Multi-Master ( Aurora )
Overview
The master is the only server active for client interaction. A pair of masters can be set up in an active-active read-write configuration using an Aurora multi-master arrangement, and the user can later grow the configuration up to a maximum of four masters as needed. This setup improves fault tolerance within the computational layer by allowing you to read from and write to any of the authorized master instances.
Introduction to Aurora Multi-Master Clusters
Most kinds of Aurora clusters are single-master clusters. For example, provisioned, Aurora Serverless, parallel query, and Global Database clusters are all single-master clusters. In a single-master cluster, a single DB instance performs all write operations and any other DB instances are read-only. If the writer DB instance becomes unavailable, a failover mechanism promotes one of the read-only instances to be the new writer.
Amazon Aurora Multi-Master, which allows uptime-sensitive applications to achieve continuous write availability across instance failure, is now broadly available. It lets you build several read-write instances of your Aurora database across multiple Availability Zones.
Multi-master clusters work differently in many ways from the other kinds of Aurora clusters, such as provisioning, Aurora Serverless, and parallel query clusters. With multi-master clusters, you consider different factors in areas such as high availability, monitoring, connection management, and database features. A multi-master cluster, for instance, can help to prevent an outage when a writer instance becomes unavailable in applications where even minimal downtime for database write operations cannot be tolerated. The multi-master cluster doesn't use the failover mechanism, because it doesn't need to promote another DB instance to have read/write capability. With a multi-master cluster, you examine metrics related to data manipulation language(DML) throughput, latency, and deadlocks for all DB instances instead of a single primary instance.
Architecture of Aurora Multi-Master Clusters
The architecture of multi-master clusters differs from those of other Aurora cluster types. All DB instances in multi-master clusters can read and write data. While all other DB instances in other types of Aurora clusters are read-only and only capable of handling SELECT queries, one dedicated DB instance handles all write activities. A primary instance or read-only Aurora Replicas are not present in multi-master clusters.
