Amazon Managed Streaming for Apache Kafka (Amazon MSK)
Overview
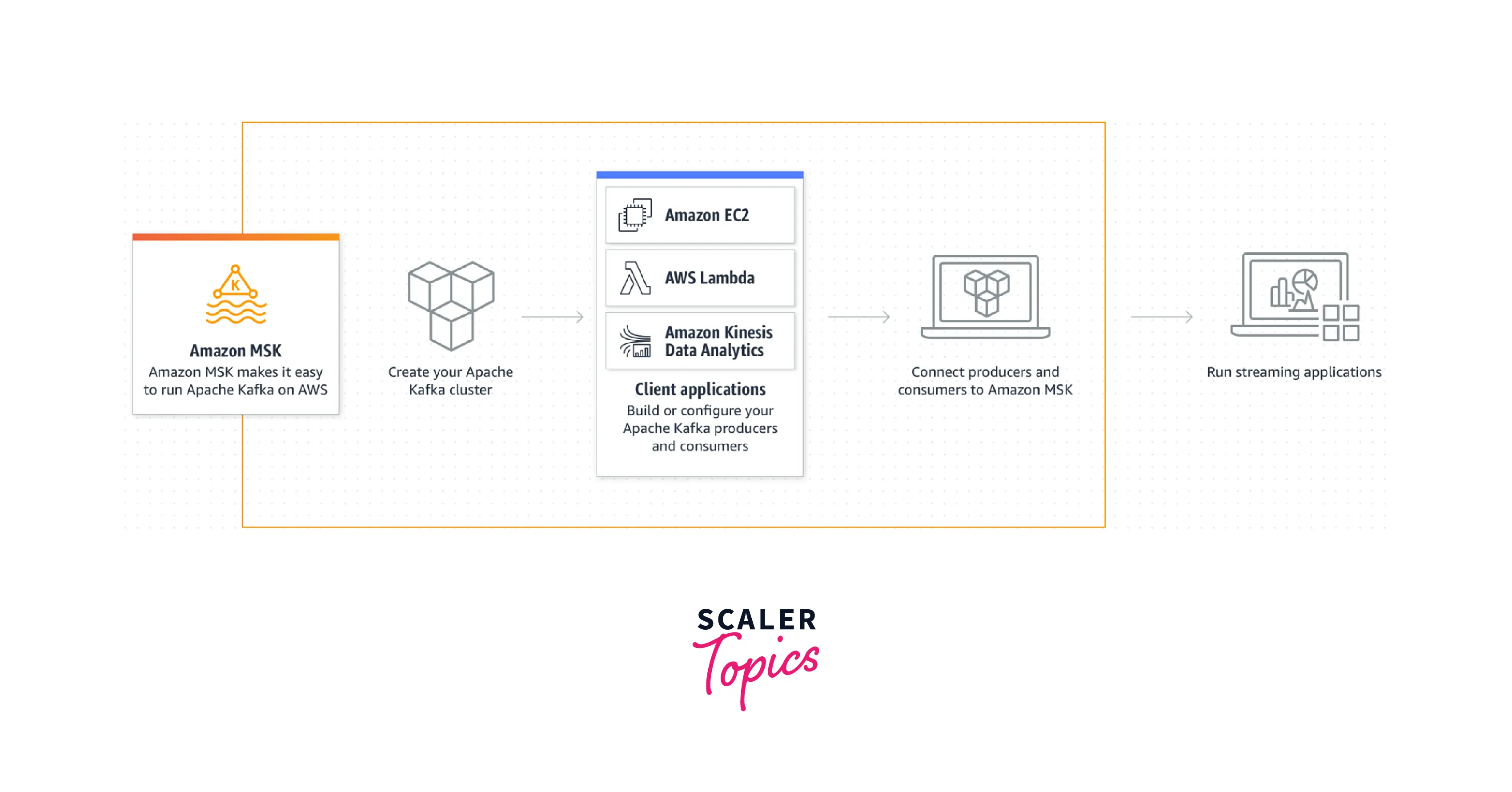
You can create and execute Apache Kafka applications to process streaming data using Amazon Managed Streaming for Apache Kafka (Amazon MSK), a fully managed service. Control-plane actions, including building, updating, and deleting clusters, are offered by Amazon MSK. It enables the utilization of Apache Kafka data-plane functions, including data creation and consumption. Any Apache Kafka versions listed under Supported Apache Kafka versions can be used to build clusters using Amazon MSK.
