HuggingFace DistilBERT
Overview
In this article, we will explore DistilBERT, a smaller, faster, and lighter version of the popular BERT model. We start with an overview of the topic, followed by an introduction to the need for a DistilBERT-like model. We then discuss the concept of knowledge distillation, which transfers knowledge from a large, complex model to a smaller, simpler one. We cover the DistilBERT architecture, implementation with Hugging Face, and how to use DistilBERT in projects. Finally, we compare BERT and DistilBERT, highlighting their similarities and differences.
Why Do We Need a DistilBERT-like Model?
DistilBERT, a scaled-down and more efficient variant of BERT, offers several advantages that make it a valuable tool in natural language processing (NLP):
-
Computational Efficiency: DistilBERT is designed to be computationally effective and quicker to train compared to larger models like BERT. With 40% fewer parameters, it requires less computation and time, which is particularly beneficial when working with large datasets or training models on a tight schedule.
-
Resource-Constrained Environments: The reduced size of DistilBERT makes it well-suited for resource-constrained situations, such as mobile and edge devices. Its smaller memory footprint allows it to be deployed on devices with limited memory capacity, enabling NLP applications in environments where computational resources are limited.
-
Comparable Performance: Despite its smaller size, DistilBERT aims to perform similarly to BERT in terms of accuracy and performance. It achieves this by distilling the knowledge from the larger BERT model into a more compact representation. As a result, DistilBERT can be a viable alternative when computational resources are limited without sacrificing much accuracy.
-
Transfer Learning: DistilBERT can serve as a starting point for transfer learning, where a pre-trained model is fine-tuned on a specific task or domain. This adaptability makes it versatile for various NLP applications, allowing developers to leverage the benefits of pre-training while customizing the model for specific tasks.
DistilBERT's smaller size, computational efficiency, and comparable performance to BERT make it a valuable tool in resource-constrained environments and time-sensitive applications. Its ability to support transfer learning further enhances its versatility in addressing a wide range of NLP tasks.
What is Knowledge Distillation?
Knowledge distillation is a powerful technique in machine learning that allows us to transfer knowledge from a large, complex model to a smaller, simpler one. By doing so, we can reduce the memory footprint and computational requirements of the model without significant performance loss.
The fundamental idea behind knowledge distillation is to leverage the soft probabilities or logits of a larger "teacher network" along with the available class labels to train a smaller "student network". These soft probabilities provide more information than just the class labels, enabling the student network to learn more effectively.
To implement knowledge distillation, we train a smaller network, known as the distilled model, on a dataset using the outputs of the larger, more complex model as targets. The distilled model learns to mimic the behaviour of the larger model by replicating its outputs at every level.
Let's consider an example to better understand knowledge distillation. Suppose we have a large, state-of-the-art image classification model, like ResNet-50, which has been trained on a massive dataset. We can use this model as the teacher network. Now, we want to deploy a smaller model on resource-constrained devices, such as smartphones, without sacrificing too much accuracy. We can train a smaller network, like MobileNet, as the student network using knowledge distillation. The student network learns from the soft probabilities generated by the teacher network, improving its performance and reducing its memory and computation requirements.
Knowledge distillation finds applications in various domains, such as model compression, transfer learning, and domain adaptation. It is a versatile technique that complements other methods for compressing neural networks, allowing us to strike a balance between model performance and resource constraints.
