Global Database ( Aurora ) in AWS
Overview
With the help of the Amazon Aurora Global Database, which enables a single Amazon Aurora database to span different AWS regions, globally dispersed applications may now be used. In addition to enabling quick local reads with minimal latency in each region and offering disaster recovery from region-wide failures, it duplicates your data without affecting database performance.
The monitoring of replication latency in the Aurora Global Database and leveraging the Aurora Global Database for disaster recovery will follow.
Introduction to Amazon Aurora Global Databases
You may deploy globally distributed apps utilizing a single Aurora database that spans many AWS Regions by using an Amazon Aurora global database. An Aurora global database is made up of one primary AWS Region in which your data is stored and up to five read-only secondary AWS Regions. You perform write operations on the principal DB cluster in the major AWS Region. Aurora replicates data to alternative AWS Regions utilizing specialized infrastructure, with an average latency of less than a second. Critical workloads having a worldwide reach, such as banking, tourism, or gaming applications, may need to be tolerant of a regional outage due to their tight availability requirements. Performance, availability, affordability, and data integrity have traditionally been traded off in a challenging way. The dedicated infrastructure used by Global Database's storage-based replication, which typically has a latency of less than 1 second, makes your database completely accessible to support application demands. One of the secondary Regions can be upgraded to read and write capabilities in less than a minute in the unlikely case of a Regional deterioration or outage. Up to five read-only secondary AWS Regions can be found in an Aurora global database in addition to the primary AWS Region where your data is stored. The main DB cluster in the main AWS Region is the target of your write operations. Using specialized infrastructure and an average latency of less than a second, Aurora replicates data to the secondary AWS Regions.
A sample Aurora global database that spans two AWS Regions is shown in the following diagram.
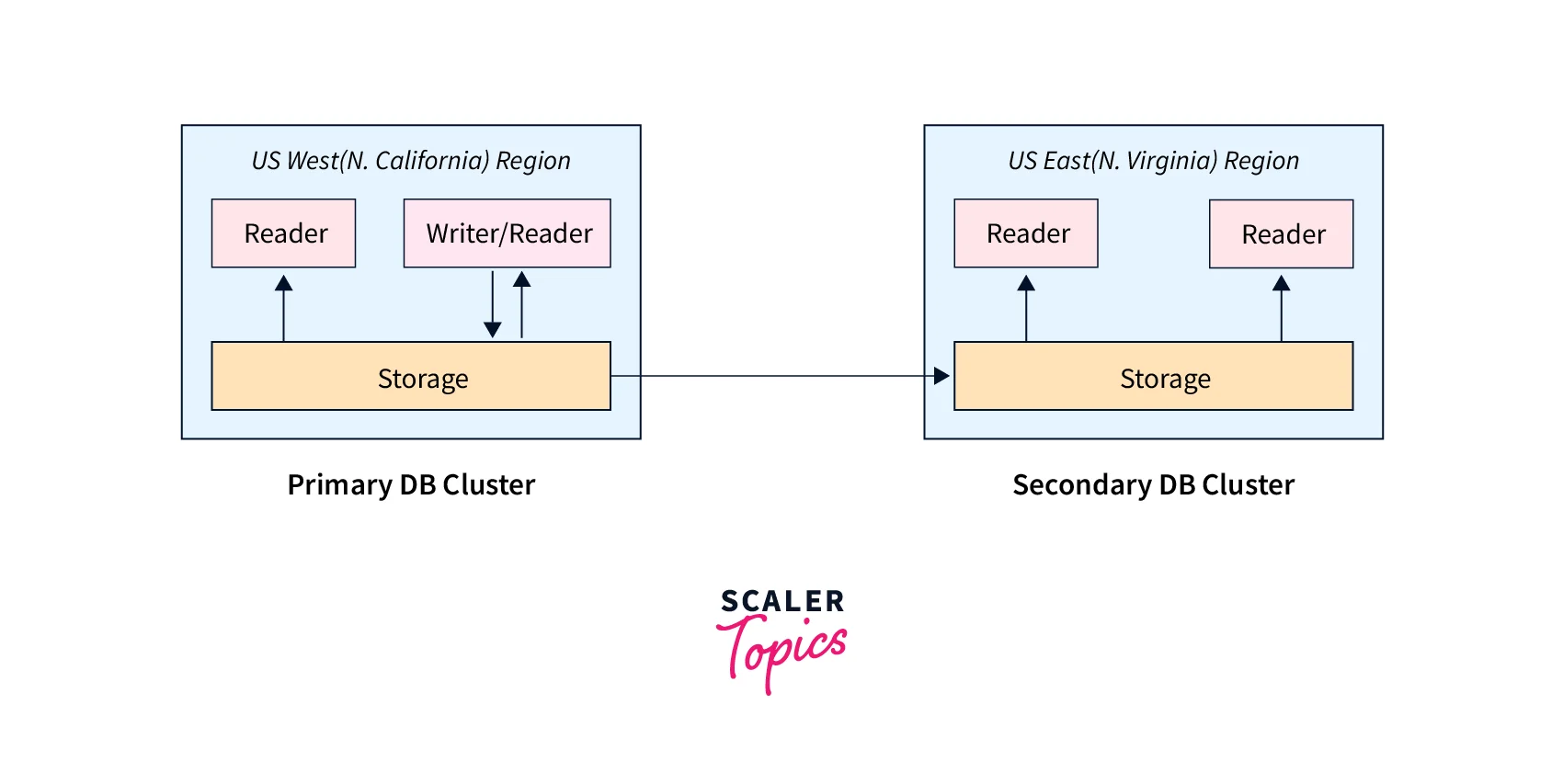
One or more Aurora Replicas (read-only Aurora DB instances) can be added to service read-only workloads, allowing you to independently scale up each secondary cluster.
Writing is only done on the primary cluster. The DB cluster endpoint of the primary DB cluster is where clients performing write operations connect. According to the diagram, the cluster storage volume, rather than the database engine, is used for replication by the Aurora global database. An overview of Aurora storage is where you can find out more.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Advantages of Amazon Aurora Global Databases
The benefits listed below may be obtained by using Aurora global databases:
- Local latency and global readings:- If your business has locations throughout the globe, you may use an Aurora global database to keep your primary information sources up to date in the primary AWS Region. The information may be obtained by offices in your other Regions with just local latency in those Regions.
