Amazon Kinesis Data Streams
Overview
Data that is continuously created from many sources, such as a website's log files or the site statistics on an e-commerce site, is known as stream data.
The size and significance of these data increase at the same rate as system traffic. The abundance of data sources in today's environment is causing data to proliferate at an accelerating rate. It could contain logs, click streams, sensor data from Internet of Things (IoT) devices, etc.
Additionally, it could be necessary to analyze and store this data in real time or very close to it. In this case, streaming data services are relevant. They are anticipated to send data, and it could be necessary to create use cases based on this data to analyze and deliver results using machine learning algorithms in real-time. It has become crucial for growing services to offer data stream services on cloud services. This is where AWS Kinesis Data Streams comes into the picture.
What are Amazon Kinesis Data Streams?
Amazon Kinesis Data Streams provide a scalable, cost-effective, and long-lasting streaming data solution. Numerous sources, including internet browsing history, database event streams, banking transactions, social media feeds, and IT logs use location-tracking events to collect gigabytes of data per second. With the acquired data accessible in milliseconds, real-time monitoring, anomaly detection, and dynamic pricing are all feasible.
AWS offers a group of streaming services under the name Amazon Kinesis. There are four services accessible right now. These include Kinesis Data Analytics, Kinesis Data Analytics Firehose, Kinesis Data Streams, and Kinesis Video Streams.
What Can You Do With Kinesis Data Streams?
Real-time data collection and aggregation are possible using Kinesis Data Streams. Examples of data include IT infrastructure logs, server logs, social media, market data feeds, and internet clickstream data. In this type of data, response times are quick, and data processing is often low.
The following are some examples of how Kinesis Data Streams can be used :
Ingestion and processing of log and data feed at a faster rate
Producers can immediately put data into a stream. For instance, you may quickly process system and application logs by pushing them. In the case that the application server fails, this keeps the log data from being lost. Since data is not batch-processed on the servers before being submitted for intake, Kinesis Data Streams offers quicker data feed intake.
Real-time reporting and metrics
Data gathered into Kinesis Data Streams may be used for simple real-time reporting and analysis. Instead of waiting for batches of data to arrive, your data-processing application, for instance, may work on monitoring and reporting for system and application logs as the data is pouring in.
Real-time data analytics
Through this, real-time data and the strength of parallel processing are combined. Consider processing website clickstreams in real-time while analyzing user involvement with the site utilizing various Kinesis Data Streams apps.
Sophisticated stream processing
Applications and data streams for Kinesis Data Streams may be turned into Directed Acyclic Graphs (DAGs). Typically, this entails combining data from many Kinesis Data Streams apps into a single stream for processing by an additional Kinesis Data Streams application later on.
Amazon Kinesis Data Streams Terminology and Concepts
Kinesis Data Stream
A group of shards makes up a Kinesis data stream. A series of data records are present in each shard. Kinesis Data Streams assigns a sequence number to each data record.
Data Record
The smallest unit of data in a Kinesis data stream is called a record. A sequence number, a partition key, and an information blob—an immutable string of bytes—make up a data record. The information in the shard is not examined, interpreted, or altered in any way by Kinesis Data Streams. A data blob may be as large as 1 MB.
Shard
An individual series of collected data in a stream is referred to as a "shard." One or more shards, each of which offers a fixed unit of capacity, make up a stream. Each shard may support up to 1,000 records per second for writes and up to 5 transactions per second for reads, with a combined maximum data read rate of 2 MB per second, and a combined maximum data write rate of 1 MB per second (including partition keys). The total capacities of the stream's shards represent the stream's overall capacity. You can adjust the number of shards assigned to your stream as your data rate rises.
Capacity Mode
- The management of capacity and how you are billed for using your data stream are both governed by the data stream capacity mode. Kinesis Data Streams offers two methods for your data streams: provided and on-demand.
- On-demand mode: In this mode, the clusters are automatically managed by Kinesis Data Streams to give the required throughput. Kinesis Data Streams seamlessly meets the throughput requirements of your workloads as they ramp up or down, and you pay only for the actual throughput you use.
