AWS Textract
Overview
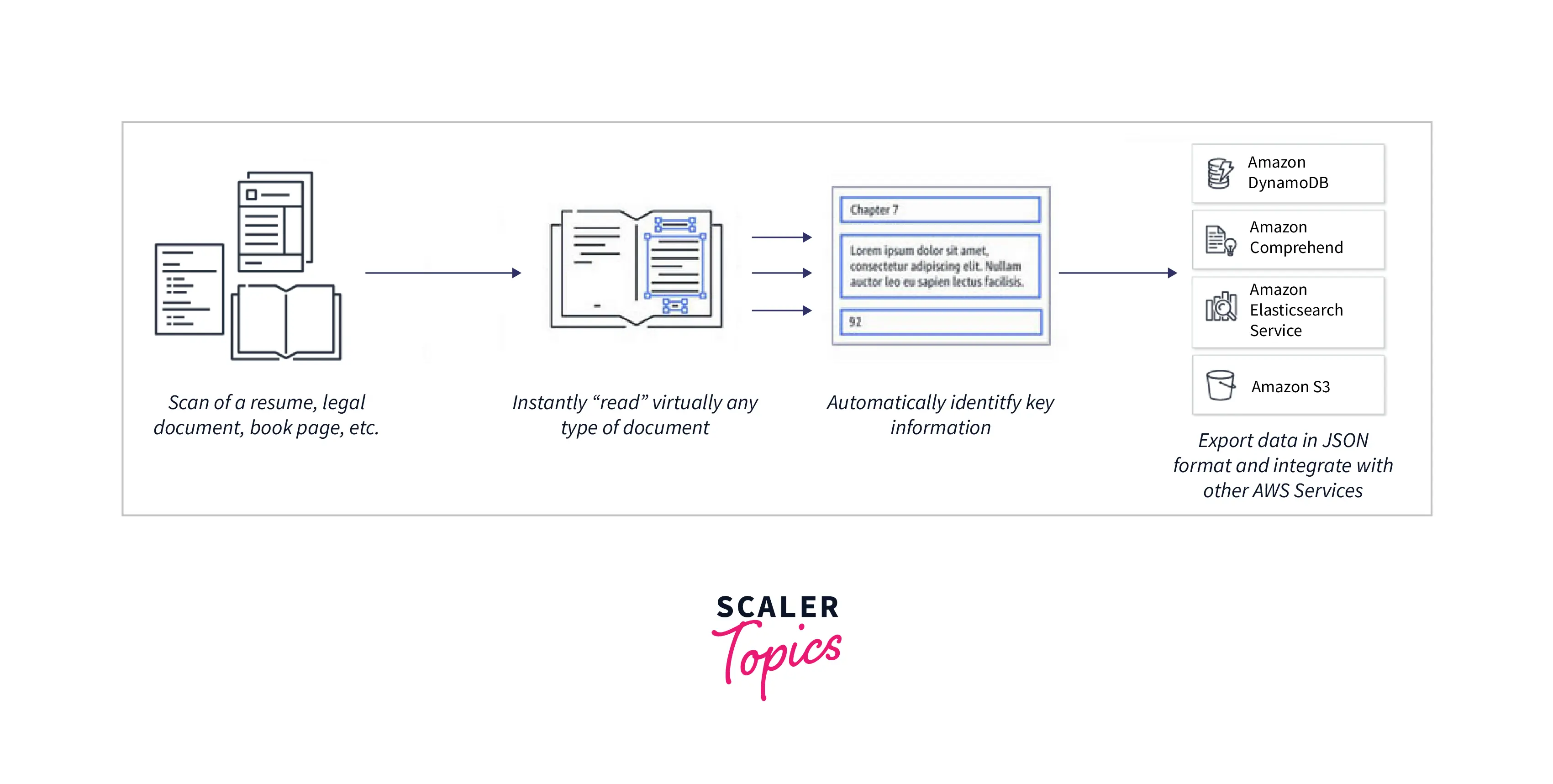
It can be an uphill task to perform manual text analysis and classification over a large number of documents, and it can eventually become overwhelming. AWS launched a service called AWS Textract in its machine learning service lineup to simplify the process of text extraction and analysis.
AWS Textract is a machine-learning tool for extracting and analyzing text from a variety of file formats. AWS Textract accepts files as input and outputs the text found in various formats for simple manual and automated analysis.
What is AWS Textract?
