Elements of Semantic Analysis in NLP
Overview
Semantic analysis is a branch of general linguistics which is the process of understanding the meaning of the text. The process enables computers to identify and make sense of documents, paragraphs, sentences, and words as a whole.
Semantic analysis is done by analyzing the grammatical structure of a piece of text and understanding how one word in a sentence is related to another.
Introduction
- Semantic analysis deals with analyzing the meanings of words, fixed expressions, whole sentences, and utterances in context. In practice, this means translating original expressions into some kind of semantic metalanguage.
- NLP applications of semantic analysis for long-form extended texts include information retrieval, information extraction, text summarization, data-mining, and machine translation and translation aids.
- Semantic analysis is also pertinent for much shorter texts and handles right down to the single-word level. These cases arise in examples like understanding user queries and matching user requirements to available data.
- The elements of semantic analysis are also of high relevance in efforts to improve web ontologies and knowledge representation systems.
What is Semantic Analysis
Semantic analysis is the process of drawing meaning from text and it allows computers to understand and interpret sentences, paragraphs, or whole documents by analyzing their grammatical structure, and identifying relationships between individual words in a particular context.
- Semantic analysis captures the real meaning of a given paragraph by first reading it and then identifying the text elements and their grammatical role.
- It can identify whether a text is based on a certain category like sports, or a category, like politics, based on the words in the text.
- Even if the related words are not present, the analysis can still identify what the text is about.
Lexical semantics plays an important role in semantic analysis, allowing machines to understand relationships between lexical items like words, phrasal verbs, etc.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Parts of Semantic Analysis
The semantic analysis focuses on larger chunks of text, whereas lexical analysis is based on smaller tokens.
- As we focus on larger chunks in semantic analysis, we divide the semantic analysis into two parts:
- Studying the meaning of the Individual Word: This is the first component of semantic analysis in which we study the meaning of individual words. This component is known as lexical semantics.
- Studying the combination of Individual Words: In this component, we combined the individual words to provide meaning in sentences.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Tasks Involved in Semantic Analysis
- The most important task of semantic analysis is to find the proper meaning of the sentence using the elements of semantic analysis in NLP.
- There are various other sub-tasks involved in a semantic-based approach for machine learning, including word sense disambiguation and relationship extraction.
1. Word Sense Disambiguation Word Sense Disambiguation (WSD) involves interpreting the meaning of a word based on the context of its occurrence in a text.
- Natural language is ambiguous and polysemic, and sometimes the same word can have different meanings depending on how it is used in the text.
- Word sense disambiguation is an automated process of identifying in which sense is a word used according to its context under elements of semantic analysis.
Need for Word Sense Disambiguation
- From a machine point of view, human text and human utterances from language and speech are open to multiple interpretations because words may have more than one meaning which is also called lexical ambiguity.
- It may also be because certain words such as quantifiers, modals, or negative operators may apply to different stretches of text called scopal ambiguity.
- It may also occur because the intended reference of pronouns or other referring expressions may be unclear, which is called referential ambiguity.
Ambiguity resolution is one of the frequently identified requirements for semantic analysis in NLP as the meaning of a word in natural language may vary as per its usage in sentences and the context of the text.
Classification of Methods for Word Sense Disambiguation
WSD approaches are categorized mainly into three types, Knowledge-based, Supervised, and Unsupervised methods.
- Knowledge-based WSD: Knowledge-based approaches are based on different knowledge sources such as machine-readable dictionaries or sense inventories, thesauri, etc.
- Wordnet is the mostly used machine-readable dictionary in this research field.
- Generally, four main types of knowledge-based methods are used under this category: LESK algorithm, Semantic similarity methods, selectional preferences, and Heuristic-based methods for WSD under elements of semantic analysis.
- These algorithms generally give higher precision. These algorithms are overlap based, so they suffer from overlap sparsity and performance depends on dictionary definitions.
- WSD using Supervised Approaches: The supervised approaches applied to WSD systems use machine learning techniques from manually created sense annotated data.