- Provisioned mode: In this specified mode the data stream's number of shards must be specified. The sum of a data stream's shard's capacities represents the stream's overall capacity. The number of shards in a data stream can be changed as needed, and we will be paying fees for the additional shards used hourly.
Retention Period
The duration of access to data records after they have been introduced to the stream is known as the retention period. The default retention time for a stream is 24 hours after it is first created. The IncreaseStreamRetentionPeriod action allows you to extend the retention time up to 8760 hours (365 days), while the DecreaseStreamRetentionPeriod operation allows you to shorten it to at least 24 hours.
Producer
Records are added by producers to Amazon Kinesis Data Streams. A producer is something like a web server that sends log data to a stream.
Consumer
Consumers get records from Amazon Kinesis Data Streams and process them. These consumers are Amazon Kinesis Data Streams Applications.
Fan-Out Consumers
- Shared fan-out consumers: If more than one user is listening to the same stream, the entire amount of available bandwidth is shared among all users. A Shard offers 2MBps of read bandwidth, for instance. The total amount of accessible bandwidth for a stream with 10 shards is 20 mbps. Each consumer will only receive a maximum of 5 mbps if there are 4 of them.
- Enhanced fan-out consumers: If more than one user is listening to the same stream, the entire amount of available bandwidth is shared among all users. A Shard offers 2MBps of read bandwidth, for instance. The total amount of accessible bandwidth for a stream with 10 shards is 20 mbps. Each consumer will only receive a maximum of 5 mbps if there are 4 of them.
You may build intricate topologies that process data in real-time by using the output of a Kinesis Data Streams application as the input for another stream. Data may also be sent from an application to several other AWS services.
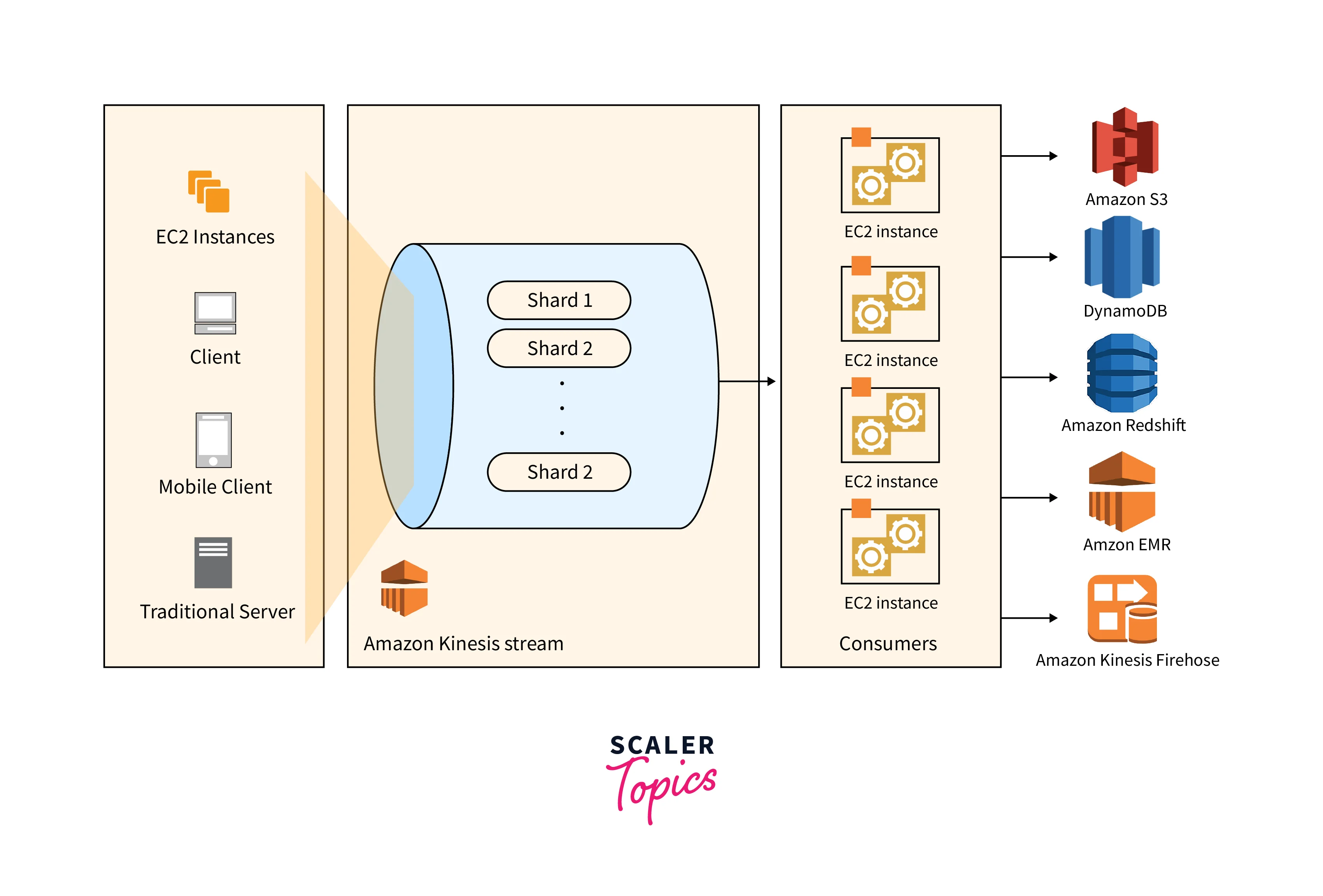
Partition Key
Within a stream, data is grouped by shard using a partition key. The data records that make up a stream are divided into several shards using Kinesis Data Streams. It determines which shard a specific data record belongs to using the partition key which is linked to each data record. Partition keys are Unicode strings with a 256-character maximum length per key. The hash key ranges of the shards are used to map related data records to shards and to map partition keys to 128-bit integer values using an MD5 hash algorithm. An application must give a partition key when adding data to a stream. Throughout the Shard's lifetime, a record with a specific Partition Key is assigned to that Shard. This is how the Shard maintains the order of its records.