What is Amazon MSK?
Amazon Managed Streaming for Apache Kafka or Amazon MSK allows you to run applications that utilize Apache Kafka within AWS. Apache Kafka functions as a persistent communications system with a publisher/subscriber-based stream processing platform. The capacity to accept data with exceptional fault tolerance is one of its primary properties. This enables continuous streams of records while maintaining the integrity of the data, including the sequence in which it was received.
The control-plane activities, including those for building, updating, and removing clusters, are handled by Amazon MSK. You can employ Apache Kafka data-plane activities with it, including those for generating and consuming data.
Apache Kafka then acts as a buffer between these data-producing entities and the customers that are subscribed to it. Subscribers receive information from Kafka topics on a first-in, first-out basis or FIFO, allowing the subscriber to have a correct timeline of the data that was produced.
Features of Amazon MSK
In this part of the article, we will focus on the features of Amazon Managed Streaming for Apache Kafka.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Fully Compatible
Support for native Apache Kafka APIs and tools
Amazon MSK supports native Apache Kafka APIs and existing open-source tools built against those APIs. As a result, current Apache Kafka applications can use Amazon MSK clusters without modifying their source code. You continue to assemble data lakes, stream updates to and from databases, and power machine learning and analytics applications using Apache Kafka's APIs and open-source ecosystem.
No Servers to Manage
Fully managed
You can construct a fully managed Apache Kafka cluster that adheres to the deployment best practices for Apache Kafka with only a few clicks in the Amazon MSK dashboard, or you can create your cluster with your unique configuration. Once you've reached your desired configuration, your Apache Kafka cluster and Apache ZooKeeper nodes are automatically provisioned, configured, and managed by Amazon MSK.
Apache ZooKeeper included
To operate Apache Kafka, manage cluster jobs, and keep track of the state of resources interacting with the cluster, Apache ZooKeeper is necessary. The Apache ZooKeeper nodes are managed for you by Amazon MSK. For no additional charge, each Amazon MSK cluster comes with the right amount of Apache ZooKeeper nodes for your Apache Kafka cluster.
Highly Available
If a component fails, Amazon MSK automatically replaces it without downtime to your applications. This means you don’t need to start, stop, or directly access the nodes yourself. It also automatically deploys software patches as needed.
Highly Secure
Your network setup and IP addresses are completely within your control. Based on the settings you provide, your clusters are available to your own Amazon VPCs, subnets, and security groups. Amazon manages the Amazon MSK virtual private cloud (VPC).
Deeply Integrated
AWS IAM, Amazon Kinesis, Apache Flink, Apache FlinkSQL, AWS Glue Schema Registry, AWS DMS, Amazon Virtual Private Cloud, AWS Key Management Service, AWS Certificate Manager Private Certificate Authority, AWS Secrets Manager, AWS CloudFormation, and Amazon CloudWatch are a few of the integrations.
Scalable
Broker Scaling
A Broker is a Kafka server that runs in a Kafka Cluster. Kafka Brokers form a cluster with a small number of brokers. Then, you may scale up to hundreds of brokers per cluster using the AWS administration panel or Amazon CLI. If you require more than 15 brokers per cluster or more than 30 brokers per account, submit a limit increase request.
Storage scaling
Using the AWS administration panel or Amazon CLI, you can easily increase the amount of storage allocated per broker to correspond to changes in storage needs.
