Amazon Aurora Serverless
Overview
Amazon Aurora is a cloud-native relational database service provided by AWS. It combines the efficiency and accessibility of top-tier commercial databases with the affordability and simplicity of open-source databases. A database service called "Amazon Relational Database Service(RDS)" was used to create it.
What is Amazon Aurora?
As discussed above, Amazon Aurora is a cloud-native relational database service provided by AWS.Amazon Relational database engine Aurora is fully manageable and compatible with PostgreSQL and MySQL. We know that PostgreSQL and MySQL, two open-source relational databases, rely on SQL (Structured Query Language), the standard language for dealing with management systems. These combine the performance and durability of top-tier commercial databases with the simplicity of use and low cost of open-source databases.
The same software, hardware, and databases already used with your PostgreSQL and MySQL databases may all be used with Aurora. For specified workloads, Aurora is claimed to be up to three times quicker than PostgreSQL and five times faster than MySQL without requiring modifications to the bulk of your present applications.
Amazon Aurora Serverless
An on-demand, autoscaling setup/feature for Amazon Aurora is Amazon Aurora Serverless. Depending on the demands of your application, it automatically starts up, shuts down, and scales capacity up or down. You don't need to manage database capacity if you use AWS to run your database.
Managing database capacity manually can be time-consuming and result in the inefficient use of database resources. You establish a database with Aurora Serverless, set the required database capacity range, and link your apps. In the Amazon Relational Database Service (Amazon RDS) panel, you can easily switch between traditional and serverless configurations. You pay on a per-second basis for the database capacity that you use when the database is active.
Amazon Aurora Serverless v1
The on-demand autoscaling setup for Amazon Aurora is known as Amazon Aurora Serverless v1 (Amazon Aurora Serverless version 1). The computational capacity of an Aurora Serverless v1 DB cluster can be scaled up or down in response to the demands of your application. In contrast, you manually manage capacity for Aurora provisioned DB clusters. For irregular, intermittent, or unpredictable workloads, Aurora Serverless v1 offers an option that is reasonably easy to use and reasonably affordable. Because it automatically starts up, increases computing capacity to match the demands of your application, and shuts down when not in use, it is cost-effective.
When it first became publically accessible in 2018, it offered some pretty intriguing new features for a relational database, including
- Data API - It offers an HTTPS endpoint to insert, update, delete, or query data directly from your web applications.
- Autoscaling - It scales up or down automatically. You don’t have to provision in advance and you do not have to rely on guesswork for those unknown spikes or downtimes.
- Sleep - It can be configured to go to sleep after a certain period of inactivity, meaning you only pay for what you use (serverless at its best!). However, this also means that your application will have to deal with some kind of cold start situation. At worst, it can take more than 30 seconds to warm up and this could lead to request timing-out errors.
Benefits of Using Amazon Aurora Serverless v1
- Simple to use-Removes the complexity of provisioning and managing database capacity. The database will automatically start up, shut down, and scale to match your application’s needs.
- Scalable-Seamlessly scale compute and memory capacity as needed, with no disruption to client connections.
- Cost-effective-Pay only for the database resources you consume, on a per-second basis. You don't pay for the database instance unless it's running.
- Highly available-Built on distributed, fault-tolerant, self-healing Aurora storage with 6-way replication to protect against data loss.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Use Cases of Amazon Aurora Serverless v1
Infrequently-used applications
You have an application that is only used for a few minutes several times per day or week, such as a low-volume blog site, and you want a cost-effective database that only requires you to pay when it's active. With Aurora Serverless v1, you only pay for the database resources you consume.
Development and test databases
Your software development and QA teams are using databases during work hours, but don’t need them on nights or weekends. With Aurora Serverless v1, your database automatically shuts down when not in use, and starts up much more quickly when work starts the next day.
Amazon Aurora Serverless v2
Aurora Serverless v2 is an on-demand, autoscaling configuration for Amazon Aurora. Aurora Serverless v2 helps to automate the processes of monitoring the workload and adjusting the capacity for your databases. Capacity is adjusted automatically based on application demand. You only pay for the capacity that your application uses, which can save you up to 90% of the cost of your database.