Sequence Number
Within each shard, each data record has a sequence number that is distinct for each partition key. Kinesis Data Streams assigns the sequence number after you write to the stream with client.putRecords or client.putRecord. The size of the sequence numbers increases with the interval between write requests.
Kinesis Client Library
Your application is built with the Kinesis Client Library to support fault-tolerant data consumption from the stream. Every shard has a record processor running and processing it, courtesy of the Kinesis Client Library. Data reading from the stream is also made simpler by the library. Control data is kept in an Amazon DynamoDB database by the Kinesis Client Library. To handle data, each application gets its table.
Application Name
An Amazon Kinesis Data Streams application is identified by its name. Every one of your apps has a unique name exclusive to the AWS account and Region it utilizes.
Server-Side Encryption
Sensitive data can be automatically encrypted by Amazon Kinesis Data Streams as a producer inputs it into a stream. Kinesis Data Streams encrypts data using AWS KMS master keys.
Shard States
A shard can have the following states in its lifetime:
- OPEN: A shard's initial condition after being put into service. In this condition, records can be added to and read from the system.
- CLOSED: This indicates that the shard is no longer updated with new data records. Instead of being uploaded to this shard, data records are now being uploaded to a child shard. However, for a little period, data records may still be accessed from the shard.
- EXPIRED: The parent shard's data records are no longer available once the stream's retention time has passed. At this point, the shard itself transitions to an EXPIRED state.
Batching
Instead of doing the operation repeatedly on each item, batching consists of performing a single action on several things. Sending a record to Kinesis Data Streams is the action in this situation, and the "item" is a record. In a non-batching scenario, you would put each record in its own Kinesis Data Streams record and transmit it to Kinesis Data Streams using a single HTTP request. Each HTTP request may now transport numerous records, rather than simply one, thanks to batching.
Aggregation
The term "aggregation" describes the placement of several records in a single Kinesis Data Streams record. Customers can boost the number of records submitted each API call by using aggregate, which in turn boosts producer throughput. Record aggregation allows customers to combine multiple records into a single Kinesis Data Streams record. Customers can increase their throughput per shard as a result.
