- Microsoft SharePoint
- Quip
- Salesforce
- ServiceNow
- Slack
- Zendesk
Queries
Users ask index questions to get replies. Users can ask questions in everyday language. The response includes details such as the title, a text extract, and the index entry for the document that best answers the question. To evaluate if a document is pertinent to the inquiry, Amazon Kendra considers all the details you supply about your papers, not just their contents. You can instruct Amazon Kendra to give more relevance to recently changed documents, for instance, if your index includes information about when documents were last updated. For Amazon Kendra to return only the documents that meet the filter requirements, a query can also include criteria for how to filter the result. You can restrict the answer so that only documents with the department field set to legal are returned, for instance, if you built an index field called the department. See Filtering queries for further details. By adjusting the relevance of specific index fields, you can affect how a query is answered. A field's impact on the outcomes can be tuned. Documents with the category new, for instance, are more likely to be included in the answer if you stress their relevance. See Tuning search relevance for further details.
Tags
By allocating tags or labels, you may manage your databases, FAQs, and indexes. Your Amazon Kendra resources can be categorized in several ways using tags. For instance, by owner, application, purpose, or any combination of these. You define the key and value for each tag, which are both components of each tag. Tags assist you in:
- You should list and arrange your AWS resources. The same tag can be applied to resources in many AWS services to show that the resources are connected. This is possible because many AWS services support tagging. For instance, you can use the same tag to identify an index and the Amazon Lex bot that uses it.
- Assign costs. On the AWS Billing and Cost Management dashboard, tags are activated. AWS categorizes your expenses using tags, sending you a monthly cost allocation report.
- Restrict who has access to your resources. In AWS Identity and Access Management (IAM) policies that regulate access to Amazon Kendra resources, tags can be used. To implement tag-based access restrestrictionsu can add these policies to an IAM role or user. See Authorization based on Amazon Kendra tags for further details.
Tagging Resources
Resources can be tagged when they are created if you use the Amazon Kendra console, or you can add tags later. The console can also be used to add or remove tags.
Use the following actions to manage tags for your resources if you're using the Amazon Kendra API or the AWS Command Line Interface (AWS CLI):
- CreateDataSource—Apply tags when you create a data source.
- CreateFaq—Apply tags when you create an FAQ.
- CreateIndex—Apply tags when you create an index.
- ListTagsForResource—View the tags associated with a resource.
- TagResource—Add and modify tags for a resource.
- UntagResource—Remove tags from a resource.
Tag Restrictions
The following restrictions apply to tags on Amazon Kendra resources:
- Maximum number of tags—50
- Maximum key length—128 characters
- Maximum value length—256 characters
- Valid characters for key and value—a–z, A–Z, space, and the following characters: _ . : / = + - and @
- Keys and values are case sensitive
- Don't use aws: as a prefix for keys; it's reserved for AWS use
Amazon Kendra Connectors
This list's connectors were developed by Amazon. These connections enable you to include new data sources in the AWS Management Console's Amazon Kendra index.
- Alfresco On-Prem Connector- For indexing and searching documents in the Alfresco On-Prem Repository, use the Alfresco connection.
- Amazon Relational Database (RDS)- You can use the Amazon RDS connector for Amazon Kendra to add files and data that are housed in an Amazon RDS location to your Amazon Kendra index.
- Amazon Simple Storage Service (S3)- The Amazon Simple Storage Service (S3) connection for Amazon Kendra can be used to upload files and information located in an S3 bucket to your Amazon Kendra index.
- Amazon FSx- Documents from FSx file systems for Windows File Server file systems are indexed by Amazon Kendra FSx Connector. In addition to offering completely managed shared storage based on Windows Server, Amazon FSx for Windows File Server offers a broad range of administrative, data management, and data access features.
- Atlassian Confluence - The Confluence connector for Amazon Kendra indexes content from on-premise server instances, including pages, blog posts, attachments, comments, spaces, profiles, and hub sites, for tags. The Confluence document access properties are supported by the connector.
