Decoding Strategies for Transformers
Overview
In the realm of language generation, decoding is the process of transforming a vector representation into coherent text output. Decoding strategies are pivotal in shaping the quality and attributes of generated text. This article delves into multiple decoding techniques, highlighting greedy decoding, beam search, nucleus sampling, temperature scaling, and top-k sampling as significant decoding strategies for transformers. These strategies profoundly influence the outcome's quality, ensuring it aligns with the desired characteristics.
Greedy Decoding
Greedy decoding is a straightforward and widely used strategy in transformer models. At each decoding step, this strategy selects the token with the highest probability without considering the impact on future tokens. While computationally efficient, greedy decoding may result in sub optimal outputs. It needs to explore alternative paths, leading to repetitive or incomplete sentences.
Step 1: Setting Up the Environment
First, we need to install the required libraries and load the pre-trained GPT-2 model. We'll use TensorFlow as our deep learning framework and the Hugging Face Transformers library for the model.
Step 2: Generating Text Using Greedy Search
Greedy search generates text one token at a time, always selecting the token with the highest probability. Here's how you can use it:
Output:
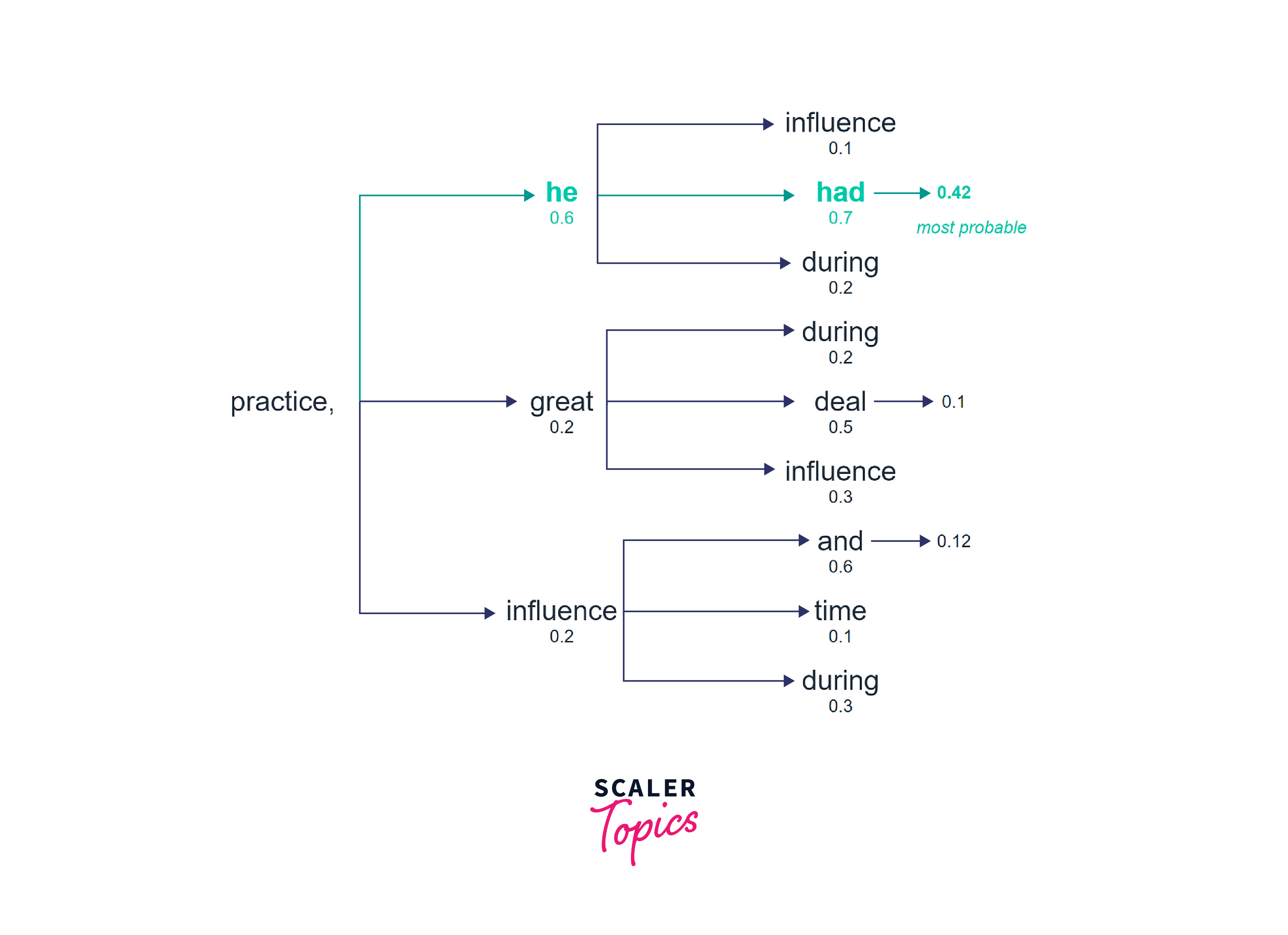 Despite its limitations, greedy decoding can be advantageous in scenarios where efficiency is a priority and minor errors can be tolerated. Real-time processing applications, such as speech recognition systems, benefit from the simplicity and speed of greedy decoding.