Collection
Instead of delivering each Kinesis Data Streams record in its own HTTP request, collection refers to batching many Kinesis Data Streams records and sending them in a single HTTP request using a call to the API method PutRecords. When compared to utilizing no collection, this improves performance since it eliminates the need to make several individual HTTP queries.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Features of Kinesis Data Streams
- Serverless: As it is serverless, you don’t have to bother about managing and scaling your servers. The on-demand mode further removes the need to provision or manage throughput by automatically scaling capacity when there is an increase in workload traffic. You can get started with Kinesis Data Streams with a few clicks from the AWS Management Console.
- Low latency: Make your streaming data available to various real-time analytics apps or AWS Lambda within 70 milliseconds of it being collected.
- High availability and durability: Synchronize your streaming data across three Availability Zones (AZs) in an AWS Region and store it for up to a year to provide several tiers of data loss protection.
- Dedicated throughput per consumer: Your Kinesis data stream may be connected to up to 20 consumers, each with a dedicated read throughput.
- Choose between on-demand and provisioned capacity mode: You may choose between provisioned mode's fine-grained control over capacity scaling up and down as necessary and on-demand mode's automated capacity management.
- Secure and compliant: Encrypt sensitive data in Kinesis Data Streams and use Amazon Virtual Private Cloud(VPC) to safely access it to comply with legal and compliance needs.
- Connected to more AWS services: Use connections between Kinesis Data Streams and other AWS services like Amazon DynamoDB, Amazon QLDB, Amazon Aurora, AWS Database Migration Service, Amazon Cloudwatch, AWS Lambda, Amazon Kinesis Data Analytics, Amazon Kinesis Data Firehose to construct complete applications more rapidly.
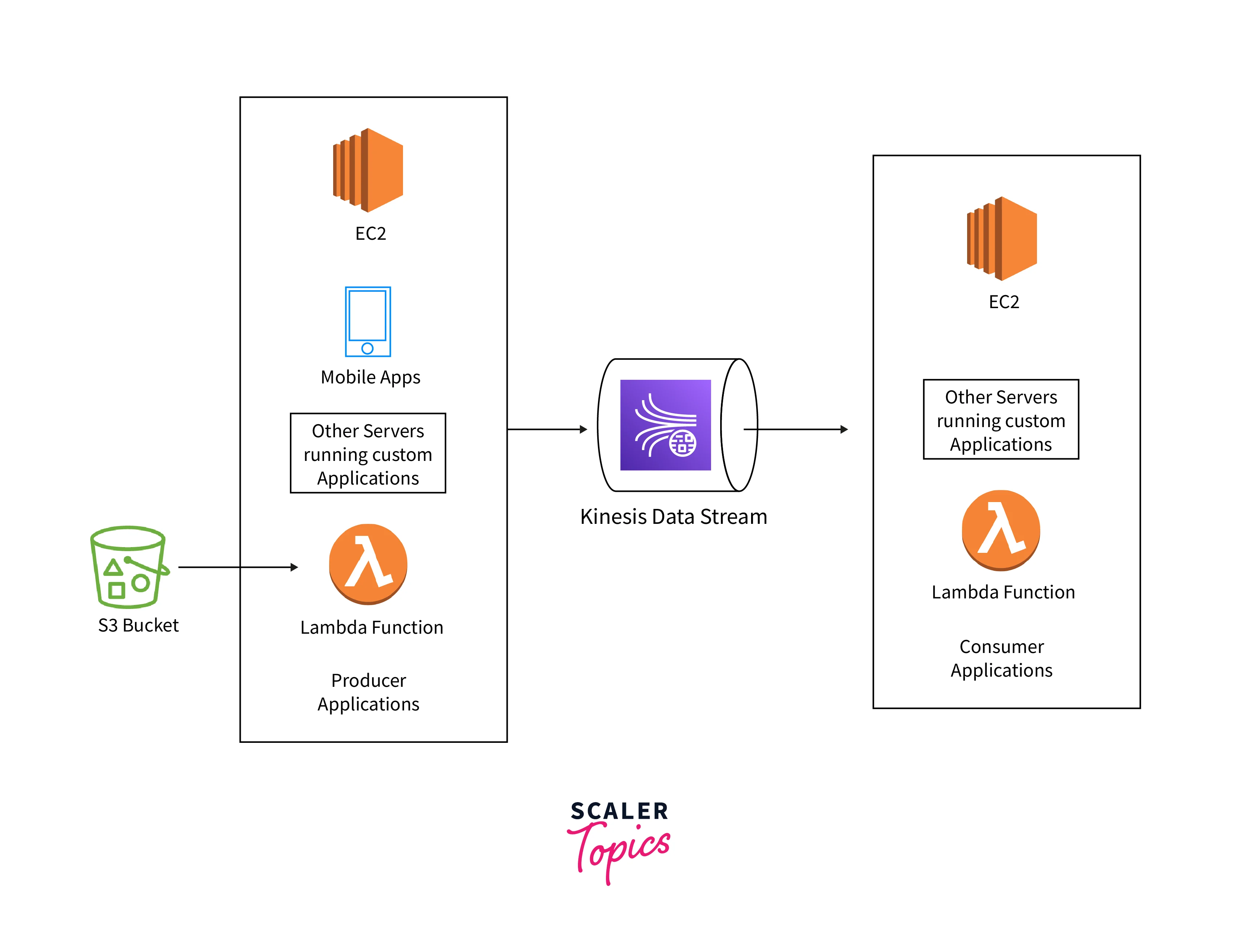
Use Cases of Kinesis Data Streams
1. Finding anomalies in signals from IoT devices