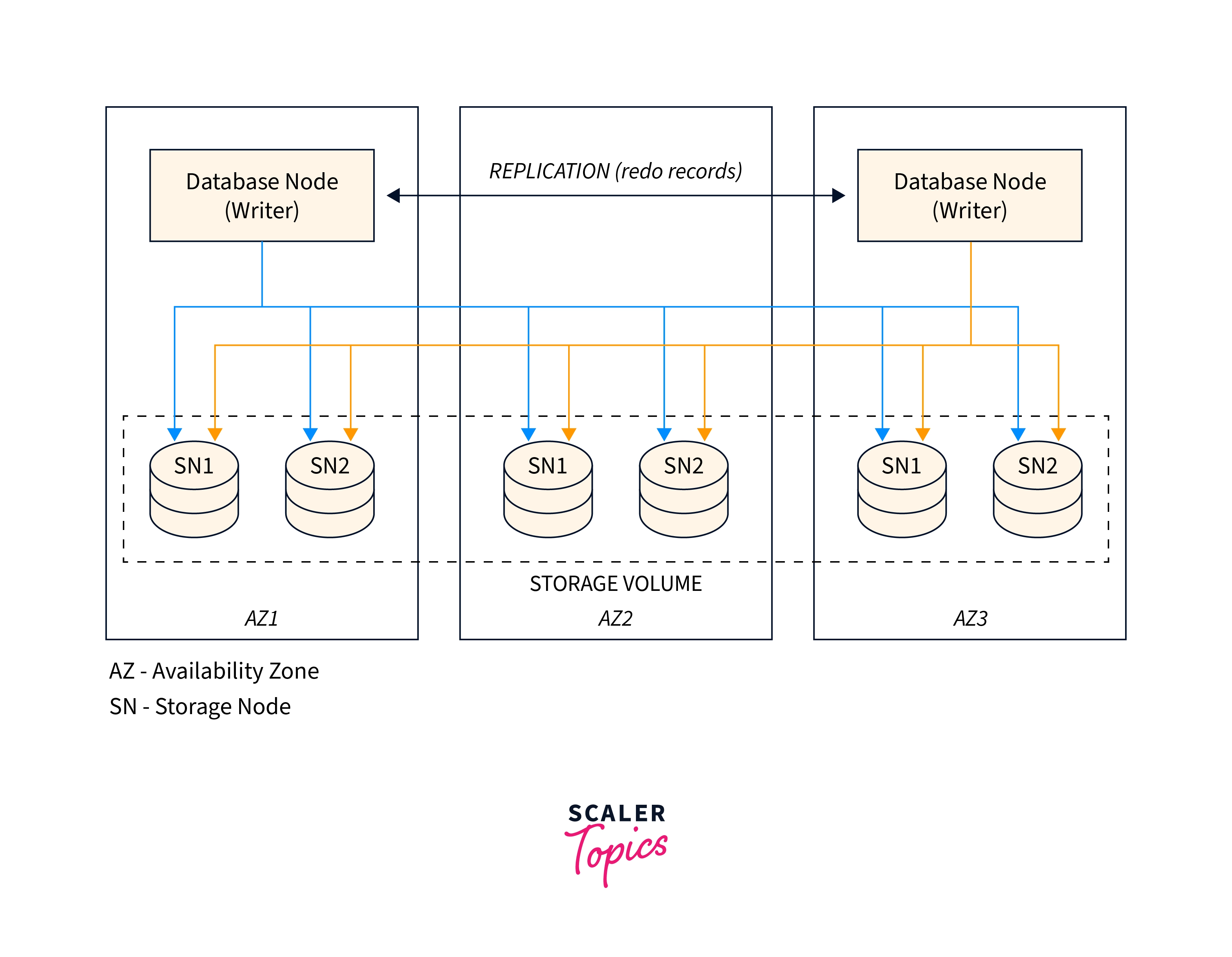
Which DB instance handles which write requests depends on your application. To execute data manipulation language(DML) and data definition language(DDL) statements in a multi-master cluster, you must establish a connection to each instance endpoint. This Aurora cluster is distinct from other types of Aurora clusters, in which all write activities are typically directed to one cluster endpoint and all read activities to one reader endpoint.
Storage for single-master clusters and Aurora multi-master clusters share a similar architecture. Your data is still kept in an extremely dependable, automatically expanding shared storage volume. The quantity and kind of DB instances make up the bulk of the differences. N read/write nodes are present in multi-master clusters. Currently, N can go up to a maximum of 4.
There are no specific read-only nodes in multi-master clusters. As a result, multi-master clusters are not covered by the Aurora policies and recommendations regarding Aurora Replicas.
The Aurora replication protocol uses low-latency and low-lag connections between multi-master cluster nodes. Multi-master clusters use peer-to-peer replication that is all-to-all. Replication operates between writers directly. Every writer copies their edits to every other writer.
A write conflict happens when two DB instances try to edit the same data page almost simultaneously. A quorum voting process is used to approve the earliest change request. The modification is permanently stored. The entire transaction containing the proposed change is rolled back by the DB instance whose change was rejected. The data is kept consistent, and apps always receive a predictable version of the data thanks to moving around the transaction. The entire transaction can be retried if your program recognizes the impasse situation.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Creating an Aurora Multi-Master Cluster
Using the Console, Build an Aurora Multi-Master Cluster
- Select Amazon Aurora as the engine type.
- Select Amazon Aurora MySQL-Compatible Edition as the edition.
- Select Multi-master after expanding Replication features. Only Aurora (MySQL 5.6) multimaster 10a is supported for multi-master clusters of the versions that are currently available.

- Complete the cluster's other settings. This step of the process is the same as how an Aurora cluster is often created in Creating a DB cluster.
- Make the database option. One writer instance is used to create the multi-master cluster.