All database workloads are supported by Aurora Serverless v2. Examples range from the most demanding, mission-critical business systems that demand high scalability and high availability to development and test environments, websites, and applications with irregular, intermittent, or unpredictable workloads. It supports all of Aurora's features, including read replicas, Multi-AZ deployments, and global databases. The Amazon Aurora MySQL-Compatible Edition and PostgreSQL-Compatible Edition both support Aurora Serverless v2.
Benefits of using Amazon Aurora Serverless v2
- Highly scalable-Scale instantly to hundreds of thousands of transactions in a fraction of a second.
- Highly available-Power your business-critical workloads with the full breadth of Aurora features, including cloning, global database, Multi-AZ, and read replicas.
- Cost effective-Scale out fine-grained increments to provide just the right number of database resources and pay only for capacity consumed.
- Simple-Removes the complexity of provisioning and managing database capacity. The database will scale to match your application’s needs.
- Transparent-Scale database capacity instantly, without disrupting incoming application requests.
- Durable-Protects against data loss using the distributed, fault-tolerant, self-healing Aurora storage with six-way replication.
Use Cases of Amazon Aurora Serverless v2
Variable Workloads
You're running an infrequently-used application, with peaks of 30 minutes to several hours a few times each day or several times per year, such as a human resources, budgeting, or operational reporting application. You no longer have to provision to peak capacity, which would require you to pay for resources you don't continuously use, or to average capacity, which would risk performance problems and a poor user experience.
Unpredictable Workloads
You're running workloads with database usage throughout the day, and also peaks of activity that are hard to predict. For example, a traffic site might see a surge of activity when it starts raining. Your database will automatically scale capacity to meet the needs of the application's peak load and scale back down when the surge of activity is over.
Enterprise Database Fleet Management
Enterprises with hundreds or thousands of applications, each backed by one or more databases, must manage resources for their entire database fleet. As application requirements fluctuate, continuously monitoring and adjusting the capacity for every database to ensure high performance, high availability, and remaining under budget is a daunting task. With Aurora Serverless v2, database capacity is automatically adjusted based on application demand. You no longer need to manually manage thousands of databases in your database fleet. Features such as global database and Multi-AZ deployments ensure high availability and fast recovery.
Software as a Service Applications
Software as a service (SaaS) vendors typically operate hundreds or thousands of Aurora databases, each supporting a different customer, in a single cluster to improve utilization and cost efficiency. But they still need to manage each database individually, including monitoring for and responding to colocate databases in the same cluster that may take up more shared resources than originally planned. With Aurora Serverless v2, SaaS vendors can provision Aurora database clusters for each customer without worrying about the costs of provisioned capacity. It automatically shuts down databases when they are not in use to save costs and instantly adjusts databases' capacity to meet changing application requirements.
Scaled-out Databases Split Across Multiple Servers
Customers with high write or read requirements often split databases across several instances to achieve higher throughput. However, customers often provision too many or too few instances, increasing cost or limiting scale. With Aurora Serverless v2, customers split databases across several Aurora instances and let the service adjust capacity instantly and automatically based on need. It seamlessly adjusts capacity for each node with no downtime or disruption and uses only the amount of capacity needed to support applications.
Amazon Aurora Features
-
It supports customized database endpoints and serverless configuration. In an on-demand, auto-scaling setup for Aurora called Amazon Aurora Serverless, the database automatically starts up, shuts down, and further adjusts capacity up or down depending on the demands of their application. The user's database may operate on the cloud without managing any database instances.
-
Amazon Aurora offers automated storage scalability and push-button computation scaling. Using the Amazon Relational Database Service (Amazon RDS) APIs or a few mouse clicks in the AWS Management Console, users may modify the compute and memory resources powering their deployment.
-
It offers instance repair and monitoring. RDS and the supporting Amazon Elastic Compute Cloud (EC2) instance continuously monitor the Amazon Aurora database's status. Amazon RDS restarts the database and any related processes when a database fails.
