Kinesis Data Firehose
Overview
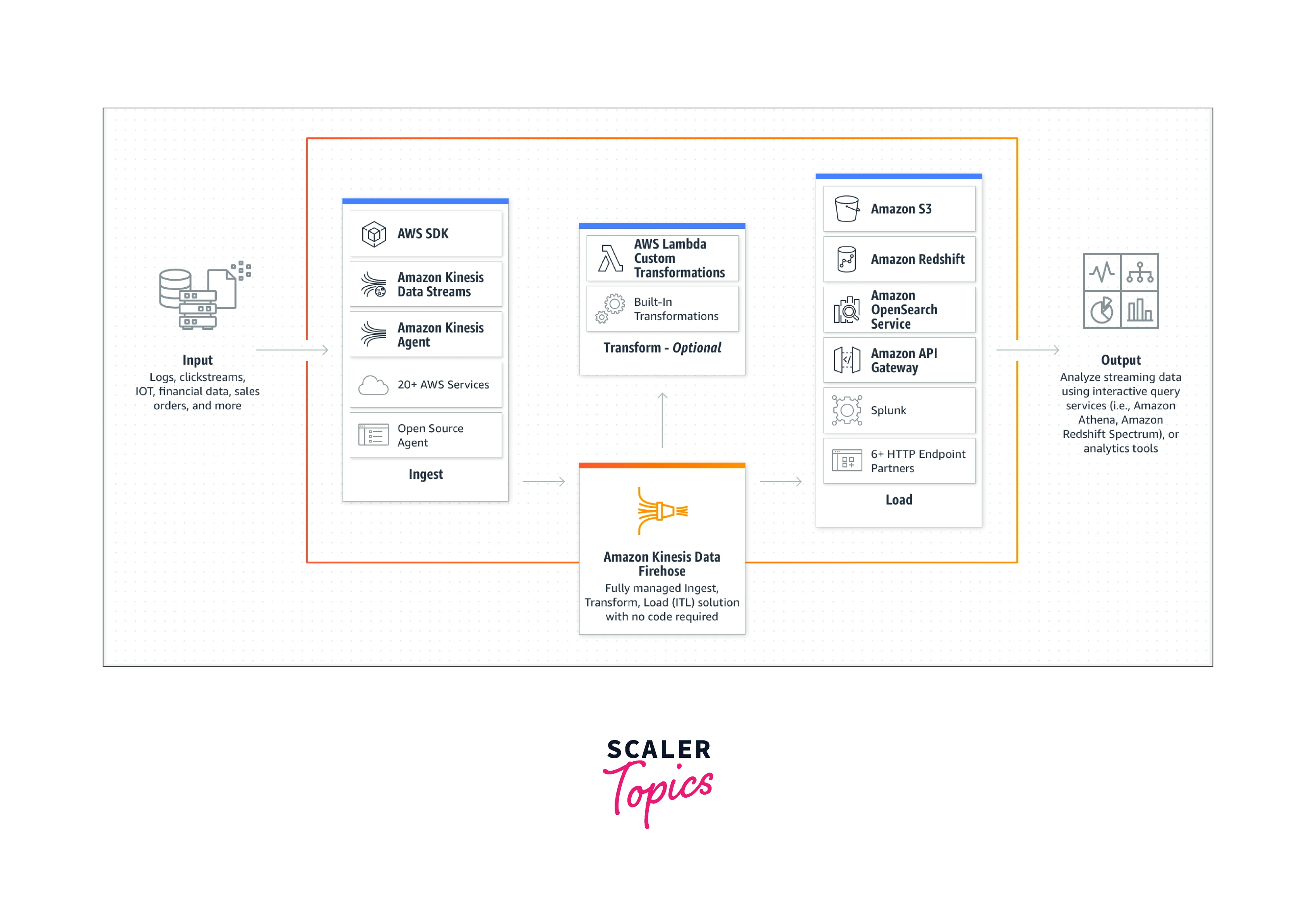
Real-time streaming data can be delivered to locations like Amazon S3, Amazon Redshift, Splunk, Amazon OpenSearch Service, and any custom HTTP endpoint or HTTP endpoints owned by supported third-party service providers like Datadog, Dynatrace, LogicMonitor, MongoDB, New Relic, and Sumo Logic using the fully managed Amazon Kinesis Data Firehose service. The Kinesis streaming data platform includes Kinesis Data Firehose, Amazon Kinesis Data Analytics, and Kinesis Data Streams. Kinesis Data Firehose is not required to build apps or manage resources. The data is automatically sent to the location you choose when you set up your data producers to send data to Kinesis Data Firehose.
