What is Data Structure?

A data structure serves as a foundational framework for efficiently organizing and managing data within a computer system. It encompasses both the conceptual representation of data and its practical implementation in computer programs, ensuring that information can be accessed, manipulated, and utilized effectively.

Why do we need to Learn Data Structures?
-
Increasing Complexity and Data Volume:
- Modern applications face growing complexity and larger data volumes.
- This leads to challenges in tasks such as data searching, processing speed, and handling multiple requests.
-
Role of Data Structures:
- Data Structures offer diverse methods for efficiently managing, organizing, and storing data.
- They facilitate easy traversal of data items, aiding in effective data handling.
-
Benefits Provided by Data Structures:
- Efficiency: Enhances performance by optimizing data operations, improving processing speed, and reducing resource consumption.
- Reusability: Structures can be utilized across various applications, saving development time and resources.
- Abstraction: Allows users to focus on high-level concepts without worrying about implementation details, enhancing ease of use and understanding.
Types of Data Structure
Primitive data structure
The primitive data structure, also referred to as built-in data types, can only store data of a single type. This includes integers, floating points, characters, pointers, and similar types.
Non-Primitive Data Structure
Non-primitive data structures, unlike their primitive counterparts, can store data of multiple types. Examples include arrays, linked lists, stacks, queues, trees, and graphs. These are often termed derived data types.