To aid in understanding, here's an image that illustrates the knowledge distillation process:
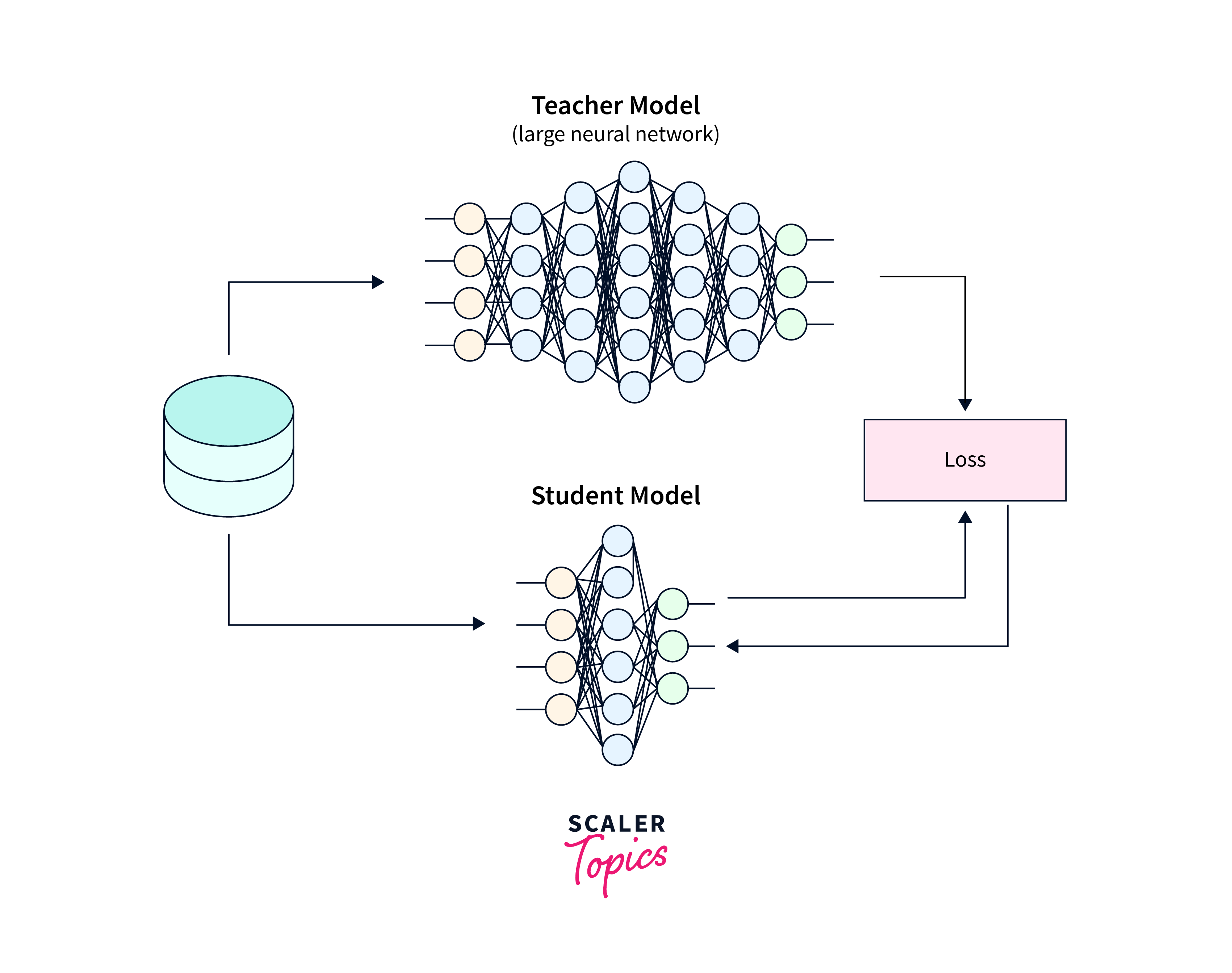
In this image, the teacher network (large model) provides soft probabilities to the student network (small model) during the training process, enabling the student network to learn effectively and replicate the behaviour of the teacher network. It is all other ways of compressing neural networks.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
DistilBERT Architecture
DistilBERT is a faster and lighter model. It retains the key components and architecture of BERT but with some modifications to reduce its size and computational requirements.
Here is an overview of the DistilBERT architecture:
- Transformer Encoder: Similar to BERT, DistilBERT is built using a transformer architecture. It comprises a stack of layers made up of transformer encoders. A feed-forward neural network and a multi-head self-attention mechanism are present in each layer. The model can recognize contextual associations between words in the input sequence thanks to the self-attention mechanism.
- Distillation: DistilBERT incorporates knowledge distillation during its training process. It learns from a larger, more complex model (often BERT) by mimicking its behaviour. This distillation process helps transfer the knowledge learned by the larger model to the smaller DistilBERT model.