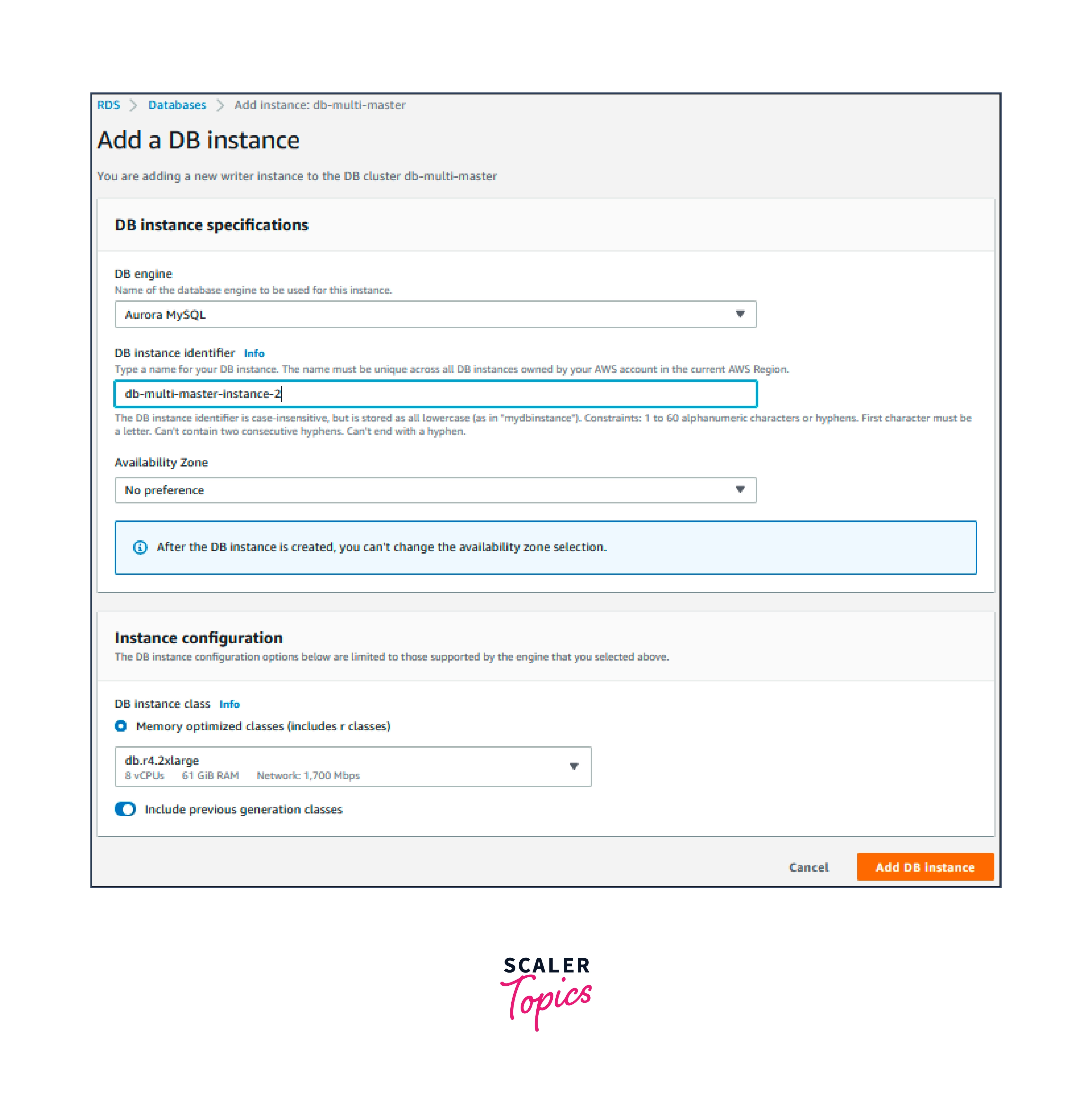
- You can add a second writer instance to the multi-master cluster by doing the following steps:
- Select the multi-master cluster from the Databases page.
- Select Add DB instance under Actions.
- Type the identification for the DB instance.
- After making any necessary selections, select Add DB instance.