-
It offers Network Isolation and Database Snapshots. Amazon Aurora offers database snapshots. User-initiated backups of user instances called "DB Snapshots" are retained in Amazon S3 until the user explicitly deletes them.
Amazon Aurora Architecture
- Along with an Aurora main database, an Aurora replica database, and an Aurora database cluster, the data for these database instances is stored on a cluster volume. Unquestionably a virtual rather than a physical database storage volume, the Aurora cluster volume spans many Availability Zones to better support worldwide applications. For each zone, database cluster details are replicated.
- The primary database's cluster volume is used for all read and write operations. Each cluster in Aurora will have a single primary database instance.
- It is fair and a copy of the primary database instance, with just read operations—that is, merely giving information—as its sole job. For a primary database instance to provide good accessibility and availability across all zones, up to 15 replicas may be used. When the primary database is unavailable, Aurora will move to a replica in a fail-safe situation.
- It may be set up by the user to store a copy of its database on Amazon S3. Even in the worst scenarios, where the entire cluster is down, this guarantees the security of the user's database.
- Users may utilize Aurora Serverless to automatically start scaling and shutting down the database to fit application demand in the case of an unanticipated workload.
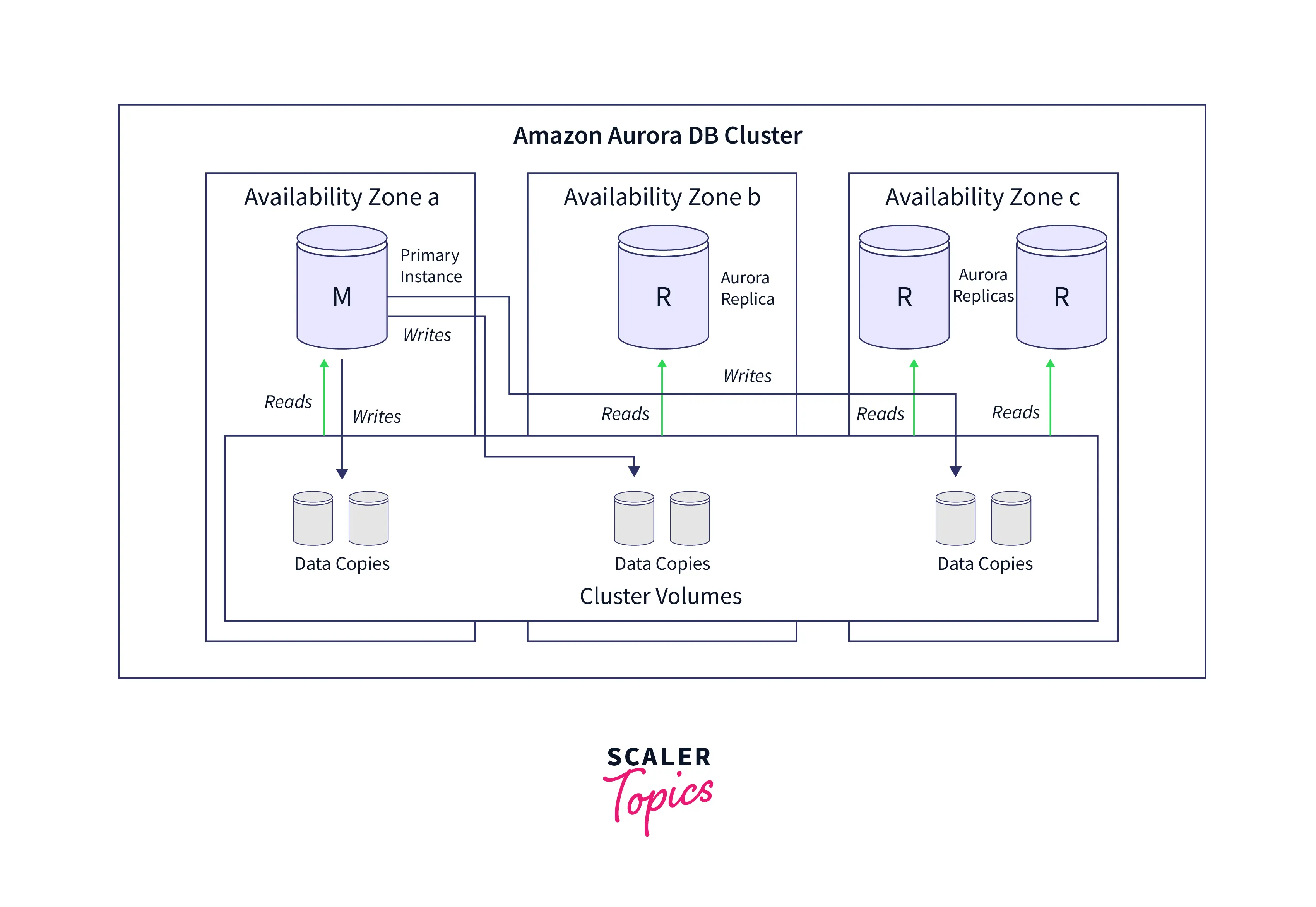
Amazon Aurora DB Cluster
The Amazon Aurora DB cluster is a virtual database storage volume that spans many availability zones. Two or more database instances and a cluster volume that essentially controls the data for those database instances make up each Amazon Aurora Database Cluster. The two kinds of database instances that make up an Amazon Aurora Cluster are as follows:
Primary DB instance: This kind of DB instance handles all data alterations to the cluster volume and allows read and write operations. There is only one primary DB instance per Aurora DB cluster.
The Aurora Replica only allows read operations, unlike the primary DB instance. It shares a storage volume with the primary database instance. High availability may be kept by placing Aurora Replicas in various availability zones.
Amazon Aurora Replica
- An Aurora DB cluster comprises distinct nodes called replicas to expand read operations and increase availability.
