File Organization in DBMS

File organization within a DBMS delineates the logical arrangement of these records, determining how they're mapped onto disk blocks. Optimal file organization is pivotal for expediting operations like insertion, deletion, and updating of records, ensuring efficiency and preventing redundancy. Memory, in this context, is partitioned into memory blocks, with each record being assigned a specific "Bucket address." While the high-level perspective presents databases as tables, the underlying reality underscores files, records, and their strategic organization. This intricate mapping, whether spanned or unspanned, encapsulates the essence of database management, emphasizing the nuanced interplay between logical structures and physical storage mediums.
Types of file organization
Depending upon the access and selection of records, various methods of file organization in DBMS are induced, explained as follows:
1) Sequential file organization:
- The simplest of all file organization methods.
- Inefficient for large databases.
- It is divided into two types: Pile file method and sorted file method.
As the name suggests, this method simply stores the records in files in sequential order, one after another in a series like a sequence of books on a bookshelf, and to access these files, we have to search through the whole sequence until we reach our desired file in O(n) provided there is no order in the files like they are unsorted else we can use binary search to access in O(logn), the image below shows a typical file containing sequential file organization scheme.
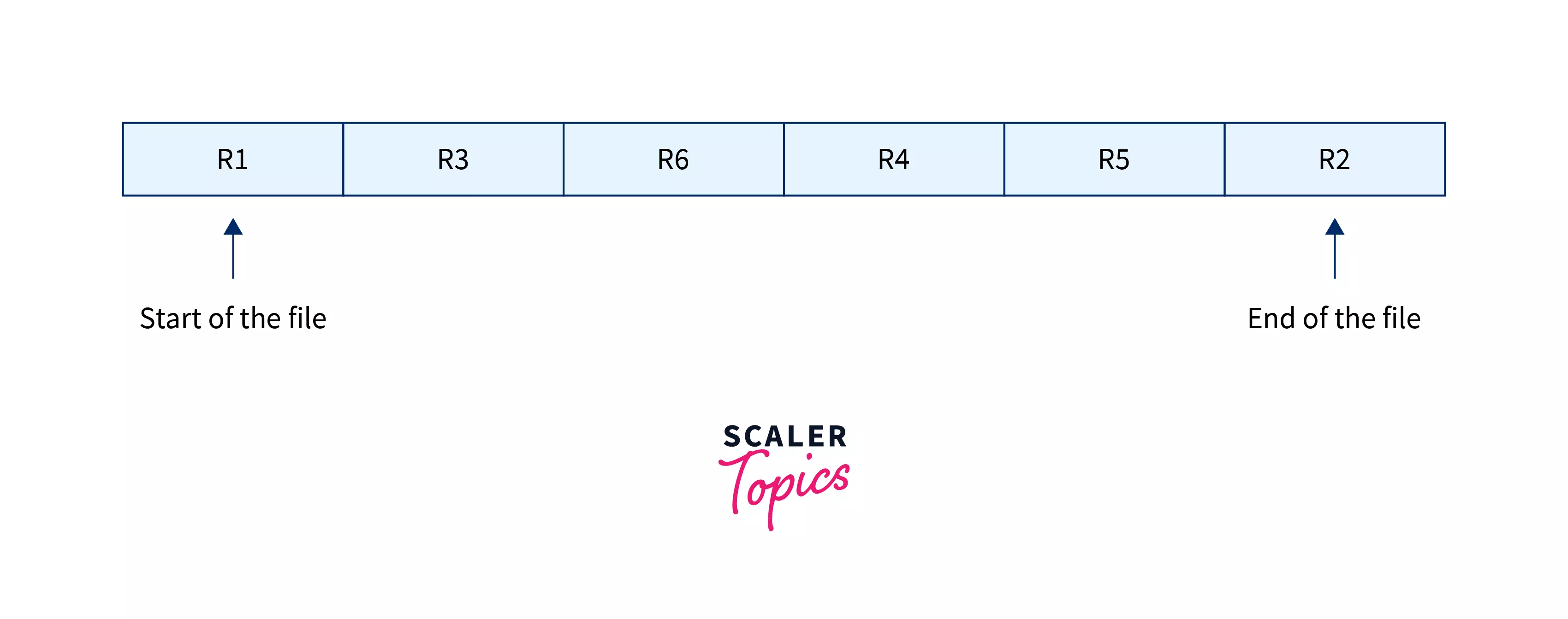
Here, R1, R2, and R3 up to R6 represent records of the file, the record is just a row in a table. There are two ways to organize records in sequential order depending upon the ordering schema of records.
a) Pile File method:
In this method, records are stored in sequential order, one after another, and they are inserted at the end of the file in the same order in which we insert them in the table using the SQL query, so it is just an O(1) space complexity operation because the order of the record does not matter. In this method of sequential file organization, there is no order i.e. the files are randomly pushed after one another, which makes accessing costly in terms of time.
In case of modification or deletion of any record, it is first searched throughout the file, and when it is found the updation or deletion operation is performed, since we traverse the whole file to search for the target element the method works in O(n) time complexity.
Let's understand the insertion of a new record in the file, Consider the file below containing records.