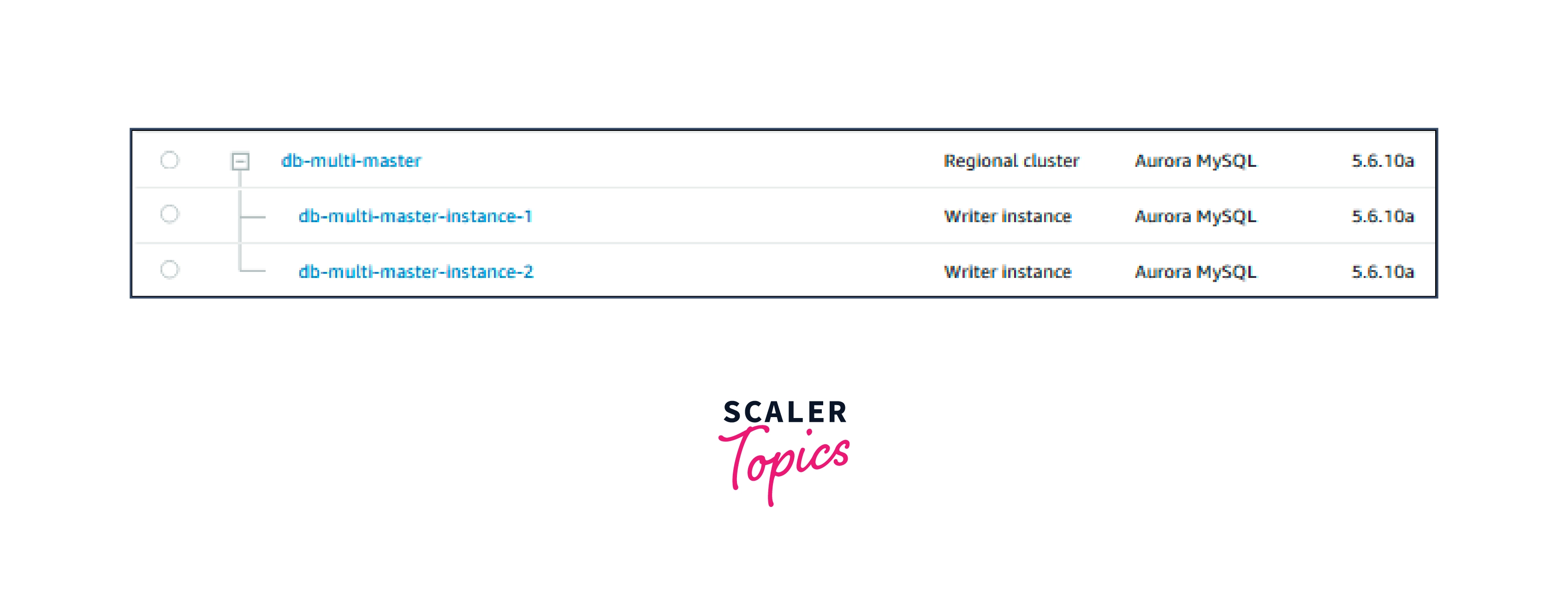
- Following the creation of the Aurora multi-master cluster and related DB instances, the cluster appears as follows on the Databases page. The role Writer instance is displayed by all DB instances.
Managing Aurora Multi-Master Clusters
The majority of management and administrative tasks for Aurora multi-master clusters are carried out in the same manner as for other Aurora cluster types. The distinctions and distinctive characteristics of multi-master clusters for management and administration are described in the sections that follow.
Monitoring an Aurora Multi-Master Cluster
For multi-master clusters, the majority of the monitoring and diagnostic functions enabled by MySQL and Aurora single-master clusters are also supported:
- MySQL general logs, sluggish query logs, and error logs.
- InnoDB runtime status tables, status variables, SHOW commands, and other built-in MySQL diagnostic tools are examples.
- Performance Schema for MySQL.
- Auditing in advance.
- Metrics from CloudWatch.
- Enhanced surveillance
The following monitoring functionalities are not presently supported by Aurora multi-master clusters:
- Insights into performance.
Data Ingestion Performance for Multi-Master Clusters
One best practice for DML activities on a multi-master cluster is to maintain transactions short and straightforwardly. Additionally, send write requests for a given table or database to a single DB instance. It might be necessary to relax the guideline for transaction size while doing a bulk import. To lessen the likelihood of write conflicts, you can still distribute the write operations.
The methods listed below can be used to add data to an Aurora multi-master cluster:
- As long as the statements don't employ any Aurora-unsupported features, users can integrate logical (SQL-format) dumps from those other MySQL-compatible servers while using Aurora multi-master clusters. For instance, logical dumps from tables using MySQL Full-Text Search (FTS) indexes do not function since multi-master clusters do not support the FTS capability.
- Data can be moved into an Aurora multi-master cluster using managed services like Database Migration Service(DMS).
- Follow the current guidelines for heterogeneous Aurora migrations if you're migrating from a server that isn't compatible with MySQL into an Aurora multi-master cluster.
- Logical dumps can be produced by multi-master clusters in MySQL-compatible SQL format. Data dumps from Aurora multi-master clusters can be consumed by any migration tool that can comprehend such a format (for instance, AWS DMS).
