Query Processing in DBMS

Query processing involves extracting data from a database through multiple steps. This includes translating high-level queries into low-level expressions at the file system's physical level, optimizing queries, and executing them for actual results.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Query Processing
One of the types of DBMS is Relational Database Management System (RDBMS) where data is stored in the form of rows and columns (in other words, stored in tables) which have intuitive associations with each other. The users (both applications and humans) have the liberty to select, insert, update and delete these rows and columns without violating the constraints provided at the time of defining these relational tables. Let’s say you want the list of all the employees who have a salary of more than 10,000.
The problem here is that DBMS won't understand this statement. So for that, we have SQL (Structured Query Language) queries. SQL being a High-Level Language makes it easier not just for the users to query data based on their needs but also bridges the communication gap between the DBMS which does not really understand human language. In fact, the underlying system of DBMS won't even understand these SQL queries. For them to understand and execute a query, they first need to be converted to a Low-Level Language. The SQL queries go through a processing unit that converts them into low-level Language via Relational Algebra in DBMS. Since relational algebra queries are a bit more complex than SQL queries, DBMS expects the user to write only the SQL queries. It then processes the query before evaluating it.
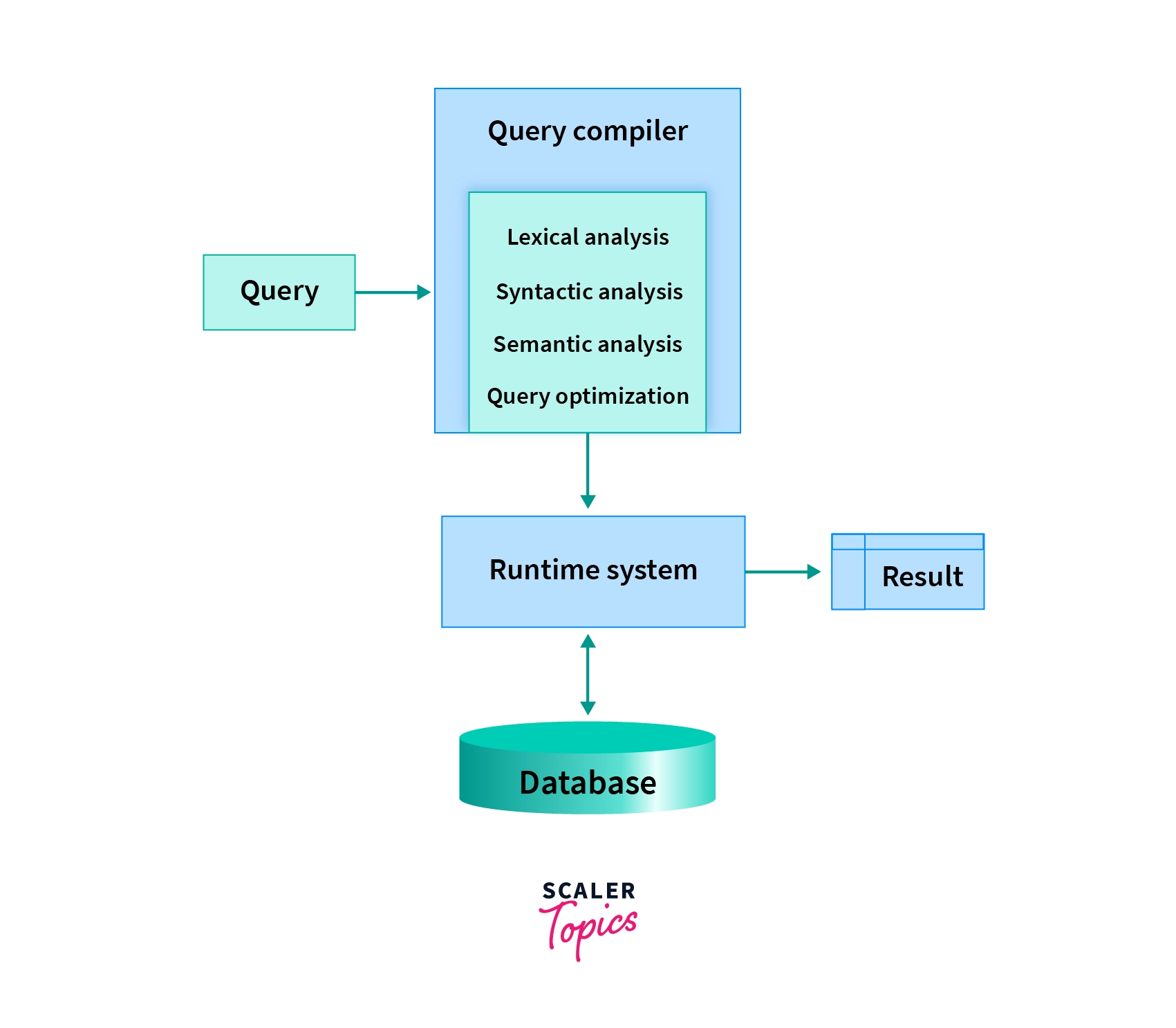


As mentioned in the above image, query processing can be divided into compile-time and run-time phases. Compile-time phase includes:
- Parsing and Translation (Query Compilation)
- Query Optimization
- Evaluation (code generation)
In the Runtime phase, the database engine is primarily responsible for interpreting and executing the hence generated query with physical operators and delivering the query output.
