Amazon Kinesis Data Analytics
Overview
Amazon Kinesis Data Analytics is the easiest way to transform and analyze streaming data in real time with Apache Flink. Apache Flink is an open-source framework and engine for processing data streams. Kinesis Data Analytics reduces the complexity of building, managing, and integrating Apache Flink applications with other AWS services.
What is Amazon Kinesis Data Analytics?
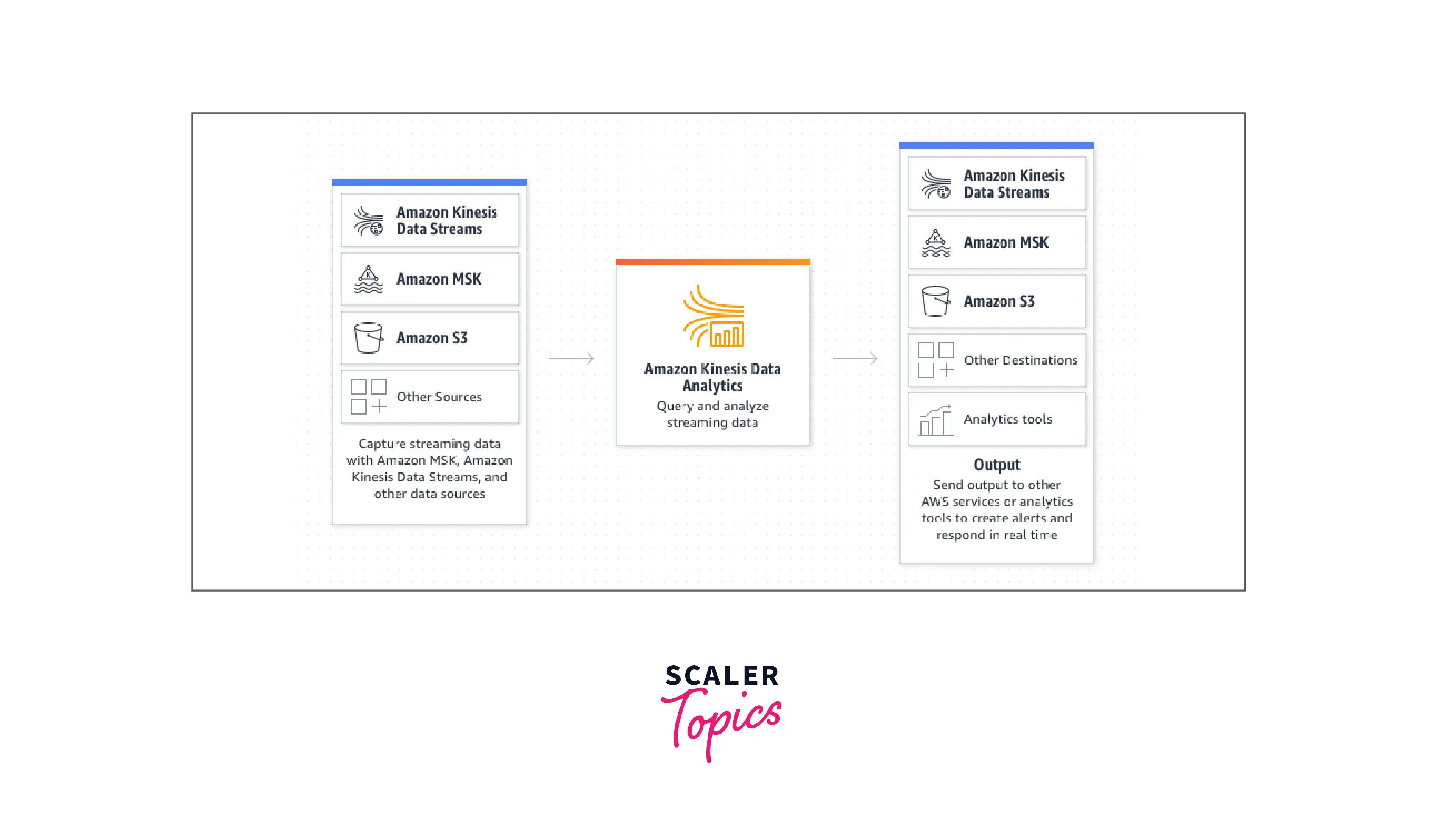
AWS Kinesis Data Analytics is used to analyze streaming data, acquire actionable insights, and respond in real time to your company and customer demands.
Amazon Kinesis Data Analytics is a simple method to analyze streaming data, get insights, and respond to your company and customer demands in real time. Amazon Kinesis Data Analytics facilitates the development, management, and integration of streaming applications with other AWS services.