Exporting Data from a Multi-Master Cluster
A multi-master cluster's snapshot can be saved and then restored to another multi-master cluster. A multi-master cluster snapshot cannot currently be restored into a single-master cluster.
Use a logical dump and restoration with a tool like mysqldump to move data from a multi-master cluster to a single-master cluster.
A multi-master cluster cannot serve as either the source or the destination for binary log replication.
High Availability Considerations for Aurora Multi-Master Clusters
Any DB instance in an Aurora multi-master cluster can restart without triggering the restart of any other instances. Compared to Aurora single-master clusters, this behaviour offers a higher level of availability for read/write and read-only connections. This level of availability is referred to as continuous availability. A writer DB instance failing does not affect write availability. Because all cluster instances in multi-master clusters can be written to, they do not employ the failover technique. In a multi-master cluster, your application can reroute workload to the remaining healthy instances if a database instance breaks.






Replication Between Multi-Master Clusters and Other Clusters
Outgoing or inbound binary log replication is not supported by multi-master clusters.
Upgrading a Multi-Master Cluster
The database engine is normally upgraded from the current version to the following higher version when you update an Aurora multi-master cluster. The upgrading process takes several steps if you upgrade to an Aurora version that increases the version number by more than one. A database instance gets updated to the next higher version until it reaches the necessary upgrade level, then to the next higher version, and so on.
The approach varies depending on whether there are significant backward-incompatible changes between the old and new versions. For example, modifications to the system architecture are viewed as changes that are not backward compatible. If a given version contains any changes that make it incompatible with earlier editions, see the release notes.
Application Considerations for Aurora Multi-Master Clusters
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
SQL Considerations for Multi-Master Clusters
The main restrictions on the SQL language feature that you can utilize with a multi-master cluster are as follows:
- In a multi-master cluster, you can't use certain settings or column types that change the row layout. You can't enable the innodb_large_prefix configuration option. You can't use the column types MEDIUMTEXT, MEDIUMBLOB, LONGTEXT, or LONGBLOB.
- You can't use the CASCADE clause with any foreign key columns in a multi-master cluster.
- Multi-master clusters can't contain any tables with full-text search (FTS) indexes. Such tables can't be created on or imported into multi-master clusters.
- You can't use the SERIALIZABLE transaction isolation level on multi-master clusters. On Aurora single-master clusters, you can use this isolation level on the primary instance.
- Autoincrement columns are handled using the auto_increment_increment and auto_increment_offset parameters. Parameter values are predetermined and not configurable. The parameter auto_increment_increment is set to 16, which is the maximum number of instances in any Aurora cluster.
Approach application adaptation for an Aurora multi-master cluster in the same way you would a migration. You may need to stop using some SQL features and alter your application logic to accommodate different SQL features:
- Change any columns defined in your CREATE TABLE statements as MEDIUMTEXT, MEDIUMBLOB, LONGTEXT, or LONGBLOB to shorter kinds that don't necessitate off-page storage.
- Delete the CASCADE clause from every foreign key definition in your CREATE TABLE statements. If necessary, add application logic to replicate the CASCADE effects using INSERT or DELETE statements.
- Examine your use of autoincrement columns. The sequences of values for autoincrement columns are different for multi-master clusters than other kinds of Aurora clusters. Check for the AUTO_INCREMENT keyword in DDL statements, the function name last_insert_id() in SELECT statements, and the name innodb_autoinc_lock_mode in your custom configuration settings.
Connection Management for Multi-Master Clusters
The quantity and kind of DNS endpoints that are readily available should be taken into account while designing multi-master cluster connectivity. Instance endpoints are frequently used with multi-master clusters, although they are rarely used with different kinds of Aurora clusters.
Endpoints in Aurora multi-master clusters include the following:
- Cluster Endpoint: This kind of endpoint always directs users to a read-write-capable database instance. There is only one cluster endpoint per multi-master cluster.
- DB Instance Endpoint: These endpoints connect to specific instances of named DBs. Your application frequently uses the DB instance endpoints for all or almost all connections to Aurora multi-master clusters. You may choose which database instance to use for each SQL query thanks to the mapping between your shards and the cluster's DB instances.