The machine learning-based document analysis service called AWS Textract allows users to automatically detect and extract text from a variety of file formats. From various file formats, Amazon Textract can extract printed data, handwritten data, tables, etc. The AWS console makes it simple to further visualize the extracted text. For the end user's convenience, all the extracted text is also displayed in a rectangular frame over the source data document. AWS Textract can be used with the AWS Management Console, AWS CLI, and Amazon Textract API. AWS Textract is a fully AWS-managed service. At the moment, PNG, JPEG, TIFF, and PDF formats are supported by Amazon Textract.

Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
How Does It Work?
AWS Textract Functions as Follows :
1. Text-only detection :
A feature to extract all the text from a document is offered by the Amazon Textract service using the Detect Document Text API. Both synchronous and asynchronous modes of operation can be used.
- Synchronous mode :
In single-page documents that are presented as images in the JPEG, PNG, PDF, and TIFF formats, Amazon Textract can find and interpret the text. The operations are synchronous, and they produce results almost instantly. - Asynchronous mode :
Multipage documents that are in the PDF or TIFF format can contain text that Amazon Textract can find and analyze. Processing multipage documents is an asynchronous process that requires asynchronous document processing.
For each operation, the information listed below is returned :
- The text lines and words that were found.
- The connections between the lines and words of the text that were detected.
- The page where the detected text is located.
- Location of the lines and words of the text on the document page.
2. Identifying and evaluating textual relationships :
Text, forms, tables, and query responses are the four categories of document extraction that Amazon Textract analysis operations return using the Analyze Document API. The form data is extracted in key-value pairs, while the raw text is extracted in the raw format. It is also possible to extract the tabular data and then store it in JSON, CSV, or text format.
