Exploring Variants of BERT (Overview)
Overview
BERT, which stands for Bidirectional Encoder Representations from Transformers, is a language processing model developed by Google. BERT is designed to pre-train deep bidirectional representations from an unlabeled text by joint conditioning on both the left and right context in all layers.
Several variants of BERT have been developed, each with its unique characteristics and performance capabilities.
Prerequisites
To better understand this article, it is helpful to have the following prerequisites:
- Basic knowledge of natural language processing (NLP) and deep learning. Including familiarity with concepts such as neural networks and machine learning.
- Familiarity with the BERT model and its underlying concepts, such as transformers and pre-training.
- An understanding of how BERT can be applied to various NLP tasks, such as text classification and named entity recognition.
- Knowledge of the challenges and limitations of the original BERT model, including its large size and need for large amounts of labeled data.
These prerequisites will provide a strong foundation for understanding the blog article and the different BERT variants discussed in it.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Introduction
The article explores the different variants of BERT. The original BERT model has some limitations, such as its large size and needs for a large amount of labeled data, which can make it less suitable for certain use cases.
To overcome these limitations, several variants of BERT have been developed, each with its unique characteristics and performance capabilities. These variants include ALBERT, RoBERTa, ELECTRA, DistilBERT, SpanBERT, and TinyBERT. This article will provide an overview of these BERT variants and explain their key characteristics and performance capabilities. We will also discuss how they differ from the original BERT model and provide examples of how these variants can be used in natural language processing tasks. By the end of the article, readers will have a better understanding of the different BERT variants and how they can be applied to solve real-world problems.
Evolution of BERT
Although BERT has proven to be a very effective language processing model, it has some disadvantages that may make it less suitable for certain use cases.
- One disadvantage of BERT is that it is a large model, which requires a significant amount of computational resources to train and use.
- It has about 110 million parameters, which makes it harder and slower to train and also makes the inference times slower.
- It requires a lot of training data.
- The training process has a lot of room for optimization.
While BERT has shown great promise in many natural language processing tasks, its large size and need for large amounts of labeled data can be limitations in some situations.
Many different variants of BERT were introduced to overcome the difficulties mentioned above. Which we will go over in detail in this article.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Types/Variants of BERT
Several variants of BERT have been developed, each with its unique characteristics and performance capabilities. Some of the most notable BERT variants include:
- ALBERT: (A Lite BERT) is a BERT model that has been modified to reduce the number of parameters and computational complexity without sacrificing performance. This makes training faster and more efficient while maintaining the ability to generate high-quality language representations.
- RoBERTa: (Robustly Optimized BERT) is a BERT model that has been trained on a larger dataset and for a longer period using more advanced training techniques. This results in a better model for various natural language processing tasks.
- ELECTRA: (Efficiently Learning an Encoder that Classifies Tokens Accurately) is a BERT model that has been modified to improve its ability to generate high-quality text representations. This is achieved by training the model to generate fake text and then using a discriminator to identify which text is real and which is fake.
- DistilBERT: DistilBERT is a BERT model that has been distilled (or simplified) to make it faster and more efficient without sacrificing too much performance. This allows it to be used when computational resources are limited, such as on mobile devices.
- TinyBERT: TinyBERT is a BERT model that has been further distilled to make it smaller and more efficient than DistilBERT. This allows it to be used in even more resource-constrained situations.
Overall, the different BERT variants are designed to improve upon the original BERT model in various ways, such as by increasing performance, reducing computational complexity, or improving efficiency.