Introduction to Amazon Kinesis Data Firehose
Near real-time analytics is made possible on the Amazon Web Services (AWS) cloud via Amazon Kinesis Firehose, which collects and loads streaming data in storage and business intelligence (BI) tools. Kinesis Firehose can scale to meet data throughput requirements and controls the underlying resources for cloud-based computation, storage, networking, and configuration.
Data is delivered to Amazon Redshift, Amazon Elasticsearch Service, and Amazon Simple Storage Service (S3) buckets via Amazon Kinesis Firehose. To improve security and reduce the amount of storage space required, Kinesis Firehose may batch, compress, and encrypt data. To increase redundancy, the service synchronizes data amongst all the Availability Zones(AZs) in the AWS region during transport.
How Kinesis Data Firehose Works?
The quickest method for loading streaming data into AWS is through Amazon Kinesis Firehose. To enable near real-time analytics with the business intelligence tools and dashboards you're already using, it can take, transform, and load streaming data into Amazon Kinesis Analytics, Amazon S3, Amazon Redshift, and Amazon Elasticsearch Service.
Features
Simple to Launch and Configure
With only a few clicks in the AWS Management Console, you can start Amazon Kinesis Data Firehose and construct a delivery stream to load data into Amazon S3, Amazon Redshift, or Splunk. By using the Firehose API or the Linux agent we provide on the data source, you can transmit data to the delivery stream. The data is then continually loaded into the designated destinations using Kinesis Data Firehose.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Add Fresh Data Almost Immediately
The amount of time that data is uploaded to destinations can be slowed down by setting a batch size or batch interval. If you want to get fresh data within 60 seconds of it being sent to your delivery stream, for instance, you could set the batch interval to 60 seconds. You can also indicate whether data should be compressed. The service supports popular compression algorithms such as GZip, Zip, Snappy, and Hadoop-Compatible Snappy. You can manage how quickly fresh data arrives at the destinations by batching and compressing your data before uploading.
To Accommodate Variable Data Flow, Use Elastic Scaling
Once launched, your delivery streams automatically scale up and down to handle gigabytes per second or more of input data rate, and maintain data latency at levels you specify for the stream, within the limits. No intervention or maintenance is needed. They preserve data latency at the levels you designate for the stream within the bounds.
Apache Parquet or ORC Format Conversion
Columnar data formats like Apache Parquet and Apache ORC are supported by Kinesis Data Firehose. They are optimized for cost-effective analytics using services like Amazon Athena, Redshift Spectrum, Amazon EMR, and other Hadoop-based tools. Before storing the data in Amazon S3, Kinesis Data Firehose may convert the incoming data's format from JSON to Parquet or ORC, saving you money on storage and analytics.
Performance Monitoring Metrics
Through the console and Amazon CloudWatch, Amazon Kinesis Data Firehose makes several metrics available, including the amount of data submitted, the amount of data uploaded to the destination, the time it takes for the data to get there, the delivery stream limits, the number of throttled records, and the upload success rate. These metrics can be used to check on the condition of your delivery streams, alter destinations as needed, create alarms when they approach restrictions, and make sure the service is absorbing data and loading it into destinations.
Automatic Optional Encryption
You have the choice to have your data automatically encrypted after it is uploaded to the target using Amazon Kinesis Data Firehose. An AWS Key Management System (KMS) encryption key can be specified as part of the delivery stream setup.
Several Data Destinations are Supported
Amazon Kinesis Data Firehose currently supports Amazon S3, Amazon Redshift, Amazon OpenSearch Service, HTTP endpoints, Datadog, New Relic, MongoDB, and Splunk as destinations. You can specify the destination Amazon S3 bucket, the Amazon Redshift table, the Amazon OpenSearch Service domain, generic HTTP endpoints, or a service provider where the data should be loaded.
Send Data Partitioned to S3
Use dynamically generated keys like customer id or transaction id to dynamically split your streaming data before delivering it to S3. You can more easily do high-performance, cost-effective analytics in S3 utilizing Athena, EMR, and Redshift Spectrum thanks to Kinesis Data Firehose, which combines data by these keys and delivers it into key-unique S3 prefixes.