- The Availability Zones can each get up to 15 Aurora Replicas.
- Multiple copies of the data make up a DB cluster volume. However, to Aurora Replicas in the DB cluster, the data in a DB cluster volume is viewed as a single copy. Each Aurora Replica sends the identical query response.
- As a failover target, an Aurora Replica becomes the primary instance if an Aurora instance fails, increasing availability.
- You must recreate the DB instance to recover from the failure event if the Aurora DB cluster does not include Aurora Replicas. Compared to starting a new database instance, Aurora Replica is quicker.






MySQL Read Replica
- Over the Availability Zones, it can build up to 5 Read Replicas.
- It improves DB instance availability and uses this capability to scale up a single DB instance's capacity for read-intensive database workloads.
- You may establish many replicas of a source database instance and use several copies of your data to fulfill many application read demands, enhancing read performance.
Amazon RDS and Relational Databases
Amazon Relational Database Service (RDS), a managed SQL database service, is offered by Amazon Web Services (AWS). Amazon RDS provides several database engines for storing and organizing data. Additionally, it simplifies duties related to relational database administration, such as data transfer, backup, recovery, and patching.
Amazon RDS expands the accessibility of relational database creation and maintenance in the cloud. A cloud administrator uses Amazon RDS to set up, run, manage, and scale a relational instance of a cloud database. Although it is not a database in and of itself, Amazon RDS is a service used to manage relational databases.

When to Use Aurora Serverless vs Amazon RDS?
What are Key Similarities and Differences?
- The primary distinction between Aurora Serverless and Amazon RDS is that the more conventional RDS allows developers a choice of database instance type and size. Additionally, you have a choice of database engines, including Microsoft SQL Server, Oracle, PostgreSQL, MySQL, MariaDB, and Amazon Aurora. The native database engine from Amazon, called Aurora, was created specifically to function with the AWS cloud.
- Developers can choose the minimum and maximum Aurora Capacity Units (ACUs), which are made up of virtual CPUs and memory while using Aurora Serverless, which was launched in 2018. The computational capacity of Aurora Serverless can also be scaled up or down automatically.