3. Locating and analyzing text in receipts and invoices :
AWS Textract makes it simple to extract pertinent information from invoices and receipts, which is otherwise very challenging to do manually. AWS Textract's AnalyzeExpense method, for instance, makes it simple to extract and use the invoice number from thousands of invoices. VENDOR_NAME, TOTAL, RECEIVER_ADDRESS, INVOICE_RECEIPT_ID, PAYMENT_TERMS, DUE_DATE, ITEM_NAME, PRICE, QUANTITY, SUBTOTAL, TAX, TAX_PAYER_ID are few of the fields that can be easily extracted using the AnalyzeExpense API.
4. Identifying and analyzing text in governmental identification documents :
Using the AnalyzeID API, AWS Textract can quickly extract data from official identity documents like passports, driver's licenses, and identity cards. Key-value pairs and implied fields—fields without keys—are the formats in which the data is returned.
Features of AWS Textract
- Easy Data Extraction :
Using Amazon Textract, text and tabular data can be extracted from a variety of documents. These aren't customized APIs, but they do gain knowledge from the enormous amounts of data generated every day, making it much simpler to extract both structured and unstructured data from your document. - Key-Value data format support :
Although it has become a common challenge in document processing, Amazon Textract can easily handle the extraction of key-value pairs. Textract can be used to build key-value pair extraction pipelines that automate document processing. - Table extraction :
The structure of the data contained in tables is preserved by Amazon Textract during extraction. It is useful for documents that contain a lot of structured data and the data is present in a tabular format. - Confidence scores :
Every word, phrase, or table that Amazon Textract finds when it extracts information from documents is given a confidence score, allowing the user to decide on the appropriate course of action.
Turn Learning into Career Growth
Getting Started with AWS Textract