- Training set will be used for the classifier to learn and the training set which consists of examples related to the target word. The tags are manually created from the dictionary.
- Supervised-based WSD algorithm generally gives better results than other approaches.
- Decision rules, decision trees, Naive Bayes, Neural networks, instance-based learning methods, support vector machines, and ensemble-based methods are some algorithms used in this category.
- This type of algorithm is better than the two approaches with respect to the implementation perspective. One other caveat with these algorithms is that they do not give satisfactory results for resource-scarce languages.**
- WSD Using Unsupervised Approaches: These methods do not depend on external knowledge sources or sense inventories, machine-readable dictionaries, or sense-annotated datasets.
- These algorithms generally do not assign meaning to the words. Instead they discriminate the word meanings based on information found in unannotated corpora.
- Unsupervised WSD has two types of distributional approaches. The first one is monolingual corpora, and the other one is translation equivalence based on parallel corpora.
- The techniques are further categorized into two types, type-based and token-based approaches. The type-based approach disambiguates by clustering instances of a target word, and the token-based approach disambiguates by clustering the context of a target word using elements of semantic analysis.**
- Context clustering, Word clustering, Co-occurrence graph, and Spanning tree-based approaches are the main approaches under unsupervised WSD.
- There is no need for any sense inventory and sense annotated corpora in these approaches. These algorithms are difficult to implement and performance is generally inferior to that of the other two approaches.
2. Relationship Extraction
Relationship extraction is the task of detecting the semantic relationships present in a text. Relationships usually involve two or more entities which can be names of people, places, company names, etc. These entities are connected through a semantic category such as works at, lives in, is the CEO of, headquartered at etc.
- Rule-based RE, Weakly Supervised RE, Supervised RE, Distantly Supervised RE, and Unsupervised RE are some methods generally used for relationship extraction (RE)
- Relation Extraction is a key component for building relation knowledge graphs and also of crucial significance to natural language processing applications such as structured search, sentiment analysis, question answering, and summarization.
- Relation Classification, Joint Entity, Relation Extraction, Temporal and Dialog Relation Extraction, Binary and Continual Relation Extraction, Hyper-Relational Extraction, Multi-Labeled Relation Extraction, and Relation Mention Extraction are some sub-tasks involved in relation extraction under elements of semantic analysis.
- Relationship extraction algorithms can be designed using either open form or targeted form.
- Open relationship extraction: The algorithm finds and returns the relationship's text snippets along with its arguments. Most of the relationship extraction tools in today's marketplace utilize open relationship algorithms to perform the task.
- These methods produce semi-structured results and need some human interpretation.
- There is also no constraint as it is not limited to a specific set of relationship types.
- Targeted relationship extraction: In this type, we pre-train the algorithms for identifying specific relationship types.
- Targeted relationship extraction algorithms produce structured information, and downstream applications like the knowledge graph easily digest it.
- These algorithms typically extract relations by using machine learning models for identifying particular actions that connect entities and other related information in a sentence.
- Open relationship extraction: The algorithm finds and returns the relationship's text snippets along with its arguments. Most of the relationship extraction tools in today's marketplace utilize open relationship algorithms to perform the task.
Relationship extraction involves first identifying various entities present in the sentence and then extracting the relationships between those entities.
Elements of Semantic Analysis
Studying a language cannot be separated from studying the meaning of that language because when one is learning a language, we are also learning the meaning of the language.
Let us learn about the difficulties associated with learning the meaning and classification of different kinds of relations that need to learn under elements of semantic analysis.
Difficulties with Understanding the Meaning of Language
- The meaning of a language can be seen from its relation between words, in the sense of how one word is related to the sense of another. These relations can be studied under the domain of sense relations.
- Sense relations can be seen as revelatory of the semantic structure of the lexicon.
- Sense relations are the relations of meaning between words as expressed in hyponymy, homonymy, synonymy, antonymy, polysemy, and meronymy which we will learn about further.
