Putting Encoder - Decoder Together
Overview
Encoder-decoder model is a neural network architecture used for tasks like machine translation, summarization, and image captioning. It compresses input data into a fixed-length vector using the encoder. It generates output using a decoder, which can be implemented using various neural network architectures such as RNN or Transformer. It is trained using input-output pairs, and the goal is to learn a mapping from input to output.
Introduction
An encoder-decoder model in machine learning is a type of neural network architecture that processes an input sequence and converts it into a fixed-length internal representation called the context vector, which is then passed to a decoder that generates an output sequence.
Encoder-decoder models have succeeded in various natural language processing tasks and have led to significant improvements in machine translation quality. They are also widely used in other areas such as word processing, language modeling, speech recognition and even for computer vision.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
The Encoder-Decoder Network
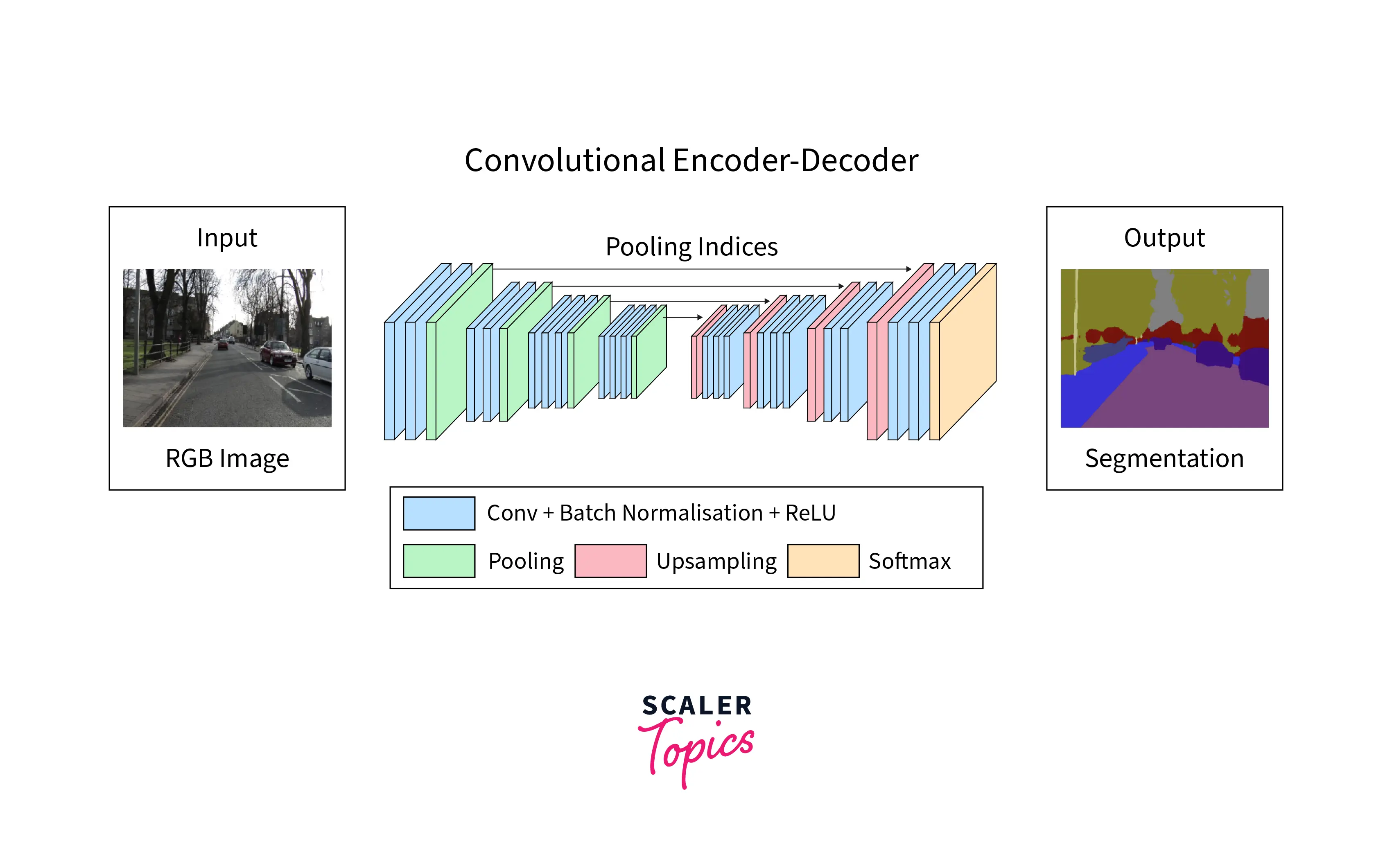
The encoder-decoder network is a neural network architecture commonly used in natural language processing tasks. It consists of two main components: the encoder and the decoder`. The encoder processes the input data and encodes it into a compact representation, which is then passed to the decoder. The decoder uses this representation to generate the desired output, which can be a translation of the input text or a summary of the input document.
One key feature of the encoder-decoder network is that it allows variable-length inputs and outputs. This is particularly useful in natural language processing tasks, where the input and output text length can vary greatly. The encoder-decoder network also can handle sequential data, as the input data is processed in a specific order, and the output is generated in a predetermined sequence.
Several variations of the encoder-decoder network include many-to-one, one-to-many, and many-to-many architectures. In a many-to-one architecture, the encoder processes multiple input sequences and generates a single output. This type of architecture is often used for tasks such as sentiment analysis, where the input is a sentence or group of words, and the output is a single label indicating the overall sentiment of the input text. In a one-to-many architecture, the encoder processes a single input sequence and generates multiple outputs. This type of architecture is often used for tasks such as image captioning, where an image can be the input, and the output is a sequence of words describing the image. Finally, in a many-to-many architecture, the encoder processes multiple input sequences and generates multiple output sequences. This type of architecture is often used for tasks such as machine translation, where the input is a sequence of words in one language, and the output is a translation of the input text in another language.