- Atlassian Confluence Cloud- Pages, blog posts, attachments, comments, spaces, profiles, and hub sites are all indexed for tags in cloud-based Confluence sources via Amazon Kendra's connection for Confluence Cloud. The Confluence document access properties are supported by the connector.
- Box Connector- For indexing and searching documents in a Box Enterprise repository, use the connection.
- Dropbox Connector- Connector for the Dropbox Repository that indexes and searches documents.
- Jira Connector- Connector for Jira that allows you to index and search documents in Jira Cloud.
- Microsoft OneDrive- The Microsoft OneDrive connector for Amazon Kendra indexes files and folders and fully supports Azure Active Directory and OneDrive's document access features. Additionally, tenants for Office365 and federated authentication are supported.
- Microsoft SharePoint Online- With support for document access attributes, Amazon Kendra's connection for SharePoint Online indexes the data and information in SharePoint Online repositories.
- Quip Connector- Quip connector for indexing and searching documents in a Quip Enterprise repository.
- GitHub On-Prem Connector- GitHub connector for GitHub Enterprise Server data source for document indexing and searching.
- GitHub SaaS Connector-GitHub connection for indexing and searching documents in the data source repository for the GitHub Enterprise Cloud.
- ServiceNow- The ServiceNow connector for Amazon Kendra indexes service catalog entries and attachments as well as knowledge articles and attachments from ServiceNow's public knowledge bases.
- Salesforce- Accounts, profiles, leads, cases, and many more typical items kept in Salesforce are indexed by Amazon Kendra's connector. The connector supports all document attributes in Salesforce.
- Slack Connector- Kendra Slack Connector will index messages and use Kendra Intelligent Search to look up information across this content.
- Google Drive- The Google Drive connector for Amazon Kendra indexes files from individual and team drives as well as Google Docs and Google Slides. The connector enables document access attributes in addition to the built-in permission model for Google Drive.
- Custom Data Source Connector- Users can use the Kendra API to build their own custom connectors and push content straight into Amazon Kendra using the connector for custom data sources in Amazon Kendra.
- Web Crawler- For indexing and searching online pages and other materials made available on websites, use Amazon Kendra's web crawler. Robots.txt access restrictions are respected by web crawlers. To provide users with search results, users must make sure they are permitted to index websites.
- Sharepoint 2013 Connector- SharePoint connector for indexing and searching documents from a Microsoft SharePoint 2013 Server.
- Sharepoint 2016 Connector- Connector for SharePoint that allows you to search and index documents on a Microsoft SharePoint 2016 server.
- WorkDocs Connector- The WorkDocs connector for Amazon Kendra allows users to search and index documents from WorkDocs on Amazon.com. With the help of Amazon Kendra's intelligent search, you may index documents in HTML, PDF, MS Word, MS PowerPoint, and plain text.
- Zendesk Connector- Zendesk connector for indexing and searching documents in Zendesk Repository.
Please visit this link to know more about AWS Kendra Connectors
Features of Amazon Kendra
An intelligent search engine powered by machine learning is called Amazon Kendra (ML). Kendra reimagines enterprise search for your websites and applications so that your customers and workers can discover the stuff they're searching for with ease, even if it's dispersed across numerous locations and content repositories inside your business.
Intelligent Search
ML is used by Amazon Kendra to extract more pertinent information from unstructured data. If you type in generic terms like "health benefits" or ask queries in plain English like "How long is maternity leave?" Amazon Kendra will use reading comprehension to provide precise responses like "14 weeks." about more basic inquiries like "How can I configure my VPN?" Amazon Kendra extracts the most pertinent text passage and uses it to provide detailed responses. A specific model was used by Amazon Kendra to extract responses from curated FAQs and facilitate FAQ matching by identifying the closest question and returning the associated answer. Amazon Kendra utilizes a deep learning semantic search model for precise document rating in addition to extracted responses and FAQ matching. This offers a richer search experience that delivers accurate solutions and associated stuff to explore if you need more information.
