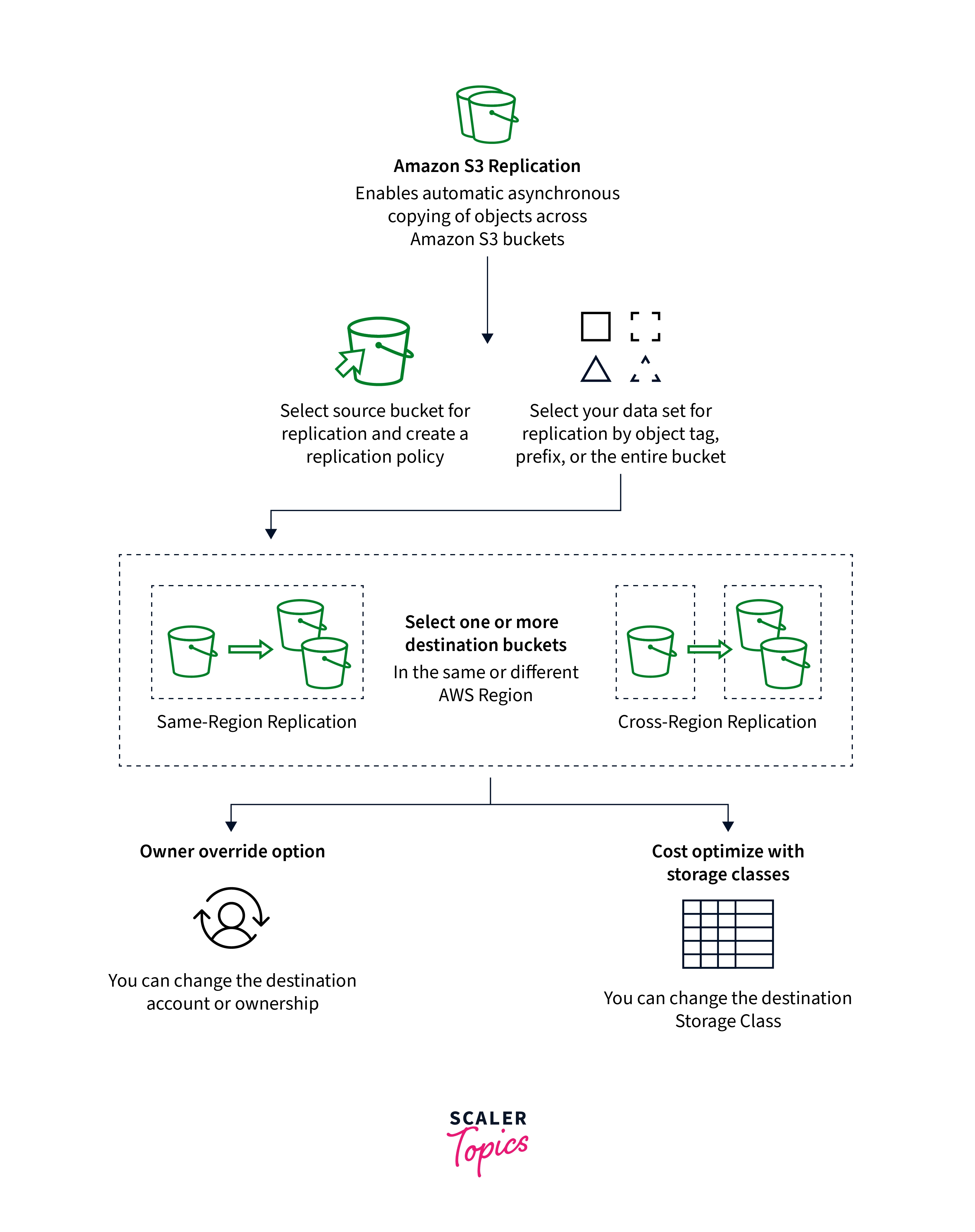
Replication in S3
Overview
Data replication in S3 is the automated transferring of data from one S3 bucket of their choosing to some other bucket without interfering with other operations. Having S3 replication enabled, users may use a technique called Cross Area Replication to replicate data between buckets located in the same or different regions. Additionally, AWS S3 retains metadata and enables the user to store and track changes to information about the origin, alterations, and other characteristics of the data source.
Why Use Replication?
Replication can assist with the following tasks:
-
Copy Items While Keeping Metadata
Replication in S3 allows you to create replicas of the objects which keep full metadata, including the unique object creation timings and version IDs. This feature is useful if you need to confirm that your duplicate is the same as the original item.