To verify that operational criteria are followed, keep an eye on any physical place in real time. For instance, at a manufacturing facility, you would need to keep an eye on a specific chemical’s temperature, pressure, and flow, self-locking doors, vacuum robots, and temperature controls could be found in a workplace. To find abnormalities, gather and analyze these data streams in real-time and adjust or investigate systems without any manual work.
2. Analyze current stock market data
This might be especially helpful in new and developing betting markets or industries where this data isn't presently easily accessible, such as NFTs and eGaming.
3. Real-time social media tracking
Track comments, tags, and more across social media sites in real time. When there is more activity than usual in a particular area, signaling a critical occurrence that warrants further examination, we may build a specific geo-grid and use streaming geo-tagged social media postings to alert.
Amazon Kinesis Data Streams Pricing
The cost of Amazon Kinesis Data Stream is based on how much is used. However, the prices change as the region changes. What this now amounts to is:
- Kinesis Processing Unit (KPU), Per Hour
- Per GB-month, Running Application Storage (50GB of running application storage is assigned per KPU)
- Durable Application Backups, Per GB-month
- For studio notebooks, Kinesis Processing Unit (KPU), Per Hour.
- Running Application Storage, Per GB-month for Studio notebooks.
Below is the example for pricing in the US East(Ohio) region:
| Pricing | |
|---|---|
| Per stream, per hour | $0.04 |
| Data ingested, per GB (Includes 24-hour retention) | $0.08 |
| Data retrievals, per GB | $0.04 |
| Enhanced fan-out data retrievals, per GB | $0.05 |
| Data stored, per GB-month (beyond 24 hours, up to 7 days) | $0.10 |
| Data stored, per GB-month (beyond 7 days) | $0.023 |
Getting Started with Amazon Kinesis Data Streams
Kinesis Data Analytics uses pay-as-you-go pricing even though it isn't included in the AWS Free Tier. You may test out Kinesis Data Analytics without making a sizable cost commitment if you're careful to begin a trial inside the parameters of the most fundamental processing processes.
The three fastest ways to get going with Kinesis Data Analytics are provided by AWS itself and include developing an application using your own IDE and Apache Flink, leveraging Amazon Kinesis Data Analytics Studio, and using SQL from the Kinesis Data Analytics dashboard.