Encoder-Decoder with RNNs
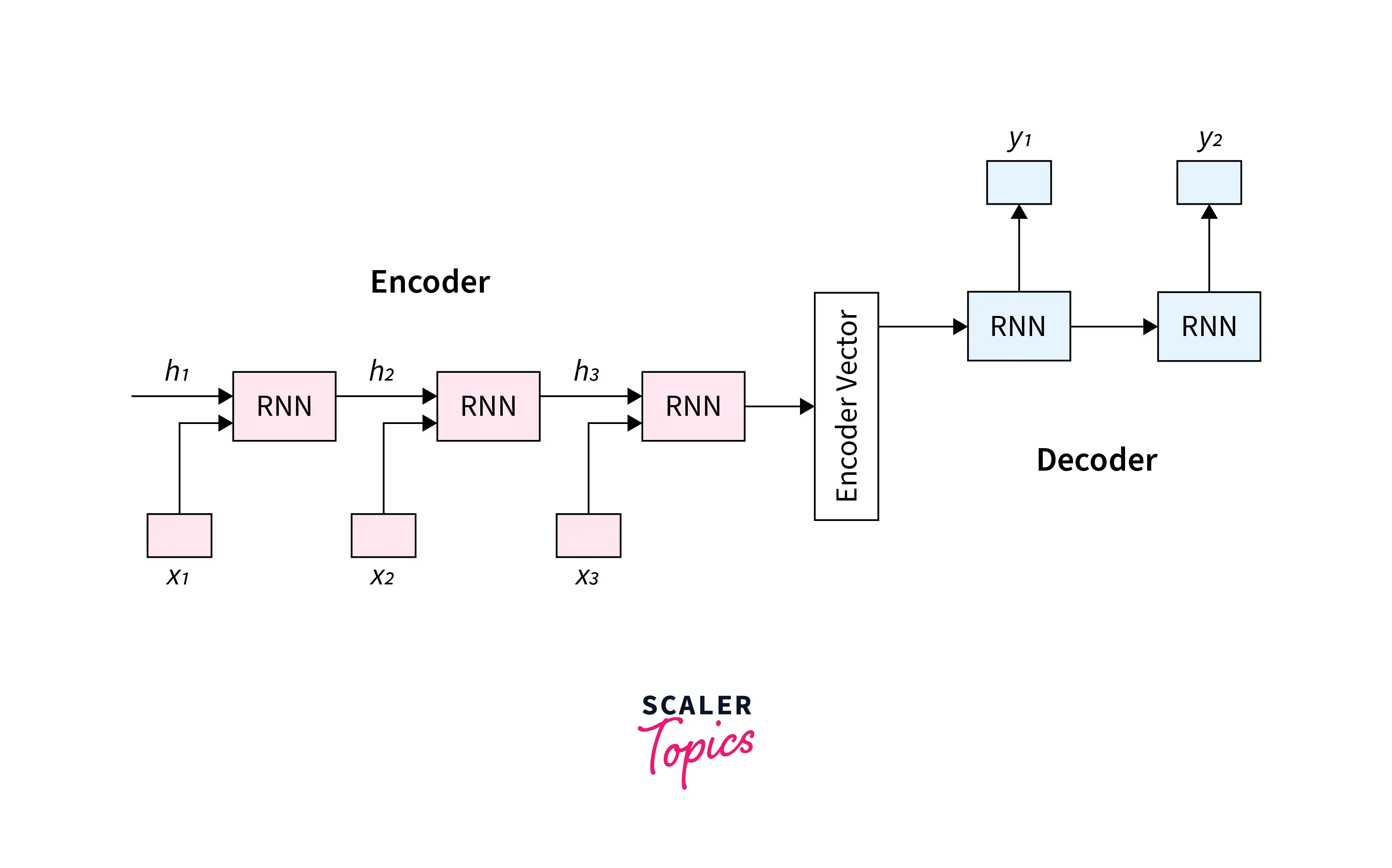
The encoder and decoder can be implemented using a variety of neural network architectures, but Recurrent Neural Networks (RNNs) are often used due to their ability to process sequential data. RNNs have an internal state that allows them to remember information from previous input data, which makes them well-suited for processing sequential data.
RNN-based encoder-decoder networks can capture long-term dependencies in the input and output sequences, which makes them well-suited for tasks such as machine translation, where the meaning of a word may depend on the words that come before or after it in the sentence.
Encoder
The encoder is typically implemented as an RNN that processes the input sequence one element at a time, from left to right. During each time step, the encoder takes in an input element and its previous hidden state and produces a new one. The hidden state captures the information from the input element and the previous hidden state, which is then used to predict the next element in the sequence.
The encoder produces a context vector by concatenating the hidden states at each time step and passing them through a linear transformation. The context vector is a fixed-length representation of the input sequence that captures the essential information from the input sequence.
Overall, the encoder plays a crucial role in the encoder-decoder architecture by converting the input sequence into a fixed-length context vector that the decoder can use to generate the output sequence.