-
Replicate Items Across Storage Class
Replication in S3 may be used to put things straight to AWS S3 Glaciers Flexible Retrieval, S3 Glacier Deep Archives, or the other storing class in the target buckets. Users could also duplicate the content to a similar storage class and utilize destination bucket lifecycle policies to shift the objects to cooler storage classes when they age.
-
Hold Object Duplicates With Separate Ownership
Irrespective of who holds the source item, users may instruct AWS S3 to shift the duplicate owner to the AWS account which controls the destination buckets. This is known as the user-overriding option. That feature allows you to limit accessibility to object replicas.
-
Storage Items Across Several AWS Regions
Users can create several destination buckets across various AWS regions to guarantee regional variances for where the data is stored. This functionality could help you satisfy certain regulatory obligations.
-
Objects Can be Replicated in 15 Minutes
Users may be using Replication in S3 Time Control to duplicate the data within a specific AWS Region or even across separate Regions inside a predictable time frame (S3 RTC). During 15 minutes, S3 RTC replicates 99.99 percent of all new items stored in Amazon S3.
-
Sync Buckets, Reproduce Existing Objects, And Duplicate Items That Have Repeatedly Failed or Been Replicated
Using Batch Replications in S3 as an on-demand replications operation to sync buckets and reproduce existing items.
-
Replication Of The Object And Failure Over To Buckets In That Other AWS Regions
Employ two-way replication rules before installing Amazon S3 Multi-Region Point of access failover controls to maintain all metadata and object in sync throughout the bucket throughout data replication. Two-way replication rules assist guarantee the data uploaded to the S3 buckets to which traffic failures are duplicated to the original buckets.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
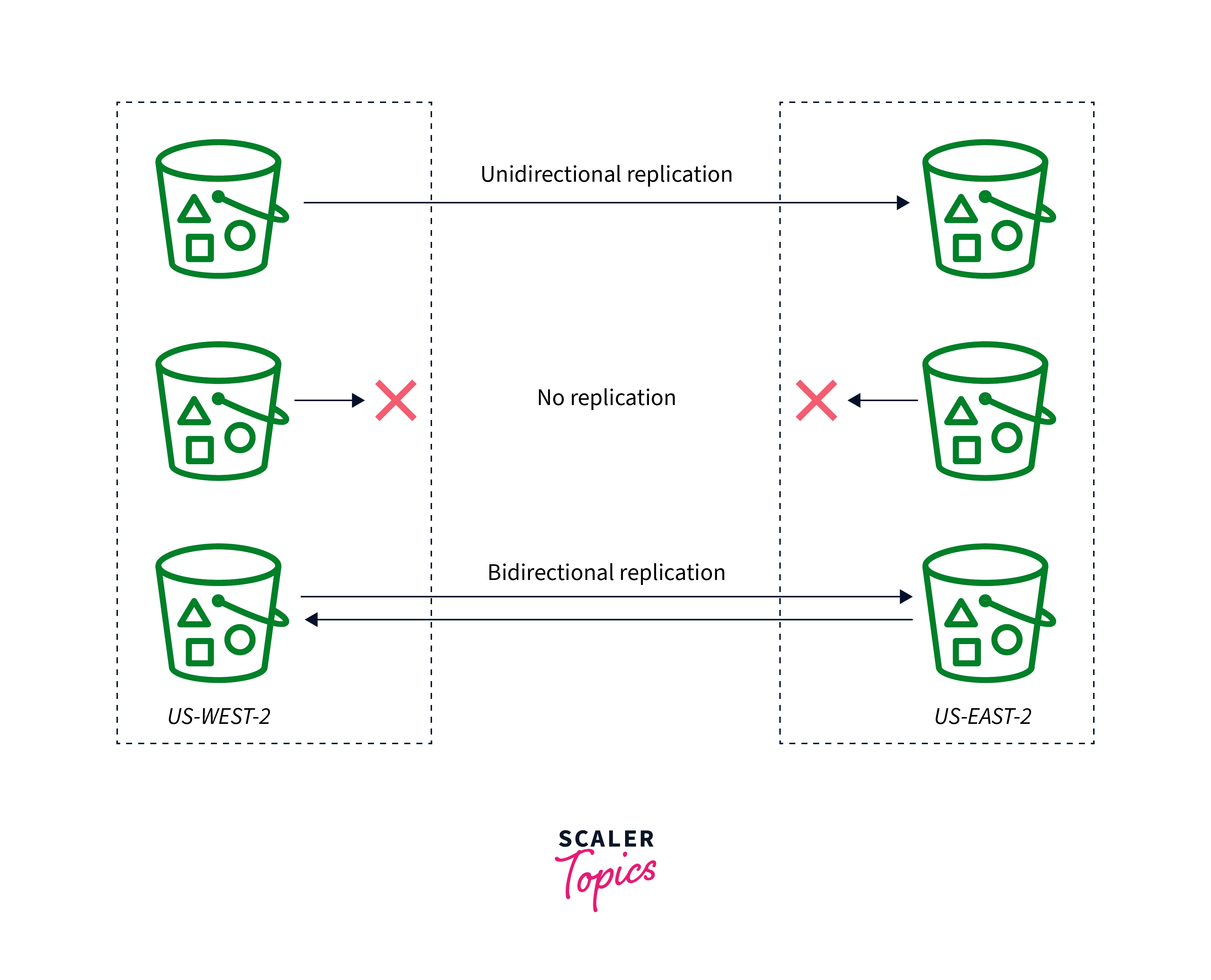
Types of Replication
When to Use Cross-Region Replication
S3 CRR is a technique for replicating items between AWS S3 buckets in various AWS regions. CRR could assist customers with the ones that follow:
Comply With All Regulations
While AWS S3 defaults to storing the data across many geographically separated AZs, compliances may compel users to store information at an even larger distance. Using Cross-Region Replication to duplicate data across remote AWS Region to meet these criteria.