Despite its limitations, greedy decoding can be advantageous in scenarios where efficiency is a priority and minor errors can be tolerated. Real-time processing applications, such as speech recognition systems, benefit from the simplicity and speed of greedy decoding.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
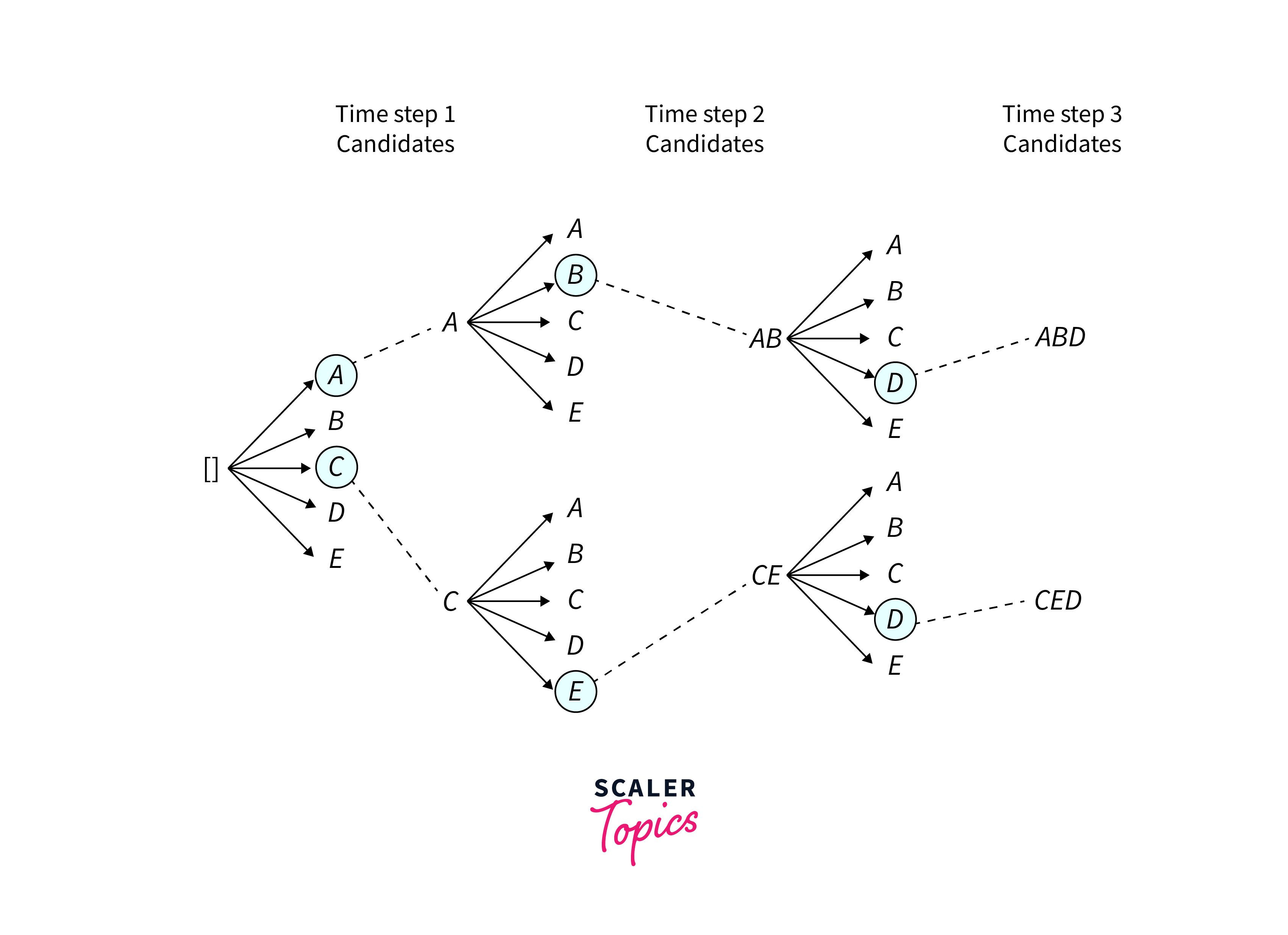
Beam Search
Beam search is a more advanced decoding strategy that addresses some of the shortcomings of greedy decoding. Instead of selecting only the most probable token at each step, beam search maintains a list of the top-k candidates, known as the beam width. Each candidate is scored based on the probability of the current token and the accumulated probability of previous tokens.