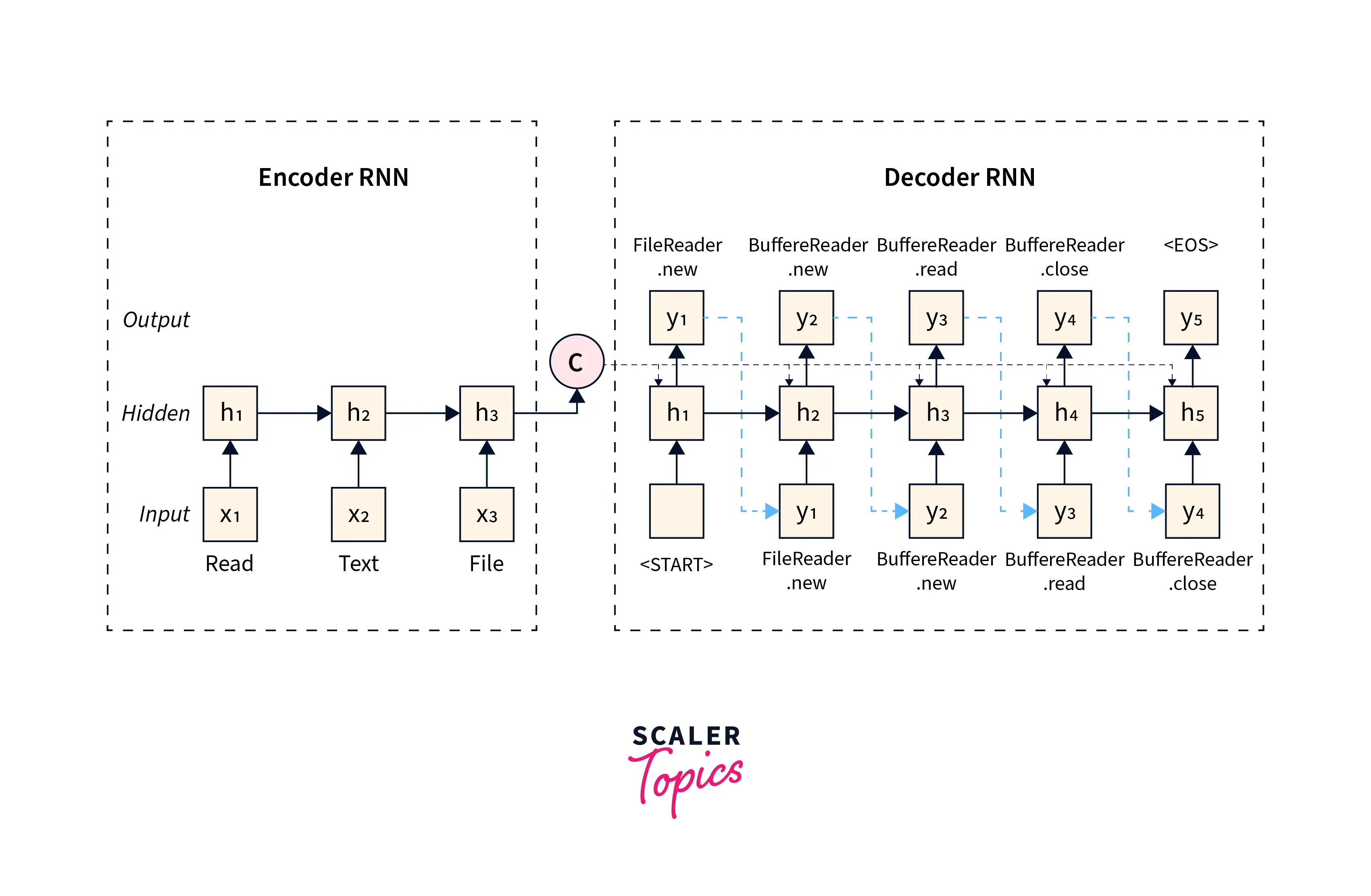
Decoder
The decoder is typically implemented as an RNN that simultaneously generates the output sequence of one element, from left to right. It produces a new hidden state and a prediction for the next output element. At each time step, the decoder takes in the previous hidden state, the context vector, and the previous output element (if available).
The decoder uses the context vector and its internal state to generate each element in the output sequence. The context vector captures the essential information from the input sequence, and the decoder uses this information to generate the output sequence.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Advantages of Encoder-Decoder RNNs
There are several advantages to implementing an encoder-decoder architecture with Recurrent Neural Networks (RNNs):
- Flexibility: Encoder-Decoder RNNs can be used for various tasks, such as machine translation, text summarization, and image captioning.
- Handling variable-length input and the output: Encoder-Decoder RNNs are particularly useful for tasks with different lengths of input and output sequences.
- Handling sequential data: RNNs are particularly well-suited for handling sequential data.
- Handling missing data: Encoder-Decoder RNNs can handle missing data by only passing the available data to the encoder.
Disadvantages of Encoder-Decoder RNNs
There are also some disadvantages to implementing an encoder-decoder architecture with RNNs:
- Long-term dependencies: RNNs can struggle to capture long-term dependencies in the input data, which can be an issue for some tasks.
- Training difficulties: Training an RNN can be challenging, particularly when the input and output sequences are of different lengths.
- Computationally expensive: RNNs can be computationally expensive to train, especially for large datasets.
- Overfitting: RNNs are prone to overfitting, particularly when the dataset is small, which can be an issue for some tasks.
Training the Encoder-Decoder Models
Training an encoder-decoder model involves several steps:
- Preprocessing: The input and output sequences are preprocessed to prepare them for training. This may involve tokenizing the sequences, adding them to the same length, and creating a vocabulary of unique tokens.
- Model definition: The encoder-decoder model includes the number of layers, the type of recurrent cells used, and any other hyperparameters, such as the learning rate.
- Training loop: The training loop is defined, which involves iterating over the training data and updating the model's parameters based on the loss function. This process is repeated until the model reaches a satisfactory level of performance.
- Encoding: The input sequence is passed through the encoder to produce a fixed-length context vector during the forward pass. The context vector captures the essential information from the input sequence and is used by the decoder to generate the output sequence.
- Decoding: The context vector is passed to the decoder, which generates the output sequence one element at a time. The decoder uses the context vector and its internal state to generate each element in the output sequence.
- Loss calculation: The loss function is calculated based on the difference between the predicted and true outputs. A loss function can measure how well the model performs and guide the update of the model's parameters.
- Backward pass: The backward pass involves the calculation of gradients based on the loss function concerning the model's parameters and updating the parameters based on the gradients and the learning rate.
- Evaluation: The trained model is evaluated on a separate dataset to measure its performance. This can involve calculating metrics such as accuracy or perplexity.
This is a simple example, and in practice, you would likely want to use more advanced techniques such as attention mechanisms and beam search for decoding. Additionally, you'll need to preprocess your data, create data loaders, define the input size, hidden size, output size, and the number of epochs, and also see how your model performs with some metrics.
Architectures and Their Applications
There are several different variants of encoder-decoder architectures that have been developed for various natural language processing tasks:
Many-to-one encoder-decoder
This variant is used for tasks where the input sequence can vary in length, but the output sequence has a fixed length.
Examples include tasks such as sentiment analysis, where the input is a variable-length text, and the output is a single label indicating the sentiment of the text.
