How to create a Spell Checker with NLP?
Overview
A spell checker is a tool used for analyzing and validating spelling mistakes in the text. Recently, the role of a spell checker has diversified and it is also used to suggest possible corrections to the detected spelling mistakes, auto-correct functionality, and even sentence correction as a whole based on context and also grammar suggestions.
What are We Building?
Most spoken and written languages in the world are diverse, contain a lot of nuisances and are grammatically rich, hence are very complex to handle.
- Grammar especially is vital for effective communication and transmission of information and is used differently by different speakers in written text.
- To learn the rules of the different languages and styles of the different writers is a very challenging task for algorithms and machines.
- Fortunately, these days with the utility of huge computing power and an arsenal of natural language processing (NLP) techniques provides a solution to this problem.
Spell checkers ingrained into the text processors comes to aid with error detection and correction as basic tasks necessary for any text processing software or tool.
Applications of Spell Checker
- We can use an arsenal of NLP techniques to detect wrongly spelled words and then provide possible correct word suggestions and the probability of occurrence of each word in the corpus.
- We can use spell checker algorithms to implement the autocorrect functionality that can be used every day on our laptops, cell phones, computers, etc.
- One example of autocorrect is, if you type the word rnunnuing, chances are very high that you meant to write running.
In this article, we aim to create a basic auto-correct spell-checker tool and explore the intuition and workings of the algorithm.
Description of Problem Statement
- Utility of spelling correction: In the modern internet era, high-quality content is an important asset in dispersing information and keeping people abreast of important things happening around them.
- The quality of the content is mainly determined by the typos, misspelled words, and grammatical mistakes made by the authors of the text.
- Hence we need to add an additional layer if we are to fabricate the content error-free and make things professional both from the viewpoints of the author and the consumer.
- Examples of the need for spelling correction: Misspelt searches result in difficulty in finding relevant information.
- Some basic examples like when users are searching for restaurants on Yelp, finding friends on Facebook, shopping on multiple websites, and finding songs on Spotify.
- It is also relevant and necessary for tasks like machine learning / NLP as a preprocessing step to tasks like sentiment analysis, intent detection, speech recognition disambiguation, chatbots etc.
- Classification of misspelled words: Misspelt words are classified into two groups, non-word errors where the resulting token does not exist in the target language and real-word errors where the resulting token is a valid word of the target language but different from the intended word.
- The non-word errors are either not valid or not present in the lexicon.
- Real-word errors are usually more difficult to detect and correct than non-word errors.
Error classification for Spell Checkers
- The different sources of noise in the human-written text can be categorized as typographical and cognitive errors.
- Typographic errors also known as typos, consists of operations like: Insertion of a character, deletion of a character, replacement of a character, and transposition which is swapping two neighboring characters.
- Common spelling errors - These are the ones that have an error in the spelling by 1-2 characters and which occur commonly. Example - viruz ( virus ) , treatmeit ( treatment )
- Words with a character in between them - These are the ones with a character exists between two tokens/strings. Example - sanitized/dry ( sanitized dry ) , handuclean ( hand clean )
- Words with recurring characters - Words with characters that occur repeatedly. Usually used when trying to express some sort of emotion in text. Example - feeeevvvveeerrrrr ( fever ), facemaskk ( facemask )
- Cognitive errors entail operations like Phonetic errors where wrong word choice is due to the similar pronunciation of words (e.g. confusing there with their) and Grammatical errors where wrong word choice or wrong sentence structure due to the lack of knowledge of grammatical rules (e.g. confusing his with her).
- Typographic errors also known as typos, consists of operations like: Insertion of a character, deletion of a character, replacement of a character, and transposition which is swapping two neighboring characters.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Pre-requisites
Context-free vs. context-dependent error correction
Approaches to spelling correction can be divided into context-free error correction algorithms (also called isolated-word error correction algorithms) and context-dependent error correction algorithms.
- Context-free error correction algorithms: Address the problem of detecting and correcting misspelled words without considering the context a word appears.
- Error detection is done by a lookup in a dictionary of correctly spelled words, or by analyzing whether a word’s character n-grams are all legal n-grams of the language at hand.
- Candidate generation and ranking is done based on the minimum edit distance to the misspelled word, similarity keys, character n-grams, confusion probabilities, word frequencies, or rule-based.
- Context dependent error correction algorithms: Context-free error correction algorithms can only detect and correct a fraction of all spelling errors and will be unable to detect real-word errors.
- Context is also needed to dissolve ambiguities. For example, consider the misspelled word yello.
- Is the intended word hello, yellow, or yell? The answer depends on the context: different corrections are plausible for the sequences Bananas are yello., yello world and Don’t yello at me..