Reduce Latency
When our consumers are all in different geographic areas, then may reduce latency in object retrieval by storing object duplicates in AWS Region which is nearer to the consumers.
Boost Operational Effectiveness
When users have computing clusters in multiple AWS regions which evaluate the same collection of objects, you may want to save object duplicates.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
When To Use Same-Region Replication
SRR is used to replicate objects across the Amazon S3 bucket within the same AWS Region. SRR could assist with the following tasks:
Collect Logs Into The One Bucket
If users keep a log in a different bucket or across different accounts, one can quickly duplicate logs into a single, in-Region bucket. This enables more efficient log handling in a single place.
Set Up Live Replications Between The Production And Test Accounts
When the clients have production and a test account with the same data, they can duplicate objects between the two while preserving object information.
Follow Data Sovereignty Laws
You may be needed to keep numerous copies of your information in different AWS accounts within the same Region. When compliance requirements prevent data from leaving your nation, Same-Region Replication can assist you in automatically replicating vital data.
When To Use S3 Batch Replication
As an on-demand alternative, Batch Replication copies existing items to other buckets. These tasks, unlike live replication, can be executed as required. Batch Replications can assist users with the following tasks:
Copy Existing Objects
Batch Replication in S3 may be used to duplicate items that have been contributed to the buckets prior Same-Region Replications or Cross-Region Replications being enabled.
Reproduce Formerly Failed To Replicate Object
The Batch Replication task could be filtered to try to duplicate items having a replication state of FAILED.
Replicate Previously Duplicated Object
You may be needed to keep numerous copies of your information in different AWS accounts or AWS Regions. Existing items can be replicated to newly additional destinations using Batch Replication.
Replicate Objects That Were Produced By a Replication Rule
Objects in destination buckets are replicated using replication settings. Object copies may only be duplicated via Batch Replication.
Requirements For Replication
Replication necessitates the following:
-
A source bucket host's accounts should have both the sources and destinations AWS Regions activated. The destination buckets owner's account should have the destination Region enabled.
-
Versioning should be enabled both in the destination and source buckets.
-
Aws S3 should be granted authorization to duplicate things on their behalf from the source buckets to the destination buckets or buckets.
-
If indeed the object inside the buckets is not owned by the owners of the source buckets, the object owners must provide the bucket user READ and READ ACP permissions through the object ACL.
-
If the S3 Object Lock is enabled inside the source buckets, it should also be enabled in the destinations bucket.
What Does Amazon S3 Replicate?
AWS S3 replicates the foregoing by default:
-
Objects are produced once a replicating config is added.
-
Objects that are not encrypted.
-
Object encrypted using customer-supplied keys, objects encrypted at rest using AWS S3 managed keys, and objects encrypted using AWS KMS keys.
-
Object info is transmitted from the source object to the copies.
-
Only items in the source buckets that the bucket owners have read and ACL rights.
-
Objects ACL update, provided users tell AWS S3 to alter replica ownership whenever the destination and source bucket is not held by the identical account.
-
It may take some time for AWS S3 to synchronize the two ACLs. This change in ownership primarily affects items generated following adding a replicating configuration to the buckets.
-
Object tag, if present.
-
If applicable, S3 Object Lock retention information.
-
When AWS S3 replicates items with retention data, it provides the very same retention rules to the replicas, disregarding the destination bucket's preset retention term.