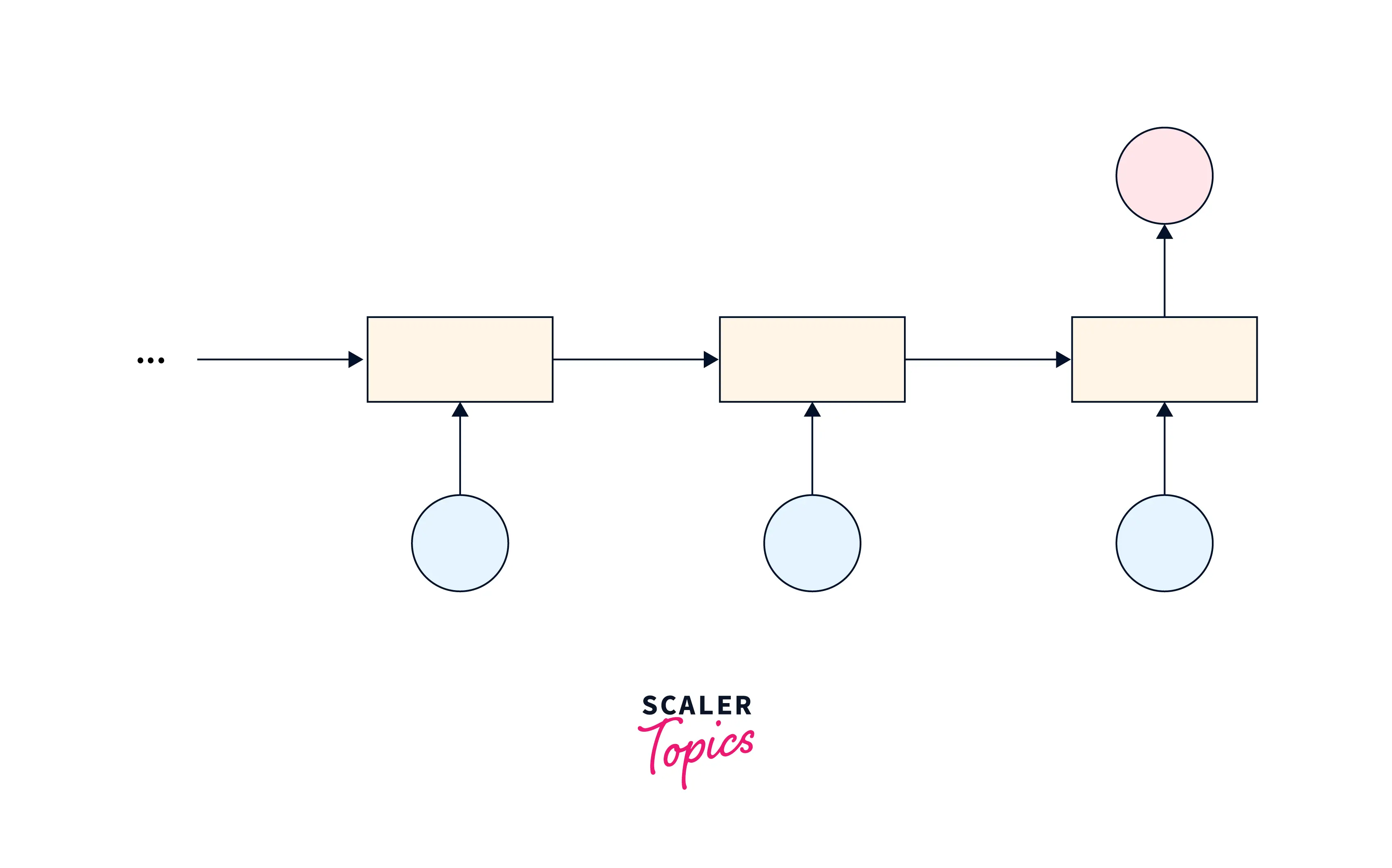
One-to-many encoder-decoder
This variant is used for tasks where the input sequence has a fixed length, but the output sequence can vary.
Examples include tasks such as image captioning, where an image can be the input, and the output is a variable-length text description of the image.
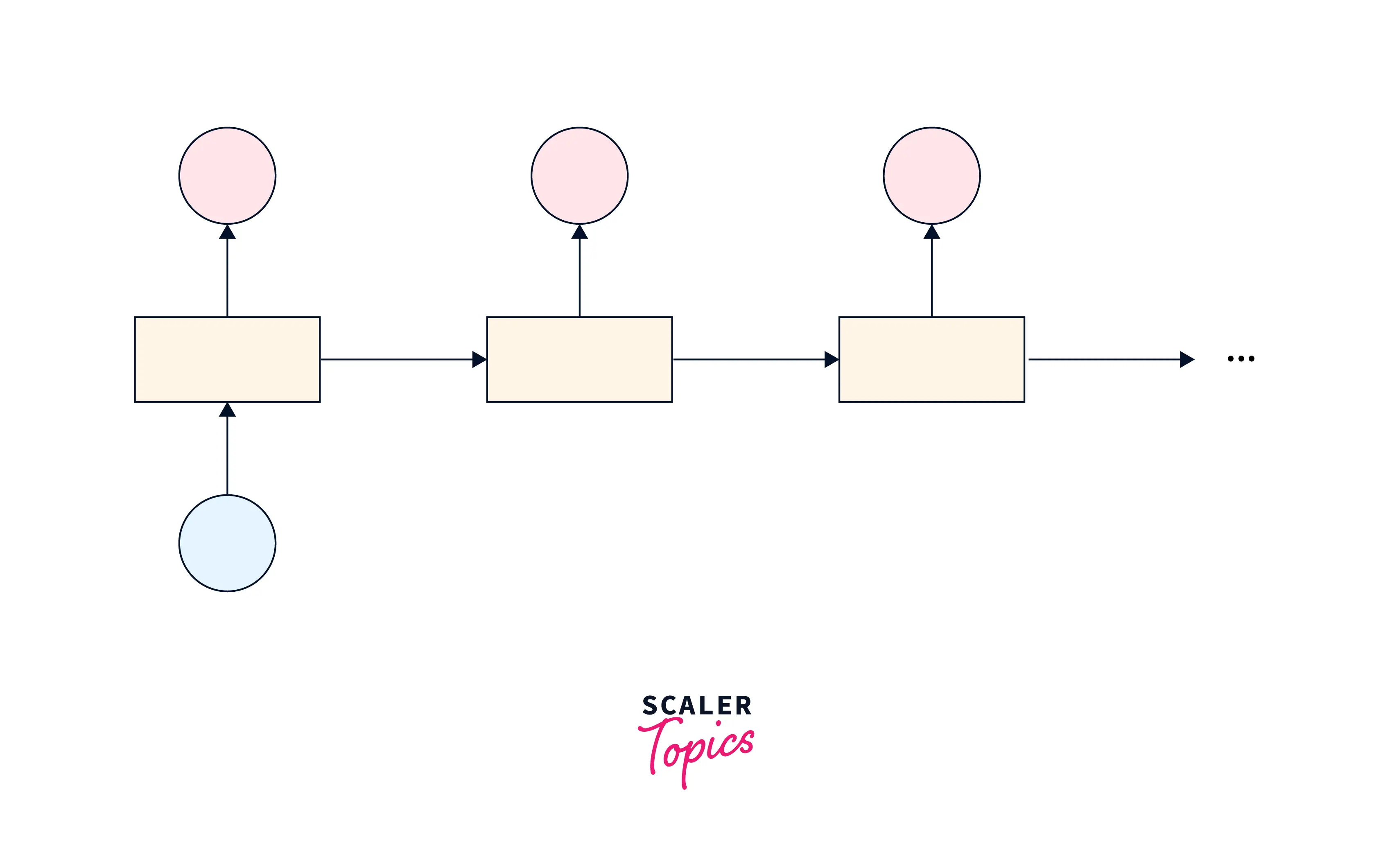
Many-to-many encoder-decoder
There are two main types of many-to-many encoder-decoder architectures:
