AWS Data Lake
Overview
An AWS Data Lake behaves as a centralized repository to store all your structured and non-structured data. In addition to storing these data, AWS Data Lake also provides facilities to process and secure these data. It can process any kind of data, structured, unstructured, semi-structured, etc., without caring about the size of the data to be processed. AWS Data Lake can store data in source format or transform it before storing.
Introduction to AWS Data Lake
Before understanding the AWS Data Lake, let’s first talk about a natural lake. A natural lake consists of many tributaries(rivers) flowing into it. The lake comprises water from various tributaries in different quantities and qualities (some clean, some muddy).
Similar to the above, we have AWS Data Lake. This data lake behaves as a centralized repository with data from various sources. This data can be structured, unstructured, or semi-structured. Data Lake stores data in any form and any quantity.
AWS Data Lake automatically configures the required AWS services to ease the process of tagging, searching, sharing, and analyzing data. The data can be stored in AWS Data Lake in the same format as the source system, or the data can be transformed before storing.
AWS Data Lake is a solution provided by AWS that offers the facility to build a Data lake on top of AWS ensuring high availability. You can create the complex Data Lake structure on top of AWS using the user-friendly AWS Management console easily. Data Lake is a concept designated to solve greater issues. AWS provides the capability to create Data Lakes on top of the AWS cloud. This solution provided by AWS to set up data lakes is known as AWS Data Lake.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Why AWS Data Lake?
“With the data lake, business value maximization from data is within every organization’s reach.”
The importance of data lake is understood from the above quote by Dr. Kirk Borne, Principal Data Scientist & Data Science Fellow, Booz Allen Hamilton.
Data Lake offers an undefined view of data. The data when stored in AWS Data Lake does not follow any structure or needs to belong to some given sets of data types. They can be in any form and any type. AWS is the leading cloud service provider to offer resources such as Data Lake and AWS also has other services which can be integrated with AWS Data Lake to increase efficiency.
The main reasons for using AWS Data Lake are:
- AWS Data Lake offers business agility as the data is accessible from any device, and any location if you have the authentication details.
- With the tremendous increase in data volumes, quality analysis of data is a significant concern. AWS Data Lake looks into this analysis.
- AWS Data Lake can be integrated with other AWS services of Machine learning and Artificial Intelligence to make profitable predictions.
- The data analysis using AWS Data Lake is more robust as it has no pre-defined structure to fit the data into. The data is not restricted to being present in any given format.
AWS Data Lake Architecture
Let’s first explore the components involved in the AWS Architecture. Although the architecture has no fixed components, we can expect to find some essential components.
Components of AWS Data Lake Architecture
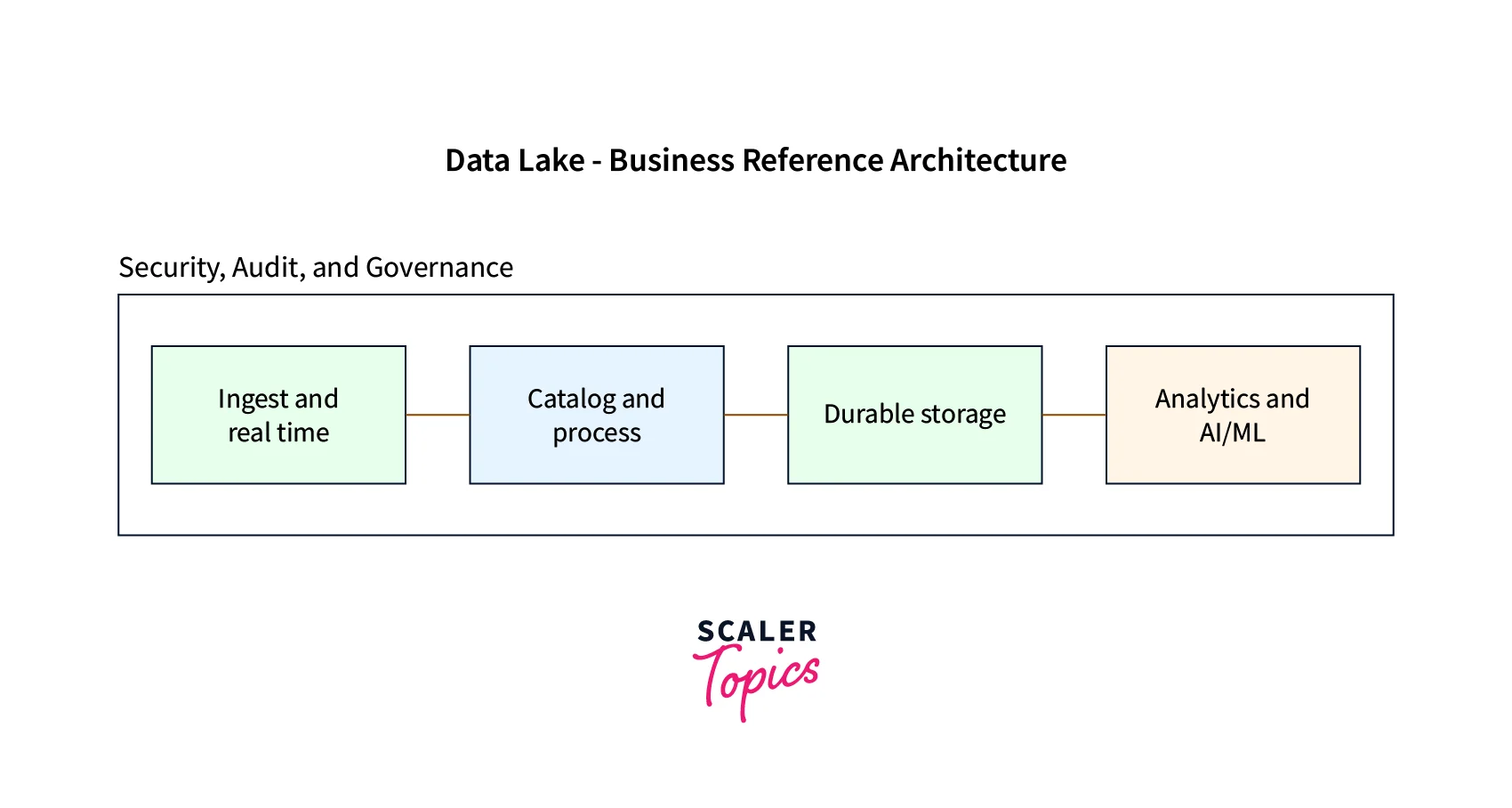
1. Ingestion
Before any other step, first, we need to ingest the data. In other words, the data needs to be added to the AWS Data Lake first.
2. Cataloguing
Once we have our data in the AWS Data Lake, we need to catalogue the data. When we add data to AWS Data Lake, it is usually in scattered form, which is difficult to understand and interpret. Cataloguing the data and generating metadata helps the user discover what exists in our AWS Data Lake.
3. Processing
After understanding the data, we need to process it. AWS Data Lake helps centralize data processing to facilitate automation, security, and easy governance.
4. Storage
Usually, when we have large volumes of data, it’s entirely possible that some data is operational and some of them are put aside. Hence we need to figure out a cost-effective way to store these data.
5. Analytics and AI/ML
Lastly, after executing all the steps like data storing, processing, etc., we want to integrate it with other AWS services (Machine Learning, Artificial Intelligence services)to generate profitable output.
Understanding AWS Data Lake Architecture
AWS Data Lake is not a specific service or platform; it’s an architecture pattern built around a central repository that can store tons of data based on a schema-on-read approach. The AWS Data Lake is simply a combination of tools or AWS services that combines to perform operations on data and produce profitable outputs.
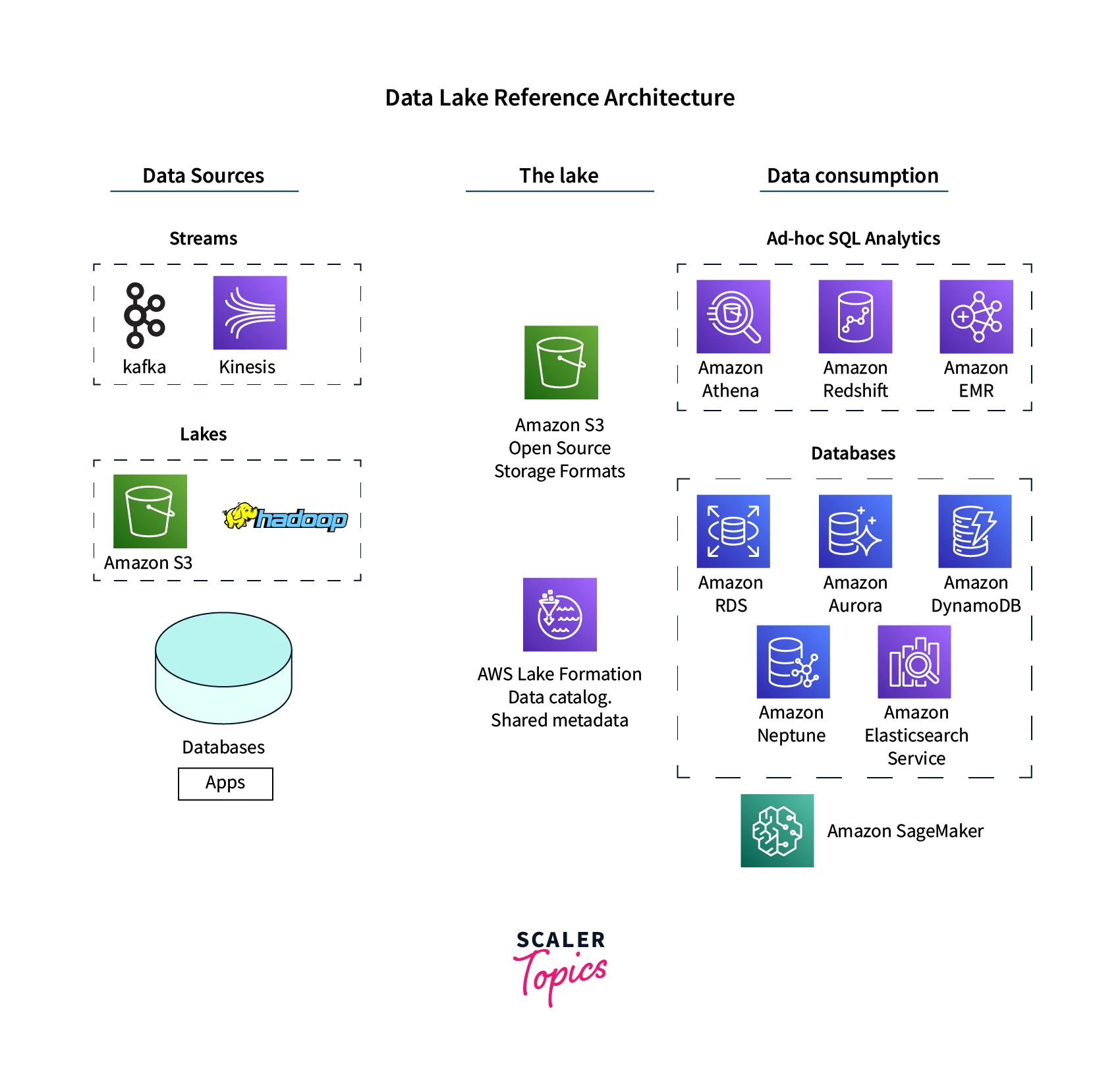
- On the left hand, we can see there are multiple data sources. These data can be in different quantities and quality(structured or unstructured).