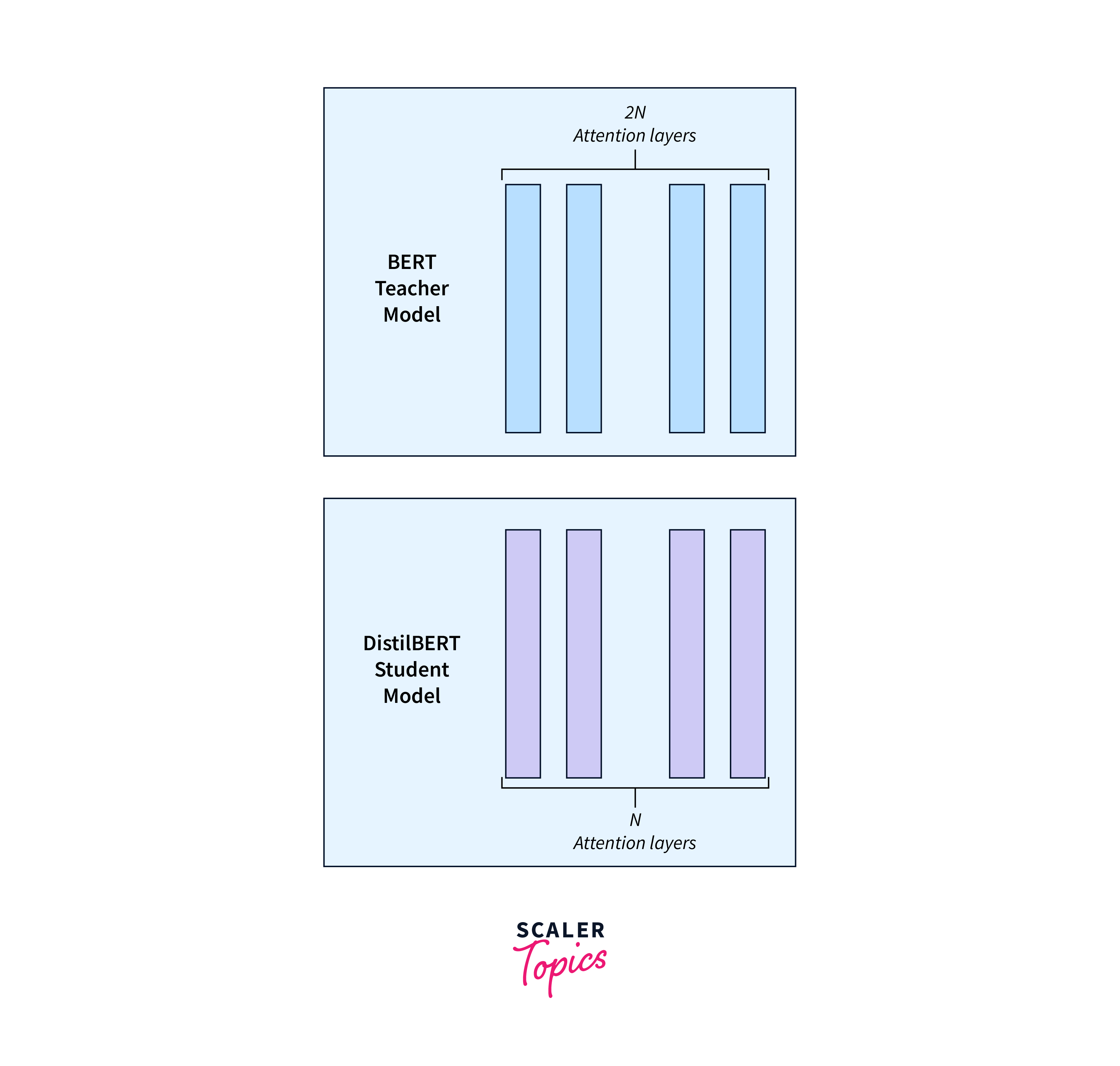
- Parameter Reduction: DistilBERT achieves parameter reduction by reducing the number of layers and the size of the hidden layers compared to BERT. DistilBERT has 6 layers, while BERT-base has 12 layers. This reduction in layers helps make DistilBERT more computationally efficient while still maintaining a high level of accuracy2
- Attention Mechanism: DistilBERT uses a distilled version of the attention mechanism found in BERT. The model may concentrate on the most crucial information in the input data thanks to the attention mechanism. This attention mechanism boosts DistilBERT2's effectiveness.