Follow these Steps to Use AWS Textract from the AWS Console :
-
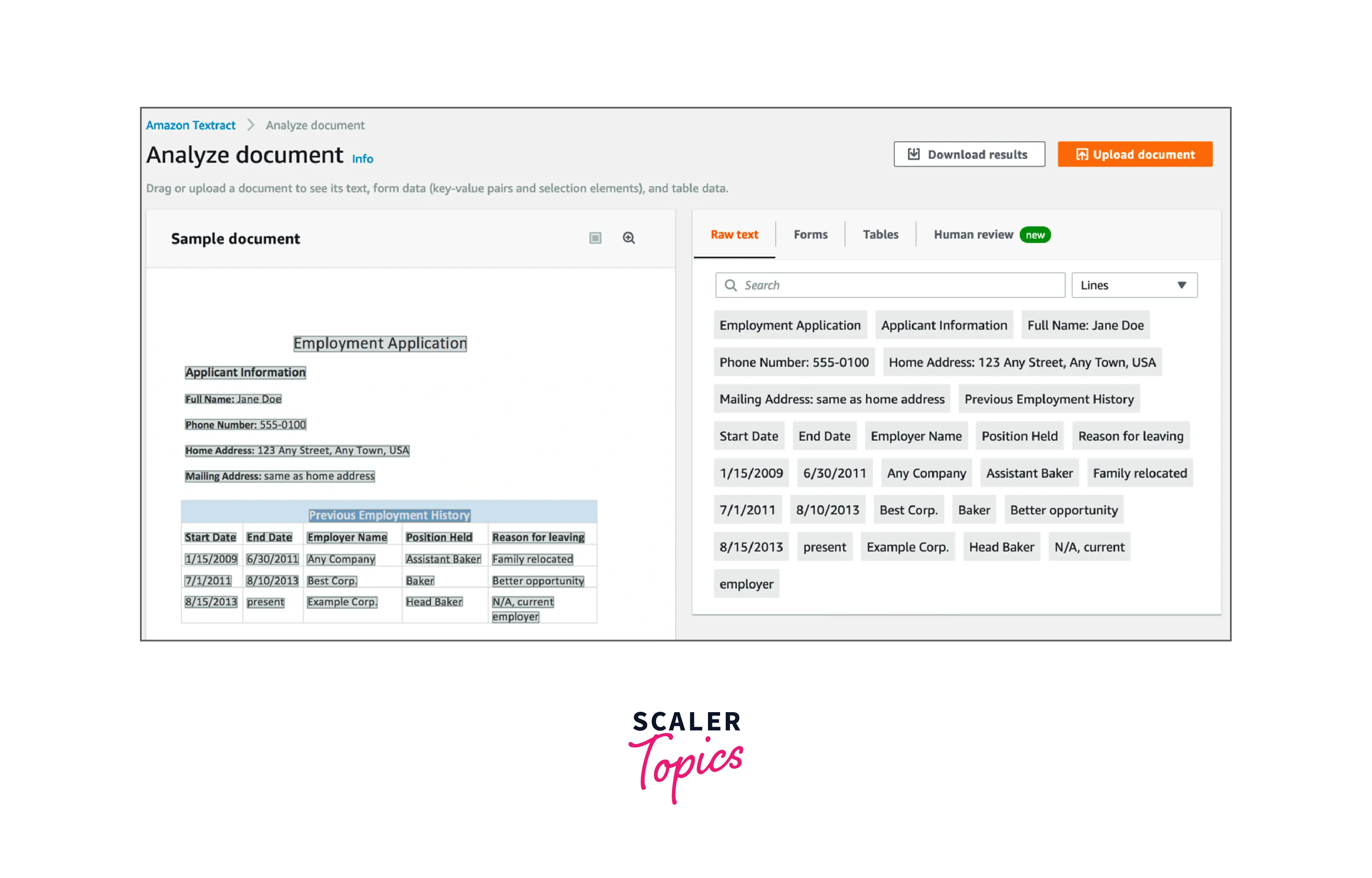
Search for AWS Textract in the AWS console to access the AWS Textract console.
-
An example document for analysis and preview is displayed by AWS Textract.
-
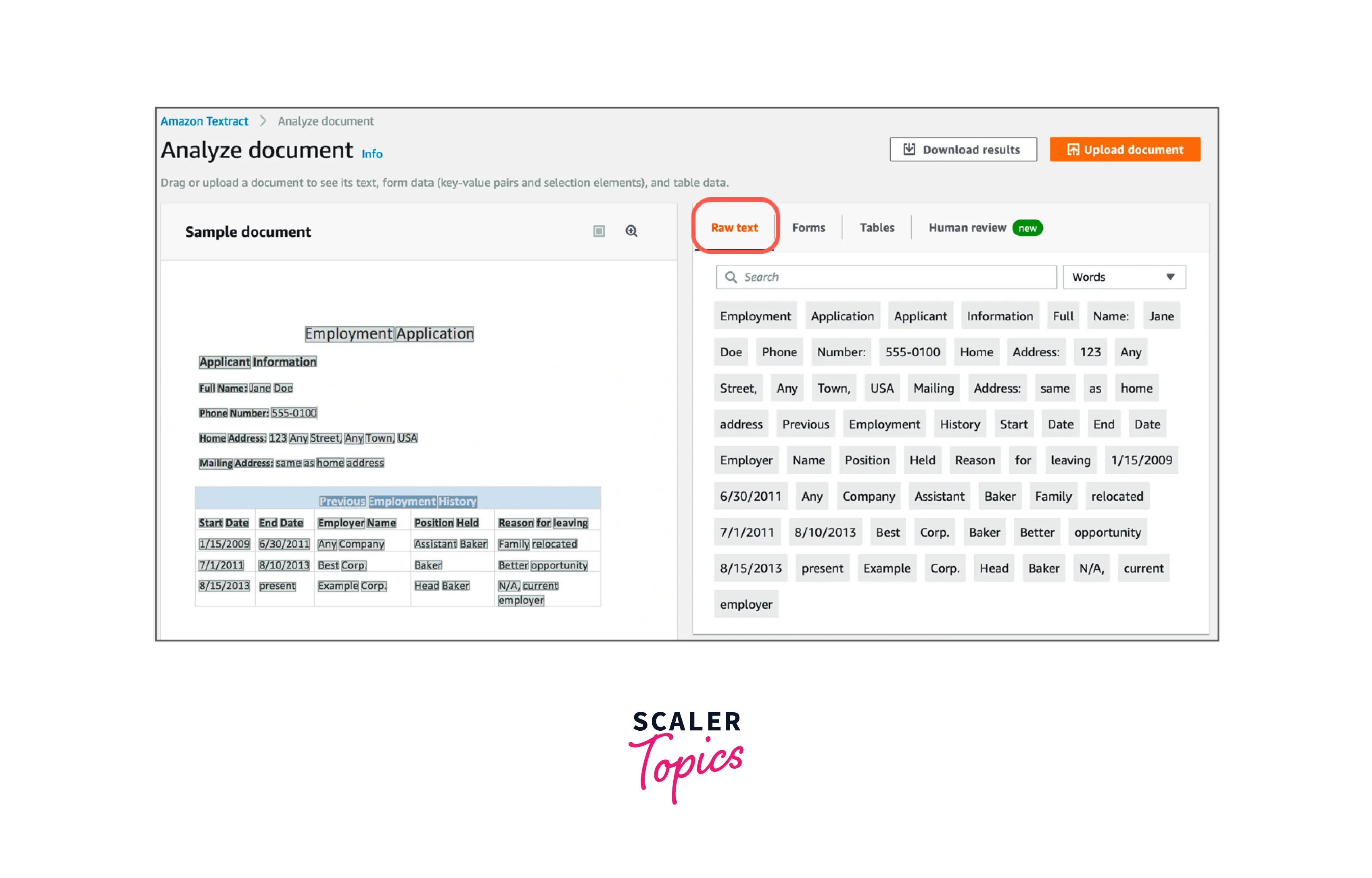
To upload a unique document, select Upload document from the Analyze document screen.
-
To view the document's extracted text after uploading it, select Raw text on the right side of the screen.
-
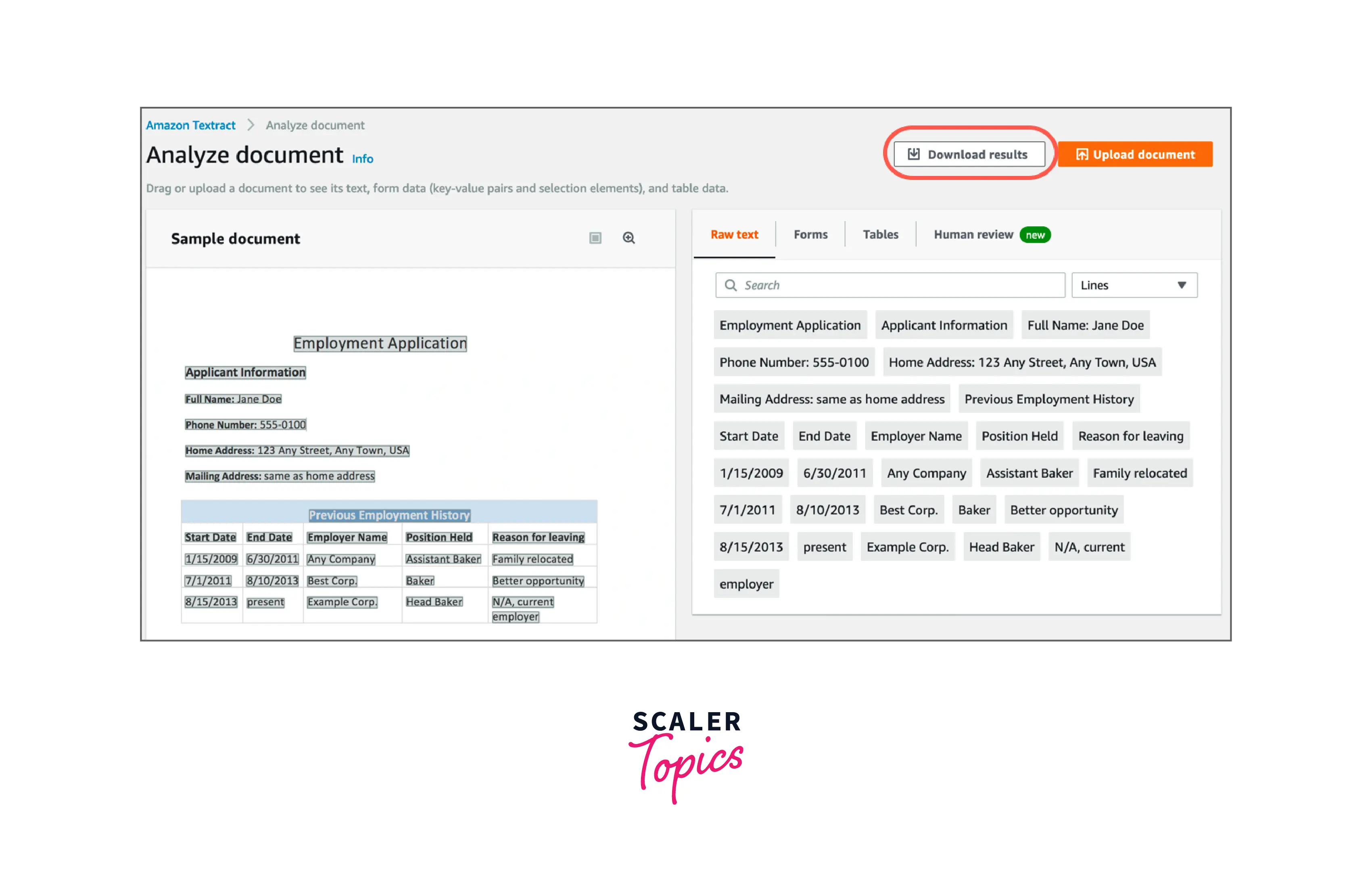
Similarly form data can be extracted, and tabular data can be extracted using the menus for forms and tables.
-
Click Download results to download the results.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Use Cases of AWS Textract
Amazon Textract's most typical use cases include :
- Building intelligent search indexes :
You can build collection of text that has been found in image and PDF files using Amazon Textract that can be used for search indexes. - Development of automated document processing workflows :
Using AWS Textract, document processing tasks can be easily automated by integrating the document data with the other custom application for data processing. - Text extraction for Natural Language Processing (NLP) :
The extracted data can be utilized as an input for the NLP applications either in a raw or structured format. - Text extraction for the classification of documents :
Using the extracted text, multiple documents can be easily sorted and classified under different labels for custom processing.
AWS Textract Pricing
Amazon Textract charges a fee based on how many pages and images are processed. Pricing is determined by the kind of API that is utilized for text extraction in a specific AWS Region. Detect Document Text API, Analyze Document API, Analyze Expense API, and Analyze ID API are the APIs that AWS Textract provides.
The following AWS Textract APIs are accessible for free through the AWS Free Tier for a set number of pages each month.
- Detect Document Text API : 1,000 pages per month
