The Earley Algorithm
Overview
Earley parsers are among the most general parsers out there, and they can parse any context-free language without restriction. Earley parsing algorithm is an efficient top-down parsing algorithm that avoids some of the inefficiency associated with purely naive search with the same top-down strategy, and they are reasonably fast on most practical grammars and are easy to implement. Earley parsing uses a dynamic programming mechanism to avoid recomputation to solve exponential time complexity problems. We will cover the top-down parsing in brief and then understand the working of the Earley algorithm in detail in this article
Introduction
We have seen majorly two categories of parsing algorithms - top-down parsing and bottom-up parsing. Both of the parsing methods suffer from common limitations like left recursion, left factoring, etc., and their implementation takes exponential time to execute. Earley parser deals with these problems using a dynamic programming mechanism where we use a memoization technique
Top-down Parsing
In Top-down parsing, we build the parse tree by starting from the root and going to the leaf opposed to bottom-up parsing, where we build the leaves first and then move upwards toward the root(top). In top-down parsing, we generate the parse tree from the root as the starting symbol of the grammar and use the leftmost derivation to build its branches. A string in top-down parsing is parsed using the following steps:-
- To derive the input string, first, a production in grammar with a start symbol is applied.
- At each step, the top-down parser identifies which rule of a non-terminal must be applied to derive the input string.
- As the next step, the terminals in the production are matched with the terminals of the input string.
Example: Consider a grammar , , and the input string that we want to parse is abd.
The top-down parser will start creating a parse tree with the starting symbol S.
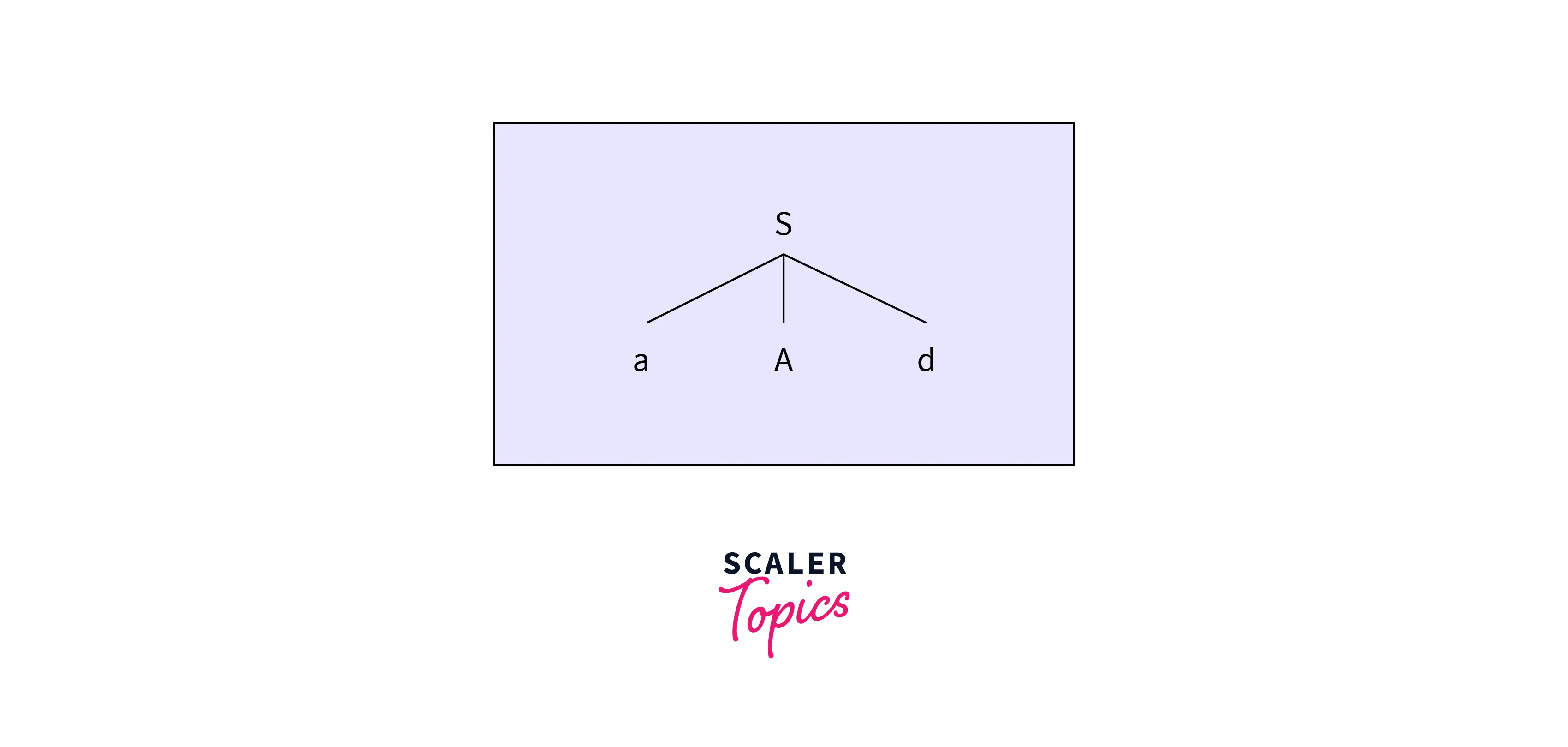 Now the first input symbol 'a' matches the first leaf node of the tree. So the parser will move ahead and find a match for the second input symbol 'b.' But the next leaf node of the parse tree is a non-terminal which has two production rules, so the parser identifies a production rule
Now the first input symbol 'a' matches the first leaf node of the tree. So the parser will move ahead and find a match for the second input symbol 'b.' But the next leaf node of the parse tree is a non-terminal which has two production rules, so the parser identifies a production rule
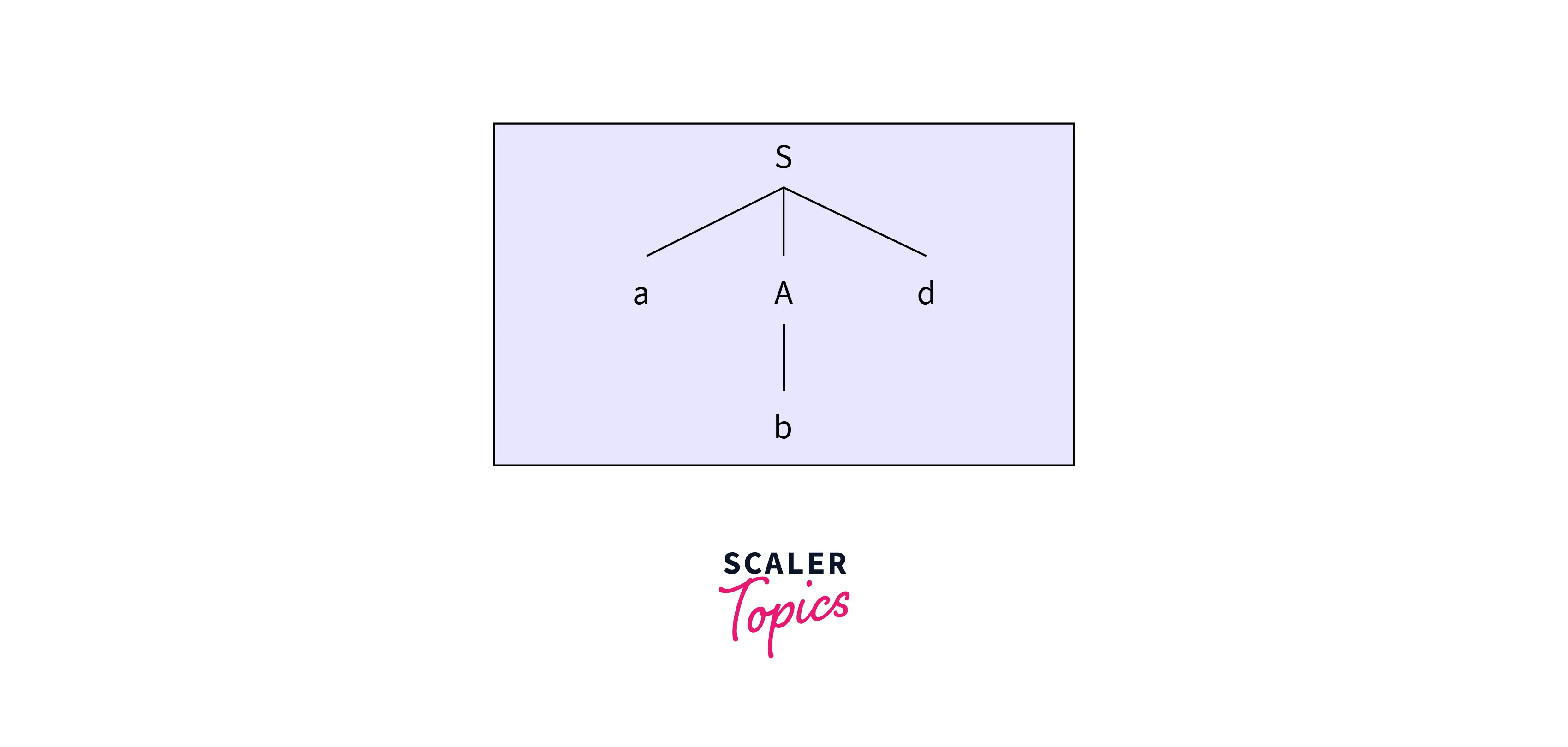 Now the next leaf node matches with the last character of the input string. Hence the parsing is completed.
Now the next leaf node matches with the last character of the input string. Hence the parsing is completed.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Pros and Cons of top-down Parsing
Advantages of top-down Parsing
- The top-down parsing is very simple
- It is very easy to identify the action decision (the grammar rule to pick up next) in a top-down parser
Disadvantages of top-down Parsing
- Top-down parsing is unable to handle left recursion in the present grammar.