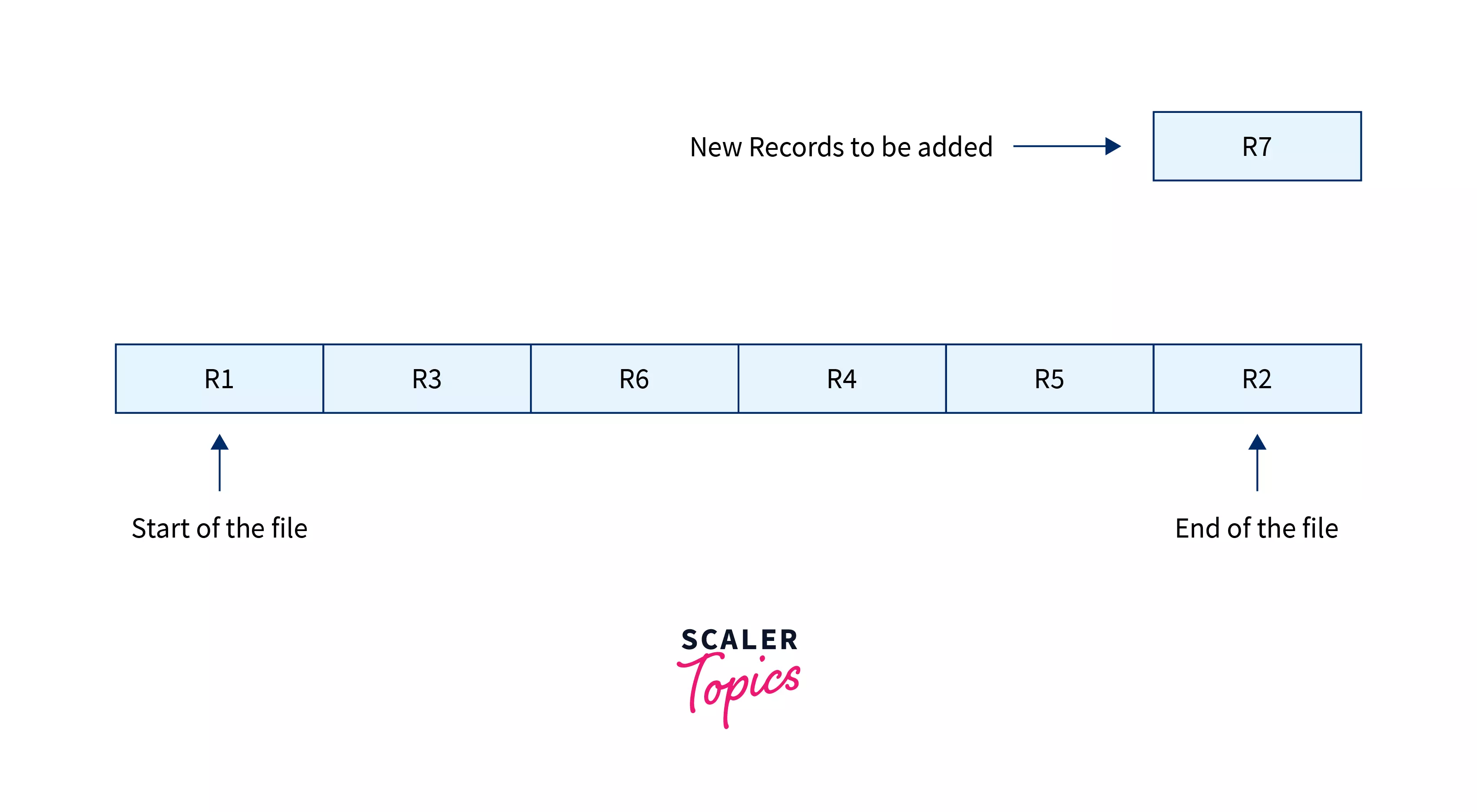
In this file, the new R7 record will be inserted at the end of the file, and we do not bother about the order in this method.
What if we keep the records in some sorted order, how does it affect the time complexities of delete, retrieve, and update operations? Let's see the next method of sequential file organization in DBMS.
b) Sorted file method: As the name suggests, the file in this method has to be kept in sorted order all the time. In this method, the file is sorted after every delete,insert, and update operation on the basis of some primary key or another reference. Insertion of the new record is done by adding the new record at the end of the file, after which the file is sorted in ascending or descending order based on the requirements giving the insertion operation a time complexity of O(nlogn) used for sorting the file. Let's understand the insertion of a new record with the image below:
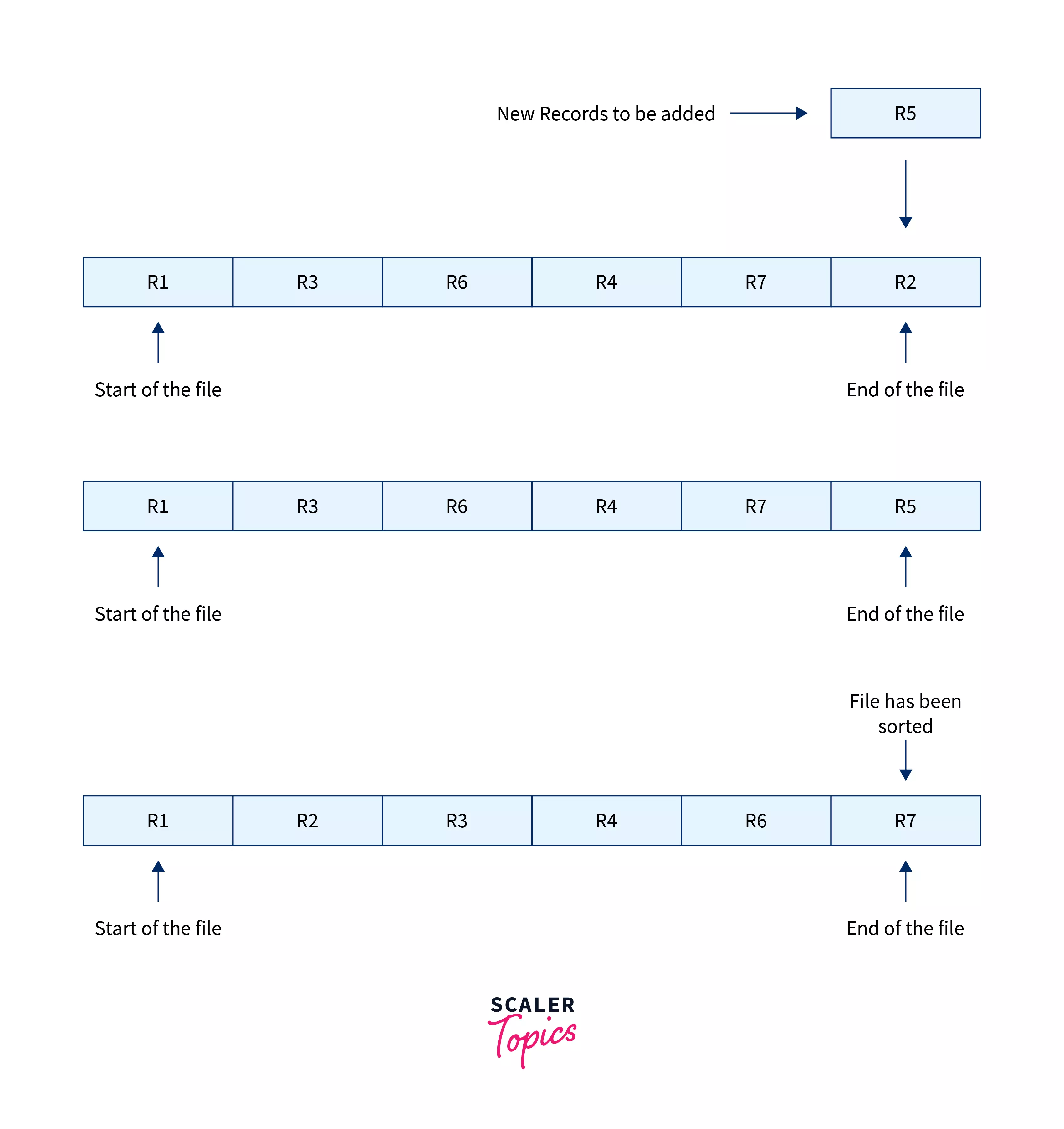
In this image, the records R1, R2, R3, R4, R6, R7 are there in the file, and the record R5 is inserted at the end of the file, then in the second step, the file is sorted such that the record R5 takes its right place in the file.
Let's understand the ion and updation in this method, in the case of the delete method, one has to search first for the element to be deleted, and initially, in the pile file method, we used to traverse the whole file to find the target element, but in this case, since the file is sorted, we can use binary search algorithm to find the element to be updated or deleted once the target element is found it can be deleted or updated in the similar fashion as in pile file method after which the file is again sorted in the same order as it was previous to maintain the sorted order. Thus, deletion and updation costs O(logn), although due to sorting, the overall complexity is O(nlogn).