- All these data need to be ingested in some centralized repository.
- Large amounts of data can be ingested in AWS Services like Amazon S3. For storing the data in S3, we need not structure the data beforehand.
- Amazon S3 has policies to convert the data into a warm or cold state depending on whether you want to use the data immediately or may not use the data for some time. This helps in saving the cost.
- Then comes AWS Lake formation, which allows you to add security, authentication, and governance to the data.
- Next, we have the data consumption layer. Our data stored in the data lake is common for all users.
- By integrating this data with other AWS services like Amazon Athena, Amazon Redshift, etc., we can conduct analysis or other operations on top of the data. This operation yields profitable outcomes.
Example Architecture
Let's understand the above architecture concerning an example.
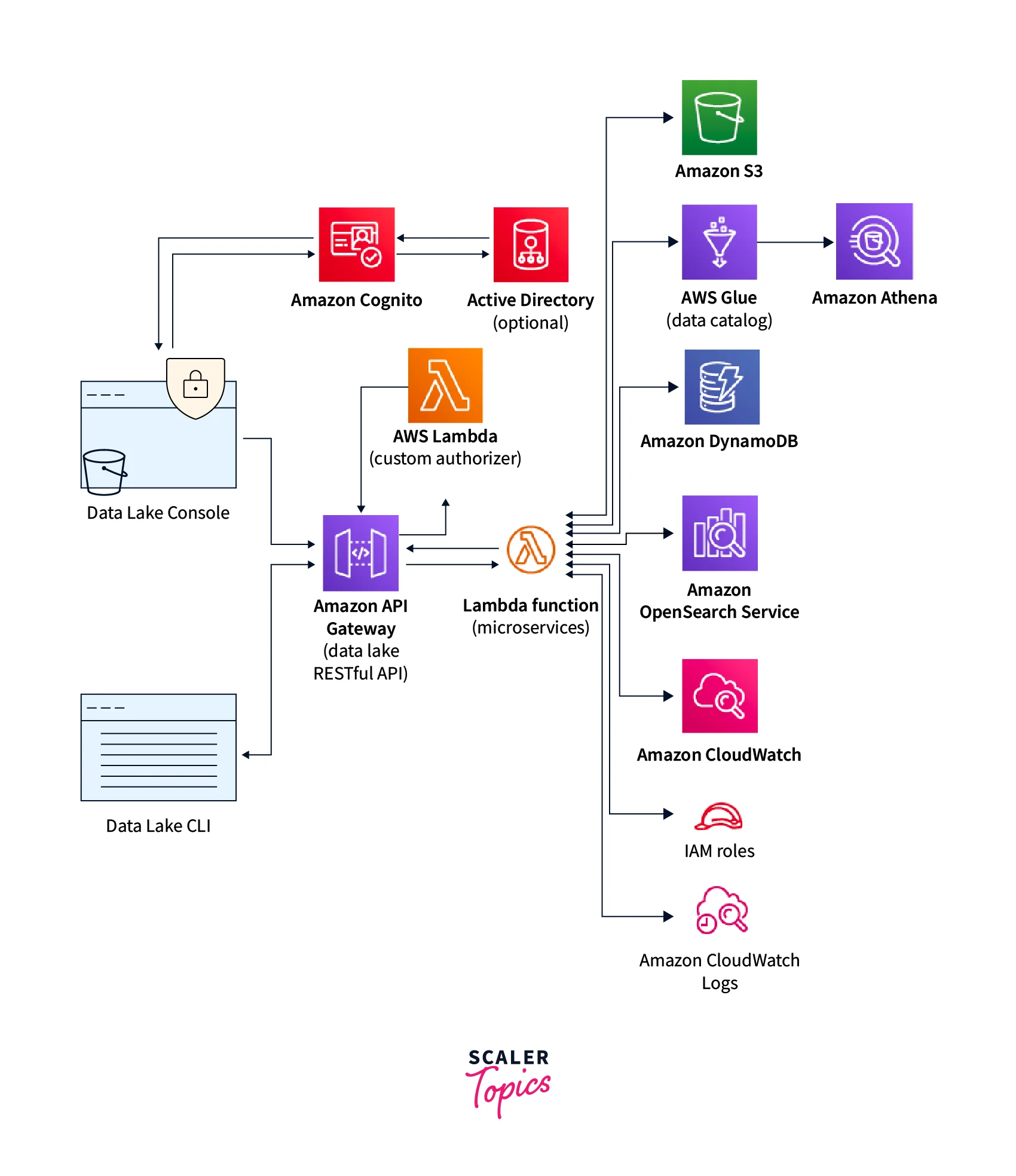
- This example uses AWS CloudFormation to deploy the infrastructure to the data lake.
- The data lake implements a data lake API to provide access to data lake microservices like AWS Lambda.
- These microservices integrate with Amazon S3, AWS Glue, Amazon Athena, Amazon DynamoDB, Amazon OpenSearch Service, and Amazon CloudWatch Logs to provide the ability to create, upload, and search for data storage, management, and audit functions.
- This solution builds a data lake and deployed it into an Amazon S3 bucket for static website hosting.
- It also configures an Amazon CloudFront distribution to be used as access to the solution’s console.
- The solution uses an Amazon Cognito user pool which helps to manage user access to the console and the data lake API.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Features of AWS Data Lake
Let's learn about the features of AWS Data Lake.
1. Data Access Flexibility
AWS Data Lake provides access to the pre-signed Amazon S3 URL. It uses the IAM role to control the direct access to any kind of dataset in Amazon S3 storage, which makes it flexible in accessing different kinds of data.
2. Data Transformation and Analysis
AWS Data Lake transforms and analyses the data in a better way. It attaches the dataset with its metadata with the help of Amazon Glue and Amazon Athena services to transform and analyze the data for various use cases.
3. Managed Storage Layer
AWS Data Lake works as a managed layer of the data. It secures and manages the storage. It manages the data using the managed Amazon S3 bucket and provides encryption to the data using the AWS Key Management Service(KMS) service.
4. Federation Sign-in
AWS Data Lake provides the option of Federation sign-in. We can allow users to sign in using the SAML identity provider(IdP). Okta and Microsoft Active Directory Federation Services(AD FS) are some of the SAML identity providers.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
5. User Interface
AWS Data Lake provides an inbuilt web-based UI(user interface). This UI is hosted on Amazon S3 and delivered by Amazon CloudFront. Using the console, the users of AWS Data Lake easily manage the data lake policies. Adding, removing, searching in data packages, and creating manifests of datasets for further analysis are easily managed with access to the console.
6. Command line interface
We can also use the AWS Data Lake command line interface(CLI). It helps to automate daily lake activities easily. It helps to integrate into existing data automation for data egress, ingress, and analysis.
AWS Data Lake Use Cases
Data Lakes help handle the data. It is very helpful when working with streaming data – which are generated continuously, such as by IoT devices, logs, etc. So let’s talk about the use cases of AWS Data Lake.
Centralized Repository for All Business Data
AWS Data Lake stores a large volume of data. It provides scalable, flexible, and relatively inexpensive for collecting different types of data. AWS Data Lake works as a centralized repository for all the business data. So, businesses use the AWS Data Lakes to store their data without constantly grappling with cost optimization.
Business Intelligence and Analytics
AWS Data Lake helps in business intelligence and analytics. It analyzes the data streams and identifies high-level trends, record-level, and granular insights.
High-performance Analytics Pipeline
AWS Data Lake is required in a high-performance analytics pipeline with fully managed services. It can be realized by using an S3 bucket as a significant data source, AWS Glue as an ETL tool, and AWS Athena, which gives users the ability to query data in SQL.
Data Science
AWS Data Lake helps unstructured data to create more possibilities for analysis and research by enabling innovative applications of machine learning(ML), advanced statistics, and predictive algorithms.
Data Serving
AWS Data Lakes are part of high-performance architectures for applications that rely on streaming or real-time data, which includes `fraud detection tools, IoT devices, etc. So, Data serving is also one of the use cases.
Data Lakes Association with Other AWS Services
Some essential pillars work as a foundation for AWS Data Lake:
1. Amazon S3
- The large amounts of data that are part of the AWS Data Lake architecture get stored in Amazon S3.
- It provides the facility to store any form of data, whether structured, unstructured, or semi-structured.
- The data stored in Amazon S3 can be moved to a cold or warm state when needed.
- Data in a warm state are available for immediate use.
- If we are not thinking of using a particular batch of data for some time, then we can move it to a cold state.
- The above strategy helps in making AWS Data Lake a cost-effective architecture.
2. AWS Lake Formation
- AWS Lake Formation makes the creation of AWS Data Lake a lot easier and more automated.
- It increases data security by enabling authentication and authorizations.
- It also adds to the data governance strategies missing in the stored data.
- It centralizes security and governance.
3. Amazon Athena
- Amazon Athena makes the searching of Data stored in Amazon S3.
- It is an interactive query service.
- When integrated with AWS Glue, it creates a metadata catalogue for the large amount of data making the search process easier.
- It supports standard SQL queries.
4. Amazon EMR
- It helps in the following:
- Data processing
- Data Analysis
- Machine learning operations on top of the data.
- It uses popular big data frameworks like Apache Hadoop, Hive, or Presto, aiding the AWS Data Lake Architecture.
Turn Learning into Career Growth
5. AWS Glue
- AWS Glue is used to import data in any size and can be all at a time or in batches.
- It solves the following purposes:
- Data integration
- Data Discovery
- Data preparation
- Data Transformation
- It provides the facility to scale using a time-saving approach, as AWS Glue handles the data structures, schema, and data transformations well.
Cost of AWS Data Lake
As we know, AWS works on a pay-as-you-go model. For AWS Data Lake, we need to set up different services of AWS like Amazon S3, Amazon Athena, Amazon EMR, AWS Lake Formation, and AWS Glue. Let’s know about their pricing in detail.
Amazon S3 Pricing
- In AWS free tier, we get 5GB of Amazon S3 in the Standard storage class; 20,000 GET Requests; 2,000 PUT, COPY, POST, or LIST Requests; and 100 GB of Data Transfer Out every month.