ALBERT
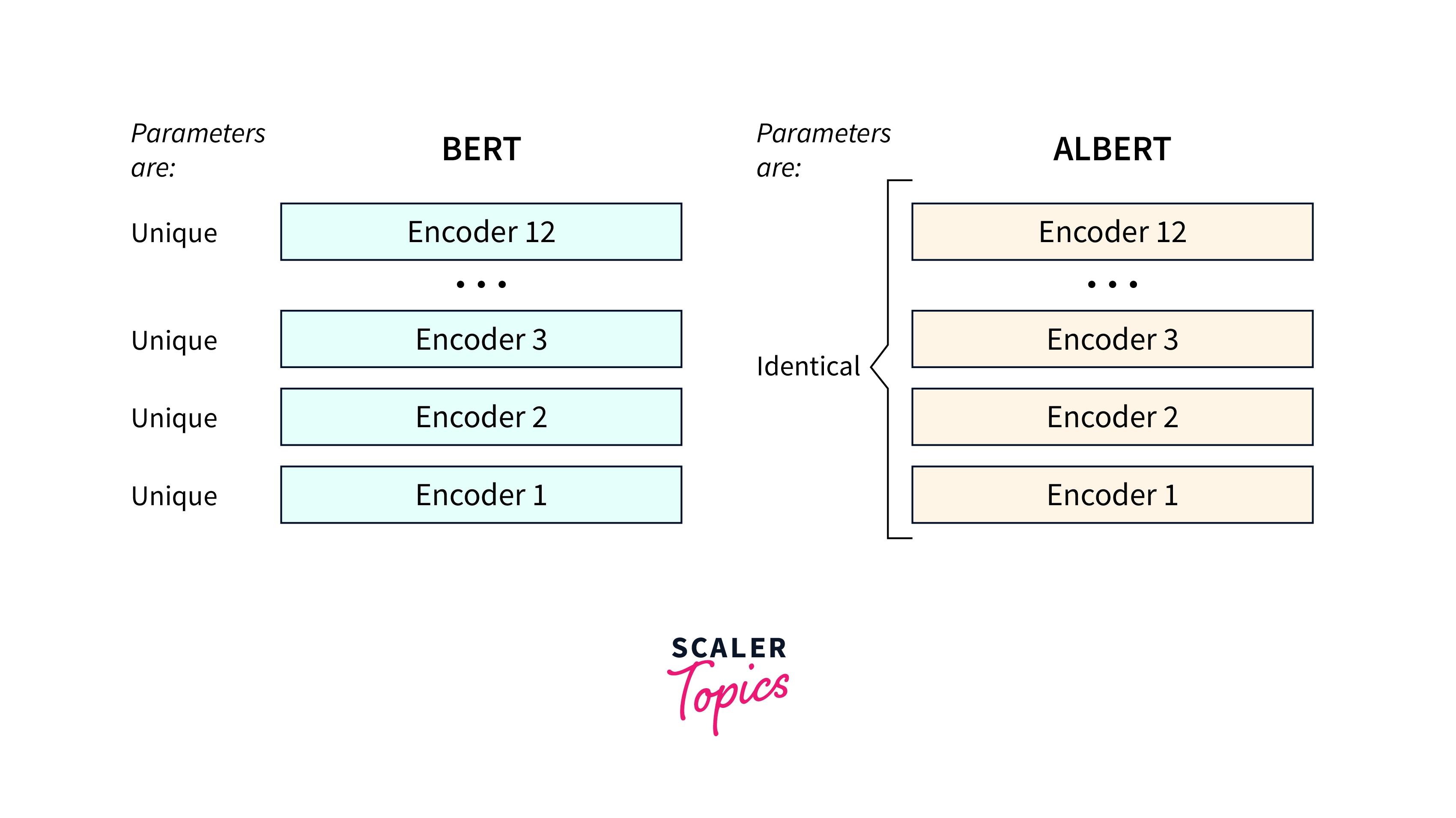
ALBERT achieves performance increase by using several techniques that make it more efficient than BERT. , For example,, it uses a technique called cross-layer parameter sharing to share parameters across different layers of the model, reducing the number of parameters that need to be trained. It also uses a technique called factorized embedding parameterization to reduce the number of parameters in the embedding layer, which is the first layer of the model.
Using the above techniques, ALBERT brings down the total parameters from about 110 million to around 12 million.
Cross-Layer Parameter Sharing
Cross-layer parameter sharing is a technique used in ALBERT (and other models) to reduce the number of parameters that need to be trained. Each layer has its own set of parameters learned during training in a typical deep-learning model. However, in a model that uses cross-layer parameter sharing, some or all layers share the same set of parameters.