Incremental Learning
ML is used by Amazon Kendra to continuously improve search results based on end-user feedback and search behavior. For instance, when people ask, "How do I modify my health benefits?" Different HR benefit documents will contend for the top slot. Amazon Kendra will learn from user interactions and feedback to move favored documents to the top of the list to discover which is the most pertinent document for this query. Without requiring ML expertise, Amazon Kendra automatically implements incremental learning strategies.
Tuning and Accuracy
Based on specific business objectives, you can fine-tune search results and elevate particular responses and documents in the results. For instance, relevance tweaking enables you to enhance results based on more reliable authors, data sources, or document freshness. You can add your unique synonyms to expand further Amazon Kendra's comprehension of the words you use in your particular line of business. These are used by Amazon Kendra to automatically expand queries to incorporate information and solutions that adhere to the expanded vocabulary. For instance, a user might inquire, "What is an HSA?" Documents with the abbreviation "HSA" or "Health Savings Account" would be returned by Amazon Kendra.
Connectors
Add data sources to your Amazon Kendra index and choose the connector type to start using connectors quickly and easily. To ensure that you are always safely browsing through the most recent content, connectors can be scheduled to automatically sync your index with your data source. For well-known data sources, like Amazon Simple Storage Service (S3), Microsoft SharePoint, Salesforce, ServiceNow, Google Drive, Confluence, and many more, Amazon Kendra provides native connectors. If a native connector is not offered, Amazon Kendra offers a variety of partner-supported connectors and a custom data source connector.






Domain Optimization
Amazon Kendra employs deep learning models to comprehend natural language queries and document content and structures for various internal use cases, including HR, operations, support, and R&D. The understanding of complex language from industries like IT, financial services, insurance, pharmaceuticals, industrial manufacturing, oil and gas, legal, media and entertainment, travel and hospitality, health, news, telecommunications, mining, food and beverage, and automotive is another goal of Amazon Kendra's. For instance, a user looking for HR information may type "deadline for filing HSA form," and Amazon Kendra would also perform a search for "deadline for filing health savings account form" for more complete results.
Experience Builder
With Amazon Kendra, you can now quickly and easily launch a fully working and configurable search experience without any coding or machine learning expertise. To promptly develop, customize, and launch your Amazon Kendra-powered search application safely on the cloud, Experience Builder offers a straightforward visual approach. You can start with the builder's ready-to-use search experience template and then personalize it by dragging and dropping the desired elements, such as filters or sorting. When ready to roll out the experience, share the project with all users by inviting others to collaborate or test your search application for feedback.
Search Analytics Dashboard
Using the Amazon Kendra Search Analytics Dashboard, you may better understand quality and usability metrics across your Amazon Kendra-powered search applications. The Analytics Dashboard enables administrators and content producers to assess the quality of the search results, the ease with which end users find relevant search results, and any content gaps. The Amazon Kendra Search Analytics Dashboard gives you a quick view of how users interact with your search engine and how practical the results are. You can view the analytics data in the console's visual dashboard or create your dashboards using an API to access the Search Analytics data.
Custom Document Enrichment
You can create a unique ingestion pipeline that pre-processes documents before they are indexed into Amazon Kendra using the Custom Document Enrichment capabilities of Amazon Kendra. For instance, you can add more metadata to documents while ingesting content from a repository like SharePoint using our connectors, convert scanned documents to text, classify documents, extract entities, and further alter the composition using bespoke ETL procedures. Simple rules that may be set up in the console or by calling AWS Lambda functions carry out the enrichment. Other AWS AI Services like Amazon Comprehend, Amazon Transcribe, or Amazon Textract can optionally be contacted by these functions.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Query Autocompletion
An end user's search query can be automatically completed using Amazon Kendra. The user benefits from query autocompletion in two ways: it speeds up typing by around $25$% and directs them to more specific and often-asked inquiries. Usually, the responses to these queries are more pertinent and beneficial. For instance, Amazon Kendra can offer suggestions to complete your search if you begin typing "Where is" in the search bar, such as "Where is the IT desk?" or "Where is the cafeteria?" and other pertinent typical queries.
