What is Multiple Granularity in DBMS?

Granularity is the size of data that is allowed to be locked. Multiple granularity is hierarchically breaking up our database into smaller blocks that can be locked. This locking technique allows the locking of various data sizes and sets. This way of breaking the data into blocks that can be locked decreases lock overhead and increases the concurrency in our database. Multiple granularity helps maintain a track of data that can be locked and how the data is locked.
What is Granularity in DBMS?
Transactions in databases are atomic, which means when a transaction needs to access the values in the database, a locking protocol is used to lock the database. Locking prevents other transactions from modifying or viewing the database simultaneously because other ongoing transactions are locked.
It is crucial to lock the database while performing a transaction optimally. Locking an entire database unnecessarily can cause a loss of concurrency. We have a concept of multiple granularity in DBMS to solve this issue.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Example
We can understand the concept of multiple granularity with a tree diagram. Consider a tree structure as mentioned below.
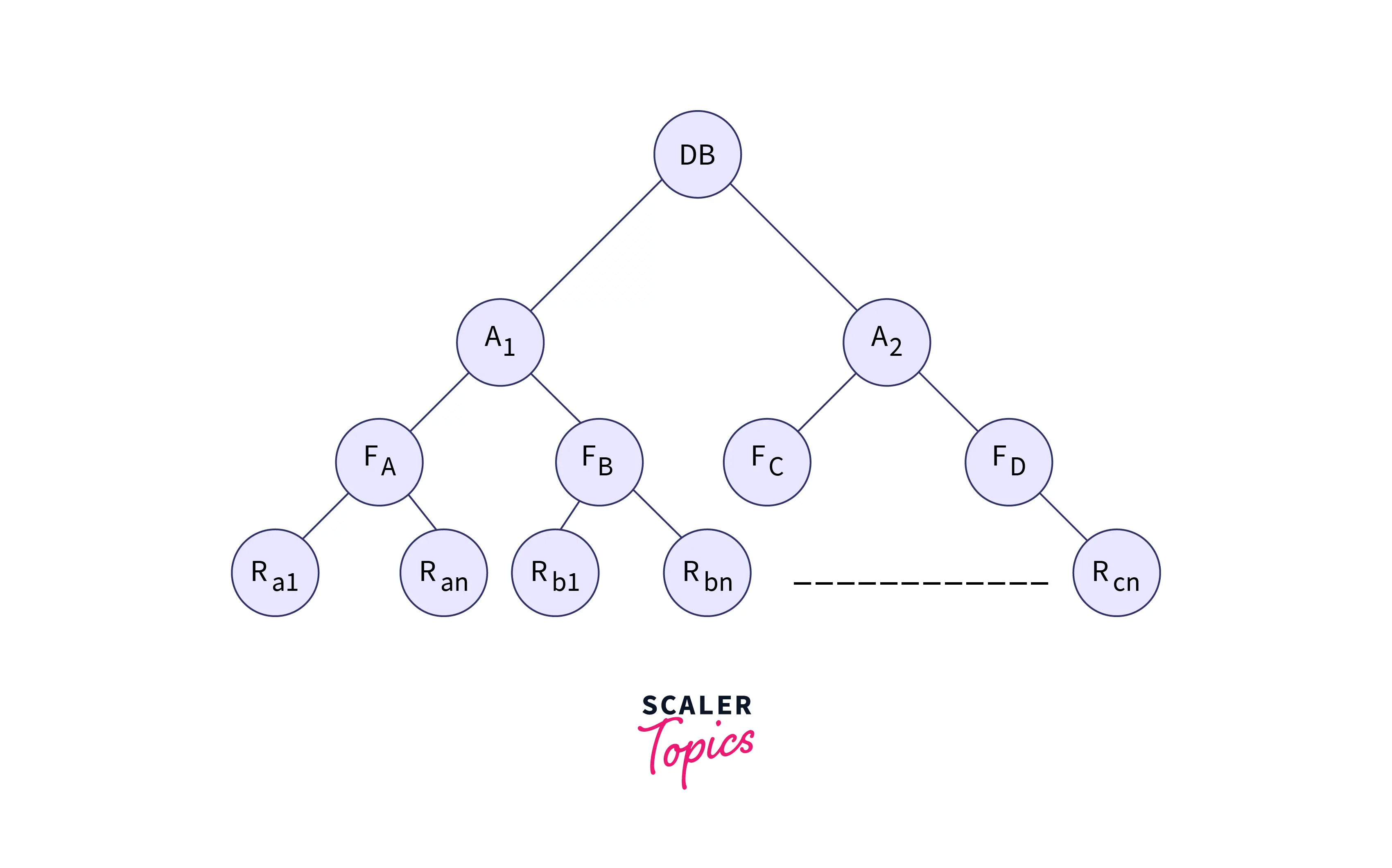
Here, our tree has four node levels.