Let's see the advantages and disadvantages of using the Sequential file organization method in a DBMS.
Advantages:
- Sequential file organization in DBMS is the simplest of all file organization methods.
- In the case of large volumes of data, this method is efficient in terms of speed as access to the data is relatively fast in this method.
- It is also cost-effective as it can be implemented using storage devices like magnetic tapes, which are relatively cheap.
- Since this method is fast in terms of accessing the records, it is used in cases where most of the records of the file are accessed at the same time, for example, calculating the attendance of the students, generating the payslips for the employees.
- This technique is also used for the statistical computation process.
Disadvantages:
-
The disadvantage of this technique is the traversal cost which is linear, hence to access a particular record, we have to use linear traversal O(n) in the case of the pile file method while in the sorted file method, although traversal cost is lesser O(logn) but to maintain the file sorted it takes more time.
-
In the case of the sorted file method, it is costlier because it has to sort the file after every delete, update, and insert operation.
-
The main requirement of this method is that the records must be of same size, which is difficult to implement in most real-world database systems.
-
The data redundancy is high in the sequential file organization in DBMS.
Let's understand the next file organization method.
Heap file organization
This method is also one of the simplest methods of file organization in DBMS. In this method, records are inserted in a sequential manner, but unlike the sequential file method, the data blocks are not allocated sequentially DBMS can choose any data block for the record to be inserted. There is no ordering of records in heap file organization once the data block is full, the next record is stored in the new data block, which might not be the next data block, as shown in the image below:
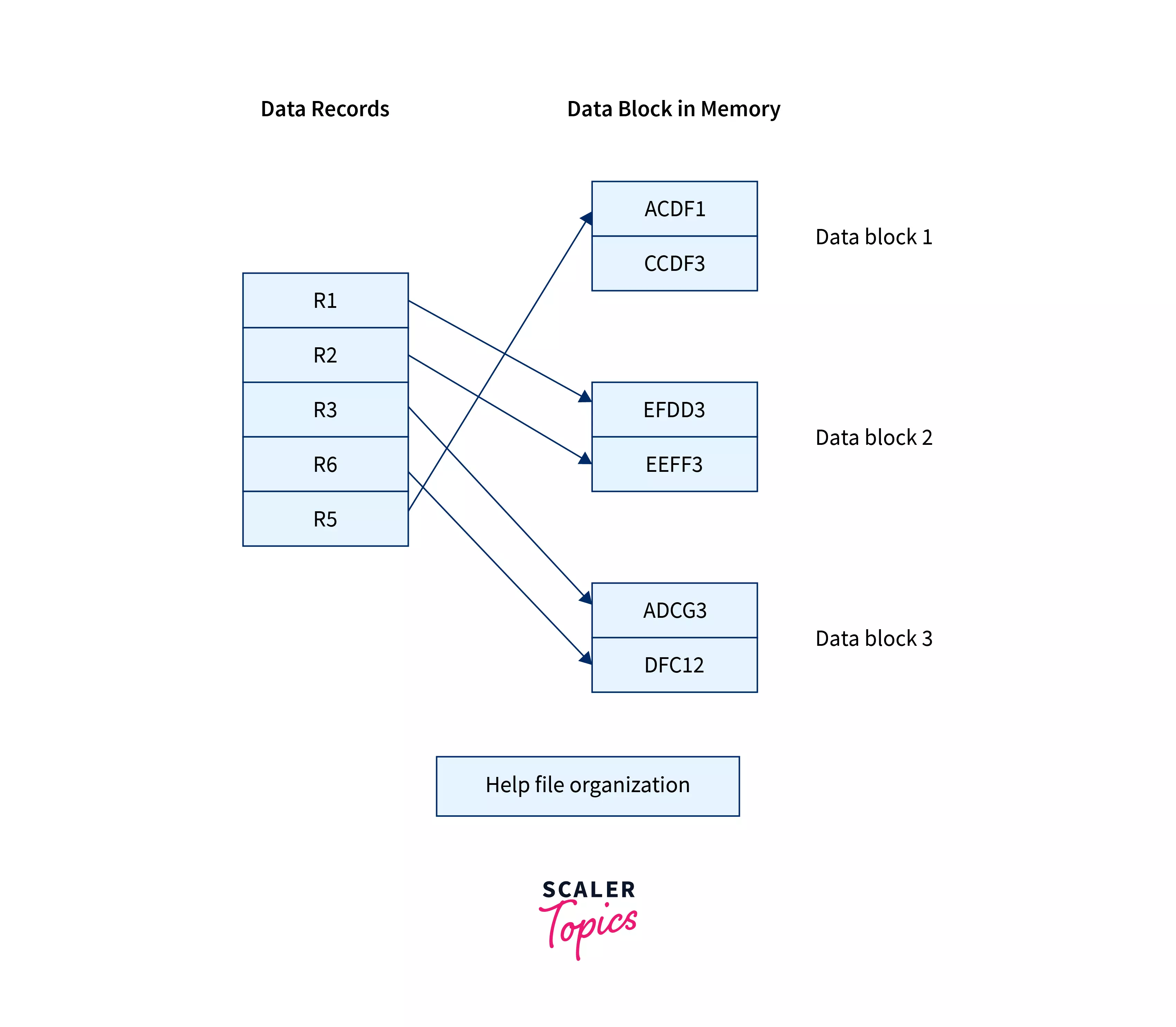
Let's understand the insertion , deletion, and updation operations in the Heap file organization method: To insert a new record, it is simply added at the end of the file, and any data block can be allocated in the memory by the DBMS to this new record as shown below:
To delete any record in this type of file, one has to traverse the entire file to reach the desired record because there is no order in the file, and hence updation, and deletion is costly in this method. Let's understand the advantages and disadvantages of heap file organization.
Advantages:
- It is one of the simplest file organization methods in DBMS in terms of its data structure and operations like insertion, deletion, and updation.
- In the case of small databases, this method is used over the sequential file method because accessing the records is relatively faster in this method.
- Since it is faster, in case of a large amount of data being transferred at a single time, then this method is best suited.
Disadvantages:
- Since the method takes linear traversal for accessing the records, hence it is not best suited for large databases, it is mainly used for small databases.