Some common algorithms for spell-checking include:
- We can build a basic spell checker simply by using a dictionary of words and then use minimum edit distance algorithm which can be very simple yet powerful.
- We can also build a spell checker that uses a combination of techniques like edit distance, phonetics, and fuzzy search which gives superior performance with a balance of accuracy and speed.
- We can also train a sequence to sequence-based deep learning algorithms from a corpus of data that can handle different kinds of errors directly.
- Off late, large language models proved powerful in utilizing the context of the word also well and correcting all the errors in a sentence directly. These are called contextual spell checkers.
- The only drawback of deep learning based models is that they are slow and there is difficulty in implementing them as they have huge overhead during in runtime.
How Are We Going to Build This?
Traditional spell-checking algorithms typically divide the spell-checking task into three main subtasks:
- Error detection: This is for distinguishing whether or not a word is misspelled.
- Candidate generation: This is for generating a set of candidate words that are similar to the misspelled word.
- Candidate ranking: This is the final step for ranking the candidate words according to the probability that they are the intended word for the misspelled word, or determining only the most likely candidate word.
Minimum Edit Distance for Spell Checker
Let us implement a spell checker algorithm using the edit distance method which takes a word as misspelled by default and generates candidates by making edits at different lengths and it compares against the dictionary and assigns probabilities based on their occurrences in the corpus.
- Edit Distance (also called Levenshtein Distance): Edit Distance is a measure of similarity between two strings referred to as the source string and the target string.
- The distance between the source string and the target string is the minimum number of edit operations (deletions, insertions, or substitutions) required to transform the source into the target. The lower the distance, the more similar the two strings.
- Some other common applications of the Edit Distance algorithm are spell-checking, plagiarism detection, and translation memory systems.
Let us see an example of edit distance between the words ellu and hello:
- We simply need to count the total edits that need to go from source string ellu to correct string hello.
- We can see from the illustration that we need one insertion, one substitution, and one deletion, so in total 3.
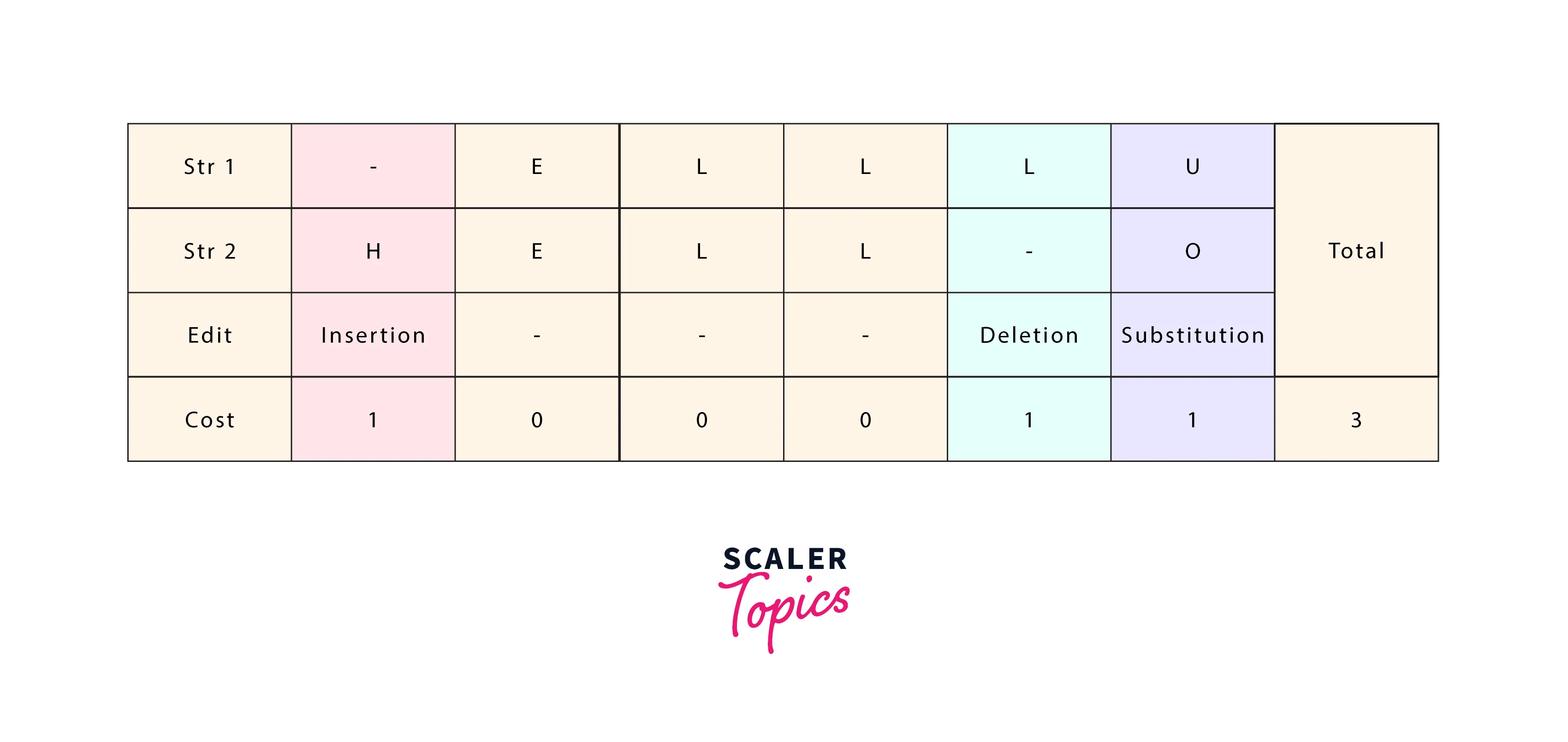
Minimum Edit Distance Algorithm (MED)
- The algorithm checks if the word is in the dictionary, and exits further processing if it is present in the dictionary.