Using templates and an interactive SQL editor, SQL users may simply query streaming data or construct full streaming applications. Java developers may easily create complex streaming apps that modify and analyze data in real-time by leveraging open-source Java libraries and AWS connectors.
How Does It Work?
Development of an Apache Flink Application The Apache Flink app is a Java (or) Scala application created with the Apache Flink framework. You develop your Apache Flink applications locally.
Applications commonly use the DataStream API or the Table API. You may also use the other Apache Flink APIs. However, they are less commonly utilized in the development of streaming applications.
The two APIs have the following characteristics:
DataStream API
The Apache Flink DataStream API programming paradigm consists of two components:
- Data stream: A structured representation of a continuously flowing stream of data records.
- Transformation operator: It accepts many data streams as input and returns one or more data streams as output.
Applications built using the DataStream API do the following tasks:
- Read data from the source.
- Apply data transformations such as filtering, aggregation, or enrichment.
- Toss the changed data into a Data Sink.
A connector is used by your program to process data. Apache Flink employs the following connectors:
- Source: connector is used to consume external data.
- Sink: connector is used to write to external destinations
- Operator: connector is used to process the data internally in an application.
Table API
The following components comprise the Apache Flink Table API programming model:
- Table Environment: A data interface you use to construct and host one or more tables.
- Table: An object that gives you access to a SQL table or view.
- Table Source: This source reads data from an external source.
- Table Function: An SQL query (or) API call for data transformation.
- Table Sink: A table sink is used to write data to a remote location, such as an Amazon S3 bucket.
Applications made using the Table API do the following tasks:
- Connect to a Table Source to create a TableEnvironment.
- In the TableEnvironment, create a table using SQL queries or Table API methods.
- Execute a query on the table using Table API or SQL.
- Using Table Functions or SQL queries, apply alterations to the query results.
- Save the results of the query or function to a Table Sink.
Building Your Kinesis Data Analytics App A Kinesis Data Analytics application is an Amazon Web Services (AWS) resource hosted by the Kinesis Data Analytics service. Your Apache Flink application is hosted by your Kinesis Data Analytics application, which supplies it with the following settings:
- Runtime Properties: These are the parameters you can pass to your program. These settings can be changed without recompiling your application code.
- Fault Tolerance: How your program recovers from interruptions and restarts.
- Logging and Monitoring: This section describes how your application reports events to CloudWatch Logs.
- Production Scaling: How your application provisions
To know more about how you can create a data analytics application, please refer to this link.
Features of Kinesis Data Analytics
- Free and Open Source Open-source libraries such as Apache Beam, Flink, Zeppelin, AWS SDK, and service integrations are included in Amazon Kinesis Data Analytics. Apache Flink is a free, open-source framework and engine for creating highly accessible and precise streaming applications.
- API Flexibility Kinesis Data Analytics provides adaptable Java, Scala, Python, and SQL APIs tailored to specific use cases such as stateful event processing, streaming ETL, and real-time analytics. With pre-built operators and analytics tools, you can create an Apache Flink streaming application in hours rather than months.
- AWS Service Interoperability You can set up (or) integrate the data source (or) destination with very less code. Amazon Kinesis Data Analytics libraries may interact with Amazon S3, Amazon MSK, AWS OpenSearch, AWS DynamoDB, AWS Kinesis Data Streams, AWS Kinesis Data Firehose, AWS CloudWatch, and Amazon Glue Schema Registry.
- Extensive integration capabilities Aside from AWS interfaces, the Kinesis Data Analytics libraries contain over ten Apache Flink connectors and the option to create custom integrations. You can change how each integration acts with enhanced features with a few extra lines of code.
- Works with AWS Glue Schema Registry Kinesis Data Analytics for Apache Flink is AWS Glue Schema Registry compliant. This free serverless AWS Glue functionality allows you to validate and manage the development of streaming data using registered Apache Avro schemas.
- Precisely Once Processing Using Apache Flink in Kinesis Data Analytics, you may create applications where processed records impact the outcomes just once, a technique known as precisely once processing. Even if there is an application outage, such as internal service maintenance or a user-initiated application update, the service will guarantee that all data is processed and no duplicate data is present.
- Stateful Operation The service keeps past and ongoing calculations or states in running application storage. Compare current and historical results across any time to facilitate rapid recovery during application outages. The state is always encrypted and stored in running application storage in increments.
- Long-Term Application Backups A single API call allows you to make and remove long-term application backups. After an interruption, immediately restore your apps from the most recent backup, or restore your application to an older version.
- Easy Build and Run Environment Studio notebooks offer a unified development environment for creating, debugging, and executing stream processing programs.