Each of these approaches has advantages and disadvantages. You can run quick queries from the terminal, but they might not be as versatile or provide the output you want. You can build more quickly and flexibly using Data Analytics Studio, but you must consider the additional expenditures. Additionally, you'll need to be able to build an Apache Flink application from within your own IDE, which may have a longer learning curve but is the most adaptable and economical choice.
This section demonstrates how to use the AWS Command Line Interface to carry out fundamental Amazon Kinesis Data Streams operations. The processes required to insert data into and retrieve data from a Kinesis data stream will be covered, along with some basic data flow principles.
Install and Configure the AWS CLI
Install AWS CLI
See Installing the AWS CLI for comprehensive instructions on installing the AWS CLI for Windows, Linux, OS X, and Unix operating systems.
To list the choices and services available, use the command:
aws help
You will be utilizing the Kinesis Data Streams service, so use the following command to study the AWS CLI subcommands associated with Kinesis Data Streams:
aws kinesis help
The Kinesis Data Streams API is described in the Amazon Kinesis Service API Reference, and this command list corresponds to that documentation. For instance, the create-stream command and the CreateStream API action are equivalent.
The following commands for Kinesis Data Streams are included in the output of this command:
AVAILABLE COMMANDS
-
add-tags-to-stream
-
create-stream
-
delete-stream
-
describe-stream
-
get-records
-
get-shard-iterator
-
help
-
list-streams
-
list-tags-for-stream
-
merge-shards
-
put-record
-
put-records
-
remove-tags-from-stream
-
split-shard
-
wait
Configure AWS CLI
The aws configure command is the quickest method for setting up your AWS CLI installation in ordinary use. See Configuring the AWS CLI for further details.
Turn Learning into Career Growth
Perform Basic Kinesis Data Stream Operations Using the AWS CLI
This section explains how to use a Kinesis data stream in its most basic form using the AWS CLI. Make sure you are familiar with the terminologies and ideas covered above in the article.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Step 1: Create a Stream
You should build a stream first, then check to see if it was successful. To create a stream called "Foo," enter the command shown below:
aws kinesis create-stream --stream-name Foo
To monitor the stream's development, follow these instructions:
aws kinesis describe-stream-summary --stream-name Foo
You should see results that resemble the illustration below:
You don't need to worry about some of the information in this output for this tutorial. For now, the most important information is "StreamStatus": "ACTIVE," which indicates that the stream is available for use, and the details of the single shard that you requested. The list-streams command can also be used to confirm the presence of your new stream, as seen in the following example:
aws kinesis list-streams
Output:
Step 2: Put a Record
You are prepared to insert some data now that you have an active stream. In this tutorial, the most basic command, put-record, will be used to insert a single data record into the stream that contains the word "testdata":
aws kinesis put-record --stream-name Foo --partition-key 123 --data testdata
If this command is successful, the output will look somewhat like this:
Step 3: Get the Record
GetShardIterator
Getting the shard iterator for the interesting shard is necessary before you can access data from the stream. The point of the stream and shard from which the consumer (in this case, the get-record command) will read is represented by a shard iterator. The get-shard-iterator command is used as follows:
aws kinesis get-shard-iterator --shard-id shardId-000000000000 --shard-iterator-type TRIM_HORIZON --stream-name Foo
Remember that the Kinesis Data Streams API powers the aws kinesis commands, so if you're interested in learning more about any of the parameters displayed, check out the GetShardIterator API reference page. The output from a successful run will be like the example below (scroll horizontally to view the whole output):
The shard iterator is the long string of seemingly random characters (yours will be different). The shard iterator must be copied and pasted into the get command, which is displayed next. Shard iterators have a 300 second lifetime, so you should have time to copy and paste the shard iterator into the following command. Be aware that before pasting your shard iterator to the following command, you must remove any newlines. Simply run the get-shard-iterator command once more if you receive a warning that the shard iterator is no longer valid.
GetRecords
Data is obtained from the stream with the get-records command, which resolves to a call to the GetRecords method in the Kinesis Data Streams API. The place in the shard from which you want to begin reading data records sequentially is specified by the shard iterator. GetRecords returns an empty list if there are no records in the part of the shard that the iterator links to. Be aware that reaching a section of the shard that includes records may require making several calls.