- It then generates all the words one Levenshtein distance away. If any of these are in dictionary, then it outputs these words.
- A distance matrix is created between the misspelled word and all possible permutations (one Levenshtein) of the word.
- If we take a word and for basic implementation, we can use brute force to find all possible edits, such as delete, insert, transpose, replace, and split.
- Example: For the word abc, possible candidates will be: ab ac bc bac cba acb a_bc ab_c aabc abbc acbc adbc aebc etc.
- Each and every word is added to a candidate list.
- We repeat this procedure for every word for a second time to get candidates with bigger edit distance (for cases with two errors).\
- The algorithm then generates all the words two Levenshtein distance away. If any of these are in the dictionary, then it outputs these words.
- Each candidate is estimated with a unigram language model (or single-word corpus).
- If there is more than one candidate in each step, the algorithm takes the ones with the highest score (score can be computed based on the corpus)
- For each vocabulary word, frequencies are pre-calculated, based on the big text corpora we have collected. The candidate word with the highest frequency is taken as an answer.
- Dynamic Programming (DP): Instead of brute force we have taken as an example, we can use DP for calculating the least possible changes needed to correct the misspelled words, and suggesting the most appropriate words as the corrections.
Steps for building the Minimum Edit Distance algorithm
- Step 1: Preparation of the word database.
- The database works great if we can use get the search words and their occurrence based on the actual usage or domain of application.
- If there is no such database, we can instead use a large set of text from any available corpus and count the occurrence/popularity of each word from that.
- Step 2: Word checking - Finding words that are similar to the one checked.
- Similar means that the edit distance is low (typically 0-1 or 0-2).
- The edit distance is the minimum number of inserts/deletes/changes/swaps needed to transform one word to another.
- Choose the most popular word from the previous step and suggest it as a correction (if other than the word itself).
Final Output
Let me show you the final output which will be building.
Input Text: "I came home so that as I would rather participate in the function the next dys."
Building a Spell Checker with NLP
Turn Learning into Career Growth
Libraries and Imports
Jupyter Notebook can be installed from the popular setup of Anaconda or Jupyter directly. Reference instructions for setting up from source can be followed from here. Once installed we can spin up an instance of the jupyter notebook server and open a python notebook instance and run the following code for setting up basic libraries and functionalities.
If a particular library is not found, it can simply be downloaded from within the notebook by running a system command pip install sample_library command. For example to install seaborn, run the command from a cell within jupyter notebook like:
Dataset
- There is no specific dedicated dataset for building and evaluating spell checkers. Practitioners usually use data from various sources like Wikipedia, news articles, short stories, newspapers, online websites, and others.
- The dataset we use is a Kaggle dataset based on the complete works of Shakespeare and corpus contains text collected from various writings. The dataset can be downloaded from here The Complete Works of William Shakespeare. It can be downloaded and kept in the same folder from which the code we write can be run.
- Change the location of the file to where it is present in your system here
Data Preprocessing
- Real-world data are often incomplete, inconsistent, inaccurate, and lack specifically required trend. Therefore, data preprocessing is a primary and most significant step in natural language processing (NLP). It is a crucial process as it directly affects the success rate of the model. The typical steps involved in data preprocessing are:
- Lexical Processing tasks like tokenization, stop word removal, stemming, lemmatization, TF-IDF representation
- Syntactic Processing like POS (Part of Speech) Tagging and NER (Named Entity Recognition)
Now we will take the set of words representing the corpus prepared from earlier and prepare a word count dictionary where key is the word and values are the frequencies of the words.