- Since records map to the random blocks of memory, unlike sequential file organization in DBMS they are not allocated in a sequence; therefore, there is a problem of memory block wastage which is the main disadvantage of this method because after one part or bucket address of a particular block is mapped with some record, it is not mandatory for the DBMS to allocate the next bucket address of the previous block, but it can choose any new random block for mapping the record which leads to memory wastage.
Let's understand the next file organization method in DBMS, i.e., Hash file organization.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Hash file organization
To access any record in all previous methods explained till now, we need to either traverse the entire file, which takes O(n) time complexity or we have to use binary search in case the file is sorted with respect to some primary key that takes O(logn) time complexity. But hashing is the best technique in this scenario, where we can access the data bucket of any record in O(1) using its primary key.
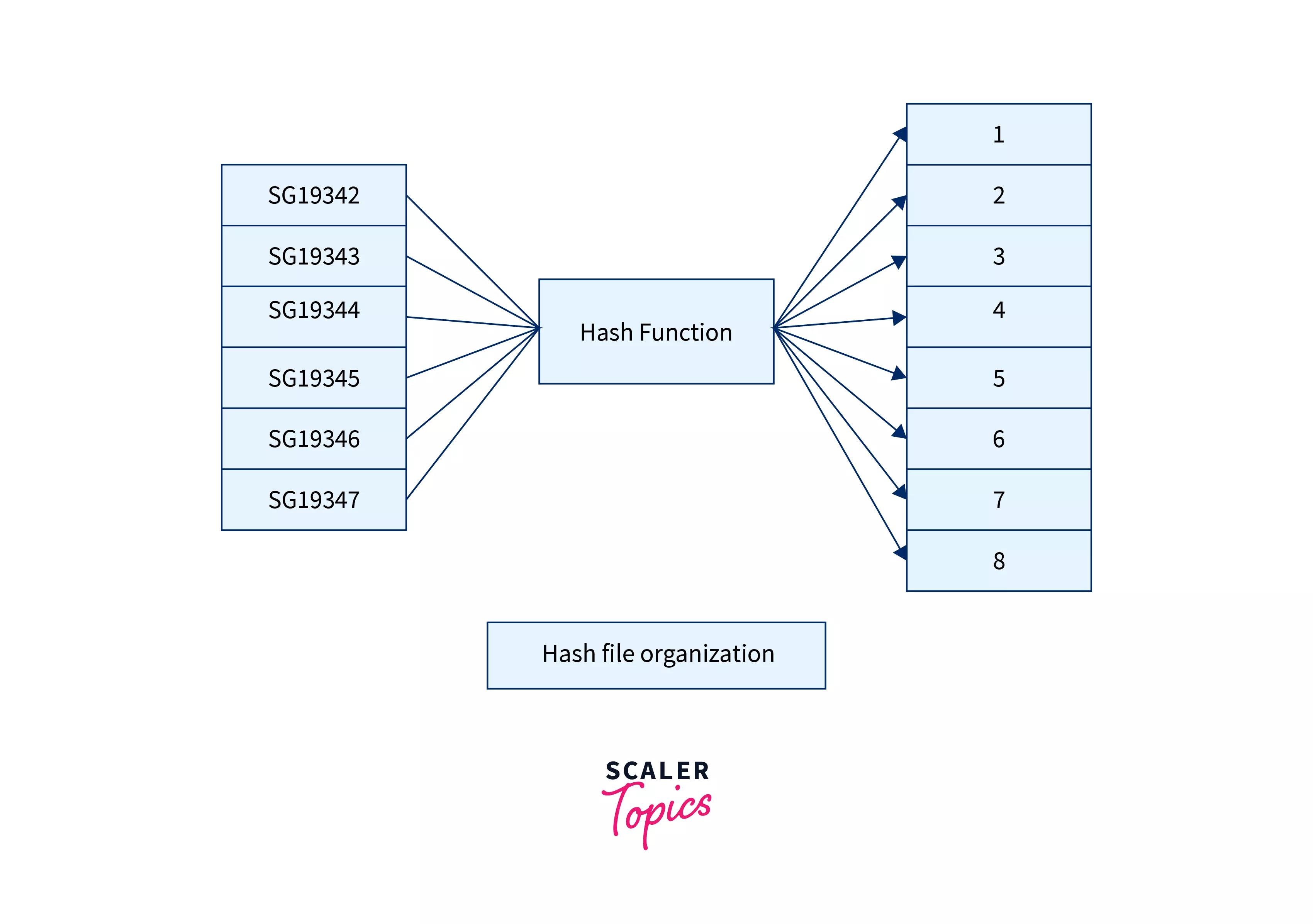
In hash file organization, Hashing is used to generate the addresses of the memory blocks where actual records are mapped. Basically, a hashing function generates the address of those data blocks using the primary key as input, and those memory locations which are generated by these hash functions are called data buckets or data blocks.
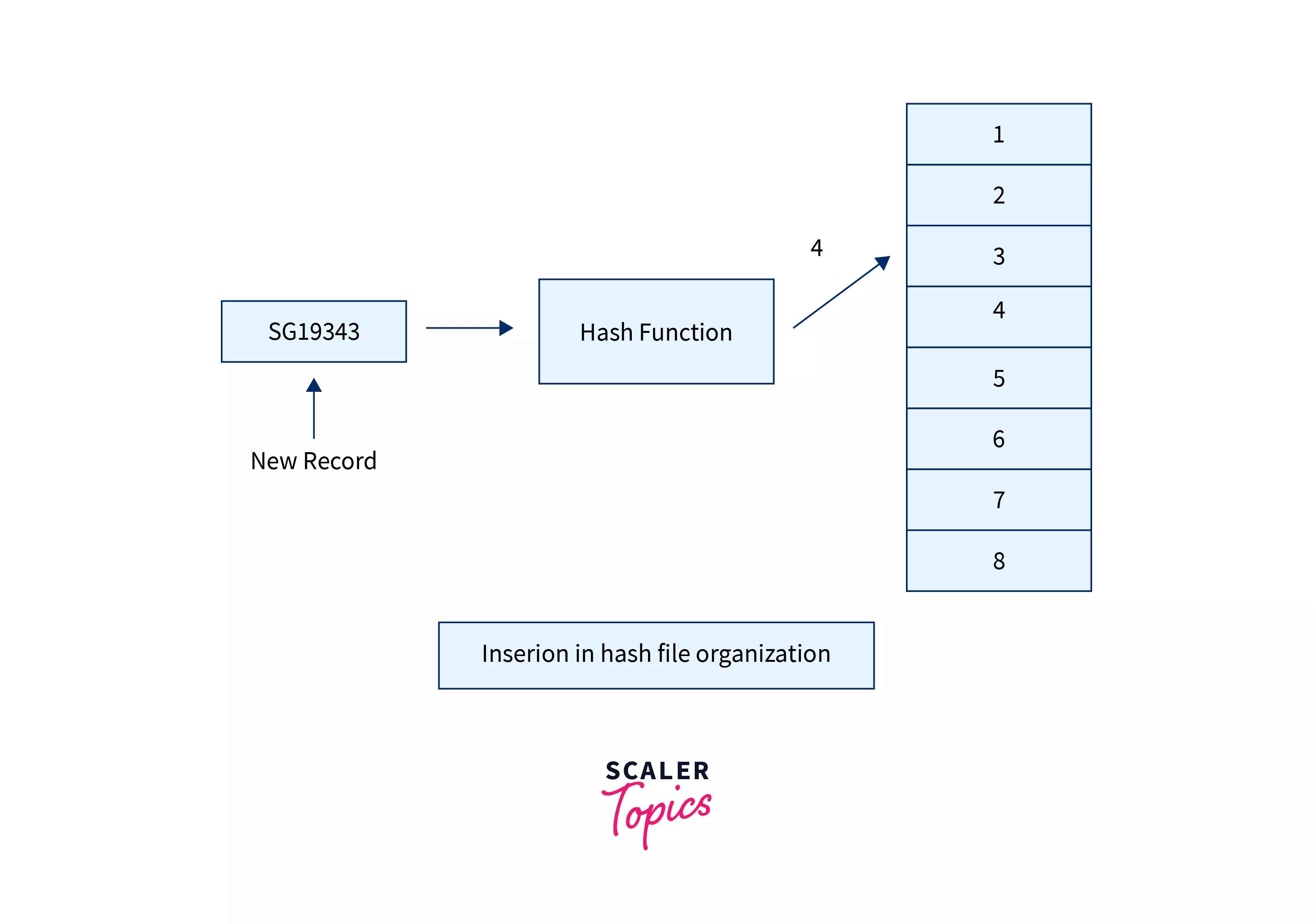
Let's understand the insertion, deletion, searching, and updation in the hash file organization method in DBMS. In this method, to insert a new record, the hash function says hash_function(key) and generates a bucket address based on the primary key, which it takes as an argument, the hash function can be some simple mathematical function or complex function. Now, the record is mapped to the address generated by this hash function. Hence, this is overall a constant time operation if the hash function takes constant time to generate the bucket address.