Transformative Data Integration
Before streaming data is put into data stores, you can enable Amazon Kinesis Data Firehose to prepare the data. Simply choose an AWS Lambda function from the AWS Management console's Amazon Kinesis Data Firehose delivery stream setup tab. Every input data record will automatically receive that function, and the changed data will be loaded to destinations through Amazon Kinesis Data Firehose. For converting popular data sources like Apache logs and system logs to JSON and CSV formats, Amazon Kinesis Data Firehose offers pre-built Lambda blueprints. These pre-built blueprints can be used as-is, further customized, or have your unique functions written for them.
Kinesis Data Firehose System Architecture
Understanding some of the key concepts provided below will help us understand the architecture of Kinesis Data Firehose.
- Record:
Your data producer feeds data of interest to a Kinesis Data Firehose delivery stream. A record can be up to a maximum of 1,000 KB in size. - Delivery Stream for Kinesis Data Firehose:
It is an underlying entity of Kinesis Data Firehose. We can create a Kinesis Data Firehose delivery stream and can transfer the data to it to use Kinesis Data Firehose. - Buffer Interval and Buffer Size:
Before sending incoming streaming data to its destinations, Firehose buffers it for a predetermined amount of time or until it reaches a predetermined size. While the buffer interval is measured in seconds, the buffer size is measured in megabytes. - Data Producer:
Producers give records to Kinesis Data Firehose delivery streams. A web server that sends log data to a delivery stream is an example of a data producer. Additionally, you may configure your Kinesis Data Firehose delivery stream to automatically read data from one Kinesis data stream and transmit it to specified locations.