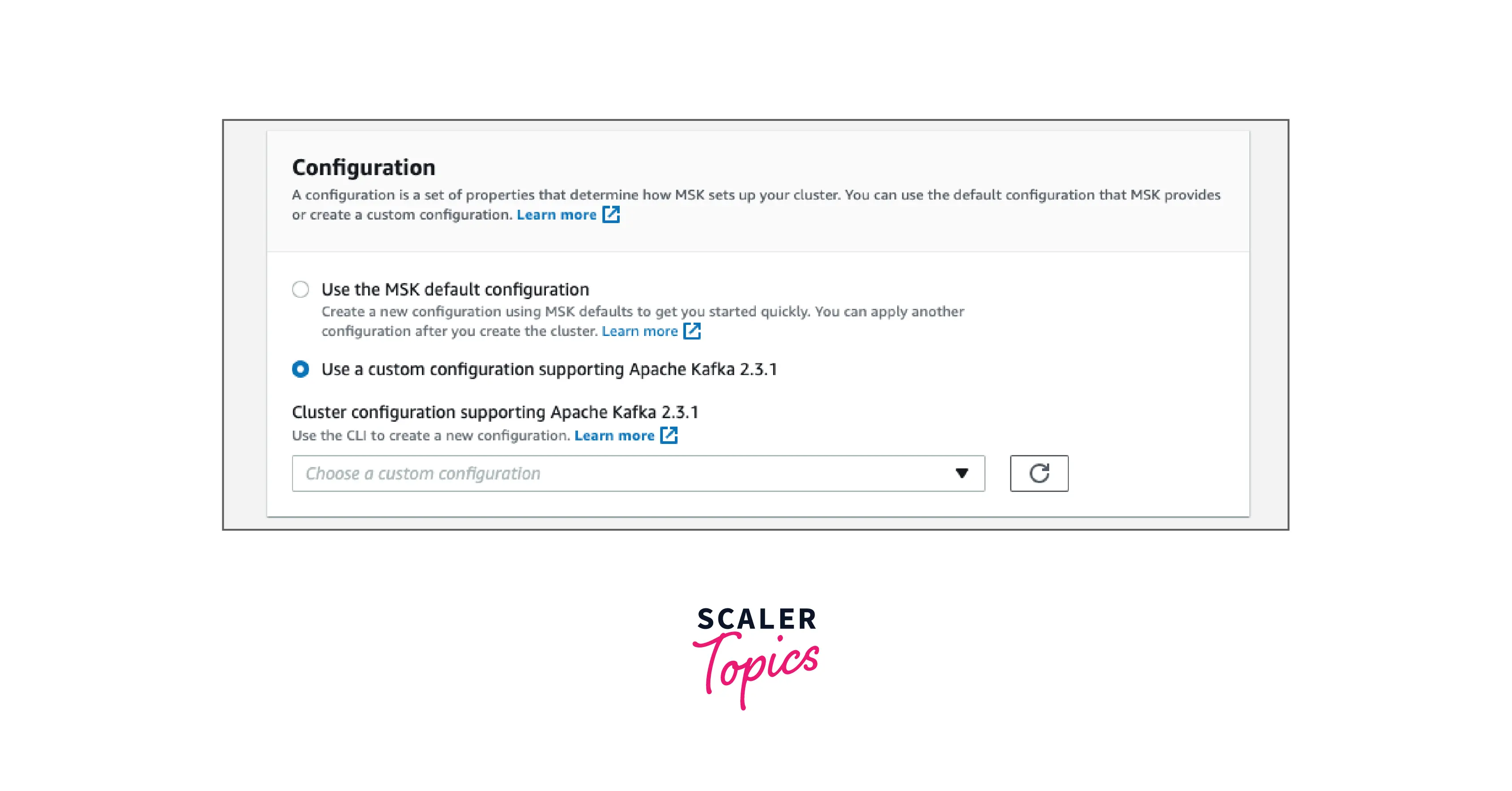
Configurable
While supporting dynamic and topic-level options, Amazon MSK deploys a best-practice cluster configuration for Apache Kafka by default and allows users to fine-tune more than 30 distinct cluster configurations.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Open Source
Applications and tools designed for Apache Kafka work with Amazon MSK out of the box, requiring no changes to the application code, even though Amazon MSK uses native versions of Apache Kafka.
AWS Kafka Use Cases
Activity Tracking
Activity tracking was Kafka's original use case. LinkedIn had to redesign its user activity tracking pipeline as a collection of publish-subscribe feeds that are updated in real-time. This was done using AWS Kafka. Activity tracking is often very high volume, as each user page view generates many activity messages (events). This includes User clicks, Registrations, Likes, Time spent on certain pages, Orders, and Environmental changes.
These occurrences may be published under specific Kafka-related subjects. Each feed can be loaded into a data lake or warehouse for offline processing and reporting, among a variety of other use cases.
Real-time Data Processing
Data must be processed as soon as it becomes available for many systems. AWS Kafka transports data with extremely low latency from producers to consumers (5 milliseconds, for instance). This is beneficial for:
- Financial institutions, collect and process payments and transactions in real-time, to stop fraudulent activities as soon as they are discovered, or to update dashboards with current market values.