- As we exceed the limit, the standard pricing varies from one region to another region.
- S3 pricing is divided into storage pricing, Data Transfer pricing, fetch and request data pricing, replication pricing, Analytical pricing, and Pricing to process the data with S3 lambda.
Amazon Athena
- In this service, we have to pay only for the queries we run and charge according to the amount of data scanned by each query.
- We can save more when we compress the data and use columnar data formats.
- Amazon Athena uses S3, Glue, and more services of AWS. So, for pricing, it is also dependent on them how the other services are being used.
Amazon EMR
- In this service, we have to pay a per-second rate for every second we use, with a minimum of one minute.
- Its pricing also depends on how we deploy our EMR applications.
- Amazon EMR pricing is simple and predictable and varies from region to region.
AWS Lake Formation
- We can store the first million objects in the AWS free tier and make one million monthly requests.
- Its pricing varies from one region to another, based on the data scanned in per TB, and pricing is calculated monthly.
- It also charges a fee for transaction requests and metadata storage.
AWS Glue
- This AWS service gets one million objects stored for free in the free tier.
- It works with S3 and Data catalog, so its pricing also depends on them.
- With this service, we can pay at an hourly rate. For crawlers and ETL jobs, we billed by the second.
This is a brief idea about how much we have to invest in AWS Data Lake using different services. To know more pricing detail, AWS provides the pricing calculator in which we have to select the services, and they calculate the Pricing for our services.
Getting Started with AWS Data Lake
Creating Data Lakes is not an easy task. It takes a lot of time. So, AWS Lake Formation is here to solve this situation.
Lake Formation is an AWS service to build AWS Data Lakes quickly. It easily creates secure AWS Data Lakes and makes the data for wide-ranging analytics. It simplifies security management with centrally defined security, governance, and auditing policies.
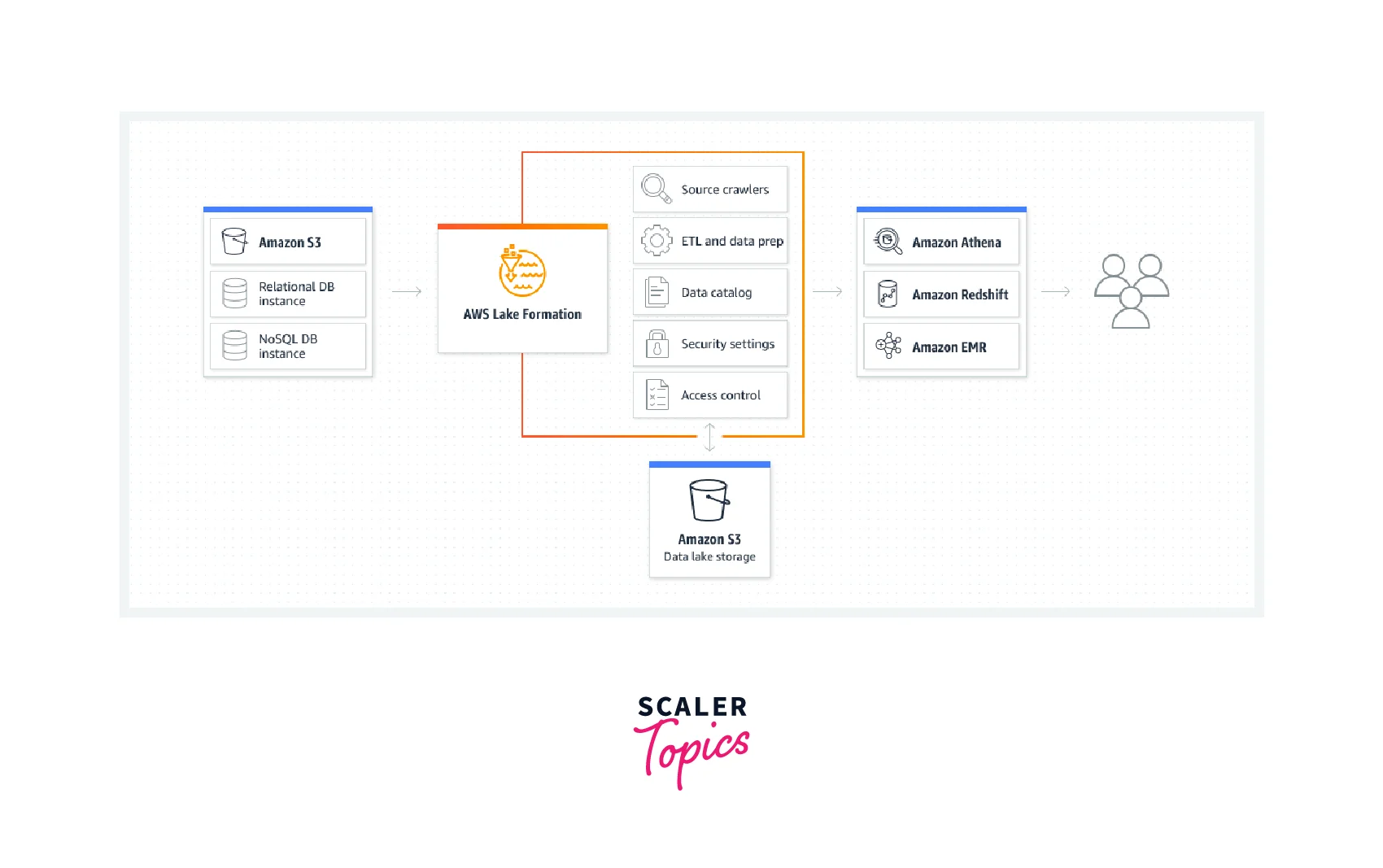
Let’s learn how to create an AWS Data Lake with a basic demo. In this demo, we keep a dataset named pincode in Amazon S3. We use AWS Glue to catalogue the data. Then with the help of AWS Lake Formation, we provide specific permission for the office user and client user. Office user is provided with access to all resources within the lake, he works as an admin. Client users are provided with limited access. With the help of Amazon Athena, the users query the data as per the defined permission.
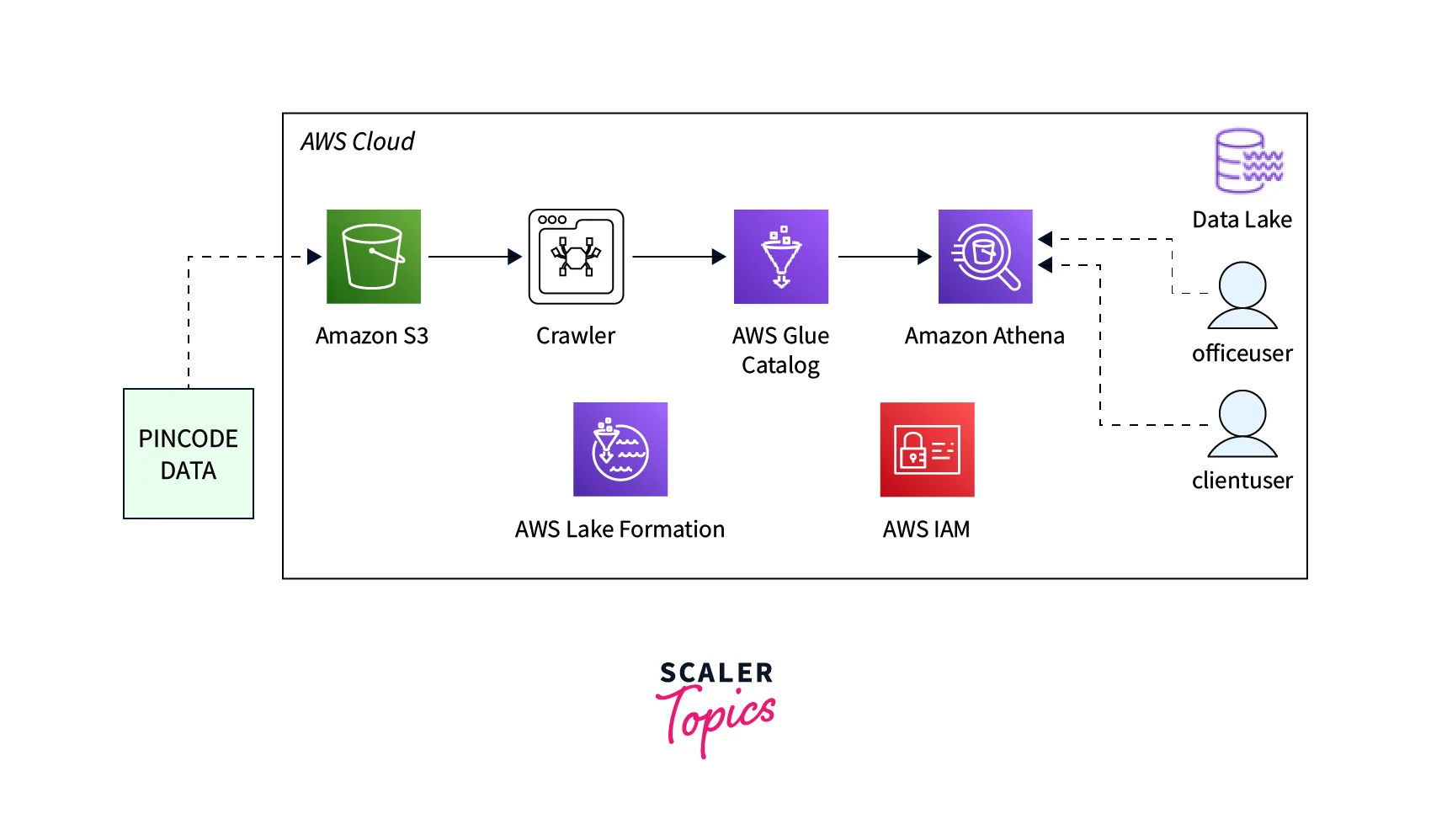
Let’s get started to create the AWS Data Lake.
It follows the following steps:
1. Create IAM users
-
Log in to the AWS console. I am using Mumbai as the region. Go to the IAM Management Console by clicking on IAM.