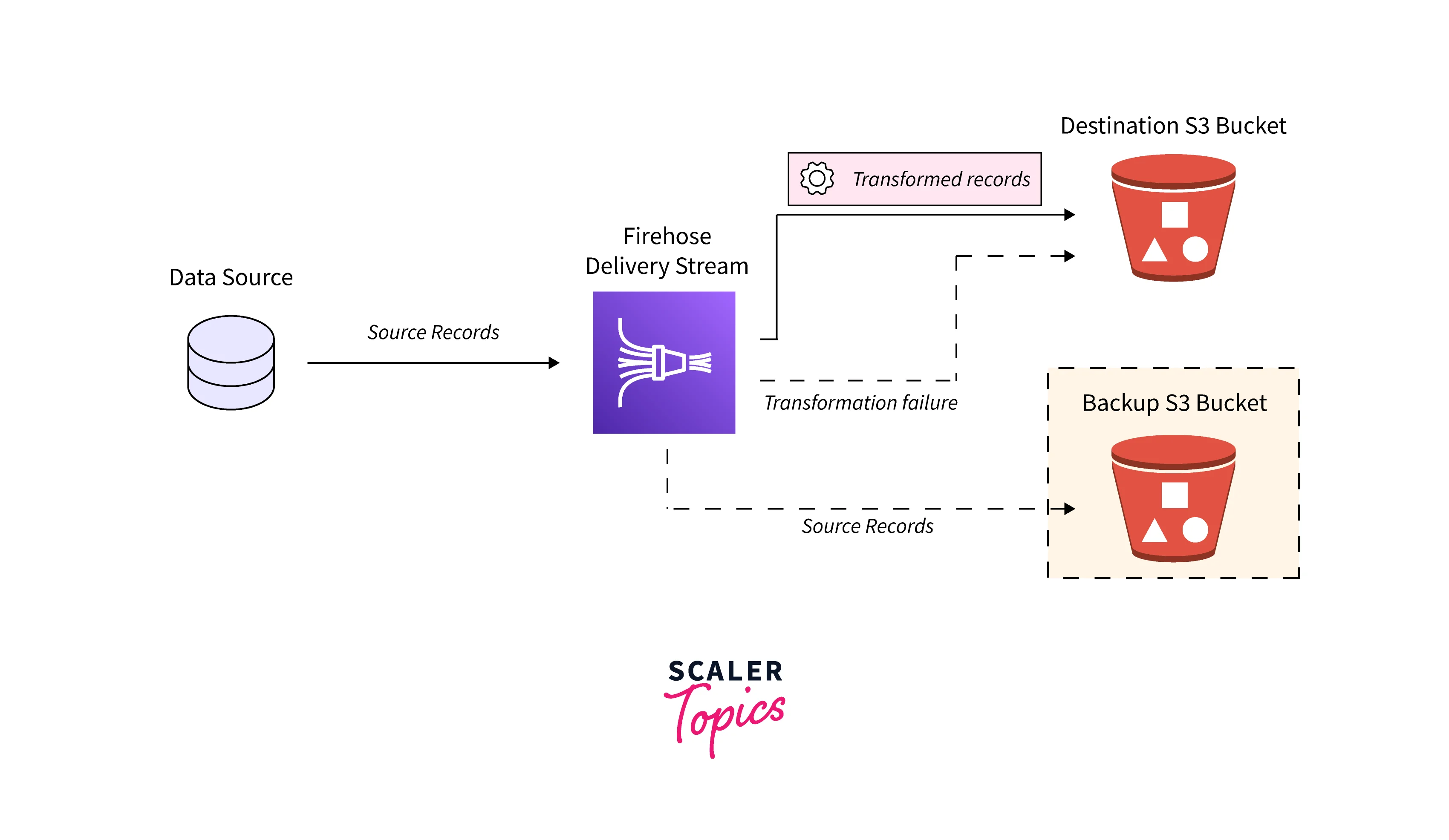
For Amazon S3 destinations, streaming data is delivered to your S3 bucket. You can back up source data to another Amazon S3 bucket if data transformation is enabled.
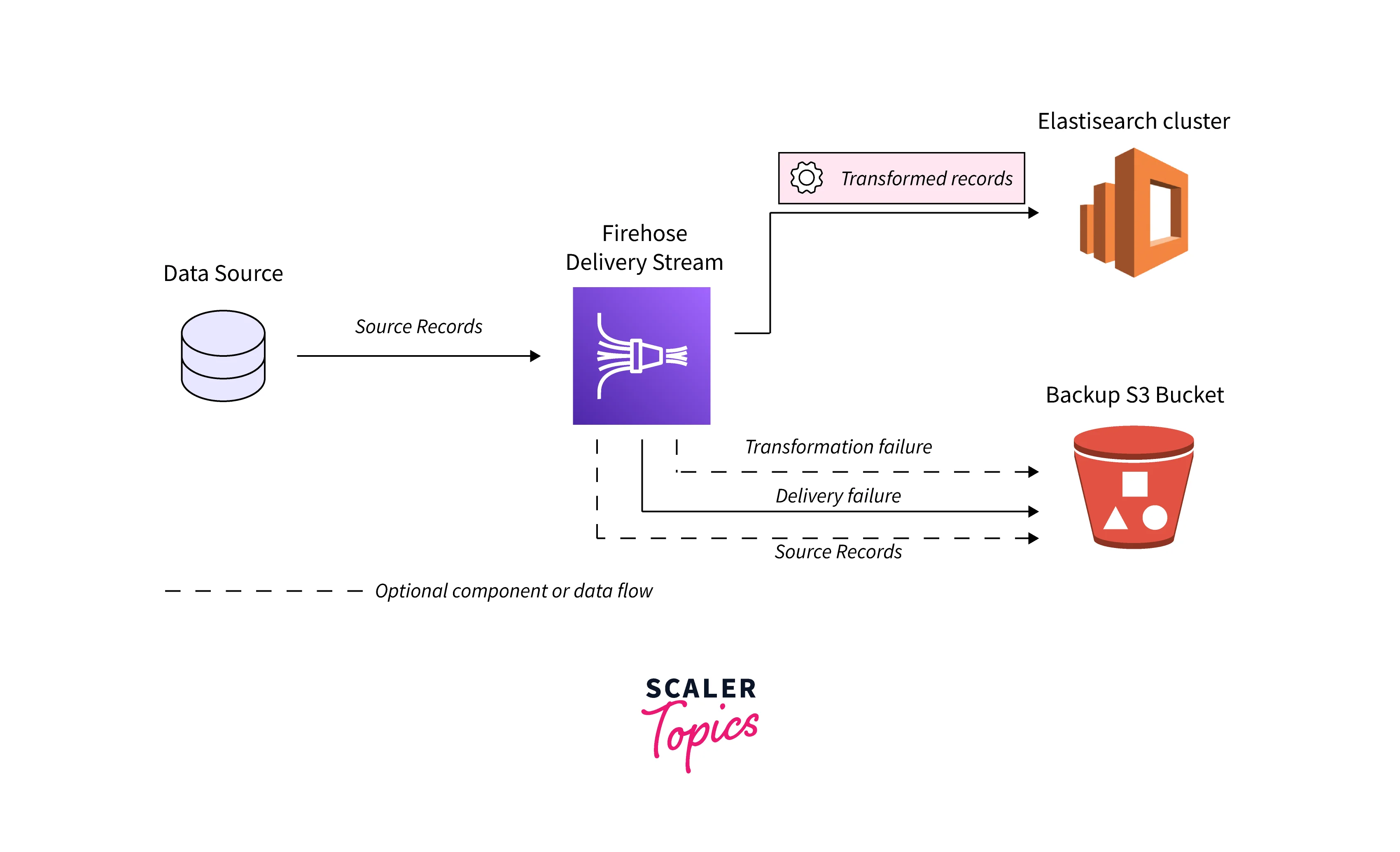
For Amazon Redshift destinations, streaming data is delivered to your S3 bucket in the beginning. Data from your S3 bucket is then loaded into your Amazon Redshift cluster using the COPY command by Kinesis Data Firehose. You can back up source data to another Amazon S3 bucket if data transformation is enabled.
Splunk receives streaming data, which you may choose to back up to your S3 bucket concurrently for Splunk destinations.






Setting Up
Sign Up for AWS
When you register for Amazon Web Services (AWS), all of its services, including Kinesis Data Firehose, are immediately added to your AWS account. Only the services you utilize are billed to you.
Download Libraries and Tools
You may work with Kinesis Data Firehose programmatically and via the command line by using the following libraries and tools:
- The fundamental set of operations that Kinesis Data Firehose provides is the Amazon Kinesis Data Firehose API Reference.
- The Kinesis Data Firehose functionality and samples are available in the AWS SDKs for Go, Java, .NET, Node.js, Python, and Ruby.
- You can also download the newest AWS SDK from GitHub if your version of the AWS SDK for Java does not include samples for Kinesis Data Firehose.
- Kinesis Data Firehose is supported via the AWS Command Line Interface. With the use of scripts, you can automate and manage a variety of AWS services using the AWS CLI.
Creating a Kinesis Data Firehose Delivery Stream