- Predictive maintenance (IoT), in which models constantly analyze streams of metrics from equipment in the field and trigger alarms immediately after detecting deviations that could indicate imminent failure.
- Mobile autonomous devices that must process data in real-time to move through a physical area.
- Logistics and supply chain companies to monitor and update tracking software, for instance, to continuously track cargo ships for estimations of the delivery of cargo in real time.
Messaging
Since AWS Kafka has superior throughput, built-in segmentation, replication, and fault-tolerance, as well as improved scaling characteristics, it works well as a replacement for conventional message brokers.
Operational Metrics/KPIs
AWS Kafka is often used for operational monitoring data. This involves aggregating statistics from distributed applications to produce centralized feeds of operational data.
Log Aggregation
AWS Kafka is a popular log aggregation tool. Log aggregation often entails gathering actual log files from servers and storing them in a centralized location (such as a file server or data lake). Kafka encapsulates the data as a stream of messages and filters out the file specifics. This makes it possible to process data with lower latency and to accommodate distributed data consumption and numerous data sources more efficiently. Kafka provides comparable speed to log-centric systems while providing substantially reduced end-to-end latency and higher durability assurance, thanks to replication.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Amazon MSK Pricing
You only pay for what you use with Amazon Managed Streaming for Apache Kafka (MSK). There are no upfront obligations or minimum fees. You are not charged for the Apache ZooKeeper nodes that Amazon MSK provides for you, for data transmission between brokers, or for data transfer between Apache ZooKeeper nodes and brokers within your clusters. The cost of Amazon MSK depends on the kind of resource you create.
The cost of using an Apache Kafka broker instance is billed hourly (at a resolution of one second), with different costs based on the size of the broker instance and the number of active brokers in your Amazon MSK clusters.
Additionally, you are charged for the storage space that you allocate to your cluster. The "GB-months" amount is determined by adding up the GB granted each hour and dividing it by the overall number of hours in the month. Additionally, you have the choice to separately provide additional storage throughput, which will be billed at a rate based on the MB/s you provision each month. This is calculated by adding up MB/s provisioned per hour per broker and dividing it by the total number of hours in the month, resulting in a “MB/s-months” value
How to Get Started with AWS Kafka?
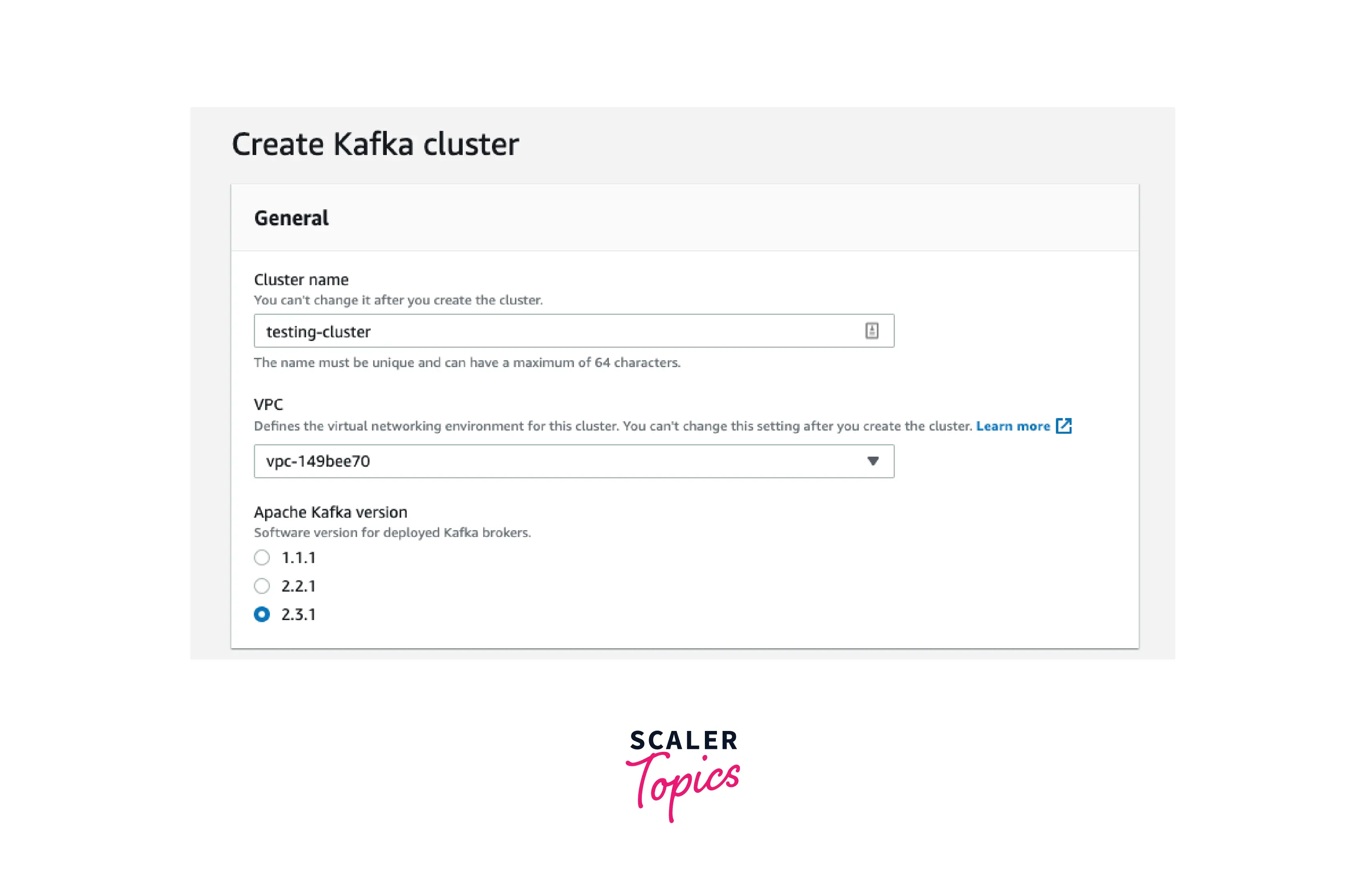