Classification of Sense Relations
- Sense relations can be classified into two classes - Those that express identity and inclusion between word meanings and those that express opposition and exclusion.
- The first class discusses the sense relations between words whose meanings are similar or included in other ones.
- The second class discusses the sense relations between words whose meanings are opposite or excluded from other words.
- Sense relations can also be classified into two groups of horizontal and vertical sense relations under elements of semantic analysis.
- Horizontal relations include synonymy, which is the sameness of meaning of different linguistic forms, and also various other relations that can be subsumed under the general notion of opposition.
- Synonymy is the sameness of the meaning of different linguistic forms, for example, orange and apfelsine in German with the same meaning of orange.
- The two principal vertical relations are hyponymy and meronymy.
- Other than these two principal vertical relations, there is another vertical sense relation for the verbal lexicon used in some dictionaries called troponymy.
- Troponymy refers to the case where one verb specifies a certain manner of carrying out the activities referred to by the other verb, such as in amble -- walk or shelve -- put.
- Horizontal relations include synonymy, which is the sameness of meaning of different linguistic forms, and also various other relations that can be subsumed under the general notion of opposition.
- Horizontal sense relations of Opposition: The oppositions forms include incompatibility, antonymy, complementarity, conversity, and reversity.
- Incompatibility is mutually exclusive in a particular context, for example, fin--foot.
- Antonymy is gradable, directionally opposed words, for example, big--small.
- Complementarity is the exhaustive division of conceptual domain into mutually exclusive compartments like aunt--uncle, possible--impossible
- Conversity are static directional opposites with the specification of one lexical element in relation to another along some axis, for example above--below
- Reversity are dynamic directional opposites with motion or change in opposite ways like ascend--descend.
Hyponymy
Hyponymy is the case when a relationship between two words, in which the meaning of one of the words includes the meaning of the other word.
- In hyponymy, the meaning of one lexical element hyponym is more specific than the meaning of the other word, which is called hyperonym under elements of semantic analysis.
- Example: Relation between cat and animal, pigeon and bird, orchid and flower.
- Cat is said to be a hyponym of animal, pigeon a hyponym of bird, and orchid a hyponym of the flower.