After your delivery stream is formed, you may modify its configuration whenever you want by using UpdateDestination or the Kinesis Data Firehose console. While your configuration is being modified, your Kinesis Data Firehose delivery stream is still in the ACTIVE state and you can still transmit data through it. In most cases, the modified configuration becomes operational immediately. After you make a configuration change, a Kinesis Data Firehose delivery stream's version number is raised by a value of 1. The provided Amazon S3 object name reflects that.
How to construct a Kinesis Data Firehose delivery stream is covered in the following section:
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Source, Destination, and Name
-
Open the Kinesis console by logging into the AWS Management Console at link.
-
Go to the navigation pane and select Data Firehose.
-
To create a delivery stream, select Create delivery stream.
-
Fill in the following fields with values:
- Source:
- Direct PUT:
To create a delivery stream for Kinesis Data Firehose that producer applications can write to directly, select this option. - Kinesis Stream:
Select this option to set up a delivery stream for Kinesis Data Firehose that uses a Kinesis data stream as a data source. The data may then be readily read from an existing Kinesis data stream and loaded into destinations using Kinesis Data Firehose.
- Direct PUT:
- Delivery Stream Destination:
It is your delivery stream's final destination using Kinesis Data Firehose. The Kinesis Data Firehose can transport data records to various destinations, including the Amazon Simple Storage Service (Amazon S3), Amazon Redshift, Amazon OpenSearch Service, and any HTTP endpoint you or one of your third-party service providers manage. - Delivery Stream Name:
The name of the delivery stream for your Kinesis Data Firehose.