- Secondary Aurora DB clusters that are scalable:- You may extend your secondary clusters by adding extra read-only instances (Aurora Replicas) to a separate AWS Region. Since the second cluster is read-only, it has a maximum capacity of 16 read-only Aurora Replica instances as opposed to the typical maximum of 15 for an Aurora cluster.
- Fast replication across primary and secondary Aurora DB clusters:- The primary DB cluster's primary DB cluster is not significantly affected in terms of performance by an Aurora global database's replication. The read-and-write workloads for applications are completely supported by the resources of the database instances.
- Recovery from Regional Outages:- In comparison to conventional replication solutions, the secondary clusters let you more quickly and with less data loss (lower RPO) making an Aurora global database accessible in a new primary AWS Region.
- Access to Subsecond Data from Anywhere:- By placing your apps adjacent to your users, Aurora Global Database enables you to grow database reads globally. Regardless of the quantity and location of secondary Regions, your applications can access data quickly thanks to typical cross-Region replication latencies of less than one second. By setting up to 16 database instances in each Region, which will all be kept continuously current, you may increase scalability even further. Performance is unaffected by expanding your database to more Regions. Database resources in the primary and secondary Regions are always fully accessible to meet application demands thanks to cross-Region replication, which employs specialized architecture in the Aurora storage layer.
Region and Version Availability
Different versions of each Aurora database engine and AWS Region have different levels of feature availability and support. A minimum of one secondary Aurora DB cluster in a separate AWS Region from the original Aurora DB cluster is required for an Aurora global database. Your Aurora global database can be connected to up to five additional DB clusters.
Reduce the number of Aurora Replicas permitted to the primary DB cluster by one for each secondary DB cluster that you add to your Aurora global database. For instance, your primary DB cluster can only contain 10 (rather than 15) Aurora Replicas if your Aurora global database includes 5 secondary Regions.
How many secondary DB clusters you can add depends on how many Aurora Replicas (reader instances) are in the original DB cluster. The sum of the primary DB cluster's reader instances and all other clusters combined cannot be more than fifteen. For instance, you cannot add a second secondary cluster to the global database if there are already 14 reader instances in the primary DB cluster and 1 secondary cluster.
It is advised that you use the same version of the DB engine for the primary and secondary clusters when building a secondary cluster. Upgrade the main if necessary to the same version as the secondary. Aurora global databases cannot fail over from a main to a secondary DB cluster if the primary and secondary have different DB engine versions—whether major, minor, or patch versions.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Console
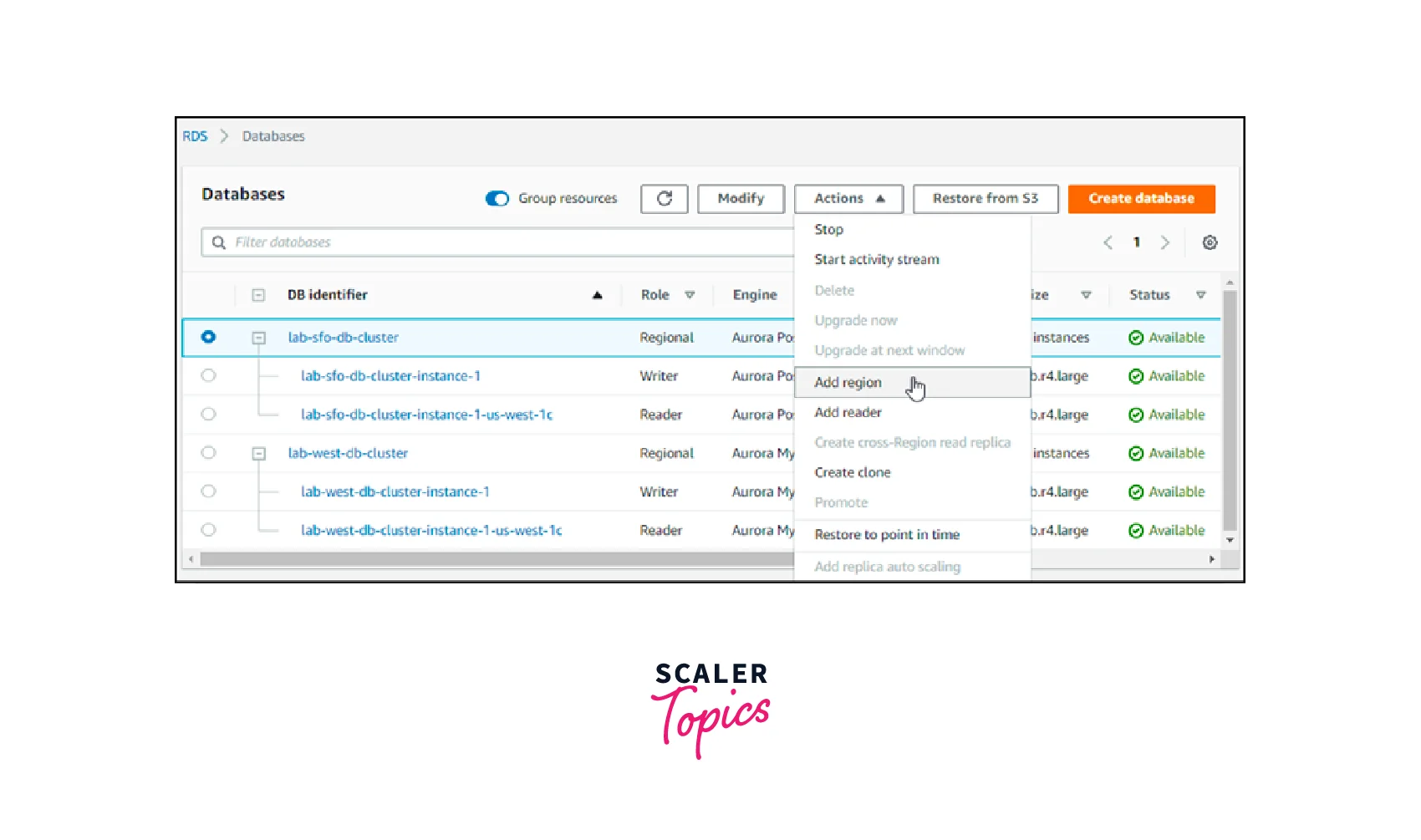
To add an AWS Region to an Aurora global database:
- At https://console.aws.amazon.com/rds/, log in to the AWS Management Interface and launch the Amazon RDS console.