Step 1: Activating Beam Search Beam search is a more advanced text generation technique that explores multiple possibilities in parallel. To enable beam search and early stopping, use the following code:
Output:
Step 2: Controlling N-gram Repetition
To avoid repeating the same n-grams in the generated text, you can set the no_repeat_ngram_size parameter:
Step 3: Returning Multiple Sequences You can also generate multiple alternative sequences with beam search by specifying the 'num_return_sequences' parameter:
Output:
Beam search allows the model to explore multiple paths simultaneously, potentially leading to more coherent and diverse outputs than greedy decoding. However, increasing the beam width requires more computational resources. Selecting an appropriate beam width is crucial since a narrow beam might result in sub optimal outputs, while a wide beam significantly slows down the decoding process.
Nucleus Sampling (Top-p Sampling)
Nucleus Sampling, also called Top-p Sampling, is a probabilistic decoding strategy that balances beam search and greedy decoding. Instead of considering a fixed number of candidates, top-p sampling samples from a subset of tokens with a cumulative probability greater than a predefined threshold, p.
Step 1: Choose a Language Model Begin by selecting a pre-trained language model that you want to use for text generation. Popular models include GPT-3, GPT-2, and BERT. Libraries like Hugging Face Transformers provide easy access to these models.
Step 2: Setup and Configure Ensure that you have the necessary Python libraries installed, including Hugging Face Transformers. You can install it using pip:
Define the Top-p parameter (p) to control text generation. Experiment with different values to find the desired balance between diversity and focus in the generated text
Step 3: Generate Text Generate text using the chosen language model and Top-p sampling. Provide input prompts or context as required.
Output
Top-p sampling allows for more diverse outputs than beam search while avoiding the computational overhead of considering all possible tokens. By adjusting the p value, we can control the trade-off between output quality and diversity. Lower p values lead to more focused and deterministic outputs, while higher values introduce more randomness and diversity.
Temperature Scaling
Temperature scaling is a decoding strategy used in language generation to control the randomness and diversity of generated outputs. It involves adjusting the temperature parameter during the sampling process. The temperature parameter determines the level of randomness in the generated text. Higher values of temperature (e.g., 1.0) result in more diverse but potentially less coherent outputs, while lower values (e.g., 0.5) lead to more focused and deterministic outputs.
Step 1: Choose a Language Model Choose a pre-trained language model that you want to use for text generation. Popular models include GPT-3, GPT-2, and BERT. You can use libraries like Hugging Face Transformers to access these models easily.
Step2: Setup and Configure Ensure you have the necessary Python libraries installed, including Hugging Face Transformers. You can install it using pip:
Define the temperature parameter (T) to control text generation. A value of 1.0 produces more diverse text, while smaller values make the text more focused. Experiment with different values to find the desired level of randomness.
Step 3: Generate Text Generate text using the chosen language model and temperature scaling. You'll need to provide input prompts or context, depending on your application.
Output
By increasing the temperature, the model assigns more equal probabilities to different tokens, allowing for exploring alternative options. This can be useful in generating creative and diverse responses. On the other hand, decreasing the temperature biases the model towards selecting high-probability tokens, resulting in more conservative and deterministic outputs.