- Development There are no servers to install, configure, or scale. Simply write code and pay for the resources that your apps need. Use the notebook to easily deploy your code to a constantly operating stream processing application with autoscaling and a persistent state.
- Compatible with AWS Glue Data Catalog The AWS Glue Data Catalog is a persistent metadata store that acts as a central repository for table definitions. The AWS Glue Data Catalog allows you to rapidly identify and search across numerous AWS datasets. The AWS Glue Data Catalog, where you may set the schema for your source and destination tables, is compatible with Kinesis Data Analytics Studio.
- SQL applications for Kinesis Data Analytics We recommend that you utilize the new Kinesis Data Analytics Studio for new projects rather than Kinesis Data Analytics for SQL Applications. Kinesis Data Analytics Studio blends ease of use with strong analytical capabilities, allowing you to quickly create sophisticated stream processing applications.
- SQL Editor for the Console Create SQL queries using a console-based editor that uses streaming data operations such as sliding time-window averages. You may also use live data to troubleshoot or fine-tune your script by viewing streaming results and problems.
- Convenient Schema Editor Kinesis Data Analytics includes a simple schema editor for discovering and editing input data structure. The wizard identifies typical data types like JSON and CSV automatically. It infers the structure of the supplied data to provide a basic schema that you may customize with the schema editor.
- Pre-Configured SQL Templates The interactive SQL editor includes a set of templates that provide basic SQL code for the most frequent operations, such as aggregate, per-event processing, and filtering. Simply choose the proper template for your analytics work and then use the SQL editor to adapt the given code for your individual use case.
- Progressive Stream Processing Functions Kinesis Data Analytics provides functions specialized for stream processing, allowing you to quickly do sophisticated analytics on your streaming data, such as anomaly detection and top-K analysis.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Kinesis Data Analytics Use Cases
- Delivering Streaming Data in Just a Few Seconds AWS Kinesis Data Analytics allows users to create software to modify and send data to services like AWS OpenSearch and AWS S3.
- Develop Real-Time Statistics AWS Kinesis Data Analytics allows real-time interaction and data analysis to provide insights for time-sensitive application cases.
- Perform Stateful Computations AWS Kinesis Data Analytics also utilizes stateful, long-running calculations to start actual operations based on past data records, such as anomaly detection.
Amazon Kinesis Data Analytics Pricing
You just pay for what you use with Amazon Kinesis Data Analytics. There are no resources to supply and no initial expenditures. The number of Kinesis Processing Units (KPUs) used to run your applications determines your hourly fee. A single Kinesis Processing Units(KPU) has one vCPU compute and four gigabytes of memory.
- Pricing for Amazon Kinesis Data Analytics for Apache Flink Streaming Applications You will be charged an extra KPU per application for Apache Flink orchestration. Running storage and long-term backups are also paid for by applications. Running application storage is utilized in Amazon Kinesis Data Analytics for stateful processing capabilities and is paid per GB/month. Durable backups are optional and offer point-in-time application recovery; they are priced per GB/month.
- Pricing for Amazon Kinesis Data Analytics Studio In interactive mode, you are charged two additional KPUs per Studio application. One KPU is dedicated to Apache Flink application orchestration, while the other is dedicated to the serverless interactive development environment. Running application storage utilized for stateful processing capabilities will also be paid for. Storage for running applications is paid per GB per month.
Region: US East (Ohio)
| Kinesis Processing Unit, Per Hour | $0.11 per hour |
| Running Application Storage, Per GB-month (50GB of running application storage is assigned per KPU) | $0.10 per GB-month |
| Durable Application Backups, Per GB-month | $0.023 per GB-month |
| Kinesis Processing Unit, Per Hour for Studio notebooks | $0.11 per hour |
| Running Application Storage, Per GB-month for Studio notebooks | $0.10 per GB-month |
Getting Started with Amazon Kinesis Data Analytics
Develop a Kinesis Data Analytics application for a python app using a Kinesis stream as a source and sink.
Create Some Resources For this experiment, you must first construct the following dependent resources before creating an Amazon Managed Service for Apache Flink:
- Two Kinesis streams, one for input and one for output.
- An Amazon S3 bucket (ka-app-<username>) for storing the application's code and output.
Create Two Kinesis Streams
Create two Kinesis data streams before creating a Kinesis Data Analytics application for this example (ExampleInputStream and ExampleOutputStream). These streams are used by your program as the source and destination streams.
You can create these streams using the Amazon Kinesis UI or the AWS CLI command below.
To create the data streams (AWS CLI)
- Use the Amazon Kinesis create-stream AWS CLI command to create the first stream (ExampleInputStream).