For example, imagine a model with three layers, where the first and second layers have their own set of parameters, and the third layer shares the same parameters as the first layer. This means that the first and third layers will use the same set of parameters during training and inference, which reduces the total number of parameters that need to be learned.
The BERT architecture contains multiple blocks of the following layers.
- Multi-Head-Attention Layer
- Normalization
- Feed Forward Layer
- Normalization
When the parameters of these blocks are shared, which means they all have the same parameters, the total number of parameters can be significantly reduced during training and inference.
The advantage of this technique is that it allows the model to use fewer parameters, making training faster and more efficient. It can also improve the model's performance by allowing different layers to share information and learn from each other.
Factorized Embedding Parameterization
Factorized embedding parameterization is a technique used in ALBERT (and other models) to reduce the number of parameters in the embedding layer, which is the first layer of the model. In a typical deep-learning model, the embedding layer maps each word in the input text to a high-dimensional vector, which is then used as input to the rest of the model.
In a model that uses factorized embedding parameterization, the high-dimensional vectors are represented as the product of two lower-dimensional vectors. , For example,, instead of representing a word as a 300-dimensional vector, it would be represented as the product of two 150-dimensional vectors.
The advantage of this technique is that it reduces the number of parameters in the embedding layer, making training faster and more efficient. It can also improve the model's performance by allowing it to learn more specialized word representations.
Note: The original BERT model has an embedding dimension of 768, whereas, in ALBERT, it is reduced to 128.
However, there are also some potential disadvantages to using factorized embedding parameterization. One potential disadvantage is that it can make the model more difficult to interpret since the word representations are represented as the product of two vectors instead of one. Another potential disadvantage is that it can limit the expressiveness of the model since the word representations are constrained to be the product of two vectors.
Overall, factorized embedding parameterization is a useful technique for reducing the number of parameters in the embedding layer of a deep learning model. Still, it should be used carefully to avoid potential drawbacks.
Turn Learning into Career Growth
Other Differences
Another key difference between ALBERT and BERT is that ALBERT uses a technique called sentence-order prediction (SOP) to pre-train the model. This involves training the model to predict whether a sentence has been randomly shuffled, which helps it learn better to understand the relationships between words in a sentence.
RoBERTa

RoBERTa (Robustly Optimized BERT) is a variant of the BERT language processing model that has been trained on a larger dataset and for a longer period, using more advanced training techniques. This results in a better model for various natural language processing tasks.
One key difference between RoBERTa and BERT is that RoBERTa is trained on a much larger dataset, which includes more than 160GB of text data, whereas BERT was originally trained on about 16GB of text data. This allows the model to learn from various sources and capture language nuances better.
Another key difference is that RoBERTa is trained using a technique called dynamic maskin, which involves randomly masking out different tokens (e.g., words or punctuation) in the input text during training. This helps the model better understand the relationships between different tokens in a sentence, improving its performance on various tasks.
** For example,**, let's take the sentence: I am traveling today.
We can extract multiple versions of the same by masking random words in the sentence,
- [MASK] am traveling today.
- I [MASK] traveling [MASK].
- [MASK] am [MASK] traveling.
RoBERTa also uses a technique called byte-pair encoding (BPE) to tokenize the input text. This involves replacing common sequences of tokens with a single, "combined" token, which reduces the vocabulary size and allows the model to learn more efficient representations.
Overall, RoBERTa is a more powerful and performant version of BERT that is trained using advanced techniques and a larger dataset. This makes it a good choice for applications that require high-quality language representations, such as in machine translation or summarization.
ELECTRA
Performance gain in ELECTRA (Efficiently Learning an Encoder that Classifies Tokens Accurately) is achieved by training the model to generate fake text and then using a discriminator to identify which text is real and which is fake.