Turn Learning into Career Growth
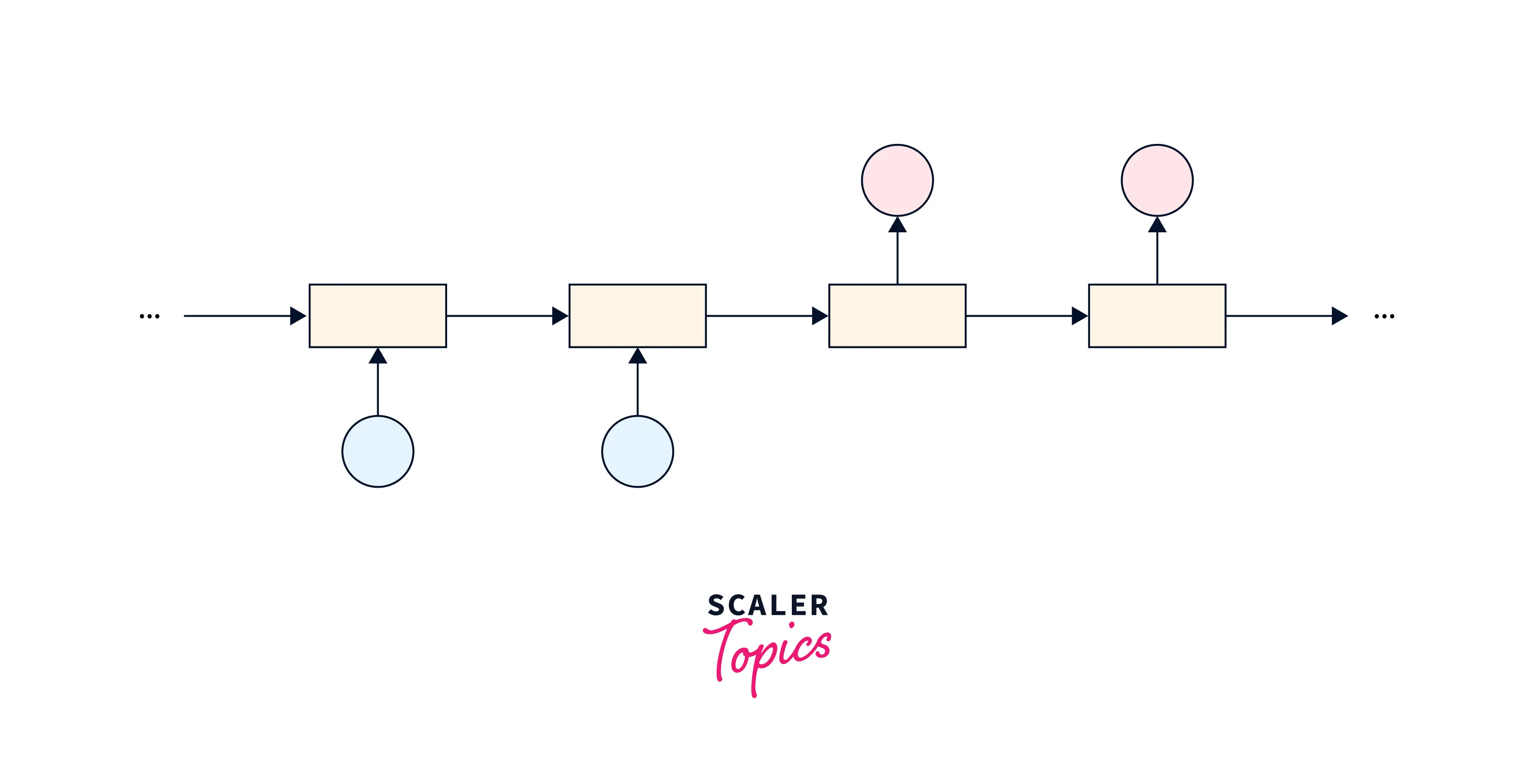
Synchronous many-to-many encoder-decoder
In this architecture, the input and output sequences are processed one element at a time, with the input and output elements corresponding to each other in a one-to-one manner. This architecture is used for tasks such as machine translation, where the input and output sequences have a fixed alignment.