Step 1: Create an Amazon MSK Cluster
To create an Amazon MSK cluster using the AWS Management Console
- Open Amazon MSK via https://console.aws.amazon.com/msk/home?region=us-east-1#/home/ after logging into the AWS Management Console.
- Choose to Create cluster.
- Keep the Quick create option selected for Creation method. You can construct a cluster with default configurations using the Quick create option.
- For Cluster name, enter a descriptive name for your cluster. For example, MSKTutorialCluster.
- Select the Cluster type as Provisioned under General cluster attributes.
- Copy the values for the following settings from the table's All cluster settings column and save them, since you'll need them later in this tutorial:
- VPC
- Subnets
- Security groups connected to VPC
- Choose Create cluster.
- On the Cluster summary page, look up the Cluster status. The cluster is provisioned via Amazon MSK and the state switches from Creating to Active. You can establish a connection to the cluster while the state is Active.
Step 2: Create a client machine
To create a client machine
- Navigate to https://console.aws.amazon.com/ec2/to access the Amazon EC2 console.
- Choose Launch instances.
- Give your Client machine a name, like MSKTutorialClient.
- Keep the Amazon Machine Image (AMI) type set to Amazon Linux 2 AMI (HVM) - Kernel 5.10, SSD Volume Type.
- Choose the t2.micro instance type.
- Choose Create a new key pair from the list under Key pair (login). Select Download Key Pair after entering MSKKeyPair as the name of the key pair. You can also use an existing key pair.
- Choose Launch instance
- Choose View Instances. Next, select the security group linked to your new instance from the Security Groups column. The security group's ID should be copied and saved for later.
- Open the Amazon VPC console at https://console.aws.amazon.com/vpc/.
- In the navigation pane, choose Security Groups. Find the security group whose ID you saved in Step 1: Create an Amazon MSK cluster.
- In the Inbound Rules tab, choose Edit inbound rules.
- Choose Add rule.
- In the new rule, choose All traffic in the Type column. In the second field in the Source column, select the security group of your client machine. This is the group whose name you saved after you launched the client machine instance.
- Choose Save rules. Now the cluster's security group can accept traffic that comes from the client machine's security group.
Step 3: Create a topic
To create a topic on the client machine
- Open the Amazon EC2 console at https://console.aws.amazon.com/ec2/.
- Instances can be selected from the navigation pane. After that, check the box next to the name of the client computer you created in Step 2: Create a client machine.
- Select Actions, then select Connect. To connect to your client's machine, follow the directions in the console.