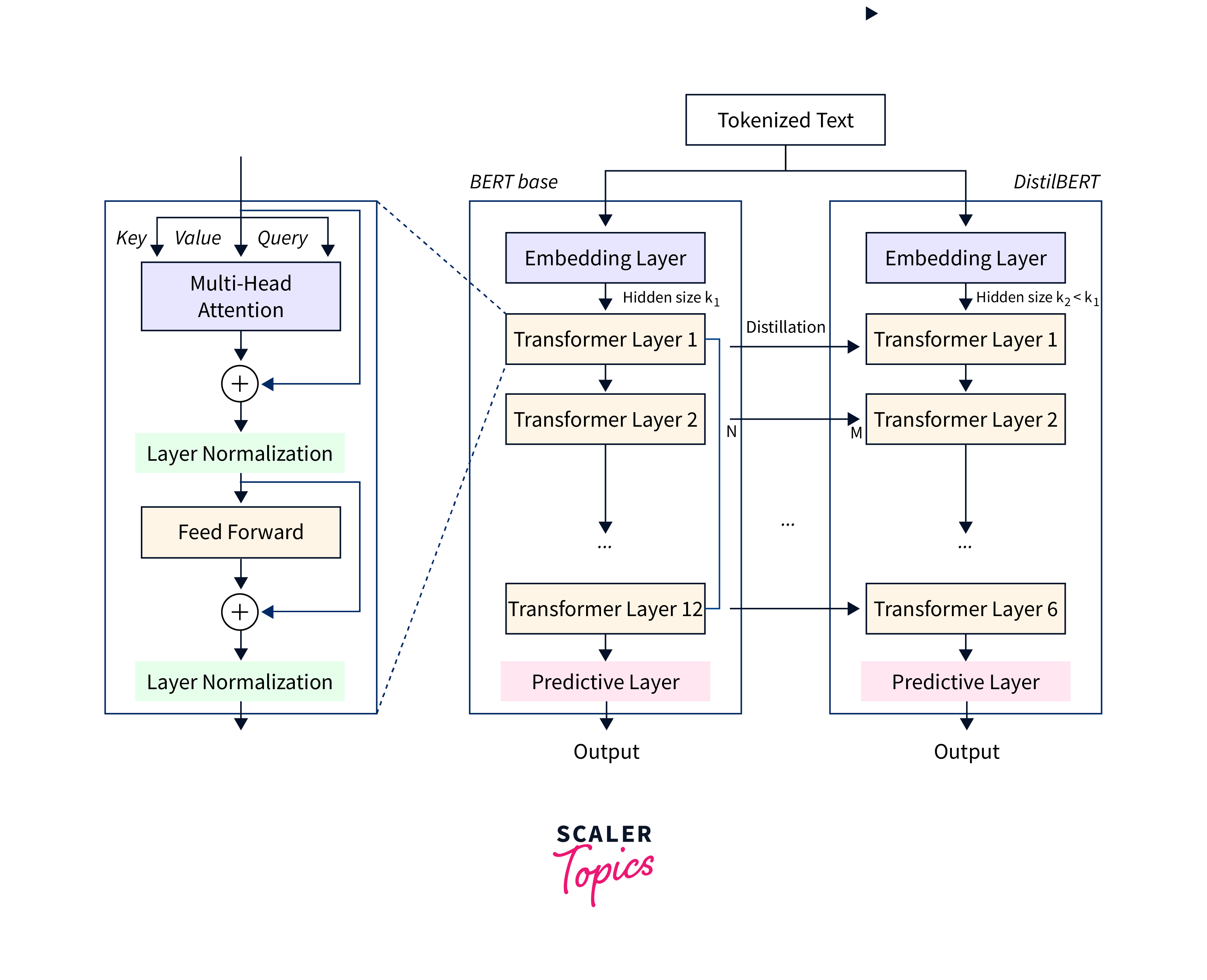
Implementation of DistillBERT with HuggingFace
To implement DistilBERT in Python, you can use the Hugging Face Transformers library. Here are the steps to implement DistilBERT
Step 1: Install the Transformers library
You can install the Transformers library using pip. Open your terminal and run the following command.
Turn Learning into Career Growth
Step 2: Load the Pre-trained DistilBERT Model
You can load the pre-trained DistilBERT model using the DistilBertForSequenceClassification class.