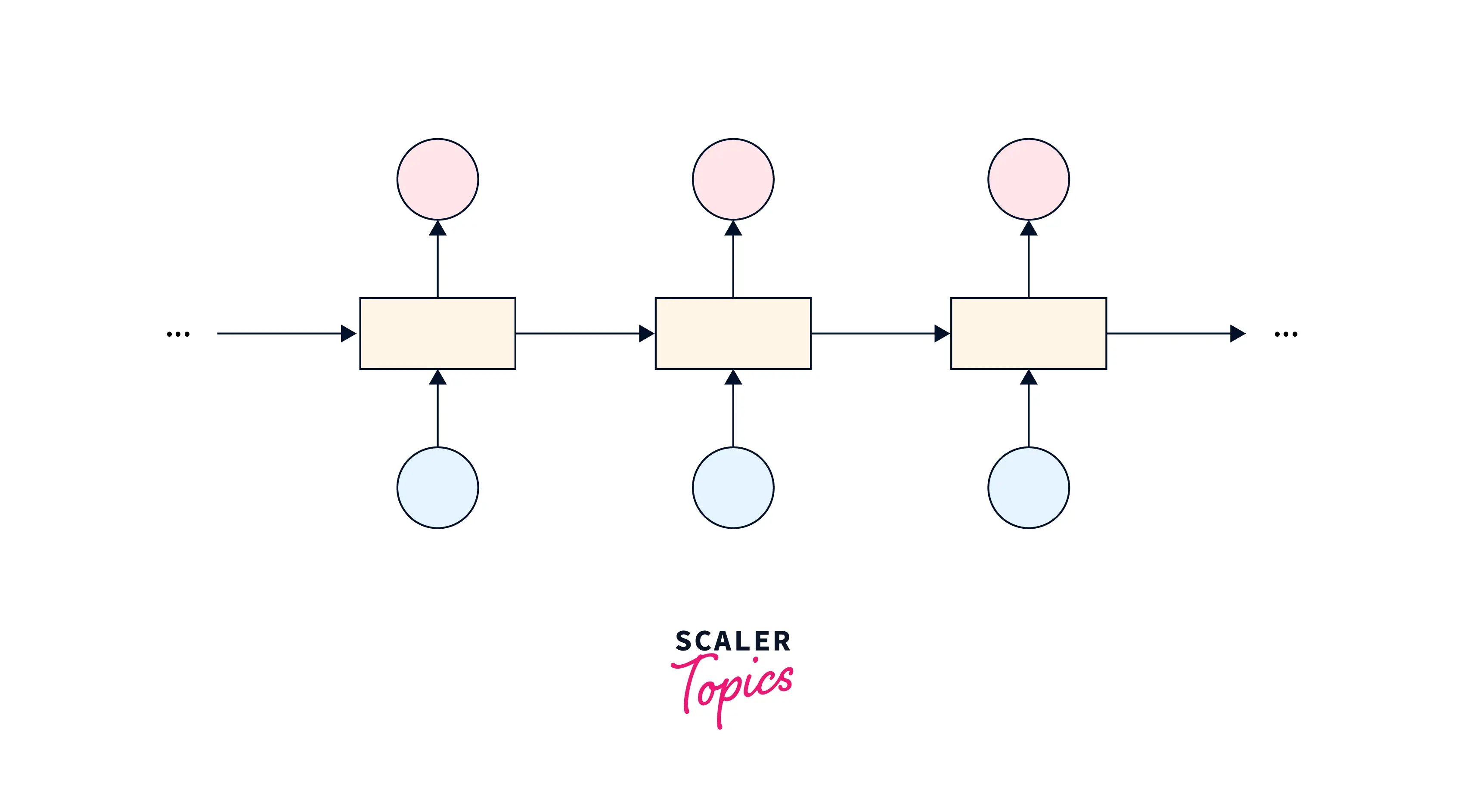
Asynchronous many-to-many encoder-decoder
In this architecture, the input and output sequences are processed independently and may not have a fixed alignment. This architecture is used for tasks such as speech tagging, named entity recognition and image captioning, where the input and output sequences may not have a one-to-one correspondence.
LSTM and GRU Units
Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRUs) are types of recurrent neural network (RNN) cells that are used to process sequential data. Both LSTMs and GRUs are designed to overcome the vanishing gradients and exploding gradients problem, which occurs when training traditional RNNs and can make it difficult for the gradients of the parameters to propagate through the network.
The problem of Vanishing and Exploding Gradients
- The problem of vanishing and exploding gradients occurs in deep neural networks during backpropagation.
- Vanishing gradients occur when the gradients of the weights become very small, causing the weights to update only slightly with each training step.
- Exploding gradients occur when the gradients of the weights become very large, causing the weights to update very quickly with each training step.
- Reasons for these problems are :
- Activation function used in the network has a small derivative, such as the sigmoid function.
- Network is deep, and the gradients are multiplied many times during backpropagation.
- Gradients are multiplied many times during backpropagation, and the weight values are initialized to be too large.
- To address these problems :
- Techniques such as gradient clipping and weight initialization methods such as Xavier initialization can be used.
- Activation functions with a stable derivative like relu can help prevent these problems.
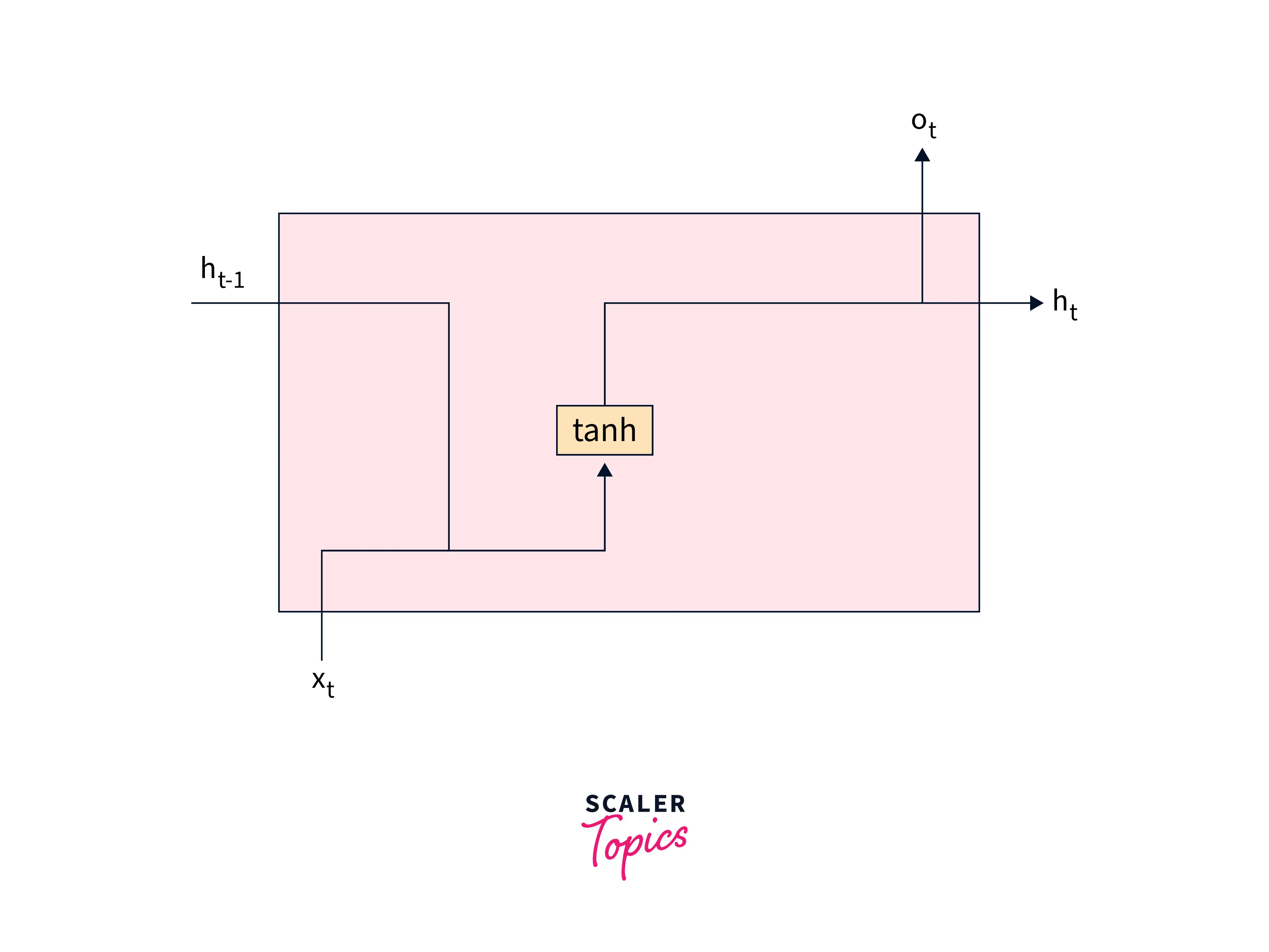
RNNs
RNNs have a hidden state that captures the information from the input elements and the previous hidden state and is used to predict the next element in the sequence. Due to their nature, they are more vulnerable to the vanishing and exploding gradients problem.