- Run the following command to install Java on the client's computer: sudo yum install java-1.8.0
- To download Apache Kafka, run the following command: wget https://archive.apache.org/dist/kafka/2.6.2/kafka_2.12-2.6.2.tgz
- Run the following command in the directory where you downloaded the TAR file in the previous step. tar -xzf kafka_2.12-2.6.2.tgz
- Go to the kafka_2.12-2.6.2 directory.
- Copy the plaintext authentication connection string.
- Run the following command, substituting the connection string you got in the previous step for BootstrapServerString.
Turn Learning into Career Growth
Step 4: Produce and Consume Data
To produce and consume messages
- Create a text file called client.properties and place the following information in it by going to the bin folder of the Apache Kafka installation on the client system: security.protocol=PLAINTEXT
- The following command should be run to launch a console producer. Substitute the plaintext connection string you obtained in Step 3 for BootstrapServerString.
- Enter any message that you want, and press Enter.
- Replace BootstrapServerString in the next command with the plaintext connection string you already saved. Then, using your second connection to the client machine, provide the following command to create a console consumer.
You start seeing the messages you entered earlier when you used the console producer command.
- Enter more messages in the producer window, and watch them appear in the consumer window.
Step 5: Delete the AWS Resources Created
To delete the resources using the AWS Management Console
- Navigate to https://console.aws.amazon.com/msk to access the Amazon MSK console.
- Your cluster's name should be selected. Take MSKTutorialCluster, for instance.
- After selecting Actions, select Delete.
- Navigate to https://console.aws.amazon.com/ec2/ to access the Amazon EC2 console.
- Select, for instance, MSKTutorialClient, the instance you generated for your client machine.
- Choose Instance state, then choose Terminate instance. Instance State allows you to leverage the state of your application from outside your application.
Best Practices for Running Apache Kafka on AWS
Deployment Considerations and Patterns
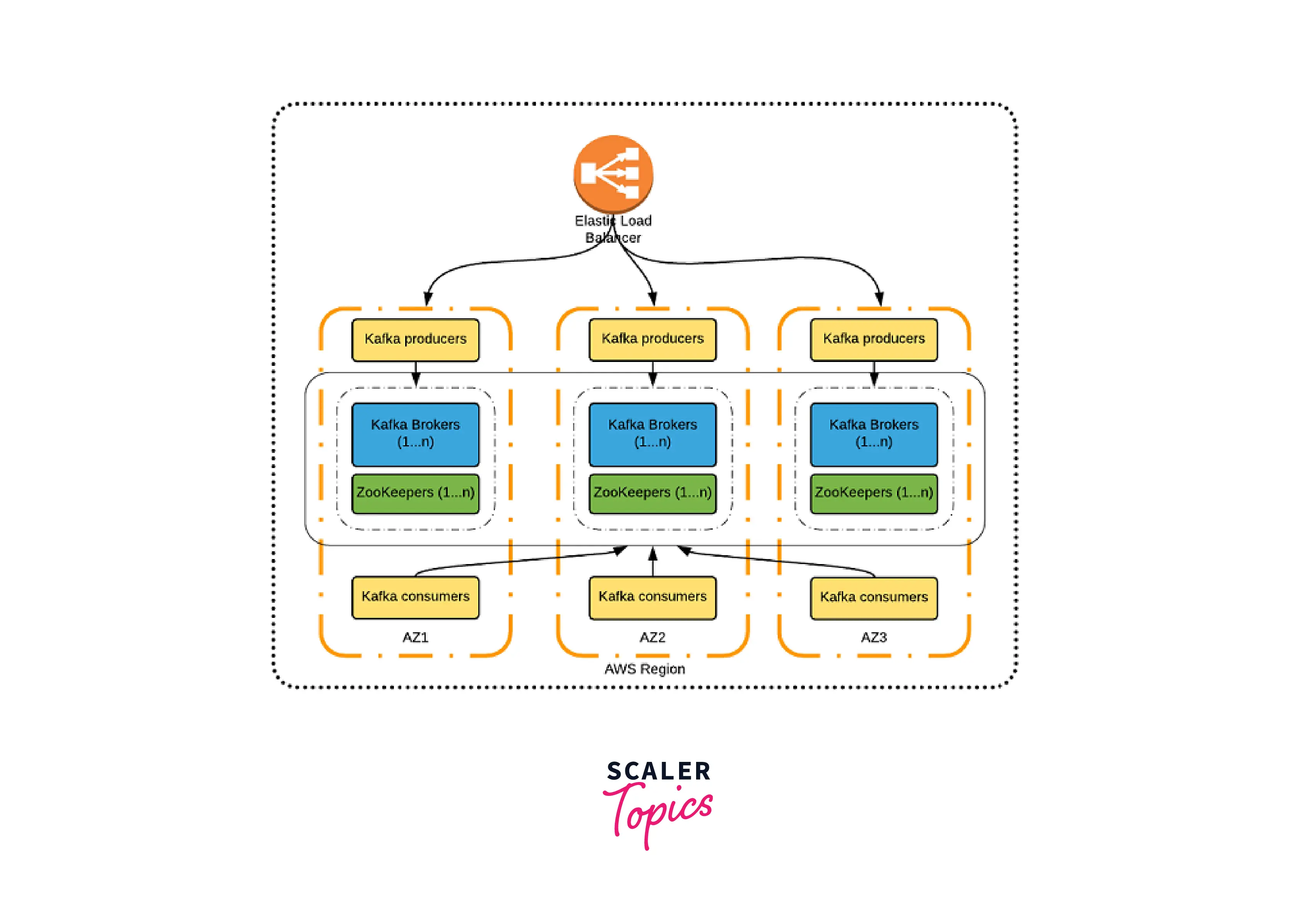
Single AWS Region, Three Availability Zones, All Active
Three Availability Zones (AZs) are used in a single AWS Region in one typical deployment strategy (all active). As demonstrated in the accompanying picture, one Kafka cluster, Apache ZooKeeper, and Kafka producer and consumer instances are all deployed in each AZ.
The benefits of this approach are:
- Highly available
- Can sustain the failure of two AZs
- No message loss during failover
- Simple deployment
Storage Options
In Amazon EC2, there are two storage choices for storing files:
- Ephemeral storage (instance store)