Turn Learning into Career Growth
Top-k Sampling
Top-k sampling, also known as top-p sampling or nucleus sampling, is a decoding strategy used in language generation to control the number of tokens from which the model can sample during the generation process. It involves setting a threshold k or p to limit the number of tokens considered for sampling.
In top-k sampling, the model only considers the top-k most likely tokens at each step of the generation process. This restricts the choice of tokens to a subset of the vocabulary, ensuring that the generated text is focused and avoids highly unlikely or irrelevant tokens. By adjusting the value of k, one can control the level of diversity in the generated output.
Nucleus sampling, also referred to as top-p sampling, is a variant of top-k sampling that considers the smallest set of tokens whose cumulative probability exceeds a given threshold p. Both top-k and nucleus sampling effectively balance the trade-off between generating coherent and diverse outputs.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
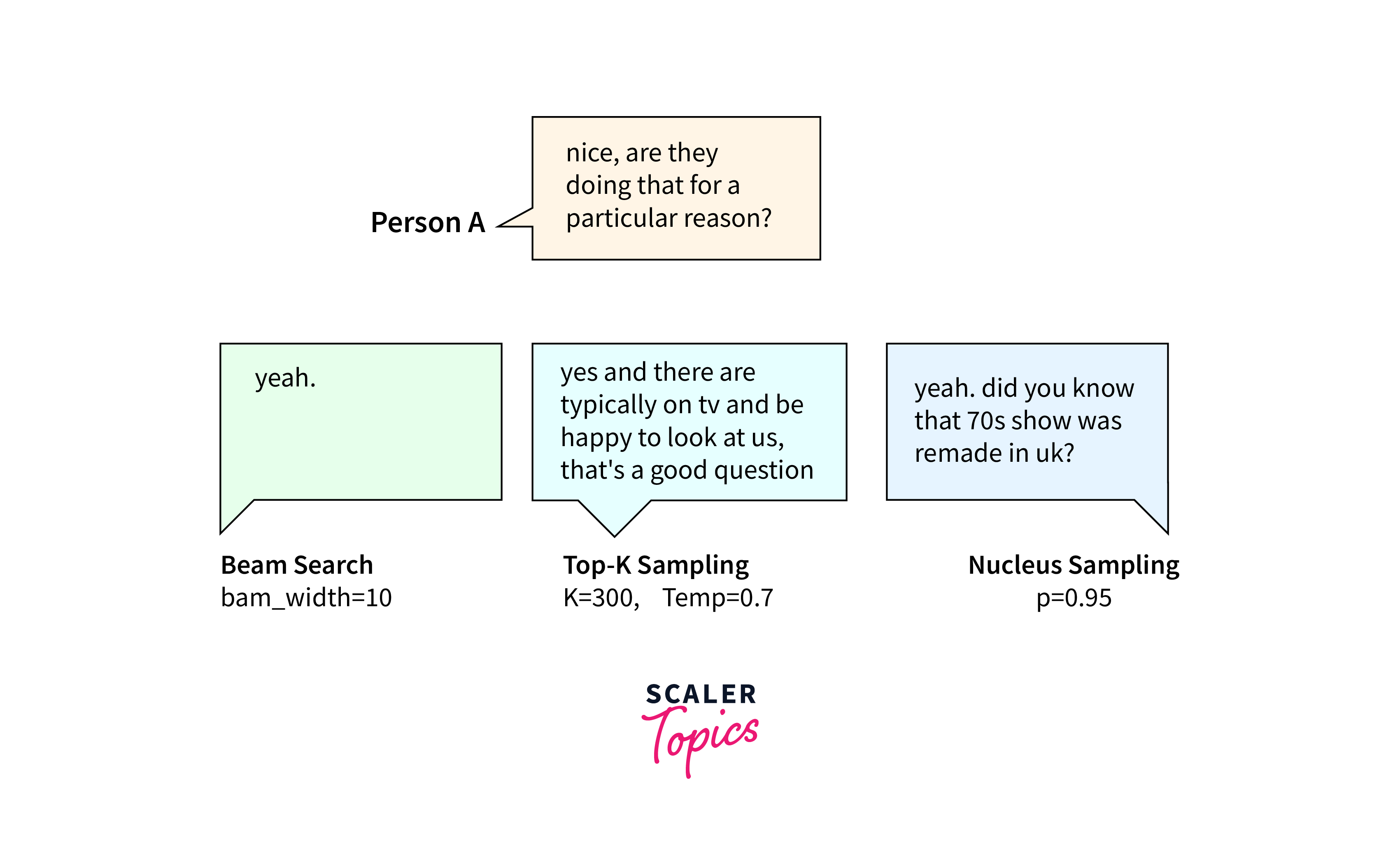
Sampling vs. Greedy Search
Sampling and greedy search are two different decoding methods used in natural language processing as discussed above. The choice between them depends on the desired output characteristics.