LSTM
Long Short-Term Memory (LSTM) is a type of RNN cell designed to overcome the gradient problem, making it difficult for the gradients of the parameters to propagate through the network. LSTMs have three gates: an input gate, an output gate, and a forget gate. The gates control the flow of information through the cell, allowing the LSTM to capture long-term dependencies in the data.
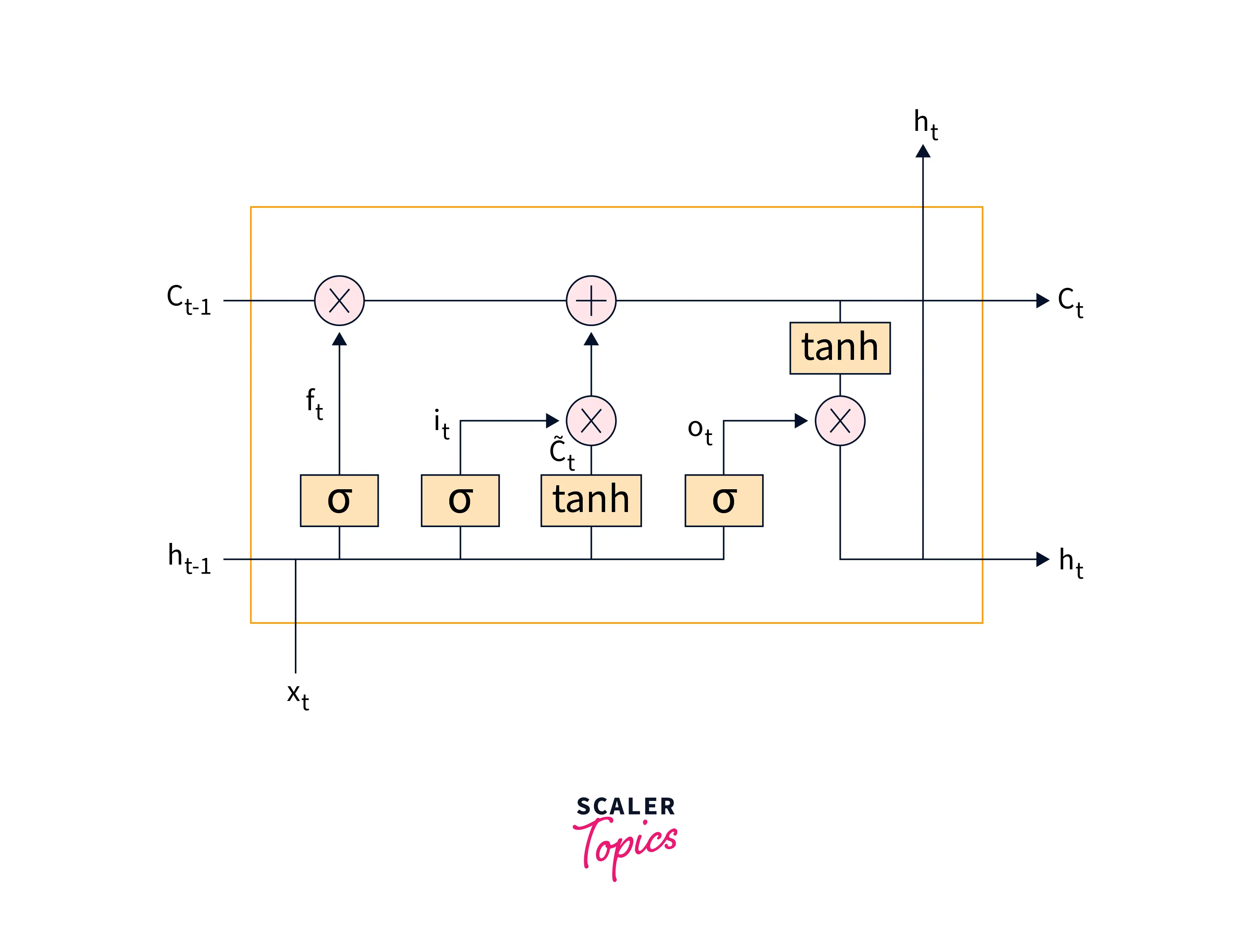
GRU
Gated Recurrent Units (GRUs) are another type of RNN cell designed to overcome the gradients problem. GRUs are simpler than LSTMs and do not have separate input, output, and forget gates. Instead, they have a single update gate that controls the flow of information through the cell.

LSTMs vs GRUs
LSTMs and GRUs have been used in various NLP tasks, including language translation, modeling, and text classification. In general, LSTMs tend to perform better on tasks with long-term dependencies, while GRUs are faster to train and can be a good alternative when the task does not require the ability to capture long-term dependencies.