- Run the same command, but change the stream name to ExampleOutputStream to create the second stream that the application uses to write output.
Create an Amazon S3 Bucket Using the console, you may create an Amazon S3 bucket. See the following topics for details on how to create this resource:
- How Do I Create an S3 Bucket in the Amazon Simple Storage Service User Guide. By appending your login name, such as ka-app-<username>, you can give the Amazon S3 bucket a globally unique name.
Other Resources If they do not already exist, Kinesis Data Analytics creates the following Amazon CloudWatch resources when you create your application:
- /aws/kinesis-analytics-java/MyApplication , a log group.
- kinesis-analytics-log-stream, a log stream.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Write Sample Records to the Input Stream
In this step, you write example records to the stream for the program to process using a Python script.
- Make a stock.py file with the following contents:
Now run the stock.py script using the following command:
$ python stock.py
Keep the script running while you finish the instruction.
Create and Examine the Apache Flink Streaming Python Code
This example's Python application code is accessible on GitHub. To obtain the application code, perform the following steps:
- If you haven't already, install the Git client.
- Use the following command to clone the remote repository:
- Navigate to the directory amazon-kinesis-data-analytics-java-examples/python/GettingStarted. The streaming-file-sink.py file contains the application code. Take note of the following information about the application code:
- To read from the source stream, the application use a Kinesis table source. To construct the Kinesis table source, the following code sample uses the create table function:
To build a table backed by the streaming source, the create table function executes the following SQL command:
The program creates two tables and then writes the contents of one to the other.
- The Flink connector from the flink- sql-connector-kinesis 2.12/1.13.2 file is used by the application.
- When utilizing third-party Python packages (such as boto3), they must be included to the GettingStarted folder, which contains getting-started.py. In Apache Flink or Kinesis Data Analytics, no further configuration is required. How to use boto3 within pyFlink provides an example
Turn Learning into Career Growth
Upload the Apache Flink Streaming Python Code
You build an Amazon S3 bucket and upload your application code in this section.
To upload the application code using the console:
- Compress the getting-started.py and files using your favourite compression application. Save the file as myapp.zip. If you include the outer folder in your archive, you must provide the following path in your configuration file(s): GettingStarted/getting-started.py.
- Go to access the Amazon S3 console.
- Select Create bucket.
- In the Bucket name field, type ka-app-code-<username>. To make the bucket name globally unique, add a suffix, such as your user name. Select Next.
- In the Configure options step, leave the settings alone and click Next.
- In the Set permissions stage, leave the settings alone and click Next.
- Select Create bucket.
- Open the Amazon S3 console and navigate to the ka-app-code-<username> bucket and select upload.
- Select Add files in the Select files step. Go to the myapp.zip file you saved in the previous step. Select Next.
- You don't need to edit any of the object's properties, so select Upload.
Create and Run the Kinesis Data Analytics Application
To use the console to create, configure, update, and launch the application, follow these steps.
Make the Application
- Go here to access the Kinesis Data Analytics console. Select Create analytics application from the Kinesis Data Analytics dashboard.
- Provide the following application details on the Kinesis Analytics - Create application page:
- For the Application name, type MyApplication.
- For the Description, type My Java Test App.
- Choose Apache Flink as the Runtime.
- Maintain the Apache Flink version 1.13.1. (Recommended version).
- Choose Create / update IAM role kinesis-analytics-MyApplication-us-west-2 for Access permissions. Select Create application.
Configure the Application
To configure the application, follow the steps below.
In order to configure the application
- Select Configure from the MyApplication page. On the Configure application page, enter the following code location:
- Enter ka-app-code-<username> for Amazon S3 bucket.
- Enter myapp.zip as the Path to Amazon S3 object.
- Choose Create / update IAM role kinesis-analytics-MyApplication-us-west-2 for Access permissions under Access to application resources.
- Select Add group from the Properties menu.
- Enter consumer.config.0 as the Group ID.
- Enter the application properties and values as follows:
| Key | Value |
|---|---|
| input.stream.name | ExampleInputStream |
| aws.region | us-west-2 |
| flink.stream.initpos | LATEST |
- Under Properties, choose Add group again. For Group ID, enter producer.config.0
- Enter the following properrties
| Key | Value |
|---|---|
| output.stream.name | ExampleOutputStream |
| aws.region | us-west-2 |
| shard.count | 1 |
- Select Add group once more from the Properties menu. Enter kinesis.analytics.flink.run.options as the Group ID. This special property group specifies where your application's code resources can be found. See here to know more,
- Enter the application properties and values as follows:
| Key | Value |
|---|---|
| python | getting-started.py |
| jarfile | flink-sql-connector-kinesis_2.12-1.13.1.jar |
- Make sure the Monitoring metrics level is set to Application under Monitoring.