- Analyze Document API : 100 pages per month when using the Forms or Tables feature. Additional 100 pages per month when using the Queries feature
- Analyze Expense API : 100 pages per month
- Analyze ID API : 100 pages per month
You can visit link to learn more about AWS Textract pricing details for various AWS Regions.
Benefits of Amazon Textract
- Integration of Textract with custom applications :
By making powerful and precise analysis with a straightforward API, Amazon Textract removes the complexity of building text detection capabilities into your applications. Any web, mobile, or connected device application can easily incorporate text detection, thanks to Amazon Textract Text APIs. - Scalable solution :
Scalable document analysis is possible with Amazon Textract, which can speed up decision-making by allowing you to quickly analyze and extract data from millions of documents. - Cost-effectiveness :
With Amazon Textract, you only pay for the documents you examine. There are no upfront obligations or minimum fees.
Conclusion
- AWS Textract is a machine learning-based document analysis service. It can extract printed data, handwritten data, tables, etc. from various file formats like PNG, JPEG, TIFF, and PDF.
- For the end user's convenience, all the extracted text is also displayed in a rectangular frame.
- AWS Textract can extract data from documents in text, forms, tables, and query responses. It is also possible to extract the tabular data and then store it in JSON, CSV, or text format.
- The Amazon Textract service supports both synchronous and asynchronous modes of operation.
- Textract can be used to build key-value pair extraction pipelines that automate document processing.
- Each word, phrase, or table it extracts is given a confidence score, allowing the user to decide on the appropriate course of action.
- The cost of using Amazon Textract is determined by how many pages and images are processed. The type of API used for text extraction in a particular AWS Region also affects the pricing.
- The APIs that AWS Textract offers are Detect Document Text API, Analyze Document API, Analyze Expense API, and Analyze ID API.