- Some recursive descent parsing may require backtracking
- In top-down parsing, there can be multiple
- In top-down parsing, there can be many possible acceptable partial parses of the first (left-most) components of the string that are repeatedly regenerated
The Early Algorithm
This revisiting of early partial solutions within the full parse structure is the result of later backtracking requirements of the search and can become exponentially expensive in large parses. Dynamic programming provides an efficient alternative where partial parses, once generated, are saved for reuse in the overall final parse of a string of words.
Turn Learning into Career Growth
Memoization And Dotted Pairs
In parsing with Earley's algorithm, the memoization of partial solutions (partial parses) is done with a data structure called a chart. This is why the various alternative forms of the Earley approach to parsing are sometimes called chart parsing. The chart is generated through the use of dotted grammar rules.
Dotted Rules
A dotted rule is a data structure used in top-down parsing to record partial solutions toward discovering a constituent.
- S → •VP, [0, 0] Predict an S will be found, which consists of a VP; the S will begin at 0.
- NP → Det • Nominal, [1, 2] Predict an NP starting at 1; a Det has been found; Nominal is expected next.
- VP → V NP•, [0, 3] A VP has been found starting at 0 and spanning to 3; the constituents of VP are V and NP.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Algorithm
Pseudocode
Fundamental Operations
There are three fundamental operations of the Earley algorithm:-
- Predict sub-structure (based on grammar)
- Scan partial solutions for a match
- Complete a sub-structure (i.e., build constituents)
Setting up the Chart
The rationale is to fill in a chart with the solutions to the subproblems encountered in the top-down parsing process.
- Based on an input string of length n, build a 1D array (called a chart) of length n + 1 to record the solutions to subproblems
- Chart entries are lists of states or info about partial solutions.
- States represent attempts to discover constituents.
States
A state consists of:
- a subtree corresponding to a grammar rule S → NP VP
- info about progress made towards completing this subtree S → NP • VP
- The position of the subtree wrt input S → NP • VP, [0,3]
- Pointers to all contributing states in the case of a parser (cf. recognizer)
Illustration through Example
Let's say we want to parse a string "astronomers saw stars with ears" and the grammar rules are :
We add a dummy rule to find the starting node in the production grammar γ → • S Let's execute the Earley algorithm to parse the input string in the following steps:-
- Enqueue dummy start state
- Processing S0 - Since the state is incomplete and NextCat (of S) is not POS, PREDICTOR (Enque all the processing Rules starting from S)
- Processing S1 - Since the state is incomplete and NextCat (of NP) is not POS, PREDICTOR (Enque all the processing Rules starting from NP)
- Processing S2 - Since NP at position [0,0] has already been considered so, continue to S3
- Processing S3 - Since the state is incomplete and NextCat is a POS, so call SCANNER (Add N → astronomers• [0,1] at Chart[0+1])
- Processing S4 - Since nextCat is Empty so, call COMPLETER
- Processing S5 - Since nextCat is Empty so call COMPLETER a. Which states from Chart[0] require the current constit. to be complete?
- Processing S6 - Since the state is incomplete and NextCat (of VP) is not POS, so PREDICTOR (Enque all the processing Rules starting from VP)
- Processing S7 - Since the state is incomplete and NextCat (of PP) is not POS, so PREDICTOR (Enque all the processing Rules starting from PP)
- Processing S8 - Call Scanner: Add V → saw• [1,2] at Chart[2]
-
Processing S9 - Call Predictor, but VP already expanded in Chart[1]
-
Processing S10 - Call Scanner, but no P in input at words[1]
-
Processing S11 - Call Completer
- Processing S12 - Call Predictor
- Processing S13 - Call Predictor, but NP already expanded
- Processing S14 - Call Scanner (Add N → stars• to chart [3])
- Processing S15 - Calling Completer
- Processing S16 - Calling Completer
- Processing S17 - Calling Completer
- Processing S18 - Call Predictor
- Processing S19 - Call Scanner (Add P → with• to chart[4])
- Processing S22 - Call completer
- Processing S23 -
- Processing S24 - Already computed for NP
- Processing S25 - Call Scanner (Enque N → ears• in chart[5])
- Processing S26 - Calling Completer
- Processing S27 - Calling Completer
- Processing further states, in the same way, the chart[5]
Code
Let's look at the python implementation of the Earley algorithm in NLTK, and how to use it.
The output of the code contains the parse chart, try it out! To see the complete implementation of the Earley algorithm in nltk, refer to this documentation.
Applications of the Earley Algorithm
- Earley parsing is used for text processing. Companies like Grammarly verify the correctness of the sentence
- Earley parsing can be used for generating texts in any language
- Earley parsing is used by the compiler to parse the code and verify its syntax
Conclusion
- Earley parsing can parse any context-free text based on the input grammar.
- Its execution takes time for the worst cases and linear for the best cases.
- Earley Parser uses dynamic programming techniques to avoid repeated work/recursion problems.