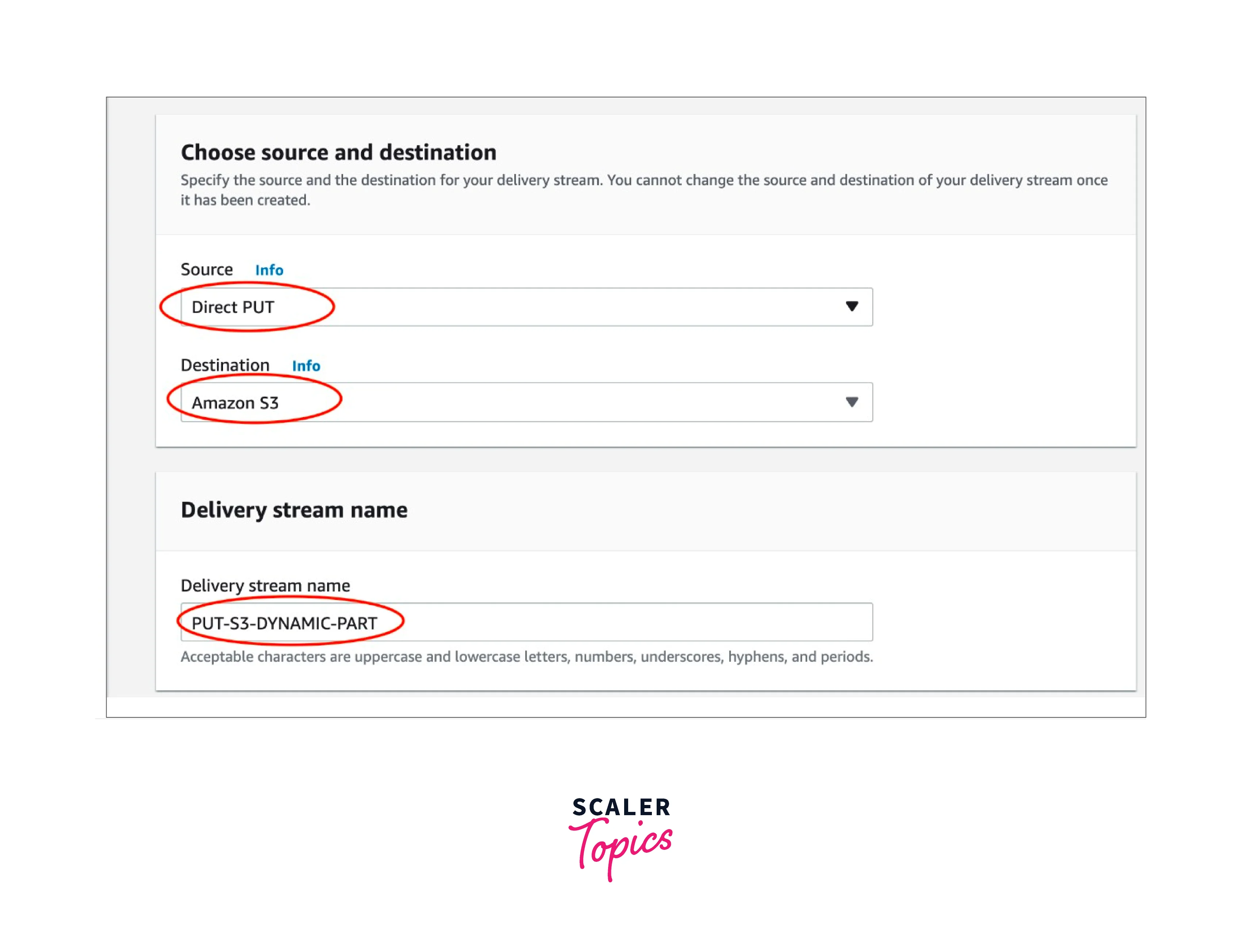
- Source:
Record Transformation and Record Format Conversion
- Fill in the following field in the Transform source records with AWS Lambda section:
Transformation of Data:
- Select Disabled to build a Kinesis Data Firehose delivery stream that doesn't modify incoming data.
- Select Enabled to define a Lambda function that Kinesis Data Firehose will use to alter incoming data before distributing it. You can select an existing Lambda function or configure a new Lambda function using one of the Lambda blueprints.
- Give values to the following field in the Convert record format section:
Format Conversion for Records:
- Select Disabled to build a Kinesis Data Firehose delivery stream that doesn't change the incoming data records' format.
- Select Enabled, then enter the desired output format to convert the receiving records' format. The schema that you want Kinesis Data Firehose to use to change your record format must be specified in an AWS Glue table.