We will now use the word count dictionary where the key is the word and value is its frequency and prepare a new dictionary where keys are the words and the values are the probability that a word will occur.
Named-entity recognition (NER) NER is a problem that has a goal to locate and classify named entities mentioned in unstructured text into pre-defined categories such as person names, organizations, locations, medical codes, time expressions, etc.
- With NER, we can scan through large documents and finding people, organizations, and locations available and then later we needn't run spelling corrections on these entities.
Let us see an example of how to do NER in python using Spacy library.
- The above gives output as New York is GPE where GPE is a Geo-Political Entity. This way we can incorporate NER in the pipeline for spell checker algorithms.
- Spacy and most other libraries also support the many entity types for example like: PERSON, NORP (nationalities, religious and political groups), FAC (buildings, airports etc.), ORG (organizations), GPE (countries, cities etc.), etc, for NER.
Building the Spell Checker Model
Let us write a few helper functions here that will do the different operations required for suggesting the correct words in the spell checker algorithm. Let us look at the brief summary of each of these functions:
- delete_letter - When we give a word, this function will return all the possible strings that have one character removed.
- switch_letter - When we give a word, this function will return all the possible strings that have two adjacent letters switched.
- replace_letter - When we give a word, this function will return all the possible strings that have one character replaced by another different letter.
- insert_letter - When we give a word, this function will return all the possible strings that have an additional character inserted.
- edit_one_letter - This function will give all possible edits that are one edit away from a word such that the edits consist of the replace, insert, delete, and optionally the switch operation.
- edit_two_letters - We can then generalize the edit_one_letter function to implement to get two edits on a word. We will have to get all the possible edits on a single word and then, for each modified word, we would have to modify it again.
Let us wrap all the helper functions into a single function here.
- This function takes the word, the dictionary of probabilities, the vocabulary set of the overall corpus, and the other input parameters if any, we want to incorporate into a spelling suggestion function.
- This function will output again with the most probable n corrected words and their probabilities which we need to pick again based on our need.
Let us run the overall function on a few words here.
The sample input and output look like below:
- When we provide an input word that is spelled wrong, the spell checker function we wrote provides all the alternate suggestions based on the dictionary and edits.
- It also provides a probability for each word from which we can pick top word or the next ones and incorporate into our workflow.
Output:
Contextual models for Spell Check
There are many implementations based on deep learning language models that can efficiently handle out-of-vocabulary words and also take context into consideration in correcting the spelling.
Let us look at an example of one such open-source implementation using Spacy.
- The contextual spell check package focuses on Out of Vocabulary (OOV) word or non-word error (NWE) correction using the BERT model.
- The library performs this Contextual spell correction using BERT (bidirectional representations). The idea of using BERT was to use the context when correcting NWE.
Following is the output of the above code. We can see that it could handle the dys word and interpret it as the day, whereas our corpus-based edit distance algorithm gave the highest probability of dye. The only caveat to the deepest learning-based implementations is that they can be expensive and slow to run.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
What’s Next?
- The algorithm we have written is basic and, to a large extent depends on the corpus and dictionary we have built, and if a certain word we give as input is not present in the corpus, it doesn't give any alternate suggestion. This can be solved by giving a large enough corpus as input.
- The model also doesn't give great performance and will be unable to scale beyond distance two.
- The model will also be slow and spell checking a 200 word paragraph on average takes about 5 to 10 seconds.
- We can take the help of many techniques to augment the base algorithm and also use other techniques and libraries utilizing NLP & Machine learning techniques to implement the spell checker.
- One such technique is dynamic programming which can help in finding the correct word in the minimum steps possible.
- To find the shortest path to go from the word, a dynamic programming system helps us in finding the minimum number of edits required to convert a string into another string.
- Fast fuzzy search is another technique that can be used to boost the accuracy of spell checkers. It also helps in other tools like indexed DB searches, elastic search, NLP, and speech recognition.
Conclusion
- Spell checker is a combination of features and tools that checks for misspellings in a text and is often needed in text preprocessing & also embedded in software such as word processors, text clients, dictionaries or search engines, etc.
- Different algorithms can be used for handling tasks of spell checker like error identification, candidate generation, and candidate ranking.
- Levenshtein distance between two words is the minimum number of single-character edits (insertions, deletions, or substitutions) required to change one word into the other.
- Dynamic programming algorithm can be combined with Levenshtein distance to quickly compute the lowest cost path and suggest possible corrections in spell checkers.
- Distance-based methods with optimizations to handle different scenarios are the best algorithms that can achieve a good balance of accuracy and speed.