Sampling allows for more exploration and variety in the generated text, while greedy search focuses on the most probable options, potentially resulting in repetitive output. The table below provides a general comparison between sampling and greedy search.
| Sampling | Greedy Search |
|---|---|
| Randomly selects the next token based on the probability distribution over the entire vocabulary given by the model . Reduces the risk of repetition. | Always chooses the token with the highest probability as the next token . May result in repetitive output. |
| Enables exploration of less probable options, leading to more diverse and creative output. | Focuses on the most probable option, potentially missing out on high probability words hidden behind lower probability words . |
| Can result in more human-sounding text due to the variation introduced by random selection. | Tends to produce text that is less varied and more deterministic. |
| Requires setting the parameter do_sample=True and num_beams=1 to enable multinomial sampling. | No specific parameters are required for greedy search as it is the default decoding method. |
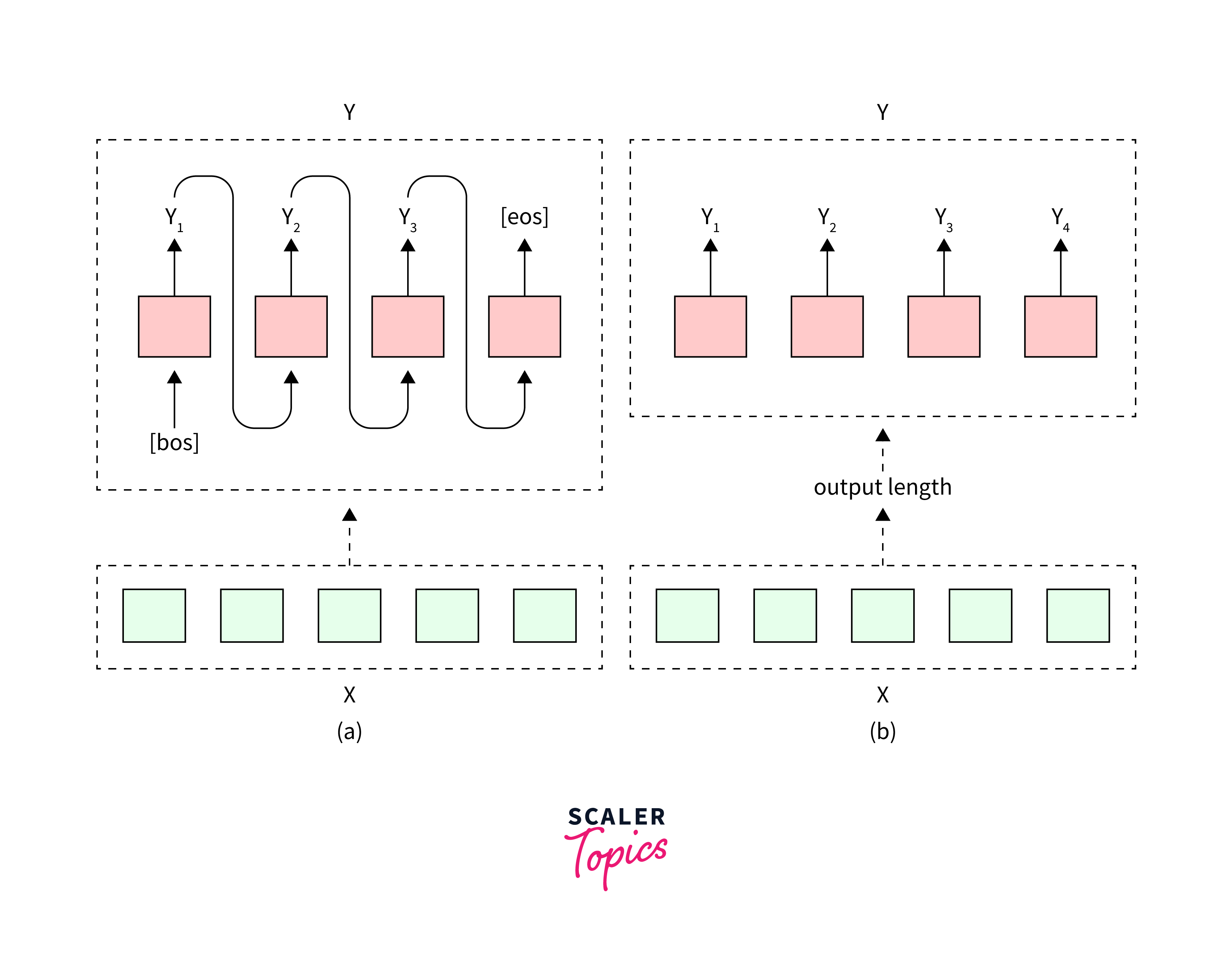
Autoregressive vs. Non-Autoregressive Decoding
Autoregressive decoding and non-autoregressive decoding are two different approaches used in generating sequences.