-
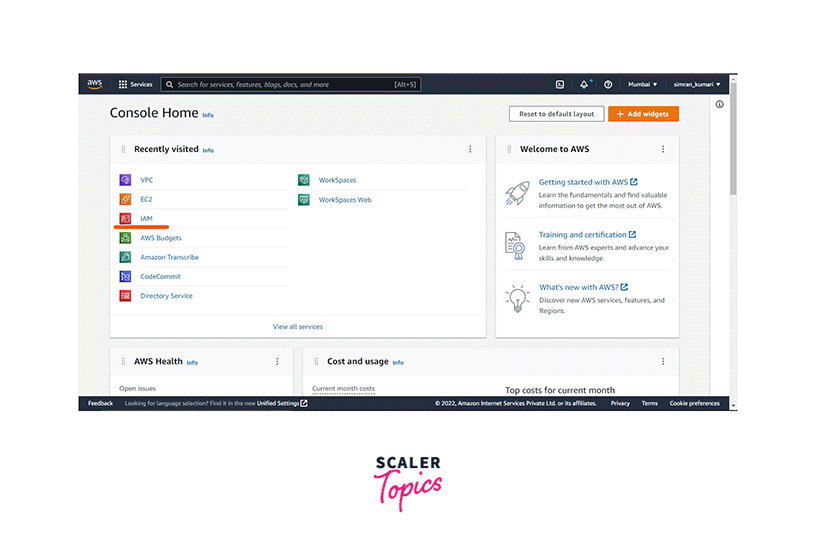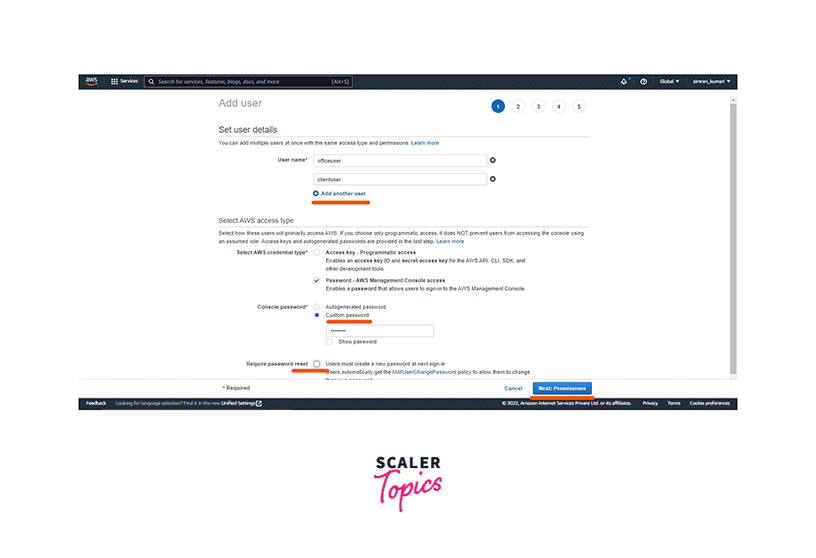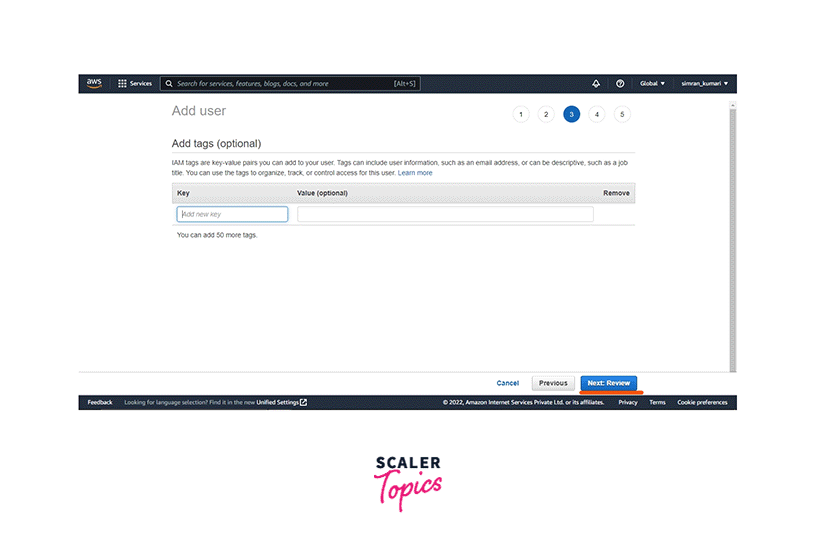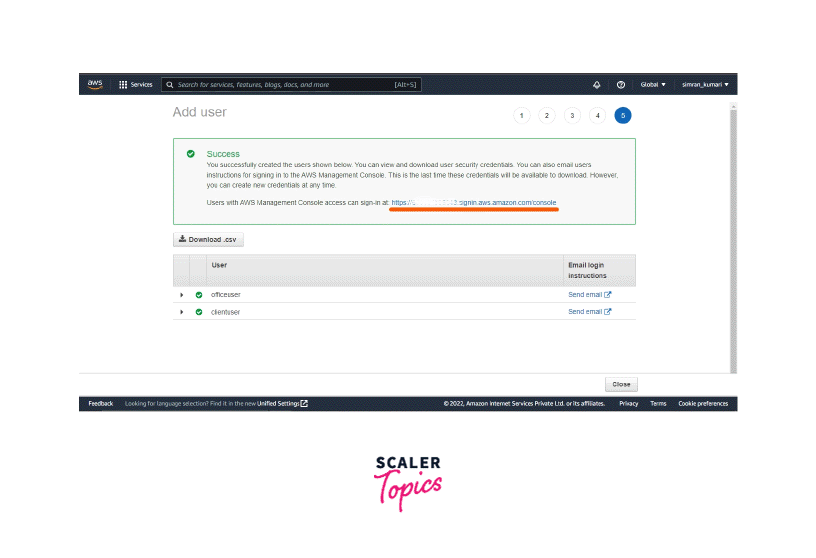
Click on the Users menu and then click on the Add user button.
-
On the next screen, click on Add another username. Fill in the user's name. Select Password - AWS Management Console access as the Access type. Select Custom password for the Console password. Type the password and remember it, as it will help in the future. Uncheck the Require password reset option. Finally, click on the Next: Permissions button.
-
Next, click on the Attach existing policies directly for the Set permissions. Select AmazonS3FullAccess, AmazonAthenaFullAccess, CloudWatchLogsReadOnlyAccess, AWSCloudFormationReadOnlyAccess and AWSGlueConsoleFullAccess as the policies. Click on the Next: Tags button.
-
Click on Next: Review on the next screen.
-
Click on Create Users button on the next screen.
-
IAM users are created. Note down the console sign-in URL. It helps to log in as users later.
Next, we create an IAM role used by the AWS Glue Crawler.
2. Create IAM Role
- Go to the IAM Management Console. Click on the Roles and then click on the Create role button.
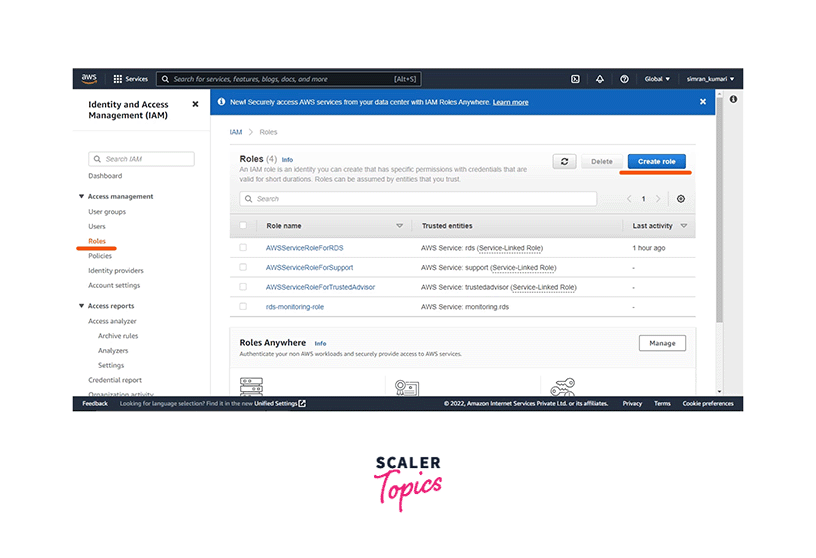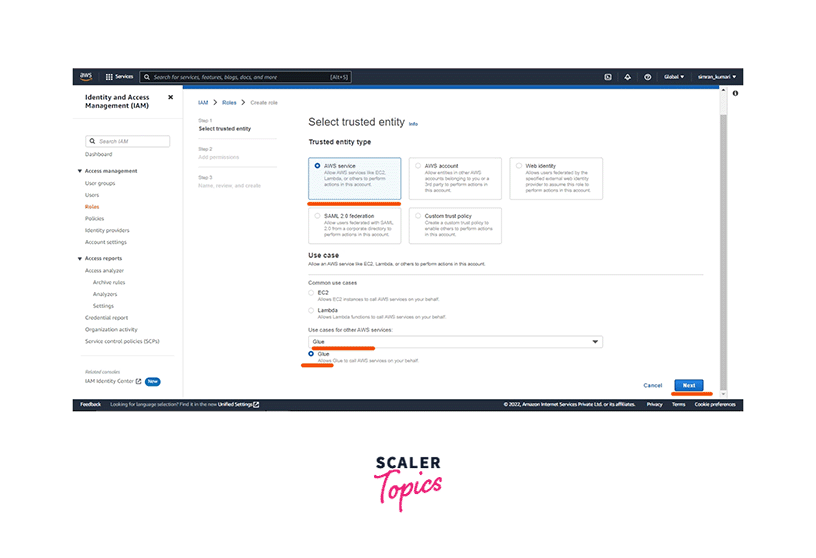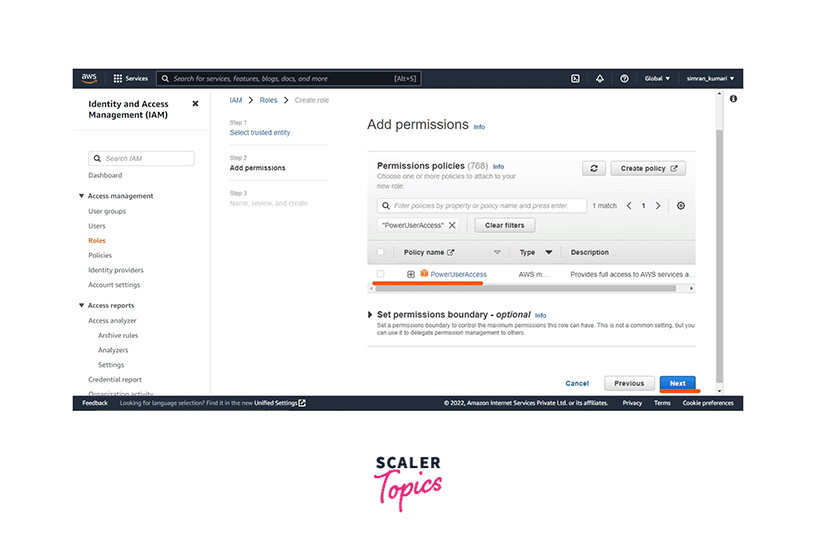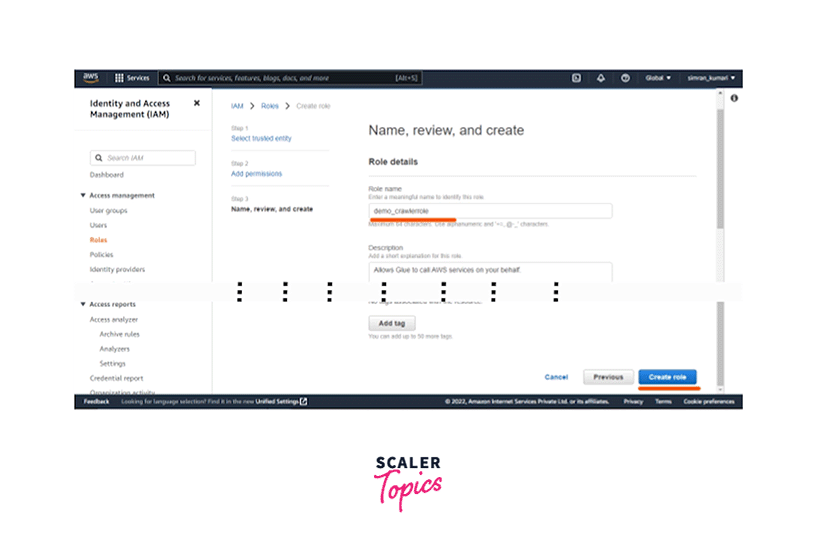
-
On the next screen, select AWS Service as a Trusted entity type. Choose Glue from the Use cases for other AWS services and select Glue. Click on Next.