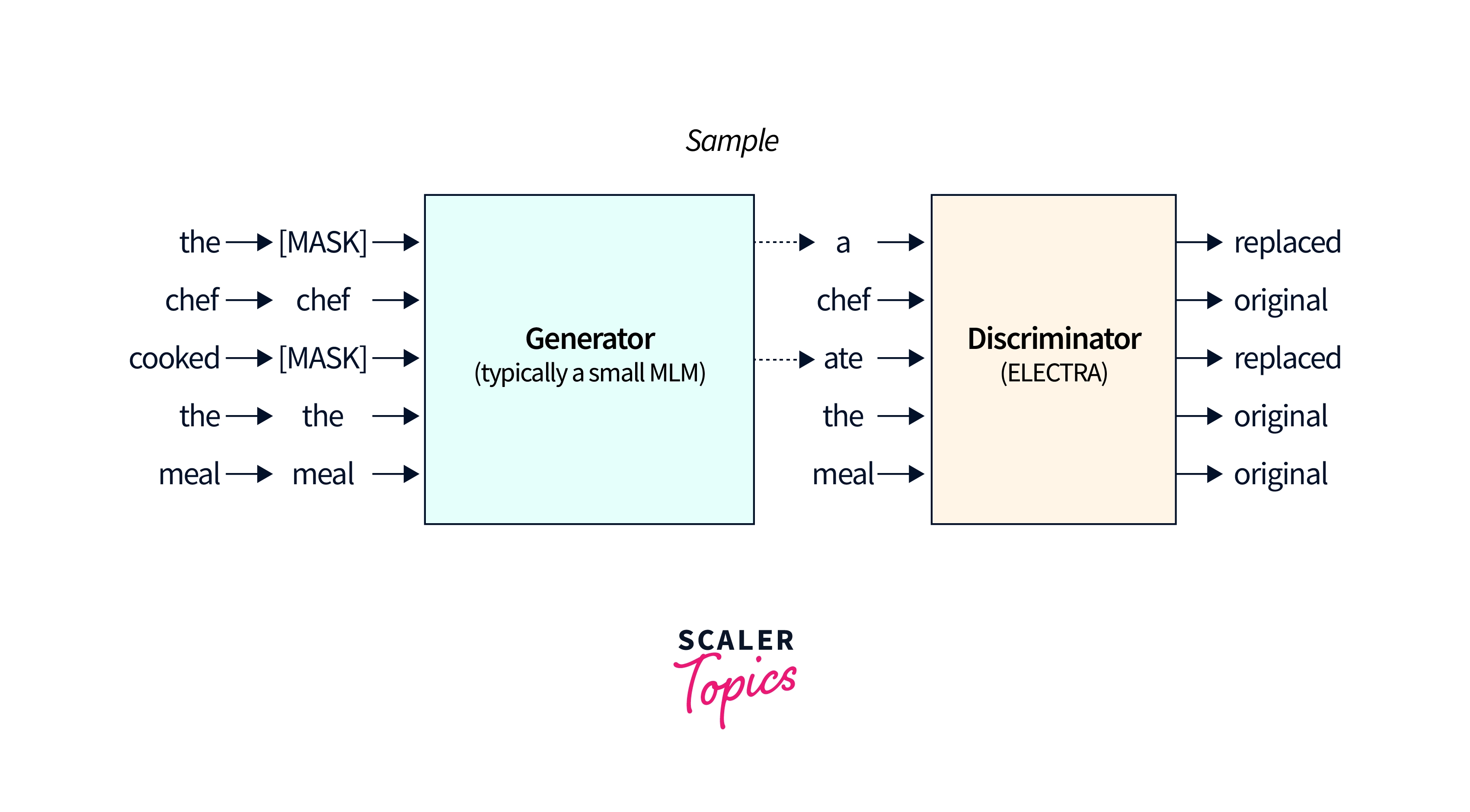
The key difference between ELECTRA and BERT is that ELECTRA uses a two-part model consisting of a generator and a discriminator. The generator is trained to generate fake text similar to the real input text, while the discriminator is trained to identify which text is real and which is fake.
, For example,, imagine a sentence where the word "dog" has been replaced with "cat". The model would be trained to identify the fake token "cat" and replace it with the original token "dog". This helps the model better understand the relationships between different tokens in a sentence, improving its performance on various tasks.
Replaced token detection is typically used with other techniques, such as masked language modeling, which involves masking out tokens in the input text and training the model to predict the masked tokens. This helps the model learn to understand better the context and meaning of the tokens in the input text.