- Animal is said to be the superordinate which is also called the hyperonym of cat, bird the superordinate of pigeon, and flower the superordinate of orchid.
- This relation is also described as one of inclusion.
Sample example illustration for hyponymy
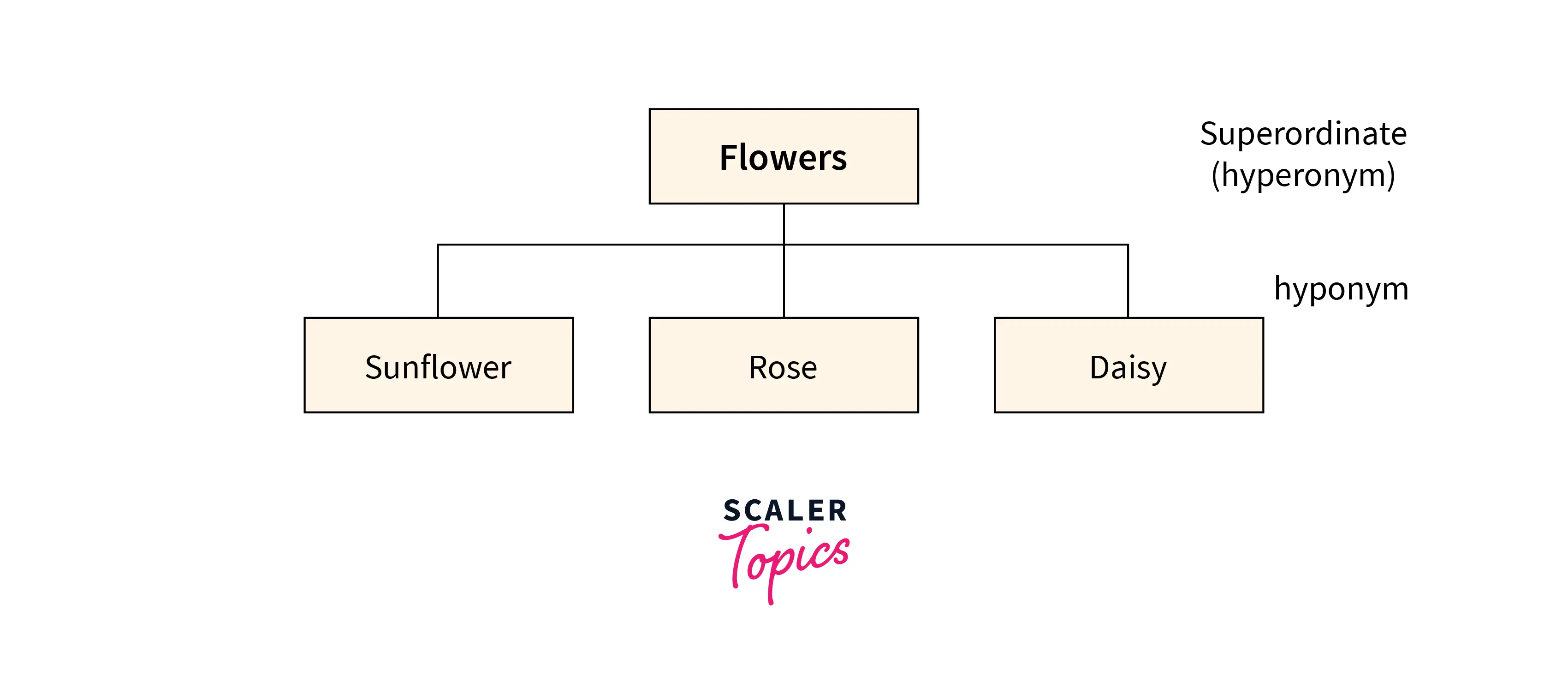
- From the flow chart we can see that the class denoted by the superordinate term includes the class denoted by the hyponym as a sub-class.
- The class of flower includes the class of orchid as one of its subclasses.
- Flower is the general term that includes orchids and other types of flowers such as roses and tulips.
- The relationship between the orchid rose, and tulip is also called co-hyponym.
Turn Learning into Career Growth
Homonymy
Homonymy refers to the case when words are written in the same way and sound alike but have different meanings.
- Example: Our house is on the west bank of the river. vs. I want to save my first salary in the bank.
- Bank in both these sentences are homonyms and are written in the same way and sound alike but their meanings are different.
- In the first example, the bank refers to the side of a river and the land near it while in the second, it is an organization that provides various financial services.
- In relation to lexical ambiguities, homonymy is the case where different words are within the same form, either in sound or writing. For example, light (vs. dark) and light (vs. heavy).
Homonymy refers to two or more lexical terms with the same spellings but completely distinct in meaning under elements of semantic analysis.
Synonymy
Synonymy is the case where a word which has the same sense or nearly the same as another word.
- Example: happy, content, ecstatic, overjoyed which convey the same emotion of happiness.
- It can also be seen as the case when two or more lexical terms that might be spelled distinctly have the same or similar meaning.
A pair of words can be synonymous in one context but may be not synonymous in other contexts under elements of semantic analysis.
- We come across many cases where words are synonymous in various places like The street is very wide/deep.; You have my deep/profound sympathy.
- In both of these sentences, wide and broad and deep and profound are replaceable to each other, and the meaning of the sentence remains the same so we can replace each other.
- We also have cases where there are synonymous in one context but not in the other one.
- The student speaks with a broad British accent vs. The student speaks with a wide British accent.
- The pair of wide and broad in this sentence is not synonymous since wide cannot substitute broad in that context.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Antonymy
Antonyms refer to pairs of lexical terms that have contrasting meanings or words that have close to opposite meanings.