-
After this, select PowerUserAccess as the Permissions policies and click on Next.
-
Next, enter the Role name. Scroll down and click on the Create Role button.
IAM Role is created. Next, we have to create an S3 bucket.
3. Create S3 Bucket
-
Go to the search bar of the console and search for S3. Click on S3.
-
On the next screen, click on Create bucket.
-
Fill in the bucket name and scroll down. Click on Create bucket.
-
Next, click on the bucket name to open it.
-
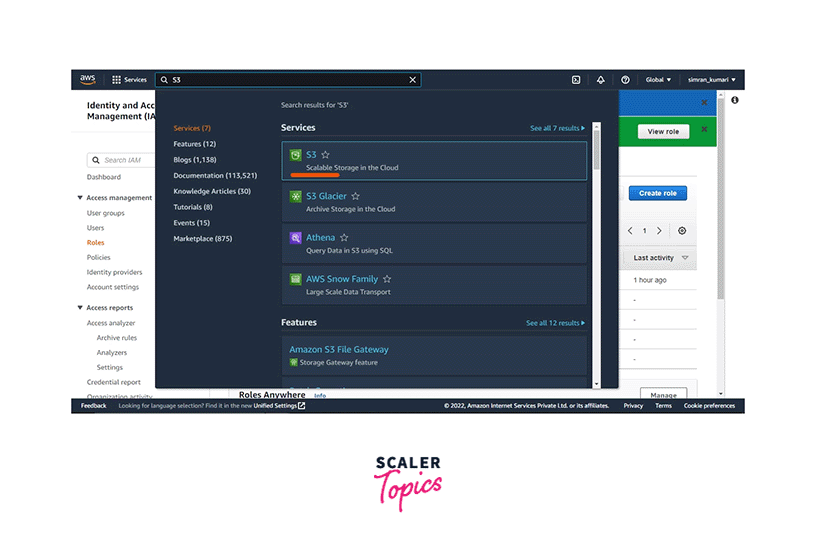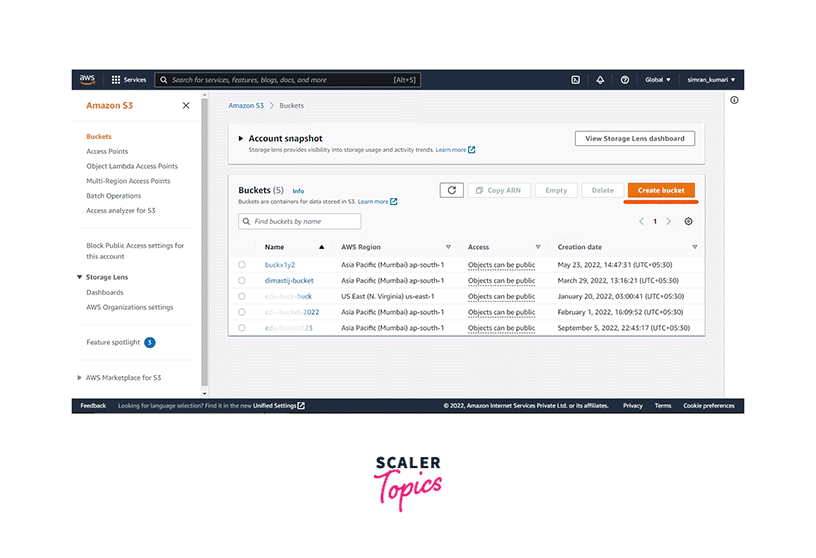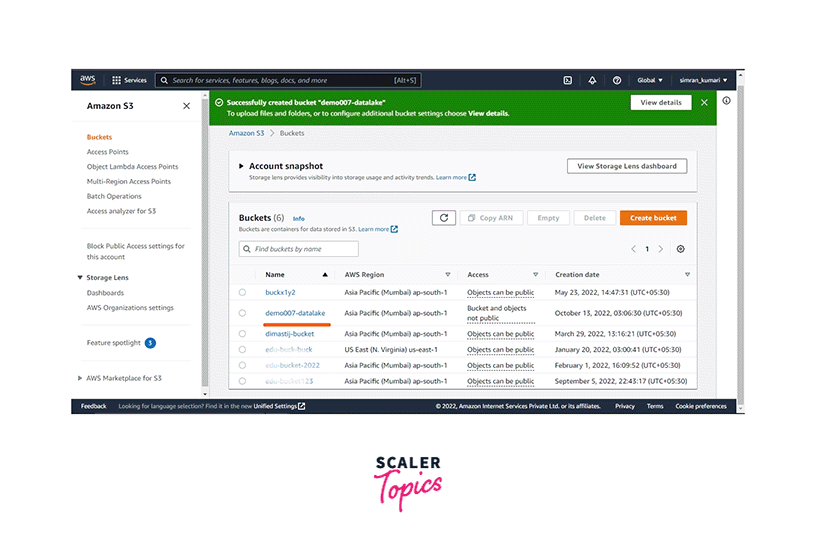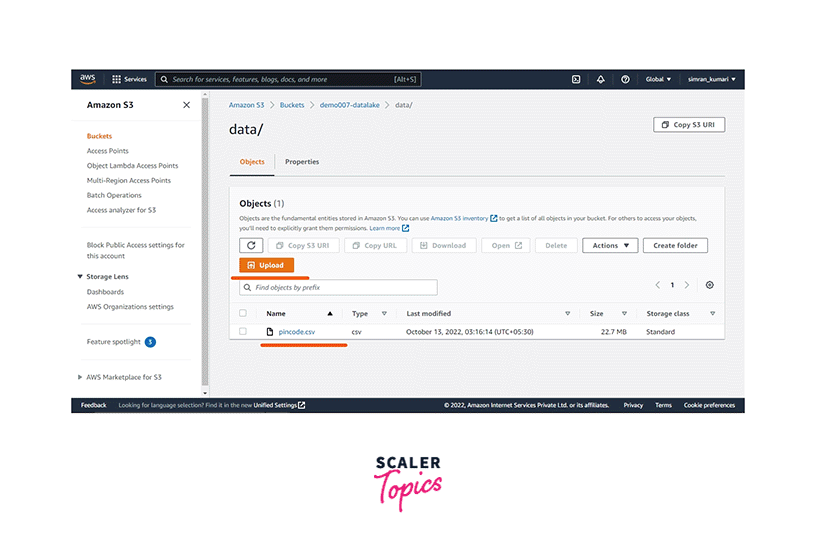
Create two folders of data and script using Create folder button. The data folder keeps the AWS Data Lake data, while Amazon Athena uses the script folder to configure the Query result location. To open the data folder, click on it.
-
Click on Upload to upload the files, select the pincode data stored in the local machine and upload it. You can see the data now in the data folder.
The data is uploaded. Let’s start configuring the Data Lake configuration.
4. Configure Data Lake
-
Go to the search bar of the console and search for Lake Formation. Click on AWS Lake Formation.