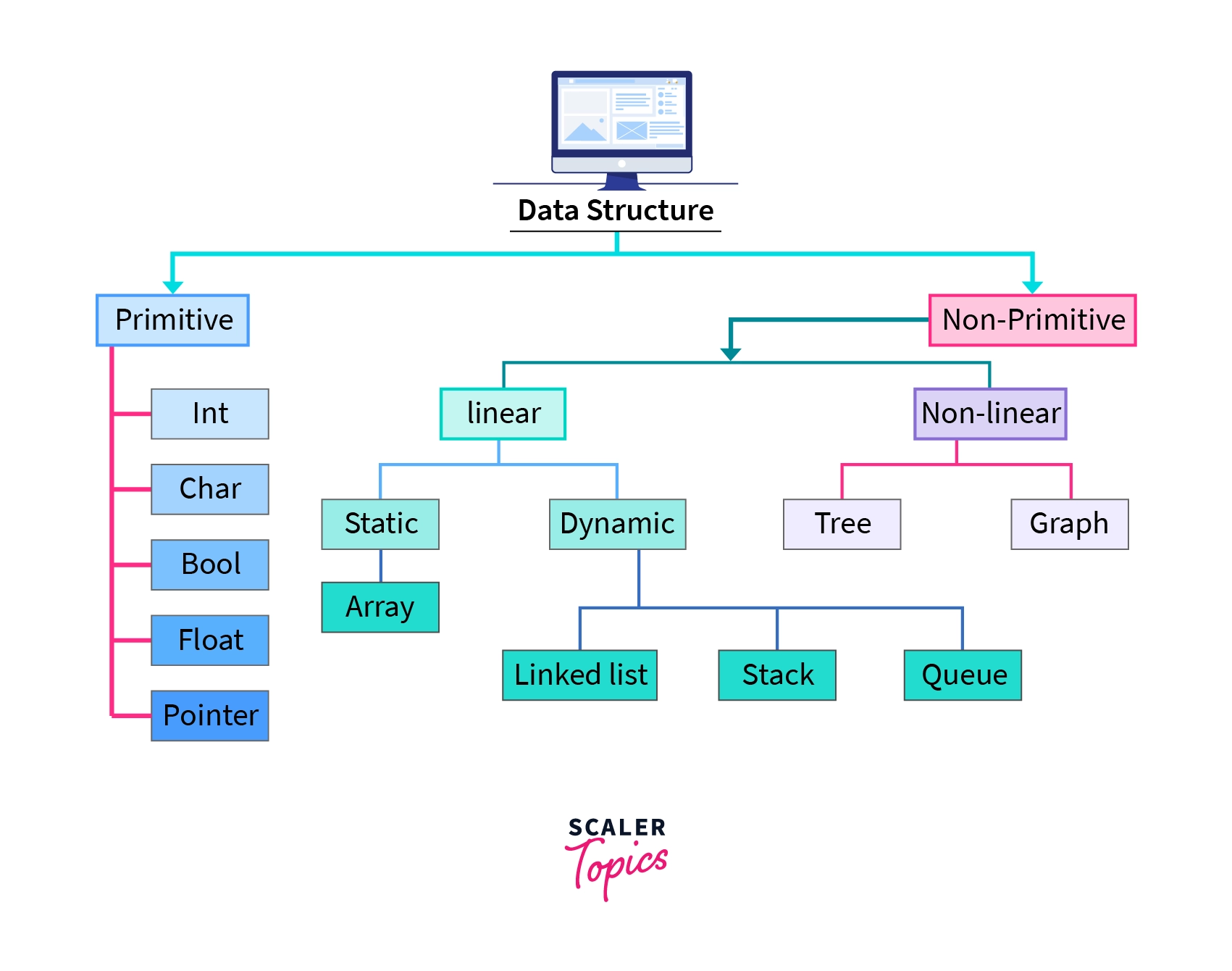
As evident, non-primitive data structures are further divided into two categories:
- Linear Data Structures
- Non-Linear Data Structures
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
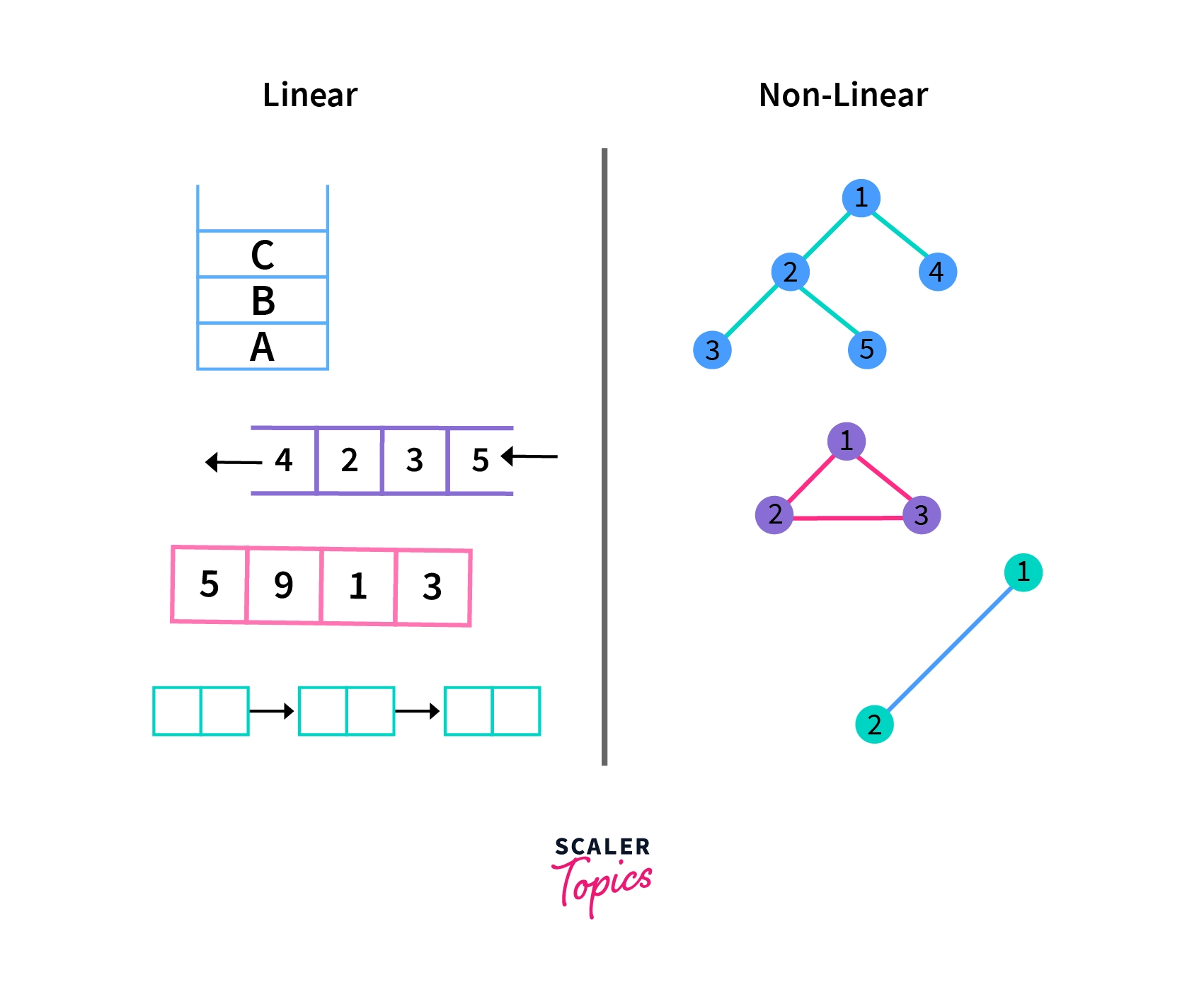
Linear Data Structure
A Linear Data Structure maintains a straight-line connection between its data elements, where each element is linked to its predecessors and successors, except for the first and last elements. However, the physical arrangement in memory may not follow this linear sequence.
Linear Data Structures are categorized into two types based on memory allocation.
Static Data Structures
Static Data Structures have a predetermined size allocated during compilation, and users cannot alter this size after compilation. However, the data stored within these structures can be modified. An example of a Static Data Structure is an Array, which has a fixed size and allows for data modification after creation.
Dynamic Data Structures
Dynamic Data Structures are those whose size can change during runtime, with memory allocated as needed. Users can modify both the size and the data elements stored within these structures while the code is executing. Examples of dynamic data structures include Linked Lists, Stacks, and Queues.
Types of Linear Data Structures
Array
An array is a data structure that holds a group of items in contiguous memory locations. Items of the same type are stored together, allowing for easy retrieval of elements using an index. Arrays can have a fixed size, where the number of elements is predetermined, or a flexible size, where the length can change during runtime.