- Example: long: short, fast: slow, easy: difficult, good: bad, hot: cold, etc.
- There are three types of antonyms: Polar antonyms, Equipollent antonyms, and Overlapping Antonyms.
- Polar Antonyms: This type of oppositeness can be easily modified with degree modifiers such as very, rather, quite, slightly, extremely, and the like.
- Example: The essay is very long.; The test is quite easy.; His performance is not extremely bad.
- Polar antonyms can also be applied in the comparative or superlative degree as in easy – easier – easiest; bad – worse – worst.
- One other characteristic of this antonym is that a normal how to question can be applied only to one member of a pair.
- Example: How long is your essay?; But not?; How short is your essay?
- Equipollent Antonyms: This type of antonym refer to subjective sensations as hot: cold, bitter: sweet, painful: pleasurable, or emotions as happy: sad, proud of, ashamed of.
- The characteristic of these antonyms is that normal how-question can be applied to both terms of the pair.
- How hot is the weather? vs. How cold is the weather?
- Overlapping Antonyms: All overlapping antonym pairs have an evaluative polarity as part of their meaning as good: bad, kind: cruel, clever: dull, pretty: plain, polite: rude.
- The how-question can be applied to both terms of the pairs, but one term yields a neutral question and the other one a committed question.
- Example: How good is the performance? vs. How bad is your test score?
Polysemy
Polysemy is defined as word having two or more closely related meanings. It is also sometimes difficult to distinguish homonymy from polysemy because the latter also deals with a pair of words that are written and pronounced in the same way.
- It differs from homonymy because the meanings of the terms need not be closely related in the case of homonymy under elements of semantic analysis.
- Example: The sun is very bright today. vs. She is a very bright student.
- In the first sentence, bright means shining, and in the second, it means intelligent. The related meanings are that the sense of a bright student brings a sense of shine in that a bright student usually shines their intelligence.
- Polysemy poses greater problems than homonym because the meaning differences concerned and the associated syntactic and other formal differences are typically more subtle.
- Mishandling of polysemy is a common failing of semantic analysis, both the positing of false polysemy and failure to recognize real polysemy.
- The problem of false polysemy is very common in conventional dictionaries like Longman, WordNet, etc.
- The problem of failure to recognize polysemy is more common in theoretical semantics, where theorists are often reluctant to face up to the complexities of lexical meanings.
Polysemy refers to a relationship between the meanings of words or phrases, although slightly different, and shares a common core meaning under elements of semantic analysis.
Difference between Polysemy and Homonymy
- Both polysemy and homonymy words have the same syntax or spelling. The main difference between them is that in polysemy, the meanings of the words are related, but in homonymy, the meanings of the words are not related.
- Example: If we talk about the same word bank, we can write the meaning as a financial institution or a river bank. In that case, it would be an example of a homonym because the meanings are unrelated to each other.
Homonymy and polysemy deal with the closeness or relatedness of the senses between words. Homonymy deals with different meanings and polysemy deals with related meanings.
Meronymy
Meronymy is when the meaning of one lexical element specifies that its referent is part of the referent of another lexical element. Example: hand -- body.
- Meronomy is also a logical arrangement of text and words that denotes a constituent part of or member of something under elements of semantic analysis.
Meronomy refers to a relationship wherein one lexical term is a constituent of some larger entity like Wheel is a meronym of Automobile.
Conclusion
- Semantic analysis helps in understanding the context of any text and understanding the emotions that might be depicted in the sentence.
- Words with multiple meanings in different contexts are ambiguous words, and word sense disambiguation is the process of finding the exact sense of them.
- Hyponym relations refer to the super and subordinate relationships between words, earlier called hypernyms and later hyponyms.
- Synonymy refers to word which has the same sense, and antonymy refers to words that have contrasting meanings under elements of semantic analysis.
- Polysemy is the coexistence of many possible meanings for a word or phrase, and homonymy is the existence of two or more words having the same spelling or pronunciation but different meanings and origins.