- These features allow Aurora Serverless to handle resource capacity more adaptable. In Amazon RDS, a deployed database server is not scaled to a larger instance type until its configuration is manually altered to a new size, which may cause up to five minutes of downtime. RDS does provide auto-scaling for read replicas, but the procedure takes a while to complete because more RDS instances need to be deployed. The automatic scaling of Aurora Serverless leads to considerably quicker deployment times, which are often under 30 seconds.
- Developers don't need to specify storage when using the Aurora database engine in RDS or Aurora Serverless since Aurora automatically assigns the necessary storage space. From a functional standpoint, each version of Aurora is transparent to the source code if an application is compatible with MySQL or PostgreSQL.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Factors to Consider Before Choosing
- First and foremost, only MySQL and PostgreSQL are compatible with Aurora Serverless. You must utilize Amazon RDS if your application needs Oracle, SQL Server, or MariaDB.
- Applications that are not anticipated to serve traffic frequently, such as development or test environments, are a good fit for Aurora Serverless. Although Aurora Serverless gives users the ability to reduce capacity to zero when there is no activity, this configuration is not advised for use in production settings. Reprovisioning computing capacity takes a short while, and during that time, production users will experience poor performance.
- Applications that see sharp and erratic spikes in use may also benefit from Aurora Serverless rather than using Amazon RDS to make time-consuming capacity adjustments. The database can be set up with Aurora Serverless to rapidly and automatically increase or decrease capacity as necessary.
- Amazon RDS may appear like a worse choice than Aurora Serverless. It could, however, result in greater AWS charges if not selected for the appropriate use case.
- As of publication, an r5.large RDS instance (16 GB, 0.29/hour ) for an application that is anticipated to provide steady traffic in US-East-1. In this situation, Aurora Serverless would cost 65% more. Reserved Instances are also incompatible with Aurora Serverless. Depending on the instance type and duration of your commitment, deploying Reserved Instances with Amazon RDS might significantly reduce your costs — anywhere from 30% to 60%.
- Aurora is undoubtedly a choice to take into account, but to make the best choice for your business, it's critical to weigh its benefits, drawbacks, and cost implications in comparison to standard RDS.
Benefits Of Amazon Aurora
1)Affordable
It just involves actual monthly payments. No up-front or additional charges are applied. Only the processing power and storage that you utilize are charged for.
2)Highly Scalable
At a cost one-tenth that of commercial databases and with performance and availability comparable to MySQL, Amazon Aurora offers up to five times the version. Depending on your demands, you may scale resources up or down. Up to 64 TB of storage can be added to each database instance.
3)Fully controlled
Getting started with Aurora is a breeze. Without charging extra, Aurora offers monitoring via Amazon Cloudwatch. Amazon is in charge of everything; when necessary, it patches all the software. You do not need to be concerned about various database administration duties, including providing hardware, fixing software, setting things up, configuring, or making backups. The data is continuously backed up to Amazon S3 and offers point-in-time recovery through an Amazon Aurora.
4)Highly Secure
Your database is protected on many levels by an Amazon Aurora. Utilizing Amazon VPC for network isolation, it offers encryption using keys you generate and manage using AWS Key Management Service. Because it enables you to encrypt your database using keys that you develop and manage using AWS Key Management Service, Amazon Aurora provides excellent security (KMS.)Amazon Aurora uses SSL to safeguard data transmission.
Turn Learning into Career Growth
5)Utilization is simple
It’s simple to utilize Amazon Aurora. A single API request, CLI command, or the Amazon RDS Management DB Instance. The settings and parameters for the selected DB Instance class are already pre-configured in Amazon Aurora DB Instances.
6)Maximum Output
Amazon Aurora employs a combination of software and hardware solutions to ensure that the database engine can utilize available computation, memory, and networking fully. For the performance to be increased, the consistency for input or output processes and distributed systems approaches like quorums are used. MySQL and PostgreSQL are both completely compatible with an Amazon Aurora. You may migrate from those databases to Aurora.