- Go to the AWS Management Console's navigation pane and choose Databases.
- The Aurora global database that requires a second Aurora DB cluster should be chosen. The availability of the main Aurora DB cluster should be checked.
- Opt for Add region under Actions.
- Make your selection from the secondary AWS Region on the Add a Region page. For the identical Aurora global database, you cannot select an AWS Region that already hosts a secondary Aurora DB cluster. Aside from that, it can't be in the same Region as the main Aurora DB cluster.
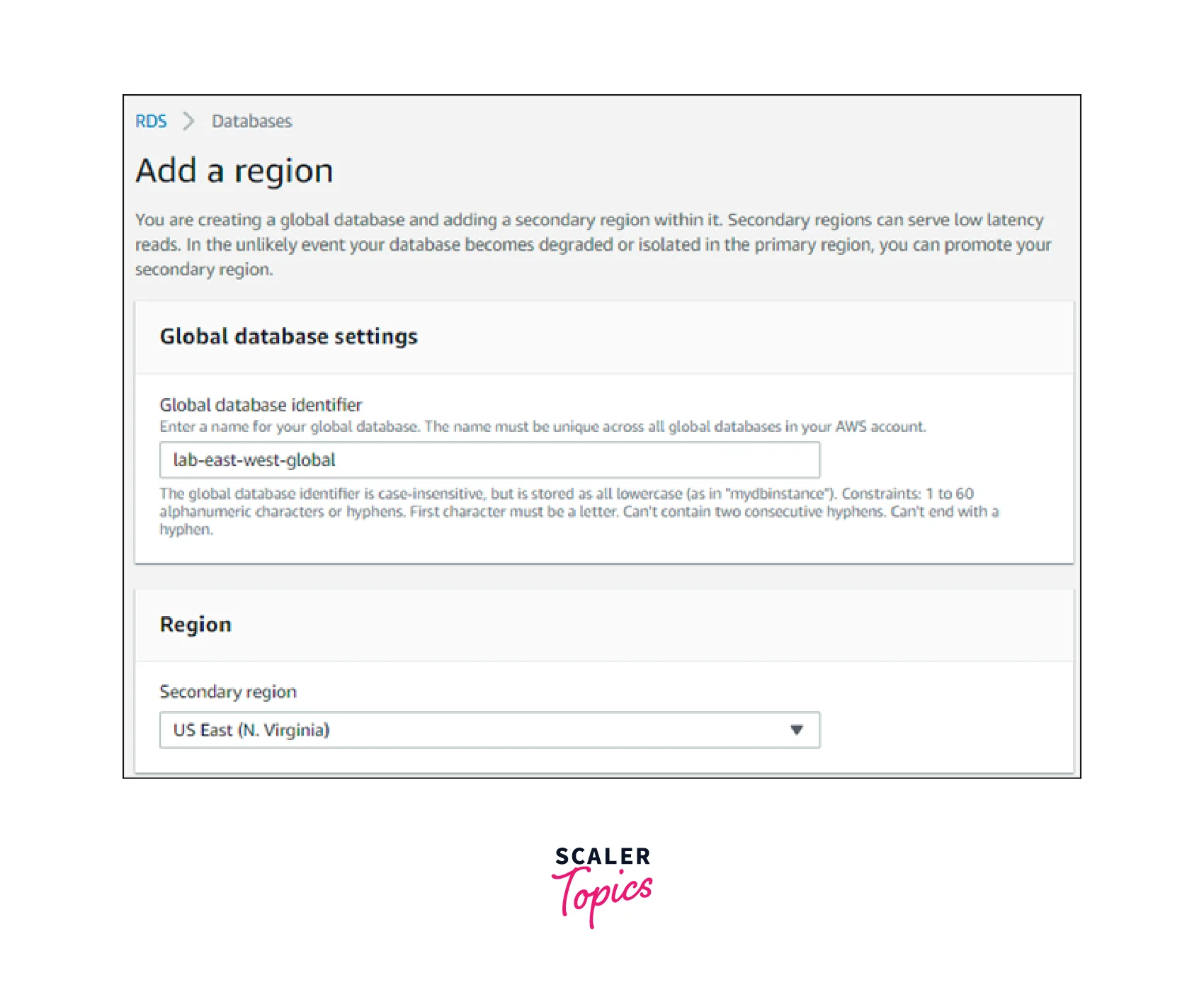
- The secondary Aurora cluster's remaining fields in the new AWS Region must be filled up. The setup choices for each Aurora DB cluster instance are the same, except for the following option, which is only available for Aurora global databases that are powered by MySQL: Enable read replica to write forwarding — This optional feature enables the secondary DB clusters of your Aurora global database to forward write operations to the primary cluster.