- The first level, or the tree's root, represents our entire database containing several tables and records.
- The next level (second level) has nodes that represent areas. The database consists of these areas.
- The children of the second level are known as files. A file can not be present within more than one area.
- The bottom layer in our trees is known as the records. Records are child nodes of files and can not be present in more than one file.
Hence, the four levels in our tree are:
- Database
- Area
- File
- Record
Now that we understand the levels in our tree diagram, we can see that each node in the tree can be individually locked. So far, we know from 2 phase locking protocol that when a transaction locks a node, it can be shared or exclusive. Once a node is locked, the children nodes are implicitly locked with the identical lock mode.
There are two problems with this approach:
- If we want to apply a lock on a node, we need to ensure that no ancestor of the node is locked. To ensure that none of the ancestors is locked, we need to iterate from root to node to check any node in the path is not locked.
- To acquire a lock on the entire database, the complete tree needs to be iterated to ensure none of the descendants (of the root node) is locked.
These limitations arise because we have a two-phase locking mechanism. The need to search the entire tree to acquire a lock on the entire database nullifies our concept of multiple granularity. We will see a better approach to solve the limitations discussed above in upcoming sections of the article.
What are the Different Types of Intention Mode Locks in Multiple Granularity?
For the problem mentioned in the above section, we introduce three additional locks other than shared and exclusive locks, which are:
- Intention Shared (IS) lock: If there is an Intention-shared lock on a node, then the lower level tree only has explicit locking with the shared lock. This means that a node can have an Intention Shared (IS) lock only when only nodes at the lower level are locked with shared locks.
- Intention Exclusive (IX) lock: Explicit lock on the lower level tree from the node with either shared or exclusive lock.
- Shared and Intention Exclusive (SIX) lock: In such type of lock, the subtree of the locked node is explicitly locked in shared mode and with an exclusive mode lock at the lower level.
Let us see the compatibility matrix for the five locks that we now know:

To ensure serializability in data, we use intention lock modes in multiple granularity protocols. If a transaction T attempts to lock a node, it needs to follow the following protocols:
- The transaction T must follow the lock-compatibility matrix.
- Transaction T first locks the root node (in any mode).
- If the parent node of T has IX or IS lock, then transaction T will lock the node only in IS or S mode.
- If the parent node of T has locked in mode SIX or IX, then transaction T will lock the node only in SIX, IX, or X mode.
- If transaction T has previously not unlocked any node, then transaction T can lock a node.
- If none of the children of transaction T is locked, only then can transaction T unlock a node.
The locks in multiple granularity are acquired from top to bottom (top-down order), but the locks must be released in the bottom-up order.
Let us see the simulation of the protocol with an example on the tree mentioned in the article:
- Suppose transaction T1 reads the recode Ra2 in a file Fa. Then another transaction, T2, will lock in the database, area A1, file Fa with IS mode, and record Ra2 in Shared mode in the same order.
- Let's say our transaction T2 modifies the record Ra8 in the same file Fa. For this operation database, area A1 and file Fa will be locked in IX mode, and the target record Ra8 will be locked in exclusive (X) mode.
- Another transaction T3, tries to read all records in our file Fa. Then T3 will lock the nodes in its path, i.e. database and area A1, in IS mode, and then file Fa will be locked in shared (S) mode.
- Lastly, let's say transaction T4 reads our entire database. Then transaction T4 will lock the database in S mode and read the database.
Here, our transactions T1, T3, and T4 concurrently access the database, while transactions T2 and T1 can execute concurrently but can not execute concurrently with either transaction T3 and T4.
This way, multiple granularity improves concurrency and reduces the overhead on locks, but deadlocks can still be possible in multiple granularity protocol, just like in the two-phase locking protocol.
Also,click here to learn more about Record in DBMS.
Conclusion
- A locking protocol locks the database whenever a transaction wants to access the database.
- Granularity is the size of data that is allowed to be locked.
- Multiple granularity is hierarchically breaking up our database into smaller blocks that can be locked.
- Other than shared and exclusive locks, three additional locks are introduced in multiple granularity locking protocols:
- Intention Shared (IS)
- Intention Exclusive (IX)
- Shared and Intention Exclusive (SIX)