Overall, ELECTRA is a BERT model trained using a two-part model and masked language modeling, allowing it to generate high-quality text representations. This makes it a good choice for applications requiring accurate and detailed text representations, such as summarization or question answering.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
SpanBERT
One of the BERT variants that have recently gained popularity is SpanBERT. SpanBERT is a BERT model that has been modified to handle better the problem of "span prediction" in natural language processing tasks. This means that it is better able to identify and predict the relationships between words and phrases in a sentence, which is a common challenge in tasks such as named entity recognition or question answering.
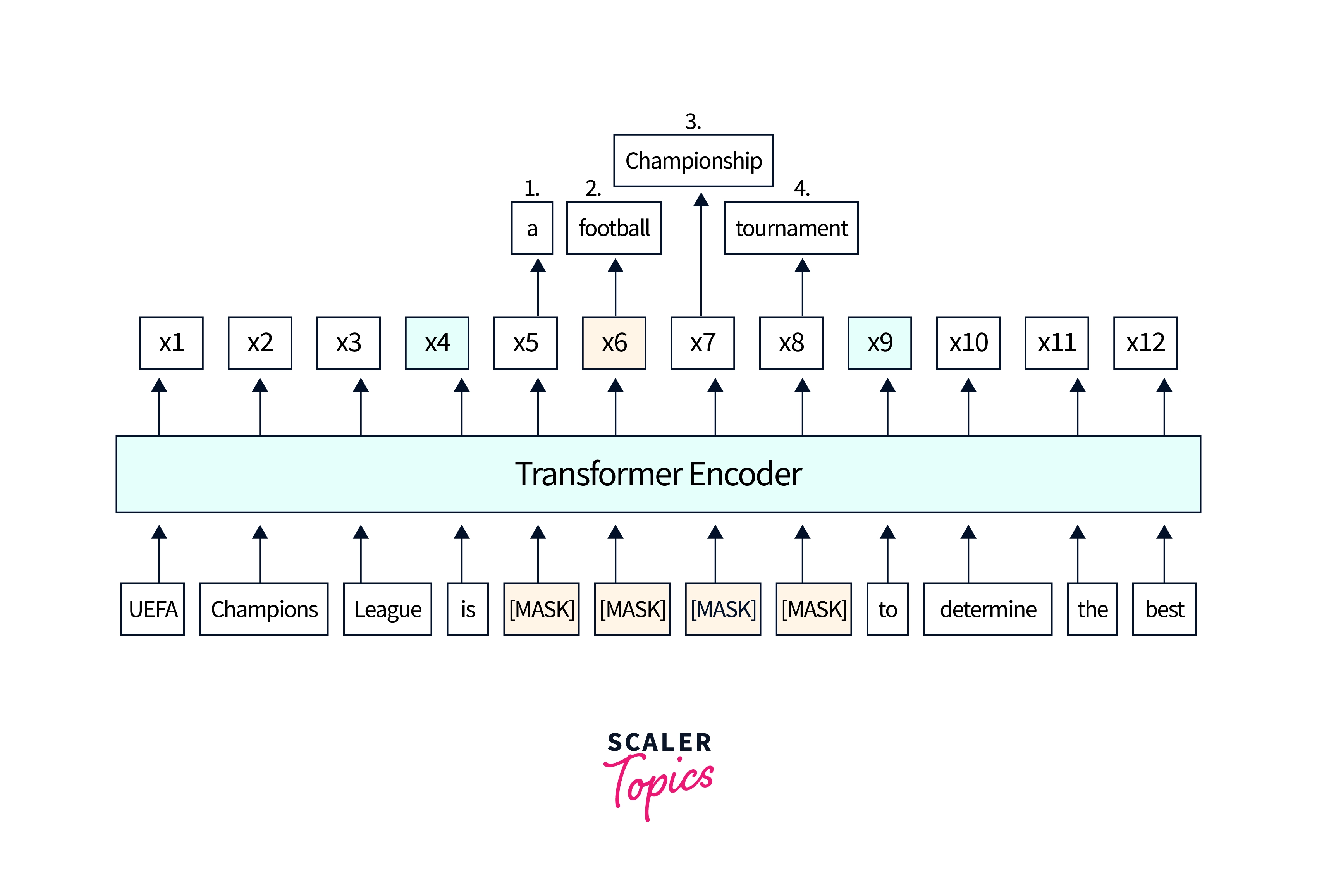
SpanBERT uses a technique called "masked language modeling with spans" during its pre-training phase to achieve this. This involves randomly masking multiple contiguous words (or spans) in a sentence and then training the model to predict the masked words based on their context. This helps the model learn to understand the relationships between words and phrases and improves its ability to handle span prediction tasks.