To delete a record, first, we need to generate the bucked address from the key of the given record using hash_function(key), then the record for that address is removed, this operation also takes constant time complexity if the hash function uses a constant time complexity function.
Searching for a record in the file is also efficient in this method, where we need to simply generate the bucket address from the key of the given record using the hash_function(key).
In the updation operation, first, the bucket address is fetched using the hash function then the record at that address is updated.
Let's understand the advantages and disadvantages of the hash file organization in DBMS.
Advantages:
- Hash file organization in DBMS uses a hashing function that gives the bucket address of any record very fast, and hence this method is very efficient in terms of speed and efficiency.
- Because of its speed and efficiency, it is used in large databases like ticket booking, online banking, e-commerce etc.
- Hash file organization in DBMS can handle multiple transactions at the same time because all records are independent, and multiple records can be accessed at the same time.
Disadvantages:
- The firstmost disadvantage is data loss because suppose the hashing key used is some non-prime attribute, say the name of the employee in an employee table, then for the same name, the same bucket address will be generated and hence one of them will override the other which will cause the data loss.
- Search can be only performed on the column which is used for hashing to generate bucket addresses and not on any other column.
- Memory is not efficiently used in this method because the hash is a randomly generated bucket address; hence there is no order in it.
- Since there is no order in the arrangement of the memory addresses, we cannot search some records in a particular range. For example, searching for students having marks 20 to 30 will not be an efficient operation because the memory addresses are scattered randomly.
Let's see other methods of file organization in DBMS
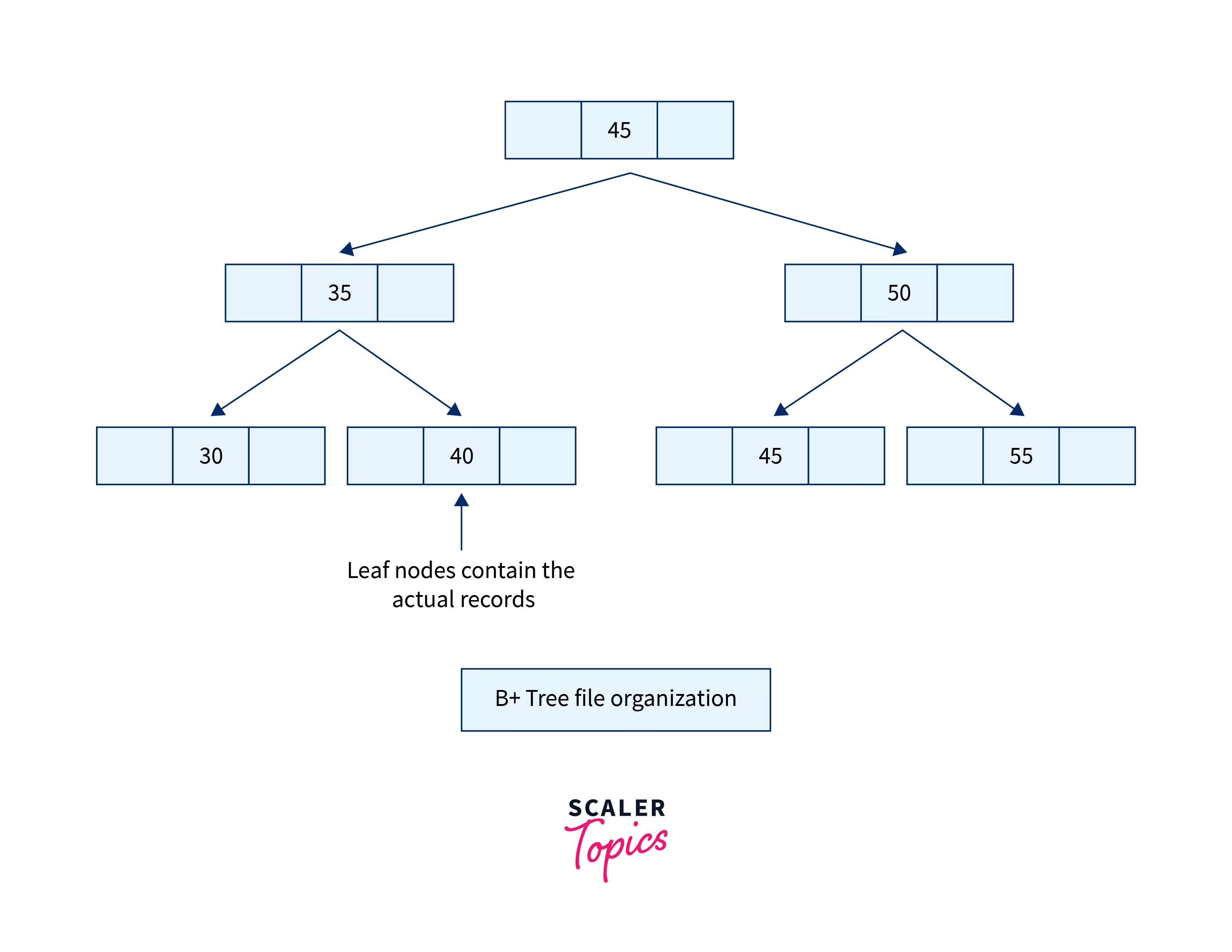
B+ tree File Organization
B+ tree is the same as a Binary search tree, but it can have more than two children, in this method of file organization, a tree-like structure is used to store and access the records. This method is an extension of the Indexed Sequential Access Method. In this method, all records are stored at the leaf nodes of the B+ trees, and the intermediate nodes act as pointers that lead to those leaf nodes. This method uses the key-index concept, where it uses the primary key for the sorting of the records, and the index value represents the bucket address of that particular key.