Amazon Kendra Use Cases
It Accelerates Research and Development
Scientists and developers in charge of new research and development who need access to data from earlier projects buried deep within their corporate data sources can do it with the help of Amazon Kendra. Due to faster and more accurate searches, they spend less time looking and more time creating.
It Minimizes Regulatory and Compliance Risks
To enhance policy enforcement and compliance operations, utilize machine learning to quickly find and analyze regulatory requirements posted across hundreds of different websites, made possible by Amazon Kendra.
It Enhances Interactions with Customers
Whether through Q&A chatbots, agent-assist, or consumer online searches, the Amazon Kendra provides more accurate and intuitive answers to your consumers' questions.
It Raises Employee Productivity
By integrating and indexing content from various dispersed, and multi-structured information silos throughout the organization, businesses can create and maintain a single dynamic knowledge library for all employees. Using this approach, users can quickly search and acquire the most pertinent information from any knowledge source, enabling them to make better decisions.
Integrate Search into SaaS Applications
AWS Kendra enables users to find information faster with ML-powered in-app search.
Turn Learning into Career Growth
Amazon Kendra Pricing
You only pay for the services you use with Amazon Kendra. There are no initial expenses. You are charged for Amazon Kendra hours from the time an index is created until it is erased after you provision Amazon Kendra. Billing for partial index instance hours is done in one-second chunks. Amazon Kendra is available in two versions. Kendra Enterprise Edition (KEE) offers a high-availability service ($1,000/month) for production workloads. Developers have a more affordable option ($810/month) called Kendra Developer Edition (KDE). However, it is not advised for use with production workloads.
Scaling
Customers that purchase the Kendra Enterprise Edition initially receive a base capacity of 100,000 searchable documents and a daily query limit of 8,000. Customers may quickly scale up and down by adding capacity units to support additional documents or daily inquiries (or both). Units with higher query and storage capacities can each accommodate 8,000 more daily queries and 100,000 documents, respectively.
Free Tier
With the Amazon Kendra Developer Edition, you can get started for nothing and use it for up to 750 hours for the first 30 days. Connector use is not eligible for free usage; normal run time and scanning costs will be charged. If you utilize more resources than allowed by the free tier, you will be charged at the Amazon Kendra Developer Edition prices for those extra resources.
Pricing Table
The capabilities listed below are made possible by the resources allocated for each of these editions.
| Developer Edition | Enterprise Edition | |
|---|---|---|
| Document Storage | Up to 10,000 docs** | Up to 100,000 docs** |
| Max Queries Per Day | 4,000 | 8,000*** |
| Data Sources | 5 | 50 |
| Availability Zones | 1 | 3 |
| Free Tier | Up to 750 hours for the first 30 days | N/A |
| Pricing per hour | $1.125 /hour | $1.4 /hour |
| Price per month | $810 | $1,008 |
| Additional Capacity Additional Document Storage Bundle * | None | $0.7 per hour per additional 100,000 docs** |
| Additional Capacity - Additional Query Bundle * | None | $0.7 /hour per additional 8,000 queries per day.*** |
| Connector Usage document scanned | $0.000001 per document | $0.000001 per document scanned |
| Connector Usage when syncing | $0.35 per hour per connector when syncing | $0.35 per hour per connector when syncing |
Depending on your demands, you can increase capacity by either boosting queries or storage, or both.
The maximum size for original documents is 50MB, with a maximum of 5MB of raw text per document. The enterprise model supports up to 30GB of total extracted text storage. The developer edition's maximum extracted text storage capacity is 3GB.
For more information about Kendra’s QPS (queries per second), please refer to the documentation.
Getting Started with Amazon Kendra
The steps below demonstrate how to use the AWS console to build and test an Amazon Kendra index. You establish an index and a data source for an index in the procedures. Finally, you run a search to evaluate your index.
Step 1: To Create an Index (console)
- Open the Amazon Kendra console via https://console.aws.amazon.com/kendra/ after logging into the AWS Management Console.