Destination Settings
Choose Amazon S3 for your Destination
To use Amazon S3 as the final location for your Kinesis Data Firehose delivery stream, you must enter the following settings:
- S3 Bucket: Select your own S3 bucket as the delivery location for the streaming data. A new S3 bucket can be created, or you can select an existing one.
- Dynamic Partitioning: To enable and customise dynamic partitioning, select Enabled.
- Multi Record Deaggreggation: Here, entries in the delivery stream are parsed to be separated into groups according to either valid JSON or the given new line delimiter.
- Multi Record Deaggreation Type: If multi-record disaggregation was enabled, Kinesis Data Firehose requires that you specify the disaggregation technique. Select JSON or Delimited from the drop-down menu.
- New Line Delimiter: When you enable dynamic partitioning, you may set up your delivery stream to transfer objects to Amazon S3 with a new line delimiter between records. To do this, select Enabled. Select Disabled to prevent new line delimiters from being added between entries in objects transferred to Amazon S3.
Backup and Advanced Settings
Backup Settings
To back up all or failed only data that Kinesis Data Firehose tries to transmit to your specified destination, it leverages Amazon S3. If you choose one of the following options, you can define the S3 backup settings for your Kinesis Data Firehose delivery stream:
- If you set Amazon S3 as the destination for your Kinesis Data Firehose delivery stream and you choose to specify an AWS Lambda function to transform data records or if you choose to convert data record formats for your delivery stream.
- If you set Amazon Redshift as the destination for your Kinesis Data Firehose delivery stream and you choose to specify an AWS Lambda function to transform data records.
- If you set any of the following services as the destination for your Kinesis Data Firehose delivery stream: Amazon OpenSearch Service, Datadog, Dynatrace, HTTP Endpoint, LogicMonitor, MongoDB Cloud, New Relic, Splunk, or Sumo Logic.
The backup settings for your Kinesis Data Firehose delivery stream are as follows:
- If S3 or Amazon Redshift is the destination you've chosen, this setting lets you choose whether you want to allow source data backup or leave it disabled. This setting determines whether you want to back up all of your source data or just failed data if any other supported service (other than S3 or Amazon Redshift) is chosen as your selected destination.
- S3 Backup Bucket: Kinesis Data Firehose backs up your data in this S3 bucket.
- Your data is backed up via Kinesis Data Firehose to the S3 backup bucket prefix.
- During the backup procedure, all unsuccessful data is accumulated in the S3 bucket error output prefix.
Advanced Settings
The advanced settings for your Kinesis Data Firehose delivery stream are as follows:
- Server-Side Encryption: When delivering data to Amazon S3, Kinesis Data Firehose supports AWS Key Management Service (AWS KMS) server-side encryption.
- Error Logging: If data transformation is enabled, Kinesis Data Firehose can record the Lambda call and report data delivery issues to CloudWatch Logs. You can then see the specific error logs if the Lambda invocation or data delivery fails.
- Permissions: IAM roles are used by Kinesis Data Firehose to grant all the necessary rights to the delivery stream. You have the option of selecting an already-created role for Kinesis Data Firehose or creating a new role where the necessary permissions are automatically assigned. If data encryption is enabled, the role is utilized to give Kinesis Data Firehose access to your S3 bucket, AWS KMS key, and Lambda function (if data transformation is enabled).
- Tags: To organize your AWS resources, keep tabs on expenses, and manage access, you can add tags.
Testing Your Delivery Stream
The AWS Management Console can be used to ingest synthetic stock ticker data. To add sample records to your Kinesis Data Firehose delivery stream, the console executes a script in your browser. This lets you test your delivery stream's settings without having to create your test data.
An illustration using the simulated data is as follows:
Test Using Amazon S3 as the Destination
- Go to link to access the Kinesis Data Firehose console.
- Pick a delivery stream.
- To create a sample stock ticker, select Start delivering demo data under Test using demo data.
- To make sure that data is being sent to your S3 bucket, follow the on-screen instructions. Please be aware that depending on your bucket's buffering configuration, it can take a few minutes for new objects to appear in your bucket.
- To cease paying usage fees after the test is finished, select Stop sending demo data.
Sending Data to a Kinesis Data Firehose Delivery Stream
You can use a variety of sources to transmit data to your Kinesis Data Firehose Delivery Stream: Using the AWS SDK, using a Kinesis data stream, the Kinesis Agent, or the Kinesis Data Firehose API. You can also use AWS IoT, CloudWatch Events, or Amazon CloudWatch Logs as your data source.