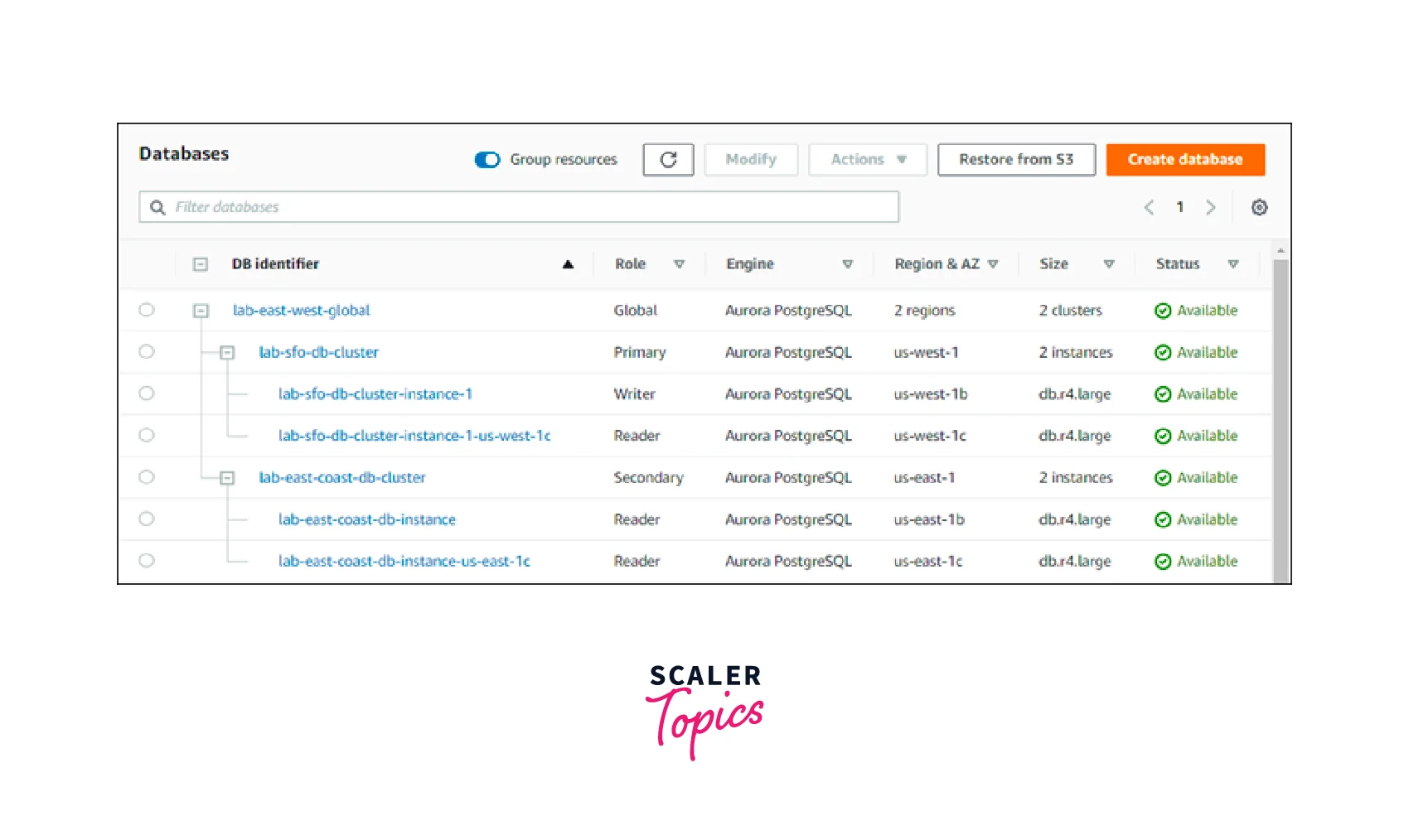
- Add region. In the AWS Management Console's list of Databases, as seen in the picture, you can find the Region once you've finished adding it to your Aurora global database.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Limitations of Amazon Aurora Global Databases
Currently, Aurora global databases have the following restrictions:
- Only certain Aurora MySQL and Aurora PostgreSQL versions of global databases for Aurora are available in some AWS Regions. See Aurora global databases for further details.
- The available Aurora DB instance classes, the maximum number of AWS Regions, and other configuration options for Aurora global databases must all be met.
- One of the following Aurora database engines is needed for managed planned failover for Aurora global databases:
- Versions 3.01.0 and higher of Aurora MySQL include support for MySQL 8.0
- Versions 2.09.1 and above of Aurora MySQL are compatible with MySQL 5.7
- Versions 1.23.1 and above of Aurora MySQL, which is compatible with MySQL 5.6
- Versions 13.3 and later, 12.4 and later, 11.9 and later, and 10.14 and later of Aurora PostgreSQL.
- When the primary and secondary DB clusters have different DB engine versions—be the major, minor, or patch versions—Aurora global databases cannot fail over from a primary to a secondary DB cluster.
- The following Aurora functionalities are not presently supported by global databases for Aurora:
- Aurora multi-master clusters
- Aurora Serverless v1
- Backtracking in Aurora
- Amazon RDS Proxy
- Aurora global databases do not automatically perform minor version updates on the Aurora MySQL and Aurora PostgreSQL clusters that make up the database. For a DB instance that is part of a global database cluster, you can specify this argument, but it has no impact.
- Aurora global databases do not presently support Aurora Auto Scaling for secondary DB clusters.
- Only Aurora global databases running the following Aurora MySQL and Aurora PostgreSQL versions can initiate database activity streams.
Getting Started With Amazon Aurora Global Databases
Choose which Aurora DB engine and which AWS Regions you wish to utilize before you begin using Aurora global databases. In some AWS Regions, only particular versions of the Aurora MySQL and Aurora PostgreSQL database engines are compatible with Aurora global databases.
One of the following methods can be used to create an Aurora global database:
- Create a new Amazon Aurora global database by following the instructions in Creating an Amazon Aurora global database. This includes creating new Aurora DB clusters and Aurora DB instances. You add the secondary AWS Region by following the instructions in Adding an AWS Region to an Amazon Aurora Global Database after creating the primary Aurora DB cluster.
- Use a current Aurora DB cluster that supports the Aurora global database feature and add an AWS Region to it. This is only possible if your current Aurora DB cluster makes use of a DB engine version that supports the Aurora global mode or is globally compatible. This mode may be explicit for some versions of the DB engine, but not for others.
After selecting your Aurora DB cluster, you can click Add region for Action on the AWS Management Console. Using that Aurora DB cluster for your Aurora global cluster is an option, if you're able to.
Managing an Amazon Aurora Global Database
The majority of administration tasks are carried out on the various clusters that make up an Aurora global database, with the controlled planned failover procedure being the sole exception. The primary cluster and subsidiary clusters are grouped under the linked global database when you select Group-related resources on the Databases page in the console. Use the Configuration tab of a global database to determine the Amazon Web Services Regions where its DB clusters are located, as well as its identification, Aurora DB engine, and version.
The controlled planned failover method is only accessible for Aurora global database objects, not for a single Aurora DB cluster.
Modifying an Amazon Aurora Global Database
You can view the primary cluster and secondary clusters for each of your Aurora global databases on the Databases page of the Amazon Web Services Management Console. Each configuration option is specific to the Aurora global database. About its primary and secondary clusters, it has Amazon Web Services Regions connected to them, as seen in the screenshot that follows.