Pricing Of Amazon Aurora
- There are no up-front costs with AWS Aurora pricing. Your use of their services determines how much you pay them each month.
- According to AWS, you will be charged in GB-month increments or for the total amount of storage each month. Billing for input/output (I/O) is done in million-request increments. There can be additional fees if you utilize their Global database, Backtrack, Snapshot Export, or move any data from your Aurora database.
- Depending on the type of PostgreSQL or MySQL database you choose, there are a variety of various charges. The editions with Aurora compatible with MySQL and PostgreSQL are the ones for which Amazon lists pricing. Depending on the type of instance, these fees might vary the price changes considerably depending on the location you choose.
- On-Demand pricing is available for Amazon Aurora Serverless, where your database capacity controls itself. This arrangement requires you to pay for capacity, storage, and I/O. You would not be charged when the database is not in use, but capacity fees are assessed in seconds. ACUs, or Aurora Capacity Units, gauge the database's capacity.
Getting started with Amazon Aurora Serverless
Two Ways to Create an Aurora Serverless Database w/ Data API:
Option #1: Amazon RDS Console — Manual
Using the RDS Console, you may deploy your resources quickly and finish in a matter of minutes by following these steps:
Create a new Aurora Serverless Cluster:
- Launch the Amazon RDS Console.
- Select Amazon Aurora engine.
- Select MySQL 5.6-compatible (the only option for serverless) and select Next.
- Select Serverless for the capacity type and provide a cluster name and master credentials and select Next.
- Leave all defaults and choose Create database.
Enable the Data API (for an existing Aurora Serverless Cluster):
Using the RDS Management Console, we will manually enable the Data API for the recently constructed Aurora serverless cluster. Hopefully, this will only last until this puppy exits BETA, at which point we can enable the Data API using a CloudFormation template and the EnableHTTPEndpointAPI parameter. In the interim
- Launch the RDS Management Console
- Select your cluster (even though it says database)
- Select the Modify button on the upper right
- Select “Data API” under the Network & Security section
- Select Continue button
- Select “Apply immediately” under Scheduling of modifications
- Select “Modify cluster” radio button.
Option #2: AWS CLI or SDK — Scripted
You may quickly create your resources using the AWS CLI or AWS SDK. Here is a complete AWS CLI command to start a fresh Aurora Serverless Cluster:
Once the Aurora Serverless Cluster has been created, follow Step 2: Enable Data API from the previous section and you now have an Aurora Serverless database with Data API enabled.
Four Ways to Connect to Your Database Using the Data API
Solution #1: Data Query (via RDS Console)
- Launch Amazon RDS Management Console.
- Select Query Editor.
- In the Connect to Database window, select your cluster, provide your master user, master password, and database name (optional).
- Select Connect to database.
- Once in the Query Editor, select the Clear button and type:
- use MarketPlace; select * from Customers;
- Select Run
Solution #2: AWS CLI
Change the database name, cluster ARN, secrets ARN, SQS select statement, and other information in the attached AWS CLI script.
Solution #3: AWS Lambda function
Using a straightforward AWS Lambda function and the RDSDataService API, you can quickly connect to a database that has the Aurora Serverless Data API enabled and run any SQL statement against it.
This function does not require any MySQL drivers, an Amazon VPC, or to be concerned about connection pooling. Simply provide SQL commands as HTTP requests, and Aurora Serverless will handle the rest!
Here is the whole code for running a SQL statement on a database that has the Aurora Serverless Data API enabled. Once more, be certain to supply the environment variables before passing in something like:
{ "sqlStatement": "SELECT * FROM <YOUR-TABLE-NAME>" }
Solution #4: AWS AppSync
-
You now have direct access to your serverless Data API-enabled database as a datasource when creating a GraphQL API via AWS AppSync, and... Based on the current database table architecture, AppSync will create a GraphQL schema for you!