-
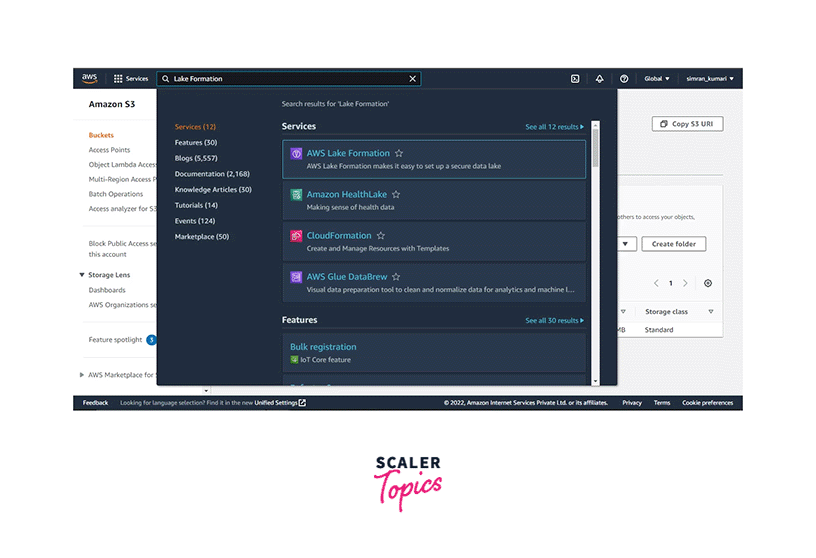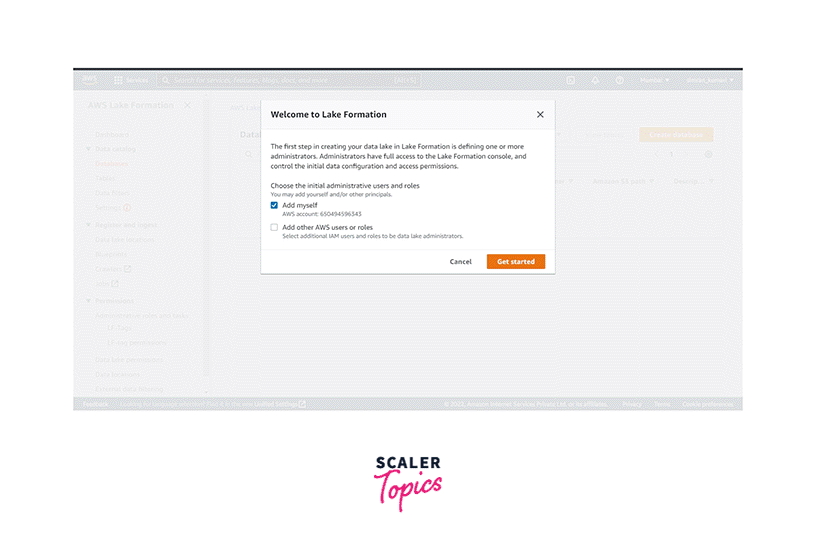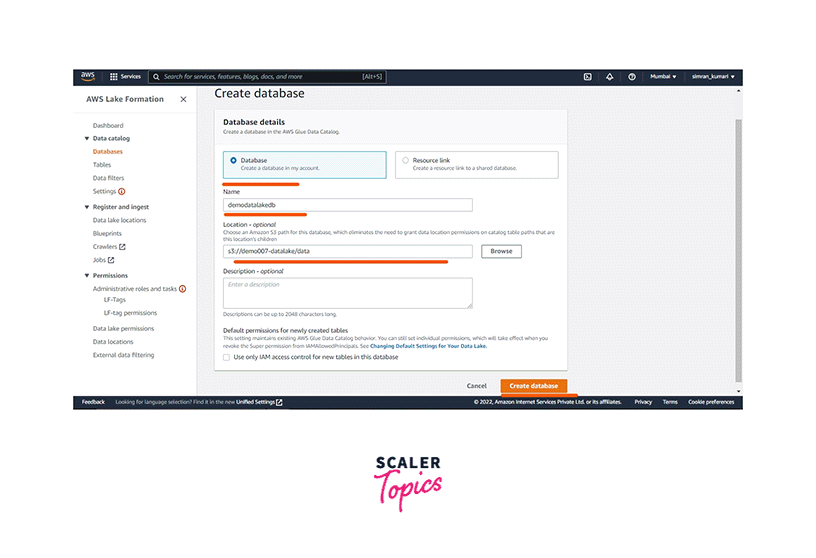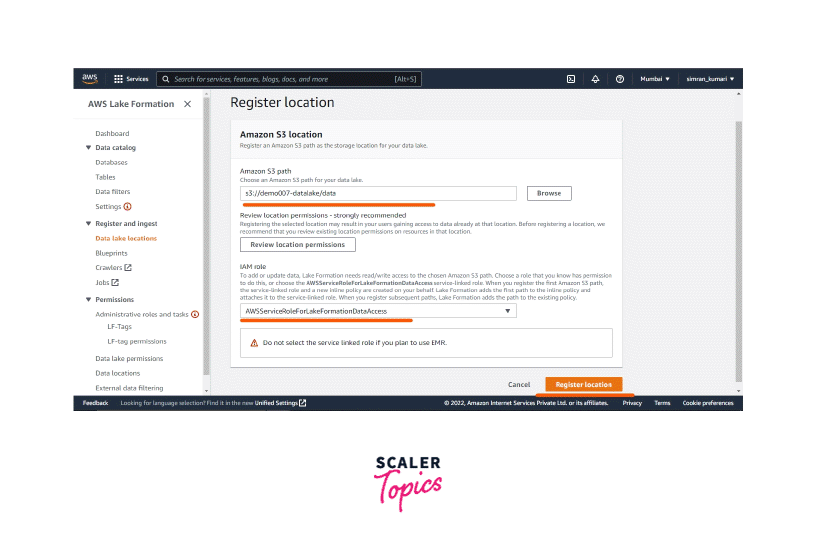
On the next screen, if we are using AWS Lake Formation for the first time in the region, it will prompt us to Choose the initial administrative users and roles. Tick, add me and click on Get Started.
-
Next, click on the Databases and then click on Create database.
-
Following this, choose Database, fill in the name of the database, and set the S3 Data Lake path. Uncheck the option - Use only IAM access control for new tables in this database. Click on Create database.
-
The database is created, now register the Amazon S3 bucket as your data lake storage. Click on the Data Lake locations and then click on Register location.
-
On the next screen, enter the Amazon S3 path and select the AWSServiceRoleForLakeFormationDataAccess role for the IAM Role.
The Data Lake location is set successfully. Now we use a crawler to catalogue the data in the database.
5. Configure and Run Crawler
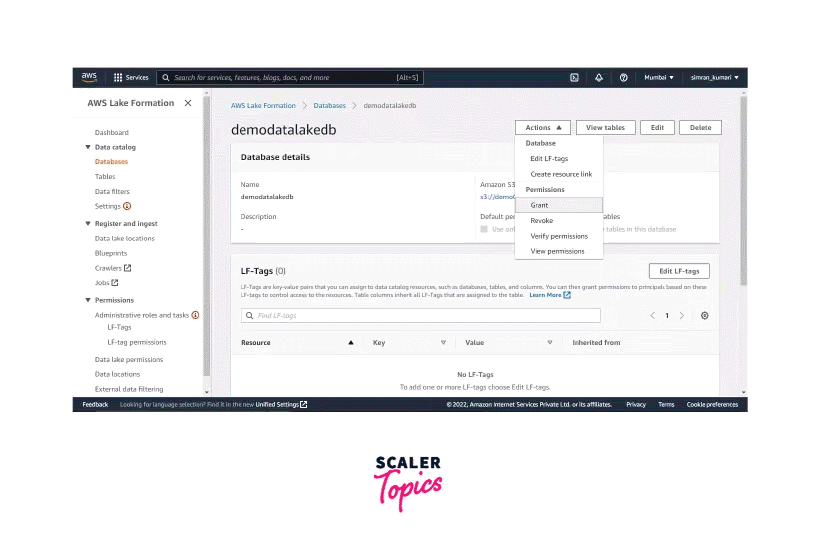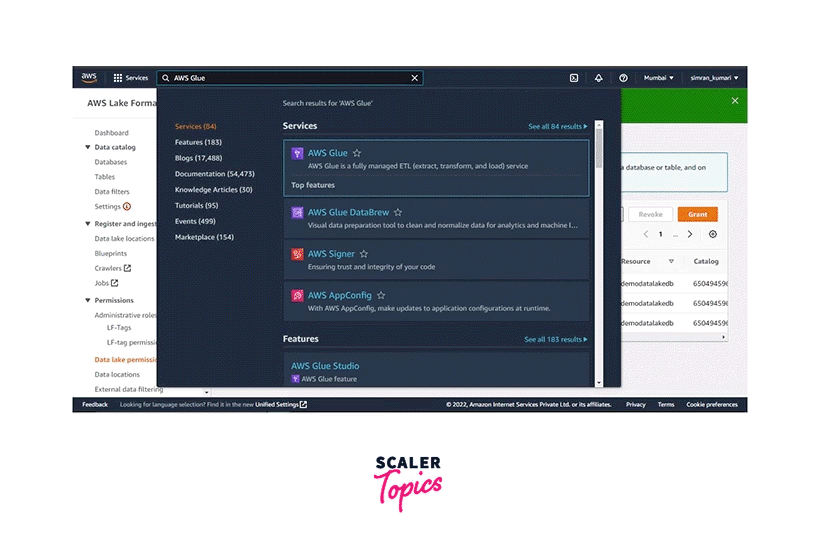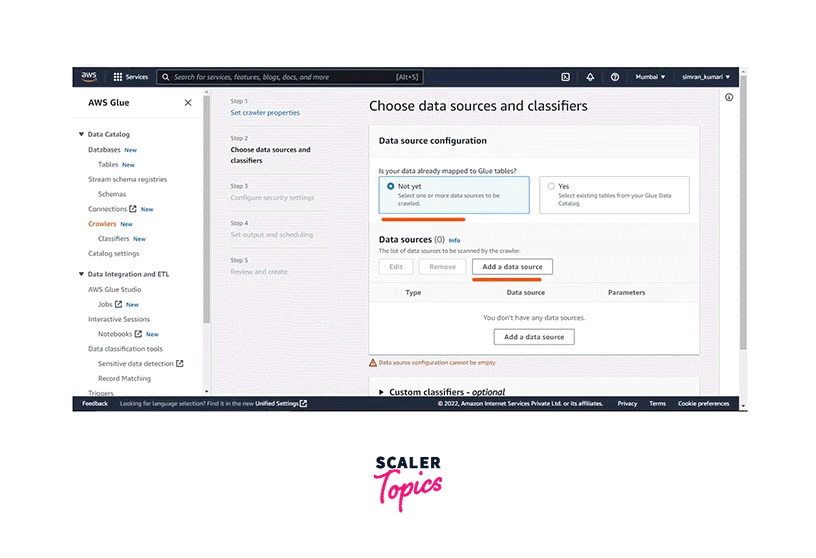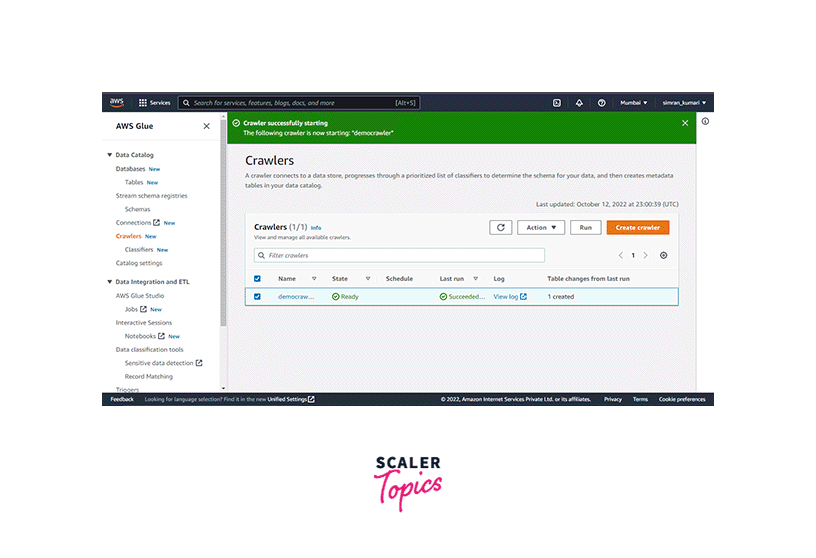
-
Click on the Databases, select the database name, and click on the Grant menu option under the Action dropdown menu.
-
On the Grant data permissions screen, select the crawler role created earlier for the IAM users and roles field. Scroll down and select only Create and Alter permissions for the Database permissions. Then click on the Grant button.
-
After granting the permissions, now time to configure and run the crawler, search the AWS Glue in the search bar and open its console.
-
Click on the Crawlers and then click on the Create Crawler button.