- Amazon Elastic Block Store (Amazon EBS)
- Ephemeral storage is local to the Amazon EC2 instance. By the instance type, it can deliver high Input/Output Operations Per Second(IOPS). Amazon EBS volumes, on the other hand, provide greater resilience and allow you to customize IOPS based on your storage requirements.
Instance Types
The kind of storage your streaming applications on a Kafka cluster require will typically influence the choice of instance types. The best options are h1, i3, and d2 instances if your application needs ephemeral storage.
AWS offers a more recent r4 instance if you require EBS storage. R4's instance is better than R3's in the following ways:
- It has a faster processor.
- EBS is optimized by design.
- Elastic Network Adapter (ENA)-based networking with up to 10 Gbps on smaller sizes is a feature of this system.
- Compared to R3, it is 20% less expensive.
Networking
An intricate part of a distributed system like Kafka is the network. Nodes can connect simply, thanks to a quick and dependable network. The amount of traffic that Kafka can handle at its maximum depends on the network throughput. Cluster sizing is frequently determined by network speed along with disc storage.
Upgrades
Although backward compatibility has historically not been supported by Kafka, it is improving. You should maintain your producer and consumer clients on a version that is equivalent to or lower than the version you are upgrading from when performing a Kafka upgrade. Three upgrading strategies are available, and they are explained below.
- Rolling or in-place upgrade: One Kafka broker should be upgraded at a time in a rolling or in-place upgrade scenario. Take into account the suggestions for doing rolling restarts to minimize end-user downtime.
- Downtime upgrade: Take the entire cluster offline, update each Kafka broker, and then restart the cluster if you can afford the downtime.
- Blue/green upgrade: It is strongly advised to use the blue/green upgrade scenario if you can afford to build a second Kafka cluster and upgrade it.
Performance Tuning
Kafka's performance can be adjusted in a variety of ways. The following are some performance tweaking best practices:
- If throughput is less than network capacity, try the following:
- Add more threads
- Increase batch size
- Add more producer instances
- Add more partitions
- For cross-AZ data transfer, tune your socket and OS TCP buffer settings.
Security
Similar to the majority of distributed systems, Kafka offers the means for data to be transferred between the many components with a comparatively high level of security. Depending on your configuration, security may entail a variety of services, including advanced access control list (ACL) configuration in brokers and ZooKeeper, Kerberos, Transport Layer Security (TLS) certificates, and encryption.