When to Use Each?
The choice between RNNs, LSTMs, and GRUs will depend on the task's specific requirements and the data's nature. Here are some general guidelines for when to use each type of network:
RNNs: RNNs are general-purpose neural networks that can handle tasks involving sequential data. They are suitable for tasks with short sequences and are simple to implement and understand.
LSTMs: LSTMs are particularly good at capturing long-term dependencies in the data and are, therefore, well-suited for tasks with long sequences. They are more complex than RNNs and may be slower to train, but they can provide better performance on tasks with long-term dependencies.
GRUs: GRUs are similar to LSTMs but are simpler and faster to train. They are a good alternative to LSTMs when the task does not require the ability to capture long-term dependencies.
When deciding between using a Long Short-Term Memory (LSTM) or a Gated Recurrent Unit (GRU) for a specific task, try both and choose the one that performs better. In cases where the two models perform similarly, it may be advisable to opt for the GRU model as it is generally less computationally expensive.
Attention Mechanism
The attention mechanism is a technique used in encoder-decoder architectures to allow the decoder to focus on specific parts of the input sequence while generating the output sequence. This can be particularly useful for tasks such as machine translation, where the meaning of a word in the output sequence may depend on specific words in the input sequence.
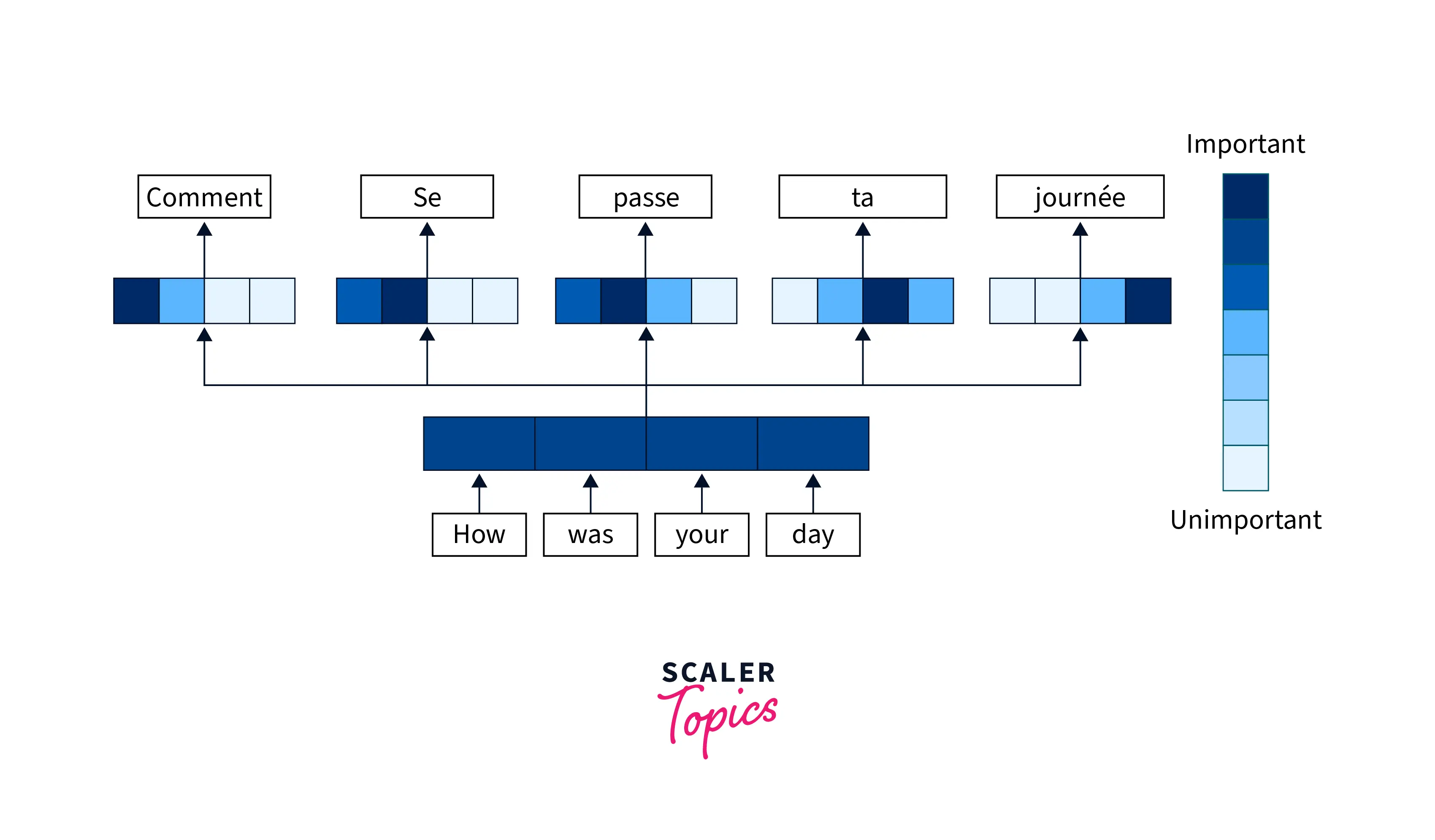
The attention mechanism works by calculating a weight for each element in the input sequence, indicating the importance of that element for generating the output sequence. The weights are calculated based on the current state of the decoder and the output generated so far. The decoder then uses the weighted sum of the input elements, weighted by the attention weights, to generate the next element in the output sequence.
By allowing the decoder to attend to specific parts of the input sequence while generating the output sequence, the attention mechanism can improve the performance of the encoder-decoder architecture. It allows the decoder to focus on the most relevant parts of the input sequence, which can help to improve the quality of the generated output. In addition, the attention mechanism can help to alleviate the problem of the input sequence being too long for the decoder to process effectively by allowing the decoder to focus on the most important parts of the input sequence.
Conclusion
- Encoder-decoder architecture is used in machine translation, text summarization, and image captioning tasks.
- Encoder compresses input to fixed-length vector; decoder generates output from it.
- It can be implemented using RNNs or transformer networks and trained using input-output pairs to learn to map.
- Encoded vector used as an initial hidden state of the decoder.
- Can face a problem of vanishing/exploding gradients, which can be addressed using techniques such as gradient clipping, weight initialization, and stable activation functions.