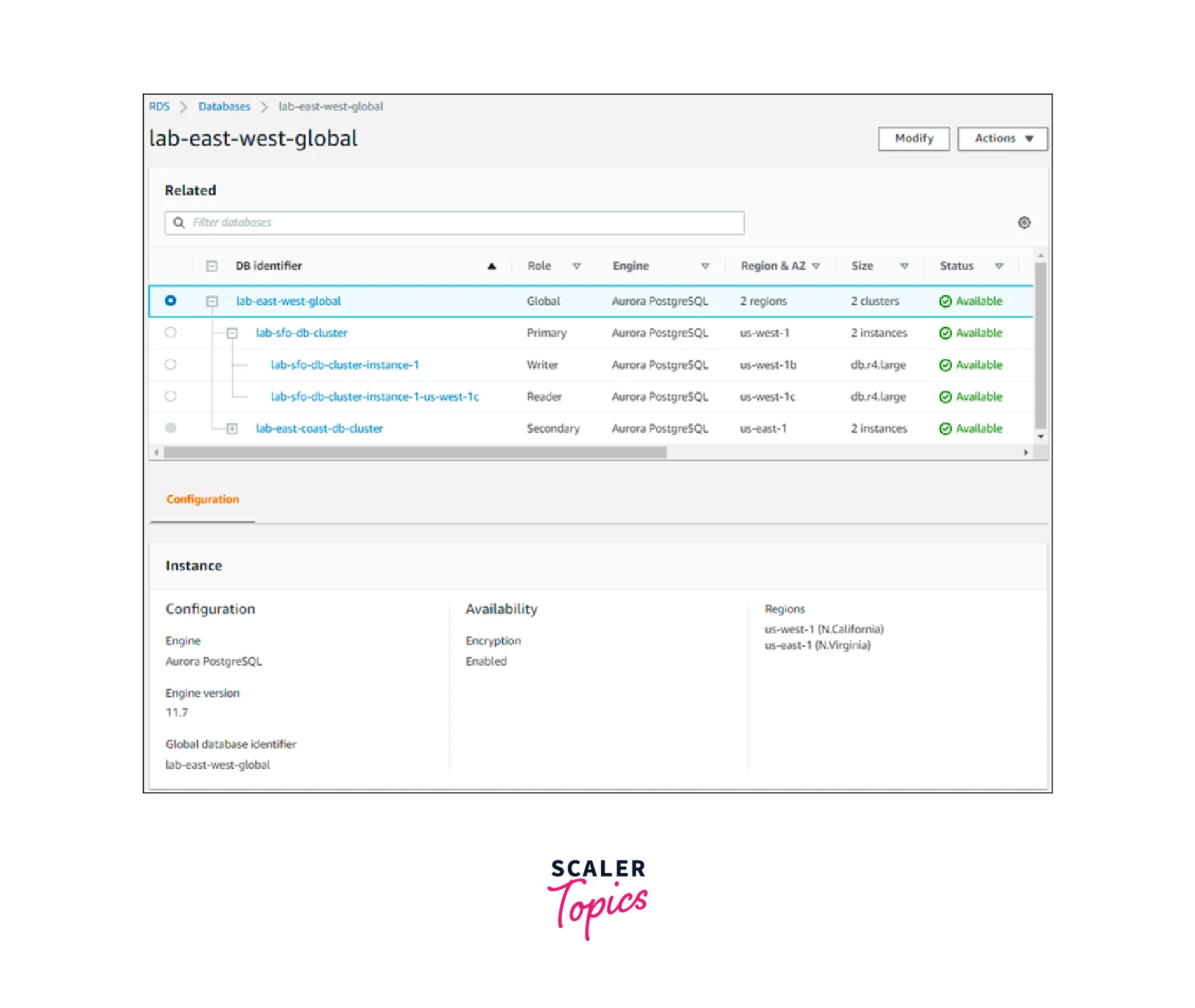
You have the option to undo changes you make to the Aurora global database, as seen in the screenshot below.
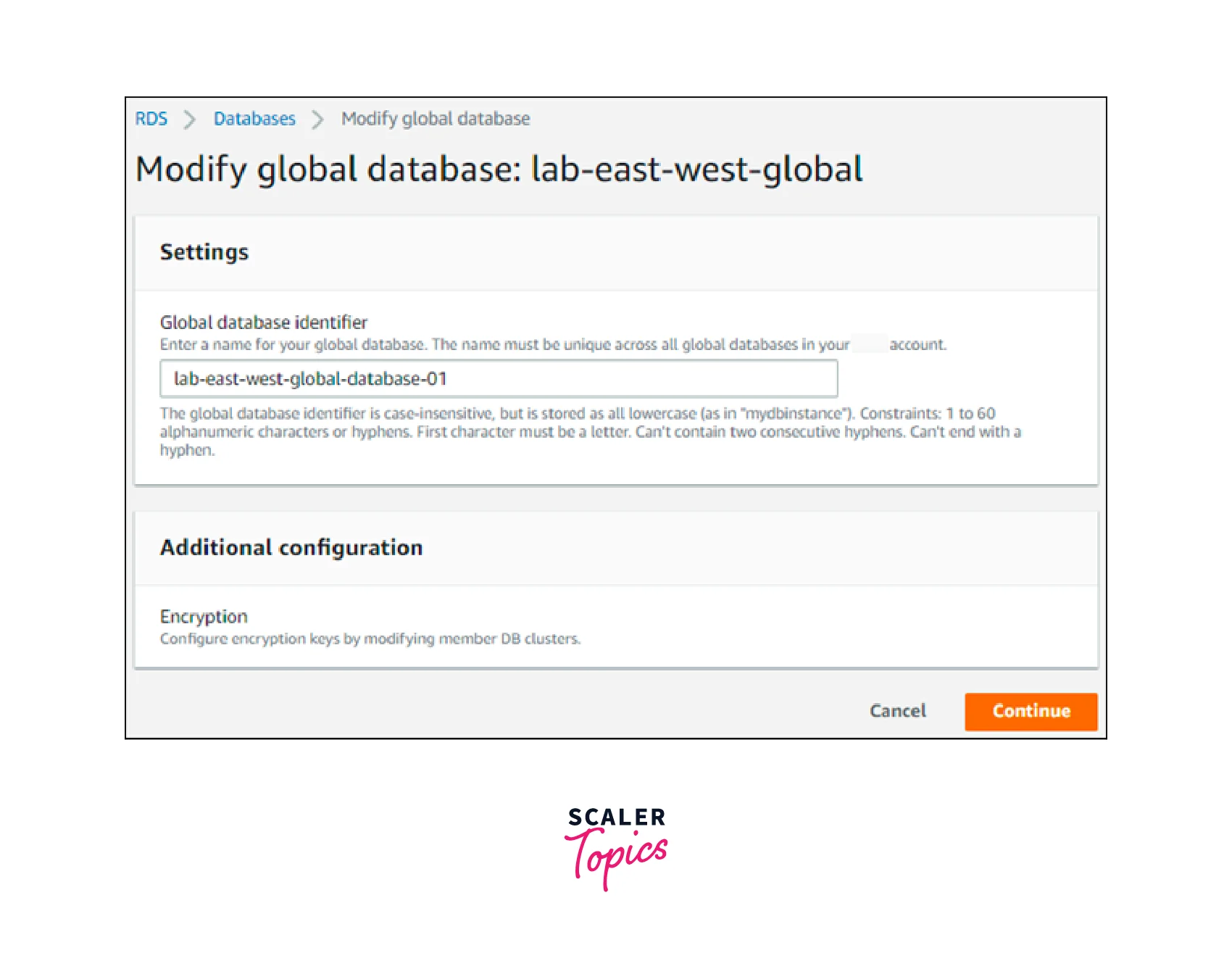
Modifying Parameters for an Aurora Global Database
Each Aurora cluster inside the Aurora global database can have its unique configuration of the cluster parameter groups. The majority of settings operate similarly to other types of Aurora clusters. We advise that you maintain uniform settings across every cluster in a global database. By doing this, you can reduce the risk of a secondary cluster becoming the primary and exhibiting unanticipated behavior changes.