In addition, SpanBERT also uses a technique called "sentence order prediction", like some of the other models previously discussed, to better understand the order of sentences in a document. This involves training the model to predict the order of sentences in a document, which helps the model learn to understand the document's overall structure and improve its performance on tasks such as summarization or text classification.
Overall, SpanBERT is a powerful BERT variant specifically designed to improve the original BERT model's ability to handle span prediction tasks. This makes it a valuable tool for natural language processing tasks that involve identifying and predicting the relationships between words and phrases in a sentence.
DistilBERT
DistilBERT uses Knowledge Distillation. Knowledge distillation is a technique in deep learning to "distil" the knowledge or information learned by a complex model into a smaller, more efficient one. It involves training a smaller model to mimic the behavior of a larger, pre-trained model on a particular task.
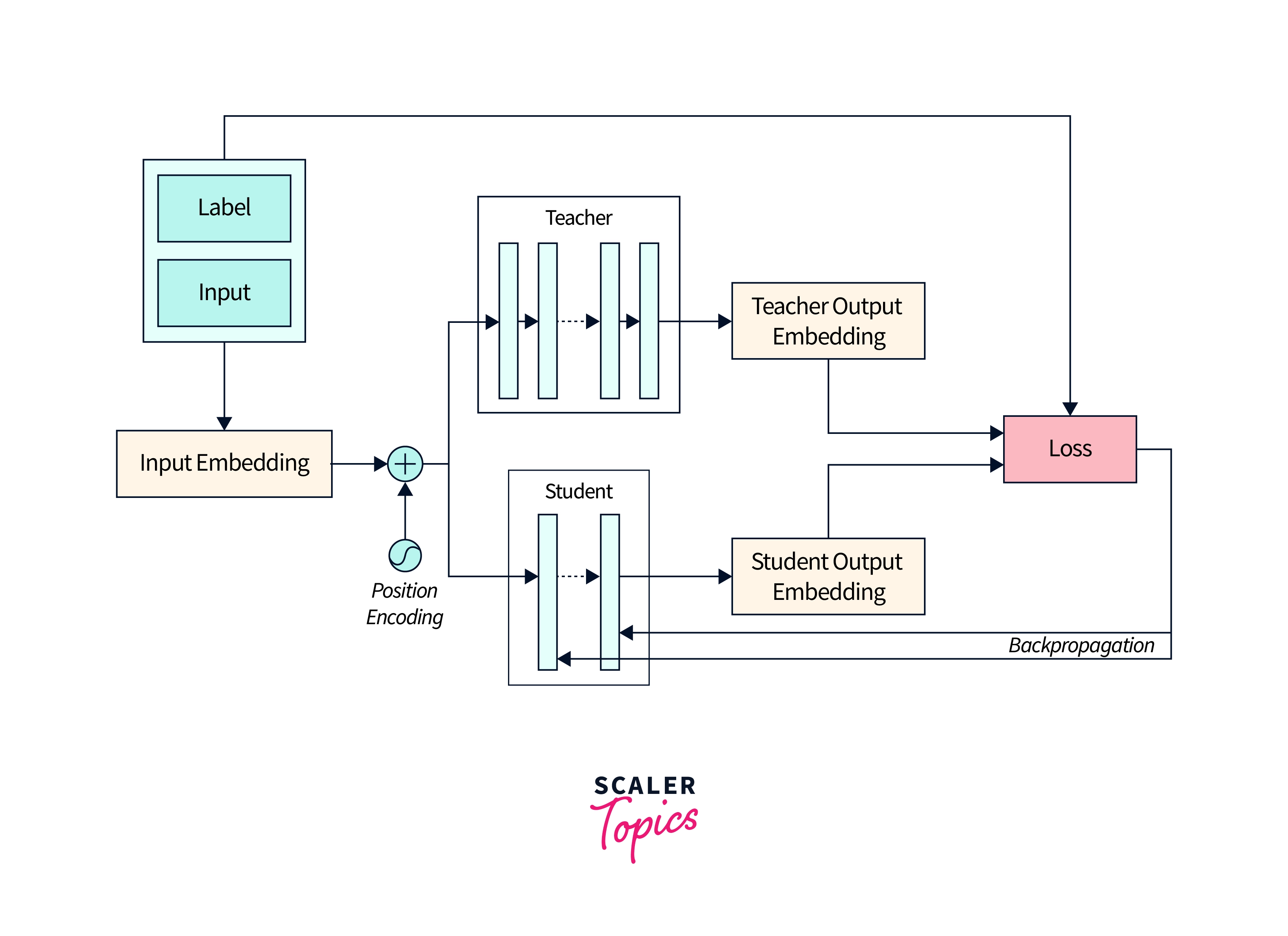
The idea behind knowledge distillation is that the larger, pre-trained model has learned to solve the task in a general and robust way, and the smaller model can learn to mimic its behavior and achieve similar performance. This makes the smaller model more efficient and easier to deploy in certain situations, such as on mobile devices.
Knowledge distillation typically involves two steps. First, the larger, pre-trained model generates predictions on a dataset. These predictions are then used as the "ground truth" labels for training the smaller model. This allows the smaller model to learn from the larger model's predictions and improve its performance on the task.
Second, the larger model's internal activations (i.e., the values computed at each layer during the forward pass) are also used to train the smaller model. This allows the smaller model to learn the larger model's internal representations, which can help it perform better on the task.
One key difference between DistilBERT and BERT is that DistilBERT is a smaller and more efficient model. It has 40% fewer parameters than BERT, with only 66 million parameters, which makes it faster to train and easier to deploy in resource-constrained situations.