- Custom Endpoint: There is an alternative endpoint type. You can build many custom endpoints to construct DB instances. Each time you connect to the endpoint, Aurora delivers a different DB instance's IP address.
Consistency Model for Multi-Master Clusters
Aurora multi-master clusters support a global read-after-write (GRAW) mode that is configurable at the session level. This setting introduces extra synchronization to create a consistent read view for each query. That way, queries always see the very latest data. By default, the replication lag in a multi-master cluster means that a DB instance might see old data for a few milliseconds after the data was updated. Enable this feature if your application depends on queries seeing the latest data changes made by any other DB instance, even if the query has to wait as a result.
Multi-Master Clusters and Transactions
Standard Aurora MySQL guidance applies to Aurora multi-master clusters. The Aurora MySQL database engine is optimized for short-lived SQL statements. These are the types of statements typically associated with online transaction processing (OLTP) applications.
Make sure to keep your written transactions as brief as you can. Doing so reduces the window of opportunity for write conflicts. The conflict resolution mechanism is optimistic, meaning that it performs best when write conflicts are rare. The tradeoff is that when conflicts occur, they incur substantial overhead.
Write Conflicts and Deadlocks in Multi-Master Clusters
One important performance aspect for multi-master clusters is the frequency of write conflicts. When such a problem condition occurs in the Aurora storage subsystem, your application receives a deadlock error and performs the usual error handling for deadlock conditions. Aurora uses a lock-free optimistic algorithm that performs best when such conflicts are rare.
All DB instances in a multi-master cluster can write to the shared storage volume. Each data page you modify in Aurora is automatically distributed across multiple Availability Zones in multiple copies (AZs). When many DB instances attempt to edit the same data page in a relatively short period, a write conflict may result. Before completing the write operation, the Aurora storage subsystem resolves conflicts after noticing that the changes overlap.
Turn Learning into Career Growth
Performance Considerations for Aurora Multi-Master Clusters
For both single-master and multi-master clusters, the Aurora engine is optimized for OLTP workloads. OLTP applications consist mostly of short-lived transactions with highly selective, random-access queries. You get the most advantage from Aurora with workloads that run many such operations concurrently.
Avoid operating constantly at full capacity. Aurora can keep up with internal maintenance tasks by doing this.
Query Performance for Multi-Master Clusters
Multi-master clusters don't provide dedicated read-only nodes or read-only DNS endpoints, but it's possible to create groups of read-only DB instances and use them for the intended purpose.
The following strategies can be used to enhance query performance for a multi-master cluster:
- Execute SELECT commands on the database instance in charge of the shard holding the relevant table, database, or another schema object. The reuse of data in the buffer pool is maximized by this method. Additionally, it prevents the same data from being cached on several DB instances.
- If you want to separate the read and write workloads, set up one or more DB instances as read-only, as detailed in Using instance read-only mode. You can direct read-only sessions to those DB instances by connecting to the corresponding instance endpoints, or by defining a custom endpoint that is associated with all the read-only instances.
- Spread read-only queries across all DB instances. This strategy is the least effective. This approach is the least efficient. Use one of the other approaches where practical, especially as you move from the development and test phase toward production.
Conflict Resolution for Multi-Master Clusters
Many best practices for multi-master clusters focus on reducing the chance of write conflicts. There is network overhead involved in resolving write conflicts. Additionally, your applications must be able to handle errors and retry transactions. Whenever you can, strive to reduce these negative effects:
- Use the same database instance for all modifications to a specific table and any related indexes, whenever possible. A data page can never cause a write conflict if only one DB instance ever makes changes to it. This type of access pattern is frequently used in multitenant or sharded database deployments.
- A reader endpoint does not exist in a multi-master cluster. You no longer need to know which DB instance is managing a certain connection because the reader endpoint load-balances incoming connections. Knowing which database instance is utilized for each connection in a multi-master cluster is necessary for managing connections.
- One 16-KB page's worth of data can cause a write conflict, which can result in a significant amount of work to roll back the entire transaction. Therefore, it is desirable to keep the transactions for a multi-master cluster short and simple.
Conflict detection is done at the page level. Because suggested modifications from several DB instances impact various rows inside the page, a dispute may arise. Conflict detection is applied to all page updates made in the system. This rule is true whether the source is a server background process or a user transaction. Additionally, it holds regardless of whether the data page comes from a table, secondary index, undo space, etc.