- Within the Indexes section, click Create index.
- Name and describe your index on the Specify index details page.
- Select Create a new role from the IAM role menu, then give the position a name. "AmazonKendra-" will be the prefix for the IAM role.
- Leave all of the other fields' default values in place. Select Next.
- Select Next on the Configure user access control page.
- Select the Developer edition option on the Provisioning information page.
- To construct your index, select Create.
- Wait for the creation of your index. The hardware is set up by Amazon Kendra for your index. This process can take some time.
Step 2: To add a Data Source to an Index (Console)
- View the data sources that you may use to index your documents with Amazon Kendra.
- Select Data sources from the navigation pane, and then click Add data source to add the data source of your choice.
- Configure the data source by following the instructions.
Step 3: To Search an Index (Console)
- Select the option to search your index from the navigation pane.
- Pick a search phrase that fits your index and enter it. The top outcomes and document outcomes are displayed.
Getting Started (AWS CLI)
The following procedure shows how to create an Amazon Kendra index using the AWS CLI. The procedure creates a data source, and index, and runs a query on the index.
To Create an Amazon Kendra Index (CLI)
- Enter the following command to create an index
- Wait for Amazon Kendra to create the index. Check the progress using the following command. When the status field is ACTIVE, go on to the next step.
- At the command prompt, enter the following command to create a data source.
If you connect to your data source using a template schema, configure the template schema.
- It will take Amazon Kendra a while to create the data source. Enter the following command to check the progress. When the status is ACTIVE, go on to the next step.
- Enter the following command to synchronize the data source.
- Amazon Kendra will index your data source. The amount of time that it takes depends on the number of documents. You can check the status of the sync job using the following command. When the status is ACTIVE, go on to the next step.
- Enter the following command to make a query.
- The results of the search are displayed in JSON format.
- Please visit this link to know more about Getting Started with AWS Kendra
Benefits of Amazon Kendra
- Get Answers Using Natural Language: Simple keywords can be used for searching. Whether your response is contained in the paper, FAQ, or PDF, it will provide superior results to the query. Additionally, rather than sifting through a lengthy list of documents, it will offer alternative solutions. In the image below, we can notice the difference in how it presents the search results.
- Access to the Content: With the help of Kendra, we can quickly access the material from many repositories, like SharePoint, Amazon S3, ServiceNow, and Salesforce, into a single index, enabling you to search through all of your data and discover the precise answer to any inquiry.
- Fine-Tune Search Results: We can fine-tune the search results by manually altering the significance of the data sources or by utilizing custom tags.
- Deploy with Just a Few Clicks: With a few clicks, we can set up an index, link relevant data sources, and start utilizing Kendra to look for solutions to our problems.
- Get Quick Answers with Search Intelligence: Forget crawling through a gigantic list of documents and links to get the relevant information. Using the Amazon Kendra technology allows natural language to perform searches. This search is quicker and more accurate as it is server-independent technology. This enterprise search uses machine learning (ML) to deliver relevant answers to queries. To increase the relevancy, AWS Kendra uses deep learning semantic search model for precise document ranking.
- Access Centralized Content Index: The best-in-class enterprise search technology used by Amazon Kendra allows access to content irrespective of content repositories. Various content repositories it uses are Amazon S3, Microsoft SharePoint, ServiceNow, and Salesforce. Along with this, the Amazon Relational Database Service (RDS) searches the enterprise data quickly. These repositories also help to get the most accurate answer or search query.
- Domain Optimization: Amazon Kendra uses deep learning models to comprehend natural language queries and document content and structures for a variety of internal use cases, including HR, operations, support, and research and development. Amazon Kendra is also designed to understand the complicated language from industries including IT, finance, pharmaceuticals, insurance, oil and gas, industrial manufacturing, legal, travel and hospitality, media and entertainment, health, news, telecommunications, food and beverage, mining, and automotive. To receive the most accurate answer, a user searching for HR answers may input "deadline for submitting HSA form," and Amazon Kendra would also search for "deadline for filing health savings account form.