A note here that as soon as any of the above stages encounters an error, they simply throw the error and return without going any further (since warnings are not fatal/terminal, that is not the case with warnings).
Parsing and Translation
The first step in query processing is Parsing and Translation. The fired queries undergo lexical, syntactic, and semantic analysis. Essentially, the query gets broken down into different tokens and white spaces are removed along with the comments (Lexical Analysis). In the next step, the query gets checked for the correctness, both syntax and semantic wise. The query processor first checks the query if the rules of SQL have been correctly followed or not (Syntactic Analysis).
Finally, the query processor checks if the meaning of the query is right or not. Things like if the table(s) mentioned in the query are present in the DB or not? if the column(s) referred from all the table(s) are actually present in them or not? (Semantic Analysis)
Once the above mentioned checks pass, the flow moves to convert all the tokens into relational expressions, graphs, and trees. This makes the processing of the query easier for the other parsers.
Let's consider the same query (mentioned below as well) as an example and see how the flow works.
Query:
The above query would be divided into the following tokens: SELECT, emp_name, FROM, employee, WHERE, salary, >, 10000.
The tokens (and hence the query) get validated for
- The name of the queried table is looked into the data dictionary table.
- The name of the columns mentioned (emp_name and salary) in the tokens are validated for existence.
- The type of column(s) being compared have to be of the same type (salary and the value 10000 should have the same data type).
The next step is to translate the generated set of tokens into a relational algebra query. These are easy to handle for the optimizer in further processes.
Relational graphs and trees can also be generated but for the sake of simplicity, let's keep them out of the scope for now. Click here, to learn more about Query in DBMS.






Query Evaluation
Once the query processor has the above-mentioned relational forms with it, the next step is to apply certain rules and algorithms to generate a few other powerful and efficient data structures. These data structures help in constructing the query evaluation plans. For example, if the relational graph was constructed, there could be multiple paths from source to destination. A query execution plan will be generated for each of the paths.