Step 3: Tokenize the Input Text
You can tokenize the input text using the tokenizer.encode_plus() method.
Step 4: Make Predictions on the Input Text
Make predictions on the input text: You can make predictions on the input text using the model() method. Finally, we get the predicted label by taking the argmax of the model's output logits.
In the example code provided, the input text is not related to any specific task, so the predicted label will not be meaningful. However, the code demonstrates the basic steps for using DistilBERT with Hugging Face, including loading the pre-trained model and tokenizer, tokenizing the input text, and making predictions on the input text using the model.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
How to Use DistilBERT in Projects?
To use DistilBERT in projects, you need to fine-tune the pre-trained model on a specific task, use the Hugging Face Transformers library, choose the appropriate architecture, evaluate the model, and deploy the model in production.
Here are the steps to use DistilBERT in projects:
- Fine-tune the pre-trained model: With the use of a labeled dataset, DistilBERT is a pre-trained model that can be adjusted for use on particular tasks. Training the model on the labeled dataset enables it to be fine-tuned to the particular task. For instance, the model can be adjusted using a dataset of labeled reviews to predict the sentiment from new reviews if the task is sentiment analysis.
- Use the Hugging Face Transformers library: The Hugging Face Transformers library provides a simple and intuitive API for working with transformer models, including DistilBERT. The library can be used to fine-tune the pre-trained model on a specific task and to generate predictions on new data.
- Choose the appropriate architecture: DistilBERT has a smaller architecture than BERT, with 40% fewer parameters than bert-base-uncased. This makes it faster and more efficient than BERT while still maintaining a high level of performance. Depending on the specific task and available computational resources, you can choose the appropriate architecture for your project.
- Evaluate the model: Once the model has been fine-tuned on the labelled dataset, it can be evaluated on a separate test dataset to measure its performance. The performance can be measured using metrics such as accuracy, precision, recall, and F1 score.
- Deploy the model: Once the model has been fine-tuned and evaluated, it can be deployed in production to generate predictions on new data. The model can be deployed on various platforms, including mobile devices, web servers, and cloud platforms.
Comparing BERT and DistilBERT
BERT and DistilBERT are both transformer-based language models developed by Google and Hugging Face, respectively. While they share some similarities, there are also some key differences between the two models.
Similarities
- Transformer Architecture: Both BERT and DistilBERT are based on the transformer architecture, which is a type of neural network that is particularly well-suited for natural language processing tasks.
- Pre-trained Models: Both BERT and DistilBERT are pre-trained models that can be fine-tuned on specific tasks with very few samples.
- High Performance: Both BERT and DistilBERT achieve high levels of performance on a wide range of natural language processing tasks. Differences
- Size: DistilBERT is a smaller and lighter version of BERT, with 40% fewer parameters than bert-base-uncased. This makes it more computationally efficient and faster than BERT.
- Training Time: Due to its smaller size, DistilBERT can be trained faster compared to BERT. This is beneficial when working with large datasets or when training models on a tight schedule.
- Attention Mechanism: DistilBERT uses a distilled version of the attention mechanism found in BERT. The distilled attention mechanism helps improve the efficiency of DistilBERT.
- Performance: While DistilBERT aims to achieve similar performance to BERT, it may not perform as well as BERT on some tasks. Despite this, DistilBERT still performs well on a variety of natural language processing tasks.
 Here is a table comparing the key differences between BERT and DistilBERT:
Here is a table comparing the key differences between BERT and DistilBERT:
| Model | Size | Training Time | Attention Mechanism | Performance |
|---|---|---|---|---|
| BERT | Large | Long | Full | High |
| DistilBERT | Small | Short | Distilled | Slightly lower than BERT |
Conclusion
- DistilBERT is a smaller and lighter model compared to BERT, with 40% fewer parameters. This reduction in size makes DistilBERT more computationally efficient and faster to train and deploy.
- While DistilBERT aims to achieve similar performance to BERT, there might be a slight drop in performance compared to BERT on some tasks.
- Due to its smaller size, DistilBERT can be trained faster compared to BERT. This is beneficial when working with large datasets or when time is a constraint.
- BERT is a powerful model that excels in tasks where maximum performance is required, even at the cost of computational resources. On the other hand, DistilBERT is a great option when computational efficiency and faster inference times are crucial without sacrificing too much performance.