Let's see the advantages and disadvantages of the B+ tree data structure. .
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Advantages:
- The records in B+ trees are in the form of singly linked lists to make the searching of data more efficient and quick.
- B+ tree is a balanced tree structure, and hence any operation delete, insert, or update does not affect the overall performance of the tree.
- Tree traversal is easier and relatively fast.
- The size of the tree is dynamic because it can grow or shrink dynamically according to the number of records.
Disadvantages:
- The drawback of B+ trees is that this method is not efficient for static tables.
Let's understand the next file organization method.
Clustered file organization
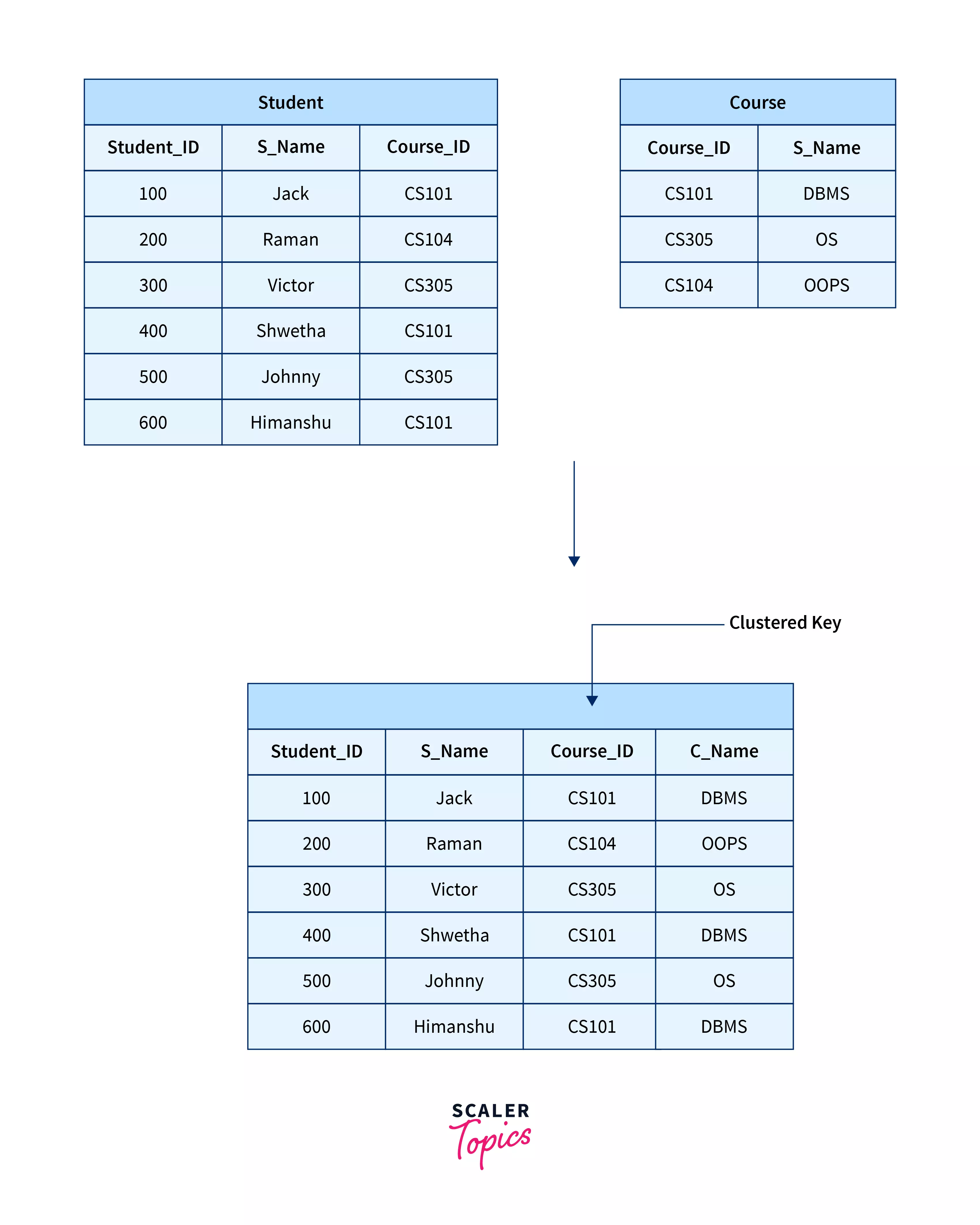
In clustered file organization, two or more records/tables are combined into a single file based on the clustered key or hash clusters, these files contain two or more tables in the same memory block, and all of them are combined using a single clustered key/hash key to a single table.
Let's understand this using an example.
Suppose the database of the university where we have two tables, namely the student table, which gives the details of the student, and the course table, which contains the information about the course.
In the above case, we want to retrieve the students who are enrolled in a particular course, hence we need to join them first and then perform the query for selecting such records, and we join the tables every time we want to retrieve the data so to avoid these computations we combine them into a single table based on a particular clustered index which is Course_id in this case. This operation will save time for us as we just need to run the query for the combined table and no longer need to use the join operation.
Let's understand when we need to use clustering in tables.
- Whenever we have a one-to-many relationship between the tables, then we opt for the clustered file organization method in DBMS as in the above example, one course can be opted by many students; hence there is a 1:M relationship between the course and student table.
- Whenever we need to use the join operation very frequently for joining the tables of the database, then we may consider clustering those tables.
Turn Learning into Career Growth
Types of Clustered File Organization:
There are two types of clustered file organization methods in DBMS
1) Indexed Clusters: In this case, the tables are combined on the basis of the clustered key for example, in the above case where student and course tables are on the basis of course_id.
2) Hash Clusters: In this case, the tables are combined on the basis of the hash value of the clustered keys, and we store the results on the basis of the same hash key value.
Let's understand the Advantages and Disadvantages of the Clustered File Organization in DBMS:
Advantages:
- The cluster file organization in DBMS is used when there is a join operation for the tables.