Stack
A stack follows the Last-In, First-Out (LIFO) principle, where elements are added and removed from the top. It resembles a stack of plates, allowing for operations like push (adding an item), pop (removing the top item), and peek (viewing the top item without removing it). Stacks are used in diverse applications like function call management, expression evaluation, and backtracking algorithms. They offer simplicity and efficiency in managing data with a strict order of access. Key operations include push, pop, peek, isEmpty (checking if the stack is empty), and size (determining the number of elements).

Queue
A queue is a First-In, First-Out (FIFO) data structure where elements are added to the rear and removed from the front. It resembles a line of people waiting for service, ensuring that the first element added is the first to be removed. Key operations include enqueue (adding), dequeue (removing), and checking whether the queue is empty or its size. Queues are used in process scheduling, task management, and breadth-first search algorithms for orderly data processing.

Linked List
A linked list is a linear data structure consisting of nodes, where each node holds data and a reference to the next node. Unlike arrays, linked lists do not need contiguous memory allocation. They offer dynamic size adjustment and efficient insertion and deletion operations. Key types include singly linked lists, where nodes point to the next node, and doubly linked lists, where nodes have references to both the next and previous nodes. Linked lists are versatile and commonly used in implementing various data structures and algorithms, such as stacks, queues, and hash tables.

Non-Linear Data Structures
Non-linear Data Structures don't put data in a straight line. Instead, they organize data with a hierarchy, like a family tree. Adding or removing data isn't straightforward, unlike in a list. Examples include trees and graphs, used for organizing complex relationships, like computer files or social networks.

Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Types of Non-Linear Data Structures
Tree
A tree organizes items in a hierarchical manner, like branches stemming from a trunk. Each node holds a value, with parent nodes connected to child nodes. At the top is the root node, the "ancestor" of all other nodes in the tree.

Graph
A graph arranges items in a non-linear way, resembling a network of connections. It consists of nodes (vertices) and lines connecting them (edges). Graphs are handy for modeling real-world systems like computer networks.

Basic Operations of Data Structures
Search Operation
Searching in a data structure involves looking for specific data elements that meet certain conditions. This could mean finding items like names, numbers, or other information within a set of data. For instance, in a list of students, we might search for those who scored above a certain grade.
Turn Learning into Career Growth
Traversal Operation
Traversing a data structure involves going through each data element one by one to manage or process it. For instance, if we want to print the names of all employees in a department, we need to traverse the list of employees to access each name and print it.
Insertion Operation
Insertion means adding new data elements to a collection. For example, when a company hires a new employee, we use insertion to add their details to the employee records.
Deletion Operation
Deletion involves removing a specific data element from a list. For instance, when an employee leaves their job, we use the deletion operation to remove their name from the employee records.
Update Operation
The Update operation enables us to modify existing data within the data structure. By specifying conditions, similar to the Selection operation, we can update specific data elements as needed. For example, we might use the Update operation to change the salary of an employee based on their performance review.
Sorting Operation
Sorting involves arranging data elements in either ascending or descending order, depending on the application's requirements. For example, we might sort the names of employees in a department alphabetically or determine the top performers of the month by arranging employee performance scores in descending order and extracting details from the top three.
Merge Operation
Merge involves combining data elements from two sorted lists to create a single sorted list. This process ensures that the resulting list maintains the sorted order of the original lists.
Applications of Data Structures
Data structures serve critical roles across diverse computer programs and applications:
- Databases: Efficient organization and storage of data in databases facilitate seamless retrieval and manipulation operations.
- Operating Systems: Data structures manage system resources like memory and files, essential for effective operating system design and implementation.
- Computer Graphics: Representing geometric shapes and graphical elements relies on data structures, contributing to the visual rendering in computer graphics applications.
- Artificial Intelligence: Data structures are instrumental in representing knowledge and information, supporting the development of intelligent systems.
- Web Development: Structuring data for websites, managing user information, sessions, and handling requests are vital tasks facilitated by data structures.
- Networking: Data structures manage network protocols, routing tables, and packet data, enabling efficient communication between devices.
- Embedded Systems: In embedded systems, data structures organize sensor data, control hardware components, and manage system resources efficiently.
- Compiler Design: Data structures play a crucial role in parsing, analyzing, and optimizing source code during compilation processes.
Advantages of Data Structures
Data structures offer numerous advantages:
- Efficiency: They enable fast storage and retrieval of data, crucial for high-performance applications.
- Flexibility: Data structures provide adaptable ways to organize and manipulate data, allowing for easy adjustments as needed.
- Reusability: They can be utilized across multiple programs, reducing the need for duplicative code and enhancing code efficiency.
- Maintainability: Well-designed data structures enhance program readability and ease of modification, facilitating long-term maintenance and updates.
Conclusion
- In conclusion, data structures are foundational in computer science, offering diverse benefits and applications.
- They enable efficient data storage, retrieval, and manipulation, ensuring optimal performance in various domains.
- From databases to operating systems, computer graphics to artificial intelligence, data structures play critical roles in modern computing.
- Their versatility and flexibility allow for adaptable data organization, promoting code reusability and simplifying maintenance.
- As technology advances, data structures continue to evolve, meeting the evolving needs of software development and computer science.
Dive into the World of Efficient Coding – Enroll in Scaler Academy's Data Structures Course Today and Learn from Industry Experts!