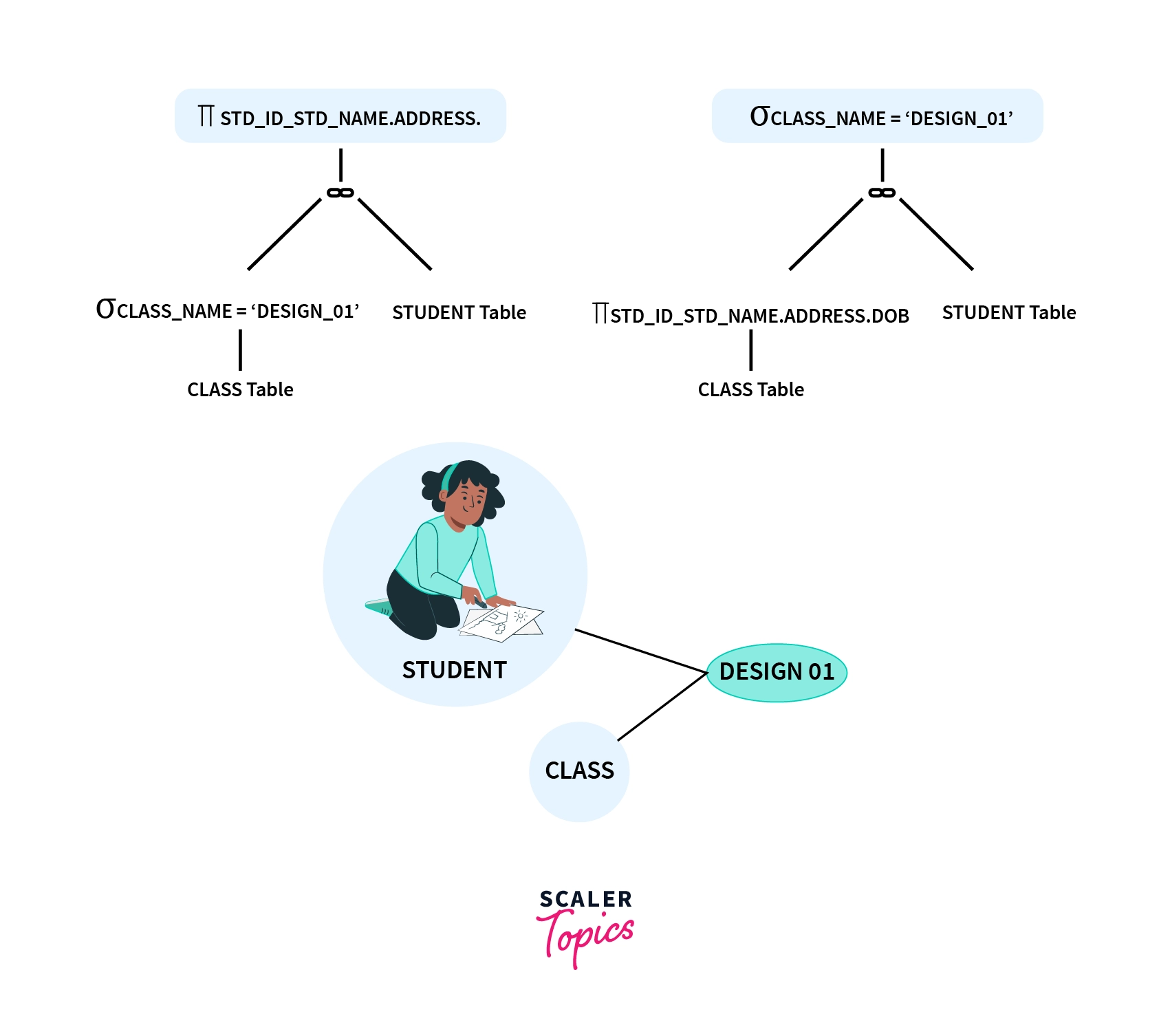
As you can see in the above possible graphs, one way could be first projecting followed by selection (on the right). Another way would be to do selection followed by projection (on the left). The above sample query is kept simple and straightforward to ensure better comprehension but in the case of joins and views, more such paths (evaluation plans) start to open up. The evaluation plans may also include different annotations referring to the algorithm(s) to be used. Relational Algebra which has annotations of these sorts is known as Evaluation Primitives. You might have figured out by now that these evaluation primitives are very essential and play an important role as they define the sequence of operations to be performed for a given plan.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Query Optimization
In the next step, DMBS picks up the most efficient evaluation plan based on the cost each plan has. The aim here is to minimize the query evaluation time. The optimizer also evaluates the usage of index present in the table and the columns being used. It also finds out the best order of subqueries to be executed so as to ensure only the best of the plans gets executed.
Simply put, for any query, there are multiple evaluation plans to execute it. Choosing the one which costs the least is called Query Optimization in DBMS. Some of the factors weighed in by the optimizer to calculate the cost of a query evaluation plan is:
- CPU time
- Number of tuples to be scanned
- Disk access time
- number of operations
Conclusion
Once the query evaluation plan is selected, the system evaluates the generated low-level query and delivers the output.
Even though the query undergoes different processes before it finally gets executed, these processes take very little time in comparison to the time it actually would take to execute an un-optimized and un-validated query. Read more on indexes and see how your queries would perform in case you don't add relevant indexes. To summarise, the flow of a query processing invloves two steps:
- Compile time
- Parsing and Translation: break the query into tokens and check for the correctness of the query
- Query Optimisation: Evaluate multiple query execution plans and pick the best out of them.
- Query Generation: Generate a low level, DB executable code
- Runtime time (execute/evaluate the hence generated query)