-
To implement this solution, we'll make use of the brand-new add-graphql-datasourcepluginfor the AWS Amplify CLI, which takes your serverless database table(s) and automatically creates/updates a GraphQL schema, generates the necessary mutations, queries, and subscriptions, and sets your database as a GraphQL DataSource to an existing GraphQL API.
-
Now that your serverless Data API-enabled database is available as a datasource when creating a GraphQL API via AWS AppSync, you may directly access it, and... Based on your current database table design, AppSync will create a GraphQL schema for you!
-
For this solution, we'll use the new add-graphql-datasourcepluginfor the AWS Amplify CLI, which automatically takes your serverless database table(s) and creates/updates a GraphQL schema, generates the necessary mutations, queries, and subscriptions, and sets your database as a GraphQL DataSource to an existing GraphQL API.
- Launch Amazon RDS Management Console
- Select Query Editor
- In the Connect to Database window, select your cluster, and provide your master user, master password, and database name (optional).
- Select Connect to database.
-
In the query editor window, run the following commands:
- Create database ‘MarketPlace’ if you haven’t already. CREATE DATABASE MarketPlace;
- Create a new Customers table.
-
Now that we have a database and a Customers table, we can now use the add-graphql-datasource plugin to generate a GraphQL schema, add the database as a datasource, and add mutations, queries, and subscriptions based on the [Customers] table.
Here’s how the add-graphql-datasource plugin works
- Amplify CLI — Installing the CLI Here's a simple shortcut if you haven't installed the AWS Amplify CLI before. The Amplify CLI will use those credentials if you already have the AWS CLI installed, thus amplify configure is not required.
-
Amplify CLI — Init Now, we’ll initialize our AWS backend project using the following Amplify command. $ amplify init
-
Amplify CLI — Add API $ amplify add api
-
Amplify CLI — Add GraphQL DataSource $ amplify api add-graphql-datasource
-
The RDS Data API has a limit of 1000 rows or 1MB of data for the amount of data that SQL query select calls can return. The independent MySQL Python client PyMySQL, which gives you the flexibility to make connections, conduct queries, and gain a greater quantity of operations on MySQL db, in our case Serverless RDS DB, is an alternative to using RDS Data API.
Strategies to Optimize Costs Using Amazon Aurora Serverless
Making sure Aurora Serverless is being used for the appropriate workload is a crucial first step in cost minimization. More advice for cost optimization is provided below.
Use Multiple Clusters
If you need to keep several databases, distribute them among various clusters. By doing this, each cluster may autonomously scale in response to the demand for its unique database.
Avoid Scale-Blocking Operations on v1
Scale-blocking actions must be avoided when utilizing Aurora Serverless v1. These prevent your instance from scaling up to meet demand and keep it stuck in a capacity-constrained condition. There are a few considerations to make so that scaling up and down for your instance is simple. Avoid temporary tables and table locks because they block scaling. Clean up any temporary tables or locks once you no longer need them.
Use Serverless V1
It is true that Aurora Serverless v2 scales much better than v1. But the price is currently double that of version 1. So, employing Serverless v1 instances can easily decrease your costs in half if your workload doesn't need to scale up or down immediately and you can avoid scale-blocking procedures.
Conclusion
- In this essay, we learned the definition of Amazon Aurora.
- After that, we discussed Amazon Aurora's features and understood its architecture well. It was followed by Amazon Aurora Replicas and the Amazon DB cluster.
- This article also covered critical information about Amazon Aurora Serverless. It briefly explained how it is an on-demand autoscaling setup/feature for Amazon Aurora.
- In this article, we also learned about some strategies to Optimize Costs Using Amazon Auror Serverless. It explained how we could use multiple clusters and avoid Scale-Blocking Operations on v1.
- Additionally, Relational Databases and Amazon RDS were covered. Along with this, we also learned when to Use Aurora Serverless vs. Amazon RDS. One of the critical things we understand is developers don’t need to specify storage when using the Aurora database engine in RDS or Aurora Serverless since Aurora automatically assigns the necessary storage space
- We concluded by talking about the benefits and pricing of Amazon Aurora.