-
On the next screen, enter the Crawler name and click Next.
-
After this, for data source configuration, click on Add a data source.
-
Choose S3 in the data source, add the data source path, scroll down and click on Add an S3 data source. Click on Next.
-
Select the IAM role created earlier from the dropdown list. Click Next.
-
Next, select the database and choose On-demand as the frequency. Click Next.
-
Finally, review and click on Create Crawler.
-
Select the crawler and Run. It may take a couple of minutes to finish crawling the bucket.
Now we have to set User Permission to the Catalog.
6. User Permission to the Catalog
-
On the AWS Lake Formation console, click on the Tables option on the left menu. Select the Sales table and click on the Grant menu option under the Action dropdown menu.
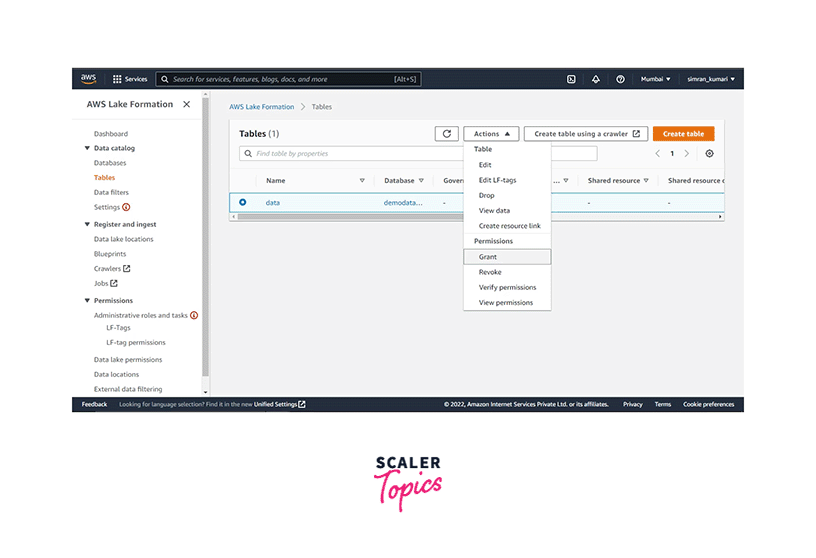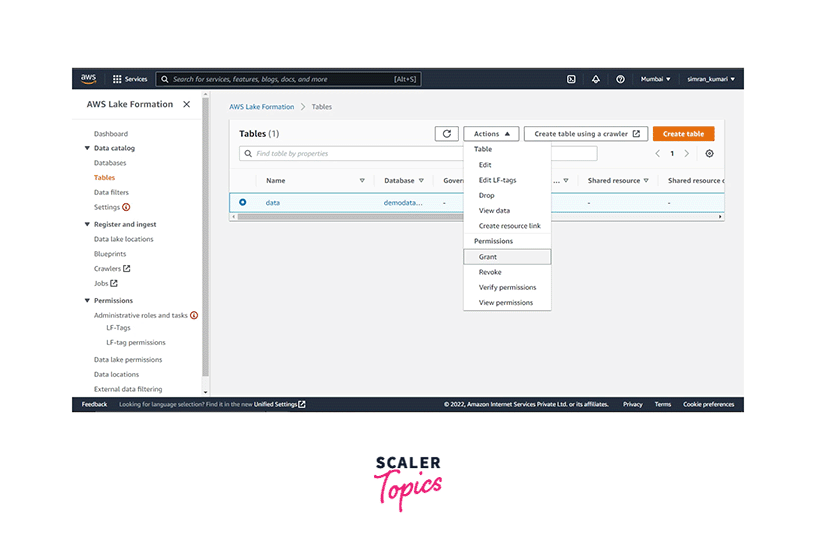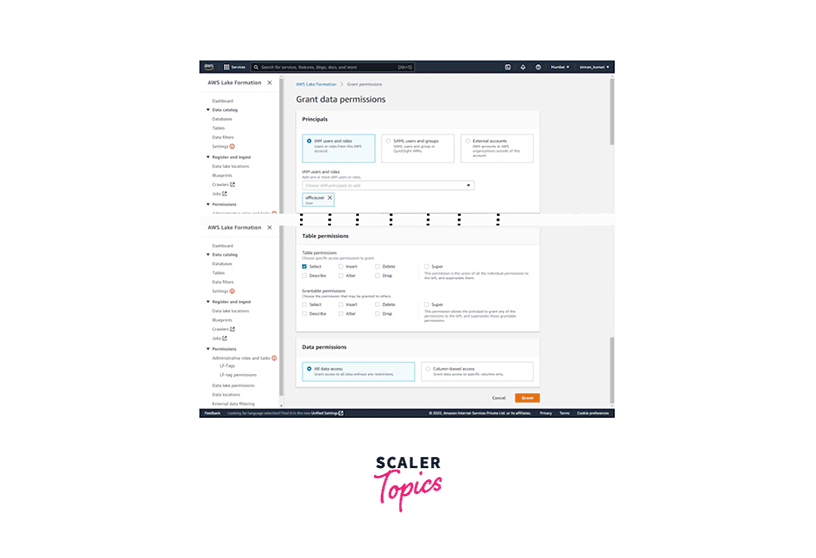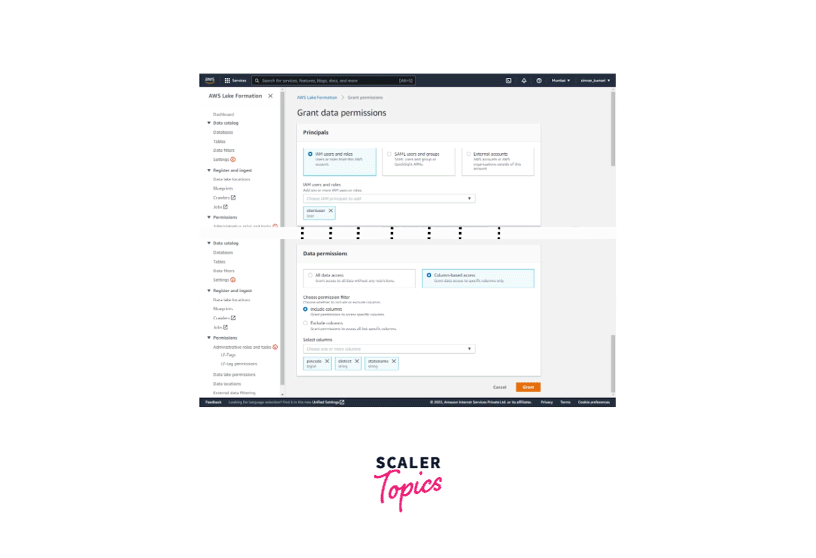
-
Select the office user for the IAM users and roles field on Grant data permissions. Choose only Select from the Table permissions and choose All data access from data permissions. Click on Grant.
-
Follow the same steps up to the Grant data permissions page. This time select the client used for the IAM users and roles field. Choose only Select from the Table permissions and choose Column-based access from data permissions. Select Include columns and select a few columns from the dataset. Click on Grant.
User permissions are configured for the users. Now log in using both users and check their permission on the tables in the data lake.
7. Query Data
-
login to the console sign-in URL, which we have to get in step one, using the username and password. Let’s first login with the office user. Go to the search bar of the console and search for Athena. Click on Athena.
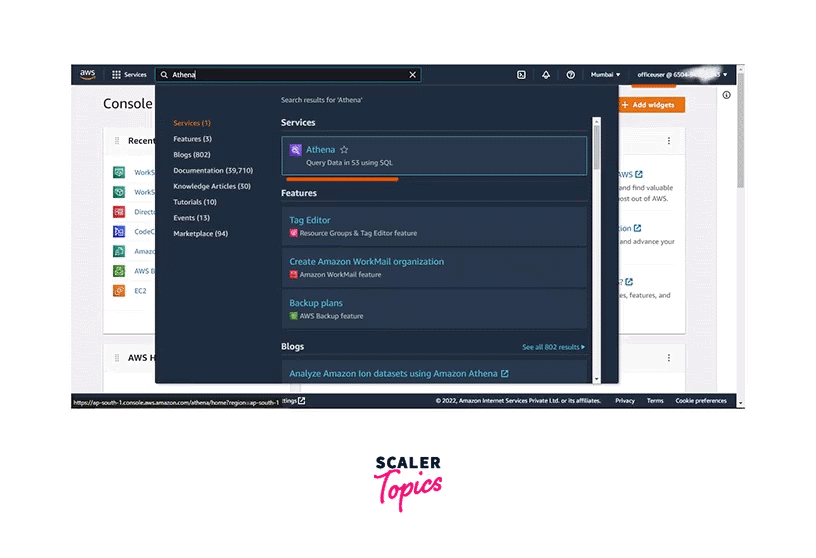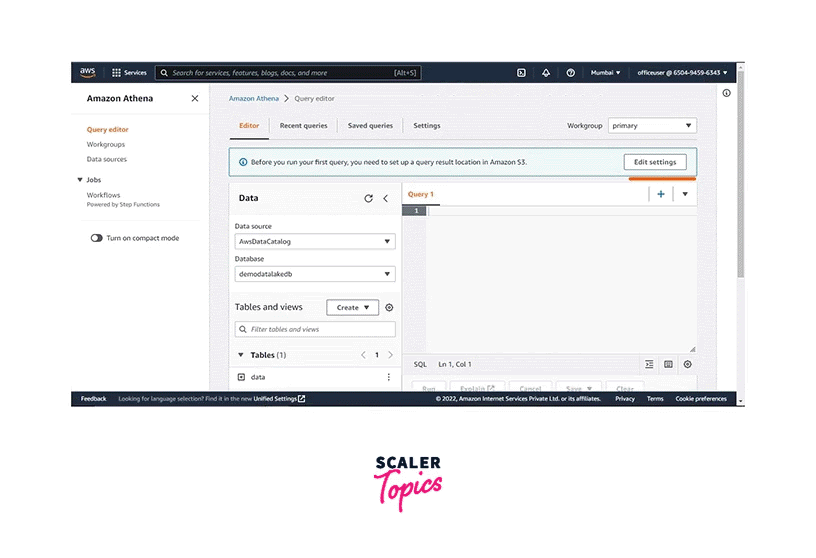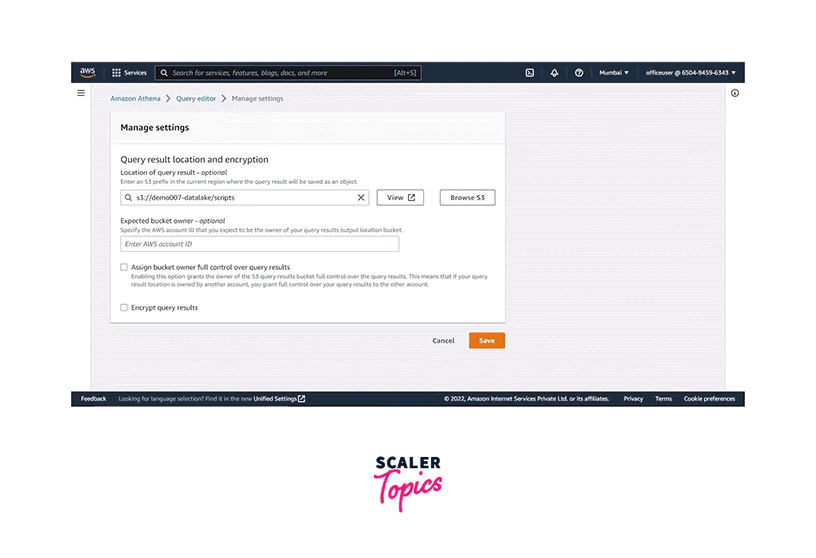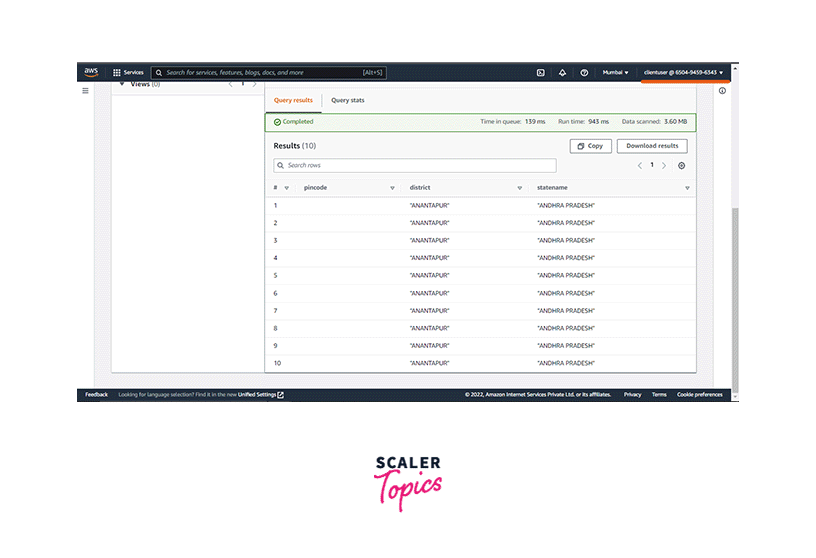
-
Click on Query editor. The data source, database, and table are shown on the screen. Before running the query, we need to configure the Query result location for AWS Athena. Click on Edit settings.