Optimizing Buffer Pool and Dictionary Cache Usage
In a multi-master cluster, each database instance keeps its own in-memory buffer pools, table handler caches, and table dictionary caches. The contents and volume of turnover for each DB instance's buffers and caches are determined by the SQL statements the instance processes.
Using memory effectively can improve multi-master cluster performance and lower I/O costs. To physically segregate the data, use a sharded design, and write to each shard from a specific DB instance. By doing this, each DB instance's buffer cache is utilized as effectively as possible. Whenever possible, try to allocate SELECT queries for a table to the same database instance that handles write operations for that table.
Approaches to Aurora Multi-Master Clusters
You can find strategies to use for certain deployments that are appropriate for multi-master clusters in the sections that follow. In these methods, the burden is divided in such a way that the DB instances only write operations for non-overlapping data segments. By doing this, the likelihood of write conflicts is reduced. Performance tuning and troubleshooting for a multi-master cluster are mostly focused on write conflicts.
Using a Multi-Master Cluster for a Sharded Database
Sharding is a well-liked schema design approach that benefits from Aurora multi-master clusters. Each database instance in a sharded architecture is tasked with updating a particular subset of the schema objects. In this manner, concurrent updates to the same shared storage volume won't cause conflicts between various DB instances. Multiple shards write operations can be handled by each database instance.
Applications with sharded schemas make excellent partners for Aurora multi-master clusters. In a sharded system, the physical partitioning of the data reduces the likelihood of write conflicts. Each shard is mapped to a schema object, such as a database, table, or division. All write operations for a specific shard are sent through your application to the proper DB instance.
Bring-your-own-shard (BYOS) refers to a use case where a partitioned/sharded database and an app that can access it already exist. Already physically separated are the shards. As a result, moving the workload to Aurora multi-master clusters is simple and doesn't require changing your schema architecture.
Shards or tenants are mapped one-to-one or many-to-one to database instances. One or more shards are managed by each DB instance. Sharded designs are most commonly used for write operations. With equal performance, SELECT queries can be run on any shard from any DB instance.
Using a Multi-Master Cluster Without Sharding
You can still distribute write operations like DML statements among the DB instances in a multi-master cluster even if your schema design does not physically separate the data into discrete containers like databases, tables, or partitions.
When write conflicts are considered deadlock situations, you could experience some performance overhead and your application might need to handle sporadic transaction rollbacks. In write operations for tiny tables, write conflicts are more common. Rows from various portions of the main key range may be on the same data page if a table has a small number of data pages.
In this situation, you should also reduce the number of secondary indexes. Aurora updates the related secondary indexes in response to changes you make to indexed columns in a table. Because the sequence and grouping of rows differ between a secondary index and the corresponding table, changing an index could result in a write conflict.
Using a Multi-Master Cluster as an Active-Standby
A database instance that is kept in sync with another and immediately prepared to take over is an active standby. When a single DB instance can manage the entire workload, this setup aids in high availability.
Using a single DB instance as the destination for all traffic, including read/write and read-only, allows you to use multi-master clusters in an active-standby arrangement. Your application must recognize the issue and redirect all connections to a different DB instance if that DB instance becomes unreachable. Since the other DB instance is already open for read/write connections in this situation, Aurora doesn't attempt any failover.
Conclusion
- In this article we learned about Aurora Mulit-Master Clusters. All DB instances in a multi-master cluster are capable of writing data. There is no use for the concepts of a single read/write primary instance and numerous read-only Aurora Replicas.
- The already high availability of Aurora is enhanced by multi-master clusters. Sharded or multitenant applications work well with multi-master clusters.
- Only the Amazon Aurora MySQL-Compatible Edition v1 is capable of hosting Aurora multi-master clusters. Regarding this significant Aurora MySQL version, Amazon has made an end-of-life announcement.
- The way that multi-master clusters operate differs significantly from the way that provisioned, Aurora Serverless and parallel query clusters operate. You take into account several aspects in areas like high availability, monitoring, connections management, and database functionality while using multi-master clusters.
- The Aurora replication protocol uses low-latency and low-lag connections between multi-master cluster nodes. Multi-master clusters use peer-to-peer replication that is all-to-all. Replication operates between writers directly. Every writer copies their edits to every other writer.