- To enable CloudWatch logging, select the Enable check box.
- Select Update.
Edit the IAM Policy Modify the IAM policy to grant access to the Amazon S3 bucket.
To add S3 bucket permissions, update the IAM policy
- Go to this link to access the IAM console.
- Select Policies. Select the kinesis-analytics-service-MyApplication-us-west-2 policy defined by the console in the previous section.
- Select Edit policy from the Summary page.
- Select the JSON tab. Add the highlighted part of the policy sample below to the policy. Substitute your account ID for the sample account IDs (012345678901).
Run the Application
Running the application, viewing the Apache Flink dashboard, and selecting the desired Flink task will display the Flink job graph.
Stop the Application
Stop the application by selecting Stop from the MyApplication page. Confirm your decision.
Reference for Getting Started(Python)
For more about getting started please refer this link and scroll to Getting Started on the left bar
Benefits of Using Kinesis Data Analytics
- ETL Streaming Streaming ETL technologies allow you to clean, enrich, organize, and convert raw data in real time before putting it into your data lake or data warehouse, minimizing or eliminating batch ETL stages. These programs may buffer tiny records into bigger files before delivering them and execute complex joins between streams and tables.
- Continuous metric generation Applications that generate continuous metrics enable you to track and analyze how your data develops over time. To serve your apps and users in real time, your applications may aggregate streaming data into crucial information and easily link it with reporting databases and monitoring services. To produce time-series analytics over time frames, you may use SQL or Apache Flink code written in a supported language with Kinesis Data Analytics.
- Responsive real-time analytics When specific metrics surpass specified criteria, or in more sophisticated scenarios, when your program discovers abnormalities using machine learning techniques, responsive real-time analytics apps provide real-time warnings or notifications. These programs let you respond in real-time to changes in your business, such as forecasting user desertion in mobile apps and spotting deteriorating systems.
- Interactive data stream analysis Real-time data exploration is possible with interactive analysis. You may investigate streams from Amazon MSK or Amazon Kinesis Data Streams using ad hoc queries or scripts and observe how data looks within those streams.
- Performs on streaming data in real-time Most analytics programs analyze data streams in batches, sample them across the stream, or have a processing delay. This is not the situation with Amazon Kinesis Data Analytics, which does real-time stream processing on data streams.
- Serverless With this service, you don't have to bother deploying and managing servers since Amazon Kinesis Data Analytics is serverless; the core architecture is maintained and automated behind the doors, so you can focus on data analytics rather than server maintenance.
- Scalability In most cases, Kinesis Data Analytics elastically grows your application to suit your source stream's data throughput and query complexity. Scaling can be achieved by enabling parallel task execution and resource allocation.
- Pay-as-you-go system Like many other AWS services, Amazon Kinesis Data Analytics is a pay-as-you-go service. This means you only pay for what you use, with no wasted resources or labor required to optimize the concern with maximizing.
- There is no need to learn new programming languages, frameworks, or machine learning algorithms You can get started using Amazon Kinesis Data Analytics without learning any new languages or frameworks, drastically shortening the learning curve for a new product.
Companies using Kinesis Data Analytics
![]()
NortonLifeLock Using Kinesis Data Analytics for Apache Flink the company saved tens of thousands of dollars each month by enforcing VPN use limitations using a real-time streaming analytics solution.
![]()
BT Group Amazon Kinesis Data Analytics for Apache Flink offers BT Group's network support teams a comprehensive, real-time picture of calls made across the UK utilizing the company's new Digital Voice service. Network support engineers and fault analysts use the system to detect, react to, and successfully address network faults.
![]()
Lightricks Apache Flink with Amazon Kinesis Data Analytics allows the organisation to respond to user activities across mobile and web apps in real time.
Conclusion
- Amazon Kinesis Data Analytics is the easiest way to transform and analyze real-time streaming data using Apache Flink, an open-source data stream framework and engine.
- Amazon Kinesis Data Analytics makes it easier to create and manage Apache Flink workloads and integrate applications with other AWS services.
- Kinesis Data Analytics Studio uses Apache Flink to produce production-ready apps. Apache Zeppelin notebooks give a familiar, easy-to-use environment for developing streaming applications in your preferred language.
- With Amazon Kinesis Data Analytics, you just pay for what you use. There are no resources to supply and no upfront costs. Your hourly charge is determined by the number of Kinesis Processing Units (or KPUs) used to operate your apps.