Another key difference is that DistilBERT is trained using a technique called "distilled-dynamic masking", which involves randomly masking out different tokens (e.g. words or punctuation) in the input text during training. This helps the model better understand the relationships between different tokens in a sentence, improving its performance on various tasks.
DistilBERT is a more efficient and lightweight version of BERT that can be trained faster and more easily without sacrificing too much performance. This makes it a good choice for applications with limited computational resources, such as mobile devices.
TinyBERT

TinyBERT is a variant of BERT that uses a technique called knowledge distillation to "teach" a smaller, more efficient model (called the "Student") to mimic the behavior of a larger, pre-trained model (called the "Teacher"). In addition to using the Teacher's output embedding (predictions), TinyBERT allows the Student to learn from each layer in the Teacher, such as the attention module and other layers. This allows TinyBERT to produce high-quality text representations while being significantly smaller and more efficient than the original BERT model.
In the knowledge distillation process used by TinyBERT, the smaller "Student" model learns from the larger "Teacher" model at three different levels:
- The Transformer layer
- The Embedding layer
- The Prediction layer
This allows the Student to learn from the Teacher's internal representations and improve their performance on natural language processing tasks. This differs from traditional knowledge distillation, which only involves training the Student on the Teacher's final output.
TinyBERT has only about 14.5 million parameters, which is more than 7 times smaller than the original BERT model, which has 110 million parameters.
Conclusion
- In conclusion, BERT is a powerful and versatile language processing model widely adopted in natural language processing applications.
- However, the original BERT model has some limitations, such as its large size and computational complexity.
- Several variants of BERT have been developed to address these limitations, each with its unique characteristics and performance capabilities.
- Some of the most notable BERT variants include ALBERT, RoBERTa, ELECTRA, DistilBERT, SpanBERT, and TinyBERT.
- Each of these models has been modified in some way to improve upon the original BERT model, such as by increasing performance, reducing computational complexity, or improving efficiency.
- These variants of BERT can be useful in various natural language processing tasks, depending on the application's specific requirements.