The get-records command is demonstrated in the example below (scroll horizontally to view the whole command)
aws kinesis get-records --shard-iterator AAAAAAAAAAHSywljv0zEgPX4NyKdZ5wryMzP9yALs8NeKbUjp1IxtZs1Sp+KEd9I6AJ9ZG4lNR1EMi+9Md/nHvtLyxpfhEzYvkTZ4D9DQVz/mBYWRO6OTZRKnW9gd+efGN2aHFdkH1rJl4BL9Wyrk+ghYG22D2T1Da2EyNSH1+LAbK33gQweTJADBdyMwlo5r6PqcP2dzhg=
If the get-records command is successful, records for the shard you specified when you acquired the shard iterator will be requested from your stream, as in the example below (scroll horizontally to view the whole output):
Step 4: Clean Up
To free up resources and prevent unauthorized charges to your account, you should remove your stream at this point. Practice doing this whenever you create a stream that you won't be using because charges apply to each stream whether you are pushing or receiving data through it or not. The clean command is straightforward:
aws kinesis delete-stream --stream-name Foo
You might want to use describe-stream to monitor deletion progress since success produces no output:
aws kinesis describe-stream-summary --stream-name Foo
If you run this command shortly after the delete command, you'll probably see an output that looks something like this:
describe-stream will return a "not found" error after the stream has been completely deleted:
A client error (ResourceNotFoundException) occurred when calling the DescribeStreamSummary operation: Stream Foo under account 123456789012 not found.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Benefits of Using Kinesis Data Streams
-
Simple to use: Within seconds, a Kinesis stream can be produced. The Kinesis Producer Library (KPL) and Kinesis Client Library(KCL) enable easy addition of data to your Kinesis stream and the creation of Kinesis Applications to handle it.
-
Cost Efficient: Users of Amazon Kinesis Data streams only need to pay for the amount of data they transmit over the service, as well as any necessary data format conversion fees if any.
-
Parallel processing: You may run numerous Kinesis Applications concurrently on the same stream thanks to Amazon Kinesis Data Streams. For instance, you may have one application doing real-time analytics while another uses the same Amazon Kinesis stream to deliver data to Amazon S3.
-
Serverless data transformation: Because it is serverless, you don't have to bother about setting up and managing servers; the underlying infrastructure is handled and automated in the background, allowing you to concentrate on your data analytics rather than server maintenance.
-
Services and providers integrated with AWS: Amazon Kinesis Data Stream is integrated with Amazon S3, Amazon Redshift, and Amazon Elasticsearch Services.
Kinesis Data Streams vs SQS
| Points of Difference | Amazon Kinesis Data Streams | Amazon SQS |
|---|---|---|
| WORKING | Amazon Kinesis Video Streaming, Data Stream, Data Firehouse, and Data Analytics. | Producer and consumer architecture. |
| FEATURES | Real-time processing and easy to use. | Message timer, delay queue, and unlimited queues. |
| ADVANTAGES | Fast, management, and scalable. | Reliable secures sensitive data and eliminates administrative overhead. |
| DURABILITY | Up to retention period - deleted on expiry | Up to retention period - deleted by consumer |
| MAX DATA RETENTION | 7 Days | 14 Days |
| MESSAGE SIZE | 1MB | 256KB - Can be extended using SQS Extended Client |
| REPLAY SUPPORTED | Yes | No |
Conclusion
- In this article we learned about Amazon Kinesis Data Streams and its different use cases which involved finding anomalies in signals from IoT devices and analyzing real-time stock market data.
- This article focussed on getting started on creating a Kinesis Data Stream which mainly involved two steps. Firstly we need to Install and Configure the AWS CLI and then we need to perform some basic operations like create a stream, delete a stream, etc
- This article also explained the pricing of the Amazon Kinesis Data Streams and how it depends region-wise
- We also discussed how Kinesis Data Streams is different from Amazon SQS. The point of difference included Message size, Maximum Data retention, durability, and key features.
- Overall Amazon Kinesis Data streams are dynamic, serverless, and very easy to use.