-
Enter the Query result location and encryption path, and click on Save.
-
Go to the Query editor and run the query.
-
It will show the output in the Results section. We can see it by scrolling down.
-
Again login to the console sign-in URL, but this time login with the client user. Go to Athena and set the Query result location before running the query. After configuring, go to Query editor and run the same query. The output will be shown according to the permissions created earlier.
This simple demo of creating the data lake gives permissions to different users.
Benefits of AWS Data Lake
There are numerous benefits of using AWS Data Lake. Let’s have a look into a few of those benefits:
Resource Optimization
AWS Data Lake optimizes the resources by isolating (cheap) storage from (expensive) compute resources. These are extensively cheaper than the databases when we work on high scales.
Less Ongoing Maintenance
AWS Data Lake needs less ongoing maintenance as Amazon services fully manage it. We can ingest the data in it without any kind of transformation or structuring means. So, it is easy to add new S3 sources and modify the sources without having to build any custom pipelines.
Increase Innovation
In AWS Data Lake, all the data are available for analysis. With the help of that analysis, different organizations can improve innovation to discover new opportunities for savings or personalization. ML and predictive analytics help these innovations with the help of a broader data scale.
Use the Best Services for the Job
We can get the best performance, scale, and cost per requirement in AWS Data Lake using AWS analytics services. It helps to quickly extract the data insights using the most relevant tool for the required job.
Eliminate Server Management
AWS provides us with a lot of services for management. Most serverless options are for data analytics. AWS analytics services are one of the services which allow us to use, administer and manage easily.
AWS Data Lake vs Data Warehouse
Before talking about the differences between the two, let’s first explore the Data warehouse.
What is Data Warehouse?
A data warehouse is a centralized repository of information for making informed decisions. It contains multiple databases. The data is stored in these databases in tables of rows and columns. When data is ingested in the warehouse, it gets stored in the tables described by a given schema.

How do AWS Data Lake and Data Warehouse Work together?
The AWS Data Lake is combined with Data Warehouse and Databases for a business use case to yield maximum profit. A data warehouse is mainly designed for analytics purposes. It analyzes a tremendous amount of data to understand the trends and patterns in the data.
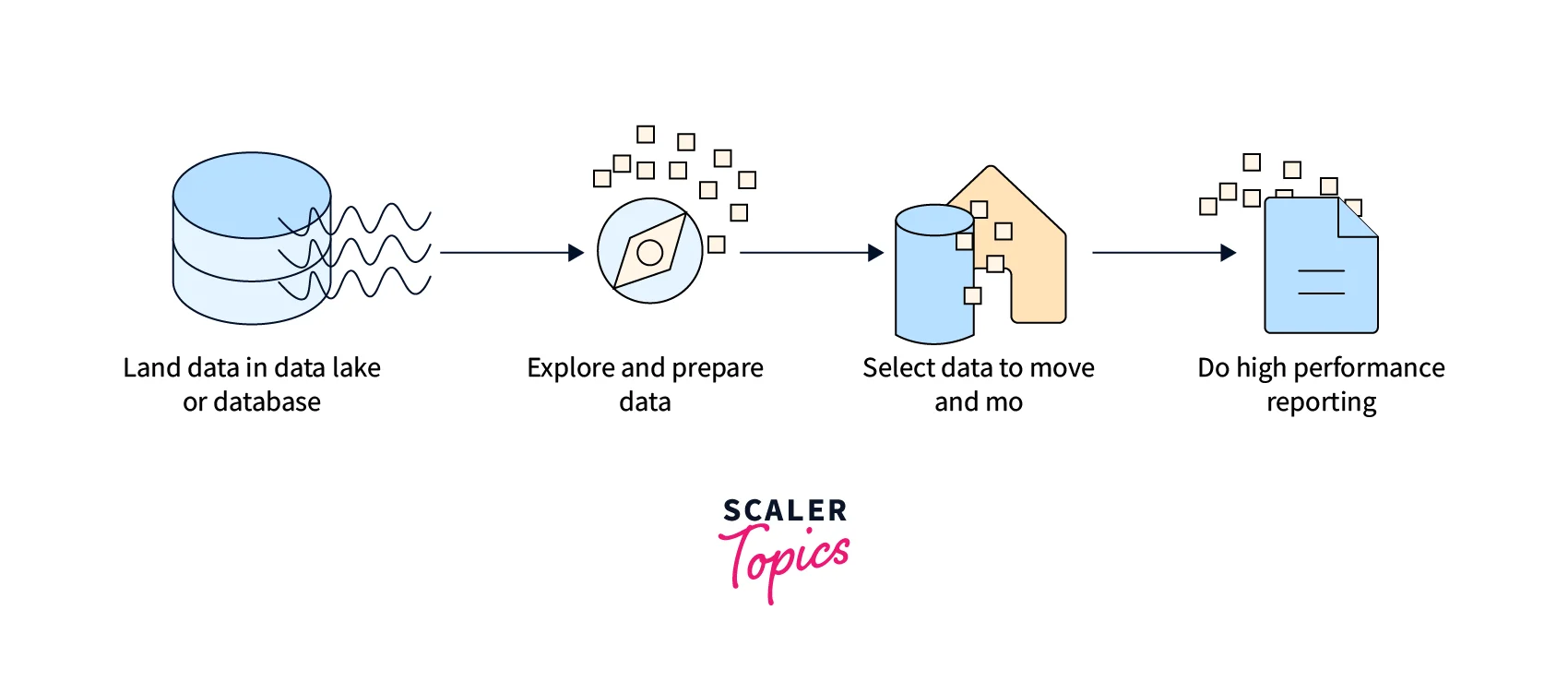
The tons of unorganized data are stored in a data lake or database. It is interpreted, catalogued, and converted into a tabular format to be stored in the data warehouse. The data is analyzed here in the data warehouse, and reports are generated.
Difference Between AWS Data Lake and Data Warehouse
There are multiple differences between the two:
1. Data Structure:
Data lakes primarily store raw data. This data is unprocessed. The data in the AWS Data Lake can be stored in the source format without converting it to a given template.
The Data warehouse stores processed data. It removes unused data and reduces storage costs. The data here is comparatively more organized and is used in analysis to generate reports.
2. Data Quality:
A Data warehouse cuts off unwanted data that might never be used and saves space. On the other hand, Data Lake keeps all the data, whether it is of immediate use or not needed, all in one place. This results in the data lake behaving as a dump area without proper governance.
3. Accessibility:
The Data Lake does not have any structure to follow, so the data stored here is easily accessible and easy to update. On the other hand, the data warehouse is structured, so the data is easy to fetch but slightly costly to update/change.
4. Schema:
The data must follow a particular schema/structure to be stored in the Data warehouse. To be explicit, storing the data in Data Warehouse gets converted into a tabular format of rows and columns. No such structure needs to be followed in the case of AWS Data Lake.
5. Purpose of Data:
Usually, the data is stored in AWS Data Lake when we are not sure about the questions like:
- When to use the data?
- How to use the data?
Once we are sure of the above questions, we can trim the data as needed, and then the data is ready to be stored in Data Warehouse.
6. Storage Costs:
Storing data in AWS Data Lake is comparatively less expensive. Storing data in the Data Warehouse is not only a costly but also a time-consuming process.
7. Users:
The data stored in the data warehouse is suitable for use only by Business Analysts. On the other hand, the data stored in Data Lakes is used not only by business analysts but also by Data scientists and Data developers.
8. Analytics:
The data from Data Warehouse is utilized to generate reports for Batch reporting, BI, and visualizations. AWS Data Lake's data is used for Machine learning analytics, predictions, data discovery, etc.
Conclusion
- AWS Data Lake is the service that provides the optimized solution to big data problems and a better way to handle those.
- It centralizes all the business data repositories in one place where we can perform different analyses.
- AWS Data Lake uses different AWS services like AWS Lake Formation, Amazon S3, Amazon Athena, AWS Glue, and AWS EMR.
- Many organizations use AWS Data Lake to store and analyze and manage their data.
- AWS Data Lake allows to evolve business around the data assets, and it is the best fit for more business value and competitive differentiation.
- We can easily access the big data platforms using AWS Data Lake.