For instance, to prevent inconsistent behavior if a different cluster takes over as the primary cluster, utilize the same settings for time zones and character sets.
Both the configuration options Aurora enable replica log compression and Aurora enable repl bin log filtering have no impact.
Turn Learning into Career Growth
Removing a Cluster from an Amazon Aurora Global Database
There are several reasons why you might want to remove an Aurora DB cluster from your Aurora global database. For instance, if the primary cluster starts to degrade or become isolated, you might want to remove an Aurora DB cluster from an Aurora global database. Once provisioned, it becomes a standalone Aurora DB cluster that can be used to build a brand-new Aurora global database.
Additionally, if you wish to destroy an Aurora global database that you no longer want, you can choose to remove Aurora DB clusters. The Aurora global database cannot be deleted until all related Aurora DB clusters have been eliminated (detached), with the parent cluster coming last.
It is no longer in sync with the primary when an Aurora DB cluster is cut off from the Aurora global database. It develops into an independent, fully functional Aurora DB cluster.
Connecting to an Amazon Aurora Global Database
Depending on whether you need to write to or read from an Aurora global database, there are different connections you may make:
- You connect to the reader endpoint for the Aurora cluster in your AWS Region for requests or queries that are read-only.
- Connect to the cluster endpoint for the primary cluster to execute statements written in the data manipulation language (DML) or data definition language (DDL). This endpoint may be in a different AWS Region than your application.
All of the general-purpose endpoints connected to every one of the clusters in an Aurora global database are visible when you visit it in the console. A sample is shown in the screenshot that follows. The primary cluster that you employ for writing operations has a solitary cluster endpoint connected to it. There is a reader endpoint that you use for read-only queries on both the primary cluster and each subsidiary cluster. Choose the reader endpoint that is located in your AWS Region or the AWS Region that is nearest to you to reduce latency. An illustration using Aurora MySQL is provided below.
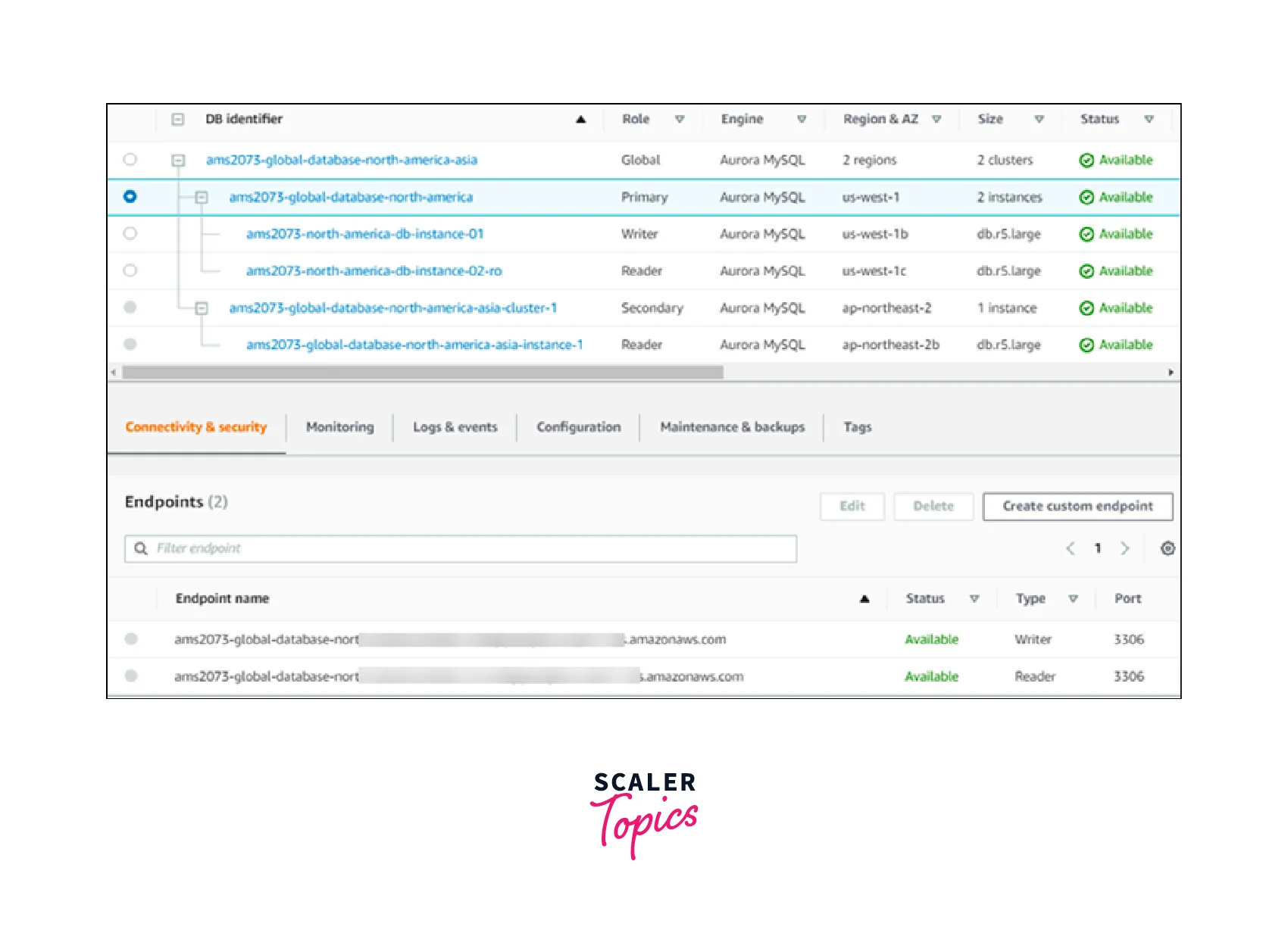
Using Write Forwarding in an Amazon Aurora Global Database
Use write forwarding to lower the number of endpoints you have to maintain for programs operating on your Aurora global database. An Aurora global database's subsidiary clusters can send SQL statements that carry out write operations to the parent cluster using this feature of Aurora MySQL. Updates are made to the source by the primary cluster, which then propagates the changes to all auxiliary AWS Regions.