- When there is a 1:M relationship, then this method is efficient.
Disadvantages:
- Clustered file organization in DBMS is inefficient for the less frequently joined tables and with the tables with one-to-one relationships.
- Clustered file organization in DBMS is inefficient for large databases.
Let's understand the next file organization method in DBMS:
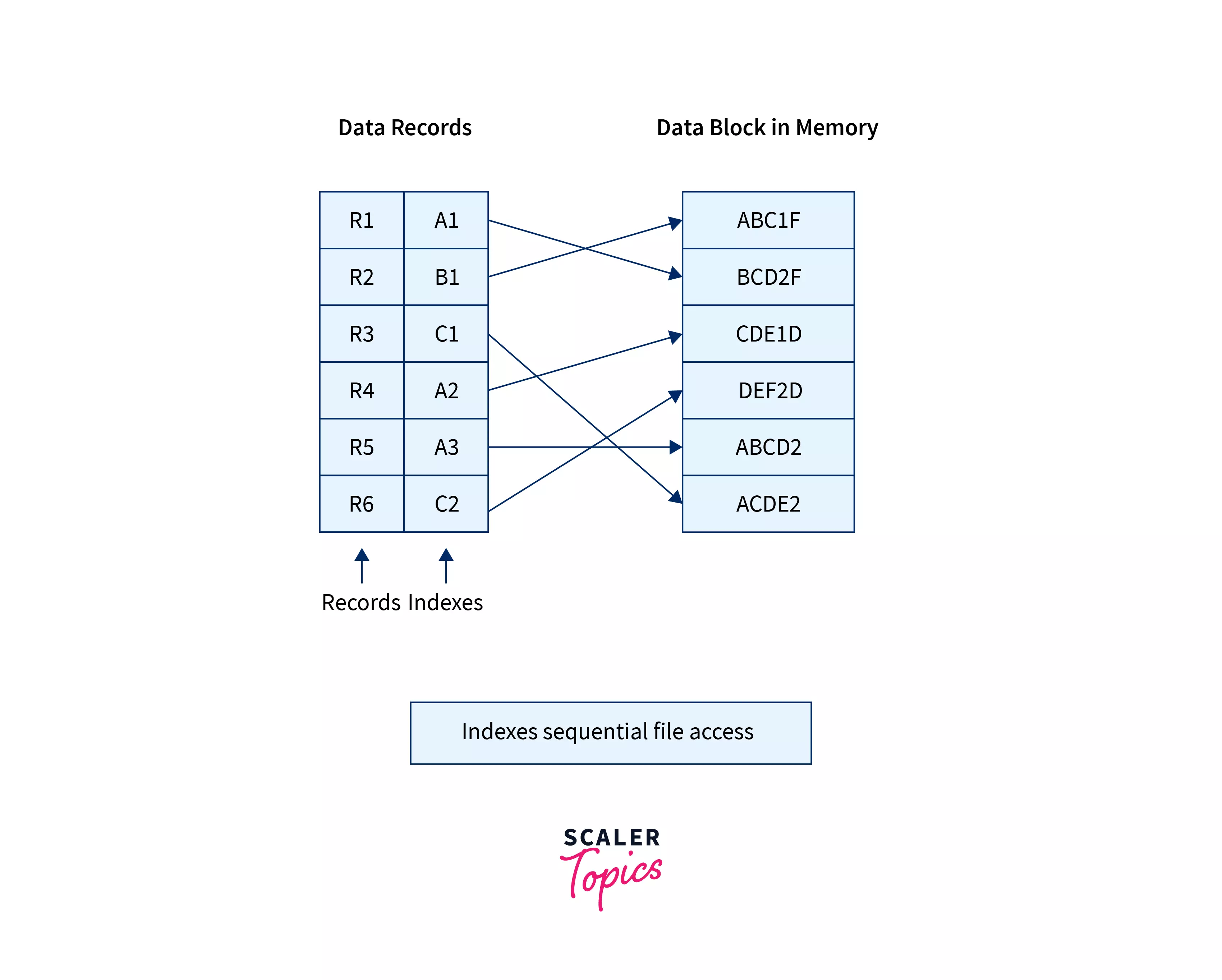
Indexes Sequential Access Method
This method is an advanced file organization in DBMS in which for each record in a file, an index value is generated from its primary key, and that index value is mapped with the record, this index contains the address of the record as shown below:
Let's understand the advantages and disadvantages of this file organization method in DBMS:
Advantages:
- Since there is an index corresponding to each record in the table, it is quicker to access any record in the memory, hence ISAM file organization in DBMS can be used for managing large databases.
- Range retrieval and partial retrieval are possible in this method since the index is generated from the key value column we can generate the record addresses of a range of key values, also when a partial key is provided, like student names starting with "RA '' can also be searched efficiently.
Disadvantages:
- The main disadvantage is that the ISAM file organization in DBMS takes a lot of space for storing index values; hence when the records increase in number the number of indexes also increases.
Objective of file organization
- File organization in DBMS makes the selection of the records, i.e., querying the database for some records, easy and optimal by giving an ordered arrangement.
- File organization in DBMS makes the database system efficient for the delete, insert and update operations.
- File organization in DBMS also checks for redundancy in the records as a result of the insert,delete , or update operation.
- File organization in DBMS tries to minimize the storage cost by storing them efficiently using the right data structures and techniques.
Conclusion
- At the low level, all the tables that we create using SQL are stored in the form of files in the physical memory.
- The memory is divided into the disk blocks where records are mapped through spanned or unspanned mapping.
- File organization is a method to organize records in a database using different storage techniques like hashing, sequential, B+ tree etc., so as to make the database efficient for the insert, delete, and update operations.
- Depending upon the size of the database and type of records, the frequency of accessing the right method for file organization is chosen to ensure the most efficient database.