Autoregressive decoding generates tokens one by one, considering the context of previously generated tokens. It tends to produce more accurate but slower output. On the other hand, non-autoregressive decoding generates tokens in parallel, without explicit dependencies on previously generated tokens. It prioritizes speed but may sacrifice accuracy. The choice between these methods depends on the specific requirements of the task at hand.
The table below explain the general differentiation between Autoregressive vs. Non-Autoregressive Decoding.
| Autoregressive | Non-Autoregressive |
|---|---|
| Generates output tokens sequentially, conditioning each token on previously generated tokens. | Generates output tokens in parallel, without explicit dependencies on previously generated tokens. |
| Tends to have higher accuracy as it considers the context of the entire sequence during generation. | May sacrifice accuracy for speed, as it does not rely on sequential generation. |
| Requires a language model to predict the next token based on the previous tokens, which can be computationally expensive. | Does not require a language model, allowing for faster generation. |
| Often used in tasks where coherence and contextual understanding are important, such as machine translation or text generation. | Suitable for tasks where real-time or fast generation is prioritized, such as speech recognition or image captioning. |
Advantages of Using Decoding Strategies in Transformers
-
Improved Text Quality: Decoding strategies allow for the generation of higher-quality text by considering various factors such as coherence, context, and language fluency. This leads to outputs that are more accurate and contextually relevant.
-
Control over Diversity: Decoding strategies provide control over the diversity of generated text. Depending on the chosen strategy and its parameters, you can either prioritize generating diverse outputs or more focused and deterministic ones.
-
Enhanced Creativity: Strategies like temperature scaling and top-k sampling enable the model to introduce controlled randomness into the generated text. This can lead to more creative and novel responses, making the model suitable for creative writing, brainstorming, and other tasks that require generating unique content
-
Customization for Specific Tasks: Decoding strategies can be tailored to specific task requirements. For example, in machine translation, you can choose strategies that prioritize fluency and accuracy, while in text generation for storytelling, you can opt for strategies that encourage imaginative and varied narratives.
-
Balanced Trade-offs: Decoding strategies allow you to strike a balance between different trade-offs, such as quality vs. diversity or speed vs. accuracy. This flexibility ensures that you can adapt the model's behavior to suit the particular needs of your application.
-
Efficiency: While some decoding strategies, like beam search, can be computationally more intensive, they often lead to more efficient generation compared to training a separate model for each task. This efficiency is crucial for real-time and resource-constrained applications.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Conclusion
- Decoding strategies like greedy decoding, beam search, nucleus sampling, temperature scaling, and top-k sampling improve the output quality of Transformer models during text generation.
- These strategies offer different trade-offs in output diversity, accuracy, and computational efficiency, allowing researchers and practitioners to choose the most suitable strategy based on their requirements.
- Autoregressive and non-autoregressive decoding are two different approaches that impact the coherence, speed, and accuracy of generated text.
- Using decoding strategies in Transformers enhances the flexibility and performance of natural language processing tasks, such as machine translation, text generation, and speech recognition, leading to advancements in these fields.