-
If users replicate to the destinations bucket with a default retention period but don't apply retention control to the objects in the source buckets, then object replica will be subject to the destinations bucket's standard retention period.
Turn Learning into Career Growth
Setting Up Replication
Add a replication in S3 in AWS config to the source buckets to enable SRR or CRR. AWS S3 is instructed to duplicate the given items by the settings. The following information must be included in the replication configuration:
The Buckets Of Destination
where you desire AWS S3 to replicate the objects is in the bucket.
The Objects Users Wish To Replicate
Users could replicate every object in the source buckets or just some of them. A key identifier prefixed, one or more object tags, or perhaps both can be used in the configuration to specify a subset.
When users set replication rules to replicate only objects only with key identifier prefixed Tax/, AWS S3 replicates objects with keys like Tax/doc1 and Tax/doc2. It doesn't however, reproduce objects with both the key Legal/doc3. When users supply a prefixed as well as one or even more tags, AWS S3 replicates just the objects that contain the specified key prefix and tag.
Classification Of Replica Storage
AWS S3 saves objects copies with the same storage type as the original object by default. For the replicas, you can provide various storage categories.
Ownership Of Replicas
AWS S3 thinks about how objects replicated are still held by the original object's user. As a result, when it replicates an object, it also copies the associated object ACL or S3 Object Ownership settings. Users may set up a replicate to alter the proprietor of a replica towards the AWS accounts that own the destination bucket if the destinations and source bucket are held by a separate AWS account.
Using REST API, AWS SDKs, CLI, and the S3 console may all be used to configure the replica.
Replicating Existing Objects With S3 Batch Replication
-
Batch Replication in S3 allows users to replicate objects which existed before such a replica config had been in existence, already replicated objects, and objects that failed replica.
-
The Batch Operation task is used to accomplish this. Live replica, on the other hand, continually and dynamically duplicates new items across the AWS S3 bucket. To get started using Batch Replica, users can do the following:
-
Start a fresh batch replica job for specific replica rules or destination - While defining the very first rules in a new replica config or adding a destination to an existing configuration using the AWS Management Console, users can generate a one-time Batch Replication operation.
-
Make a new Batch Replica job with AWS S3 Batch Operation using the AWS SDKs, AWS CLI, or even the AWS S3 console for an existent replica setup.
Additional Replication Configurations
This section discusses extra replica configuration options in AWS S3.
-
Replica metrics and S3 event alerts are used to track progress.
-
Utilizing AWS S3 Replica Time Control to meet compliances criteria
-
Duplicating remove markings across the bucket
-
AWS S3 replicas alteration sync is used to replicate metadata updates.
-
Updating the ownership of the replicas
-
Object replication via server-side encryption
-
Amazon S3 delivers the x-amz-replication-status header with the value REPLICA when you request an item from a destination bucket and the object in your request is a replica that Amazon S3 made.
-
The x-amz-replication-status header behaves differently when items are replicated to several destination buckets. When replication is successful to all destinations, the source object's header simply returns the value COMPLETED. Up till all destinations' replication is finished, the header's value is PENDING. The header returns FAILED if one or more destinations experience replication failure.
Getting Replication Status Information
-
Users may use the replication in S3 in AWS state to determine the current state of replicating objects. The source object's replicating status might be PENDING, COMPLETED, as well as FAILED. A replica's replication state would show REPLICA.
-
Users configure the replication in S3 in AWS on source buckets, and AWS S3 replicates items to destination buckets. If you use the GET objects or HEAD objects commands to request the objects or object information from one of these buckets, AWS S3 responds with the following response header:
-
If such objects in the request are qualified for a replica, AWS S3 responds with the x-amz-replication-status flag whenever users request it from the source buckets.
-
As an illustration, let's say users instruct AWS S3 to replicate all objects with the key named prefixed TaxDocs by specifying the object prefixed TaxDocs in the replica settings.
-
It will replicate any files users upload with this key named prefixed, such as TaxDocs/document1.pdf.
-
AWS S3 responds to object requests with this key named prefixed by returning the x-amz-replication-status headers only with values PENDING, COMPLETED, or FAILED for the object's replica state.
Verify The Following in The Replication Settings on The Source Bucket:
-
The destination buckets' Amazon Resource Names (ARN) are accurate.
-
The prefix of the key name is accurate. For instance, only objects with key names like Tax/document1 or Tax/document2 are duplicated if the settings are set to replicate items with the prefix Tax. There is no replication of an object with the key name document3.
-
The state is activated.