You may avoid creating your system to transfer write operations from a secondary AWS Region to the primary Region by using the write forwarding option. The networking configuration across Regions is handled by Aurora. Additionally, Aurora sends each statement's whole session and transactional context. In the Aurora global database, data is always changed first on the primary cluster and then replicated in the secondary clusters. In this manner, your primary cluster serves as the source of truth and maintains a current copy of all of your data.
Using Failover in an Amazon Aurora Global Database
A default Aurora DB cluster's failover capabilities are less extensive than those offered by an Aurora global database. You can prepare for a disaster and recover fairly quickly by utilizing an Aurora global database. RTO (Recovery Time Objective) and RPO (Recovery Point Objective) numbers are commonly used to gauge recovery following a disaster.
- The amount of time it takes for a system to go back to functional order following a calamity. RTO, then, calculates downtime. RTO for an Aurora global database might range from minutes to hours.
- The maximum quantity of data that can be lost is known as the recovery point objective (RPO) (measured in time). RPO is commonly measured in seconds for an Aurora global database. The rds.global db.rpo option may be used with an Aurora PostgreSQL-based global database to establish and track the upper bound on RPO, however, doing so may have an impact on how transactions are processed on the writer node of the primary cluster.
Depending on the circumstance, there are two distinct failover strategies for an Aurora global database.
- Manual Unplanned Failover ("Detach and Promote"):- Perform a cross-region failover to one of the secondary tables in your Aurora global database to recover from an unforeseen outage or to conduct disaster recovery (DR) testing. The RTO for this manual procedure is based on how soon you can complete the actions outlined in Recovering an Amazon Aurora global database after an unforeseen outage. The RPO is commonly expressed in seconds, although this relies on the Aurora storage replication latency over the network at the moment of the failure.
- Managed Planned Failover:- This capability is designed for controlled conditions like operational maintenance and other preplanned operational processes. Your Aurora global database's primary DB cluster can be moved to one of the secondary Regions utilising controlled planned failover. RPO is 0 as a result of this functionality synchronizing secondary DB clusters with the primary before implementing any additional modifications (no data loss).
Monitoring an Amazon Aurora Global Database
Numerous settings that enable you to track the performance of your DB cluster are available when you construct the Aurora DB clusters that make up your Aurora global database. These choices include the following:
- Amazon RDS Performance Insights:- Enables performance schema in the underlying Aurora database engine. See Monitoring an Amazon Aurora Global Database with Amazon RDS Performance Insights for additional information on Performance Insights and Aurora global databases.
- Enhanced Monitoring:- Produces measurements for CPU process or thread use.
- Publishes particular log types to CloudWatch Logs through Amazon. By default, error logs are published, but you can select different logs according to your Aurora database engine.
- The audit log, general log, and sluggish query log may all be exported for Aurora DB clusters powered by MySQL.
- You may export the Postgresql log for Aurora DB clusters powered by PostgreSQL.
- You may use specific functions for Aurora PostgreSQL-based global databases to verify the status of your Aurora global database and its instances.
The primary Aurora DB cluster under an Aurora global database's Monitoring page of some of the parameters is shown in the screenshot below.