Turn Learning into Career Growth
Writing to Kinesis Data Firehose Using AWS IoT
To Construct a Command that Sends Events to an Already Existing Delivery Stream in Kinesis Data Firehose:
- On the Create a rule page of the AWS IoT console, select Add action under Set one or more actions when creating a rule.
- Select Send messages to a stream on Amazon Kinesis.
- Select Configure action
- Select an existing Kinesis Data Firehose delivery stream as the Stream name.
- Select a separator character to be added between records under Separator.
- Choose an existing IAM role or select Create a new role for the IAM role name.
- Select Add action.
Writing to Kinesis Data Firehose Using CloudWatch Events
To Choose a Delivery Stream as the Destination for Events Sent by a CloudWatch Events Rule:
- Open the CloudWatch console by logging into the AWS Management Console at link
- Select Create rule.
- Select Firehose delivery stream under Targets on the Step 1: Create rule page, then click Add target under Targets.
- Pick an existing Kinesis Data Firehose delivery stream as your delivery stream option.
Writing to Kinesis Data Firehose Using Kinesis Data Streams
You can configure Amazon Kinesis Data Streams to send information to a Kinesis Data Firehose delivery stream.
Writing to Kinesis Data Firehose Using Kinesis Agent
You can configure Kinesis Agent to send information to a Kinesis Data Firehose delivery stream.
Writing to Kinesis Data Firehose Using Kinesis AWS SDK
You can configure AWS SDK to send information to a Kinesis Data Firehose delivery stream.
Writing to Kinesis Data Firehose Using CloudWatch Logs
You can configure CloudWatch Logs to send information to a Kinesis Data Firehose delivery stream.
Use Cases of Kinesis Data Firehose
- Flow Into Data Warehouses and Lakes:
Using Amazon Kinesis Data Firehose, stream data into Amazon S3 and transform it into the formats needed for analysis without creating processing pipelines. - Enhance Security:
Using approved Security Information and Event Management (SIEM) solutions, you can keep an eye on network security in real-time and generate alerts when potential threats appear. - Construct ML Streaming Applications:
Add machine learning (ML) models to your data streams to analyze the data and forecast inference endpoints as the streams travel to their final destination.
Pricing
You only pay for the amount of data you consume in the service while using Amazon Kinesis Data Firehose. There are no up-front costs or commitments. With Kinesis Data Firehose, there are four different on-demand usage scenarios: ingestion, format conversion, VPC delivery, and dynamic partitioning. There may be additional data transmission fees.
Direct PUT and KDS as a Source Ingestion
Ingestion and distribution are the fundamental duties of a Kinesis Data KDF delivery stream. Ingestion price is graded and charged in 5KB increments for each GB ingested (a 3KB record is billed as 5KB, a 12KB record is billed as 15KB, etc). Unless optional features are enabled, there are no additional Kinesis Data KDF delivery fees.
Vended Logs as a Source Ingestion
The Ingestion cost is tiered and invoiced per GB ingested with no 5KB increments for records coming from Vended Logs.
Format Conversion
Depending on the number of GBs ingested in 5KB increments, you can allow the conversion of JSON to Apache Parquet or Apache ORC format at a per-GB cost.
Conclusion
- In this article, we learned about Amazon Kinesis Data Firehose. The Kinesis streaming data platform includes Kinesis Data Firehose. You do not need to use Kinesis Data Firehose to build applications or manage resources in this.
- After creating your delivery stream, you can modify its configuration using UpdateDestination or the Kinesis Data Firehose console.
- A record can be up to 1,000 KB in size of the record in the Kinesis Data Firehose delivery stream.
- Data is delivered to Amazon Redshift, Amazon Elasticsearch Service, and Amazon Simple Storage Service (S3) buckets via Amazon Kinesis Firehose. To improve security and reduce the amount of storage space required, Kinesis Firehose may batch, compress, and encrypt data.
- The developer must construct a delivery stream using either the Firehose console or an API to use Amazon Kinesis Firehose. The delivery stream transfers data from the source to the designated destination.
- There are no up-front expenses with Amazon Kinesis Firehose. The resources consumed and the amount of data that Amazon Kinesis Firehose ingests are charged to an AWS user.