-
Check to see whether any buckets have not had their versioning halted. Versioning has to be turned on in both the source and destination buckets.
-
Users must include the s3
method in the permission policies linked to the IAM role unless you're giving the buckets owners possession of the object. The IAM role you defined in the replication setup, which enables AWS S3 to accept and replicated objects on their behalf, is this one. -
Check to see if the bucket owners do have a buckets policy just on destination buckets that allows the owners of the source buckets to replicate objects if the destination buckets are held by other AWS accounts. Setting replications while the source and destination buckets are held by separate accounts provides an example.
-
Replication may not have occurred if an item replica showed up in the target bucket due to one of the following factors:
-
The objects in source buckets that have a duplicate made by some other replica config are not replicated by AWS S3. For example, AWS S3 won't replicate objects replicas in bucket B to bucket C if you establish a replicating config through bucket A to bucket B to bucket C.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Troubleshooting Replication
-
Have used these troubleshooting suggestions to locate and resolve problems if, after configuring replication in S3 in AWS, object replicas do not show up in the target bucket.
-
Most things duplicate in 15 minutes or less, but occasionally it might take up to two hours. Rarely, the replication process might go more slowly.
-
The dimension of the object and the destination and source Region pairs have an impact on how long it takes AWS S3 to replicate an object. Replica might take many hours for huge items.
-
Pause a bit before verifying to see whether the massive object being cloned shows up at the destination. The replication in the S3 status of the source item may also be checked.
-
The replication in the S3 process has not been finished by Amazon S3 if the item replication state is PENDING. Examine the replica config specified on the source buckets if the object's replication state is FAILED.
-
The owner of source buckets may authorize the upload of objects from other AWS accounts. The objects generated by other accounts do not by default have rights granted to the owner of the source bucket. Only the items for which the source buckets user has access permissions are replicated by the replication settings.
-
Other AWS accounts may be given conditional permission to create objects by the owner of the source bucket, subject to those objects' specified access rights. Granting cross-account capabilities to upload things while ensuring the bucket owner has complete control is a sample policy.
-
Let's say you add a rule to the replication configuration that replicates only items with a certain tag. In this scenario, for AWS S3 to replicate the object, you must specify the precise tag key and value when creating the object. Amazon S3 does not duplicate an item if it is first created and then the tag is added to an already-existing object.
-
Users may use a Batch Copy task to replicate the source object in situ and re-replicate these objects. When such objects are replicated into position, a newer version of such object is created in the source buckets, and replication is instantly started to the destinations.
-
As standard, remove markers placed to the source buckets that aren't replicated while replication from the separate AWS accounts.
-
Objects are kept in the AWS S3 Glacier Deep Archive and Flexible Retrieval storage classes.
-
Object in the source buckets that cannot be replicated by the bucket operator due to insufficient permission.
-
Modifications to sub-resources at the buckets levels.
-
For example, recent changes to a source bucket's life cycle settings or notifications settings are not carried to the destination buckets. With this function, the destination and source buckets settings might be varied.
-
operations that the life cycle configuration takes.
-
For example, AWS S3 produces a remove marker for the expired object but does not duplicate such marks if the life cycle setting is only activated on the source buckets. Set the same lifetime setting for both the destination and source bucket if you'd like the life cycle configurations to be enforced on both.
Limitations of AWS S3 Replication Using Replication Rule
AWS S3 doesn't replicate the below by default:
-
Objects in the source buckets that are replicas from some other replication in S3 rules. Assume users set up a replica with buckets A as the source and bucket B as the destination.
-
Assume you create an additional replication in the S3 setup, this time with buckets B as the sources and buckets C as the destinations.
-
Things in bucket B that are clones of the object in bucket A aren't replicated in bucket C in this situation.
-
Use batch replicating to replicate a replica of an object.
-
Source buckets object that has previously been replicated to a different area For instance, AWS S3 won't duplicate the items after you modify the destination buckets in an established replication setup.
-
Employ batch replicating to reproduce already replicated items.
-
Trying to replicate deleted objects using the version ID of objects from destination buckets is not supported via batch replica.
Conclusion
-
Customers of Amazon Simple Storage Service (S3) can use Replication in S3, a fully-managed capability. To help you cut expenses, preserve your data, and comply with legal requirements, it can automatically clone S3 objects.
-
You may deploy disaster recovery, manage compliance, cut down on latency, and enforce security with the aid of CRR. Users can duplicate objects with their associated information and object tags onto different Amazon Regions (ARs) using this functionality.
-
Within the same AR, AWS S3 Same-Region Replication (SRR) offers completely automatic replication of S3 items to a different AZ.