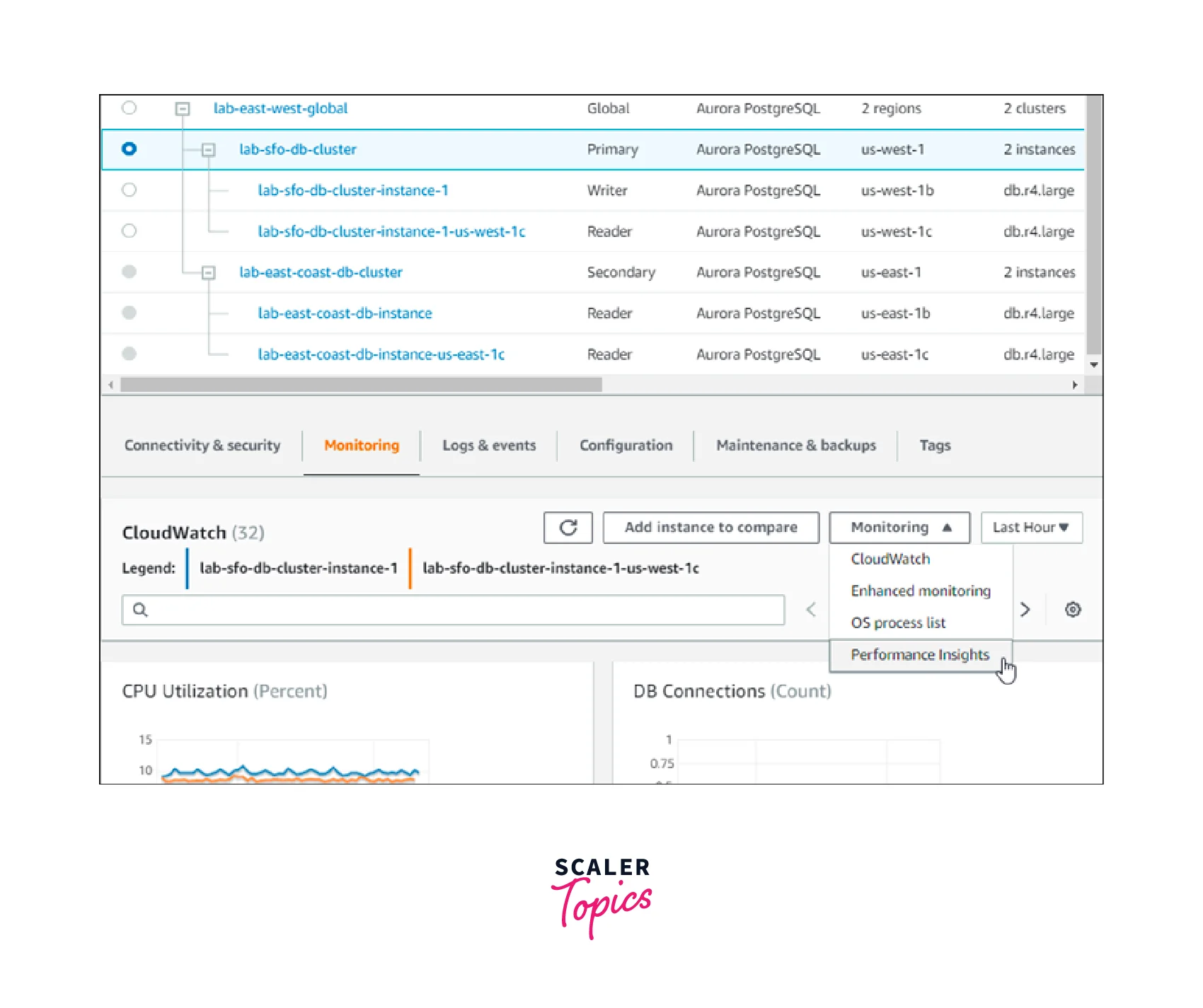
Using Amazon Aurora Global Databases with Other AWS Services
Other AWS services like Amazon S3 and AWS Lambda are compatible with your Aurora global databases. For this to work, each Aurora DB cluster in your global database must be granted the same permissions, access to the same external resources, and other requirements in each of their various AWS Regions. We advise setting up write rights beforehand on all Aurora DB clusters for any services you want to use with your Aurora global database as a read-only Aurora secondary DB cluster in an Aurora global database can be promoted to the position of primary.
The methods to follow for each AWS service are listed in the following list:
- AWS Lambda functions may be called from an Aurora global database.
- Follow the steps in Invoking a Lambda function from an Amazon Aurora MySQL DB cluster for each Aurora cluster that makes up the Aurora global database.
- The (ARN) of the new IAM (IAM) role should be set for each cluster in the Aurora global database.
- Assign the role you defined in Creating an IAM role to allow Amazon Aurora to access AWS services with each cluster in the Aurora global database to allow database users in an Aurora global database to call Lambda functions.
- Configure the Aurora global database's clusters to permit outbound connections to Lambda.
To import information from Amazon S3:
- Implement the steps in Loading data into an Amazon Aurora MySQL DB cluster from text files in an Amazon S3 bucket for all the Aurora clusters that comprise the Aurora global database.
- Set the Amazon Resource Name (ARN) of the new IAM role as either the aurora load from the s3 role or AWS default s3 role DB cluster parameter for each Aurora cluster in the global database. Aurora utilizes the IAM role defined in AWS default s3 role if an aurora load from the s3 role isn't specified.
- Assign the role you defined in Creating an IAM role to allow Amazon Aurora to access AWS services to each Aurora cluster in the global database to allow database users in an Aurora global database to access S3.
- The global database's Aurora clusters should all be set up to permit outgoing connections to S3.
Upgrading an Amazon Aurora Global Database
To keep in mind before you begin the procedure, however, are the following significant distinctions. We advise you to update both the primary and secondary DB clusters to the same version. When the primary and secondary DB clusters have different DB engine versions—be the major, minor, or patch versions—Aurora global databases cannot fail over from a primary to a secondary DB cluster.
Conclusion
- With the help of the Amazon Aurora Global Database, which enables a single Amazon Aurora database to span different AWS regions, globally dispersed applications may now be used. In addition to enabling quick local reads with minimal latency in each region and offering disaster recovery from region-wide failures, it duplicates your data without affecting database performance.
- At least two Amazon Web Services Regions are involved in an Aurora global database. One writer Aurora DB instance in an Aurora DB cluster is supported by the main Amazon Web Services region.
- An fully Aurora Replica-based read-only Aurora DB cluster is hosted in a separate Amazon Web Services region. The minimum number of secondary Amazon Web Services Regions for an Aurora global database is one, whereas the maximum number of secondary Amazon Web Services Regions is five.
- A single Amazon Aurora database may be spread across many AWS Regions thanks to the Amazon Aurora Global Database, which was created for globally dispersed applications. It supports disaster recovery from region-wide outages, quick local reads with minimal latency in each Region, and data replication without affecting database performance.
- When connected to the same Aurora Storage Engine volume as the primary DB Instance, an Amazon Aurora Replica can only perform read operations. To achieve high availability, it is possible to place Aurora Replicas in different Availability Zones, whereby Aurora will carry out an automatic failover if the primary DB Instance becomes unavailable.
- A default Aurora DB cluster's failover capabilities are less extensive than those offered by an Aurora global database. You may prepare for a disaster and recover rather fast by utilizing an Aurora global database. RTO and RPO numbers are commonly used to gauge recovery following a disaster.
- An Amazon Aurora global database's global database cluster, rather than the individual clusters it includes, is upgraded when a major version update is carried out. Before upgrading the primary cluster, you upgrade all of the subsidiary clusters in an Aurora global database.