- Encryption at rest: Using Amazon EBS volumes with encryption turned on will enable encryption at rest for EC2 instances supported by EBS. Amazon EBS encrypts data using AWS Key Management Service (AWS KMS).
- Encryption in transit: For client and internal communications, Kafka makes use of TLS.
- Authentication: Clients' (producers' and consumers') connections to brokers from other brokers and tools are authenticated using either Secure Sockets Layer (SSL) or Simple Authentication and Security Layer (SASL). In Kafka, Kerberos authentication is supported.
- Authorization: Kafka supports connection with external authorization providers and offers pluggable authorization.
Backup and Restore
Your backup and restoration approach is determined by the kind of storage that is used in your deployment.
Setting up a second cluster and using MirrorMaker to replicate messages is the best option to back up a Kafka cluster that uses instance storage. Maintaining a replica of an existing Kafka cluster is achievable, thanks to the mirroring capability of Kafka.
Benefits of AWS Kafka
- Highly Scalable: There are two types of scaling: broker scaling, which involves changing the number of brokers in the cluster as storage needs vary, and storage scaling, which involves adjusting the amount of storage provisioned per broker.
- Fully Compatible: Apache Kafka is operated and managed for you by Amazon MSK. Because of this, moving and running your current Apache Kafka applications on AWS without making any modifications to the application code is simple. By utilizing Amazon MSK, you may keep using well-known, specialized, and community-built products like MirrorMaker while maintaining open-source compatibility.
- Highly Secure: For your Apache Kafka clusters, Amazon MSK offers several levels of security, including VPC network segregation, AWS IAM for control-plane API authorization, encryption at rest, and TLS encryption in transit.
- Highly Available: Automatic recovery is provided by keeping an eye on the clusters' health and swapping out sick brokers without pausing the applications. You won't need to start, stop, or directly access the Apache ZooKeeper nodes since Amazon MSK manages their availability. Amazon MSK releases software patches as required to keep the cluster current and operating properly. For high availability, Amazon MSK additionally leverages multi-Availability Zone replication.
- Fully Managed: Amazon MSK is responsible for the provisioning, setting up, and upkeep of Apache Kafka clusters and Apache ZooKeeper nodes. Key Apache Kafka performance indicators could also be displayed in the specific AWS web console. Because Amazon MSK enables users to concentrate on the development of their streaming applications, there is no need to stress about the operational burden of managing your Apache Kafka setup.
When NOT to Choose Amazon MSK Serverless for Apache Kafka?
Better Alternatives for Complete Platform for Streaming Data
A modern data flow requires a simple, reliable, and governed way to integrate and process data. Leveraging Kafka’s ecosystem like Kafka Connect and Kafka Streams enables mission-critical end-to-end latency and SLAs in a cost-efficient infrastructure. Development, operations, and monitoring are much harder and more costly if you glue together several services to build a real-time data hub.
If you use Amazon MSK Serverless, it is the data ingestion component in your enterprise architecture. There are no fully managed components other than Kafka and no native integrations to other 1st party clouds AWS services like S3 or Redshift, and 3rd parties cloud services like Snowflake, Databricks, or MongoDB. You must combine Amazon MSK Serverless with several other AWS services for event processing and storage. Additionally, connectivity needs to be implemented and operated by your project team using Kafka Connect connectors, another 1st or 3rd party ETL tools, or custom glue code).
Time Bound Retention Period
The storage capability of Kafka is a key differentiator against message queues like IBM MQ, Rabbit MQ, or AWS SQS. Retention time is an important feature to set the right storage option per Kafka topic.
Amazon MSK Serverless has a limited retention time of 24 hours. This is good enough for many data ingestion use cases but not for building a real-time data mesh across business units or even across organizations. Another tough requirement of Amazon MSK Serverless is the limitation of 120 partitions.
Conclusion
- Amazon MSK allows you to run applications that utilize Apache Kafka within AWS. Apache Kafka is a persistent communications system with a publisher/subscriber-based stream processing platform.
- Amazon MSK is a fully managed service and is highly secure.
- This article also went through many use cases of Amazon Kafka. It described how it is helpful in Activity tracking and Real-time data processing.
- This article also explained the pricing of the Amazon MSK. With Amazon Managed Streaming for Apache Kafka (MSK), you pay only for what you use.
- There are certain drawbacks as well with Amazon MSK. Amazon MSK Serverless has a limited retention time of 24 hours.