- Query Autocompletion: Amazon Kendra can autocomplete a user's search input. Query autocompletion not only saves the user roughly 25% of their typing time, but it also guides them to more precise and often-asked inquiries. These inquiries usually provide more relevant and meaningful answers. For example, if you begin typing "Where is" in the search field, Amazon Kendra will suggest alternatives to complete the inquiry, such as "Where is the IT desk?" or "Where is the cafeteria?" and other related popular inquiries.
- Connectors: Connectors are simple to use, add data sources to your Amazon Kendra index and choose the connectivity type. Connectors can be configured to automatically sync your index with your data source, ensuring that you're always browsing through the most recent content. Amazon Kendra has native connectors for a variety of common data sources, including Amazon Simple Storage Service (S3), Microsoft ServiceNow, Google Drive, SharePoint, Salesforce, Confluence, and many more. If a native connector is unavailable, Amazon Kendra provides a custom data source connector as well as a number of partner-supported connectors.
Amazon CloudSearch vs Amazon Kendra
| Amazon CloudSearch | Amazon Kendra |
|---|---|
| AWS Cloud Search is built on Solr, a keyword search engine. | In contrast, Amazon Kendra is an ML-powered search engine that delivers more accurate search results over unstructured data, including Word documents, PDFs, HTML, PPTs, and FAQs |
| Amazon CloudSearch returns document lists like keyword engines | Amazon Kendra was built from the bottom up to handle natural language questions and offer detailed replies. |
| In Amazon CloudSearch, data must be formatted as a valid JSON or XML batch to be uploaded to your domain | On the other side, Amazon Kendra offers pre-built connectors that let users automatically index content into the Kendra index from well-known repositories like Sharepoint Online, S3, Salesforce, Servicenow, etc |
| It supports Automatic Scaling For Data | It supports Reading comprehension & FAQ matching |
| Audiences include Websites that want a powerful search functionality that integrates with AWS | Audiences Includes Organizations that want a powerful enterprise search functionality for their website or intranet |
| Integrations are supported with Amazon S3,Beats,CopperEgg,Datadog,and Martini | Integrations are not with Amazon S3,Beats,CopperEgg,Datadog,Martini |
| Pricing - $0.059 per Hour | Pricing - $2.50 per hour |
- Amazon Kendra might be a better option, depending on your use case, particularly if you're looking at the service for enterprise search applications or even website searches where more robust language comprehension is necessary.
Companies Using Amazon Kendra
- 3M: Multinational company 3M, established in Minnesota, manufactures a wide range of goods, including adhesives and medical supplies.
- Wall Street Journal(WSJ): Since 1889, decisions that advance the globe have been informed by the unmatched insight and distinctive reporting of The Wall Street Journal.
- Gilead Sciences: A biopharmaceutical firm with a research-based foundation, Gilead Sciences, Inc. is dedicated to the development, commercialization, and discovery of novel medications. Gilead focuses on the study and creation of drugs and antiviral technology, including potential cures for HIV and viral hepatitis.
- InpharmD: A mobile-based academic network of drug information centers called InpharmD combines pharmacy expertise with artificial intelligence to offer curated, research-based answers to clinical questions.
- Sage: With more than 3 million clients globally, Sage is a UK-based provider of business management software and services (covering accounting and payroll, finance and operational management, HR and people management, and customer relationship management).
Conclusion
- In this article, we learned about Amazon Kendra and its key features, including Query autocompletion, Custom Document Enrichment, Search Analytics Dashboard, etc.
- We also learned how Amazon Kendra works and looked through the three key components, index, data source, and document addition API, which are its core architecture.
- This article also covered some of the critical concepts in Amazon Kendra, which mainly covered how searching indexes work. Also, it covered all the types of documents that Amazon Kendra supports.
- In the end, we discussed the critical difference ibetweenAmazon Kendra and Amazon CloudSearch, which explained how CloudSearch only supports its functioning in only JSON and XML formatted documents.