Getting Started with NLTK in NLP
Overview
Natural Language Processing(NLP) has become the cornerstone of machine learning projects. The applications of NLP are going up by leaps and bounds. Data in the form of texts, speech, and voice are intuitively analyzed in order to get meaningful results. "With huge data comes huge responsibilities" and hence we need a reliable Python package to handle them, and the best one yet is NLTK.
Introduction
There are a plethora of algorithms involved in Natural Language Processing such as tokenization, stemming, lemmatization and many more. The major portion of the data that has to be analyzed is unstructured and one of the most important processes in any application of NLP is to preprocess it. Here's where the Natural Language Tool Kit(NLTK) comes in.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
What is NLTK?
NLTK(Natural Language Tool Kit) is a collection of libraries and programs for statistical natural language processing for English, written in the Python programming language. It is one the most powerful libraries in NLP, helping our machine learning models to interpret human language. Learning about the NLTK library is crucial while building a career in AI and NLP. The package helps incredibly with text preprocessing and makes the tedious task look simple. NLTK helps us to implement basic to advanced preprocessing algorithms such as lower casing, tokenization, punctuation removal, word count, POS tagging, stemming, lemmatization, etc.
How to Install NLTK
Prerequisites
NLTK requires Python versions 3.7, 3.8, 3.9 or 3.10
Installation
- pip
- Anaconda
- Jupyter Notebook
NLTK has an easy-to-use interface and provides the users with over 50 corpora and lexical resources. To use them, we use the NLTK's data downloader.
Installing NLTK data
You can test the downloaded data by:-
Output:-
Performing NLP Tasks with NLTK
- Tokenization : This is the first step in any NLP process that uses text data. Tokenization is a mandatory step, which simplifies things for our machine learning model. It is the process of breaking down a piece of text into individual components or smaller units called tokens. The ultimate goal of tokenization is to process the raw text data and create a vocabulary from it.
Tokenize words:- We use word_tokenize
Output
Tokenize sentences:- We use sent_tokenize
Output
- Filtering stop words The most commonly used words are called stopwords. They contribute very less to the predictions and add very little value analytically. Hence, removing stopwords will make it easier for our models to train the text data.We use nltk.corpus.stopwords.words(‘english’) for this purpose.
Output
- Stemming:- Stemming or text standardization converts each word into its root/base form. For example, the word "faster" will change into "fast". The drawback of stemming is that it ignores the semantic meaning of words and simply strips the words of their prefixes and suffixes. The word "laziness" will be converted to "lazi" and not "lazy".
For the purpose of stemming, we generally use the PorterStemmer of the NLTK library. We can stem the filtered words we obtained after removing the stopwords in the previous example.
Output
Notice how the word "however" is stemmed to "howev"
- Lemmatization:- This process overcomes the drawback of stemming and makes sure that a word does not lose its meaning. Lemmatization uses a pre-defined dictionary to store the context words and reduces the words in data based on their context. NLTK uses the WordNetLemmatizer for the purpose of lemmatization.
Output
- POS tagging:- POS or Parts Of Speech tagging is a very important data preprocessing technique of Natural Language Processing. In this process, we assign each of the words to one of the parts of speech, such as a noun, adjective, verb, etc. The processes of tokenization, punctuation removal and stopwords removal are preferred before tagging the words with their respective parts of speech.
Output:-
The parts of speech are abbreviated, so NNP stands for a singular proper noun, JJ stands for adjective and so on.
- Named Entity Recognition:- Named Entity Recognition or NER is a very popular data preprocessing task. This process identifies key information in the text data and classifies it into certain predefined categories such as a person, organization, location, numerals and many more.
The steps for implementing NER with NLTK are as follows:-
- Tokenize the sentences.
- Tokenize the words.
- Tag the words with their parts of speech.
- Chunking: It is the process of natural language processing used to identify parts of speech and short phrases present in a given sentence.
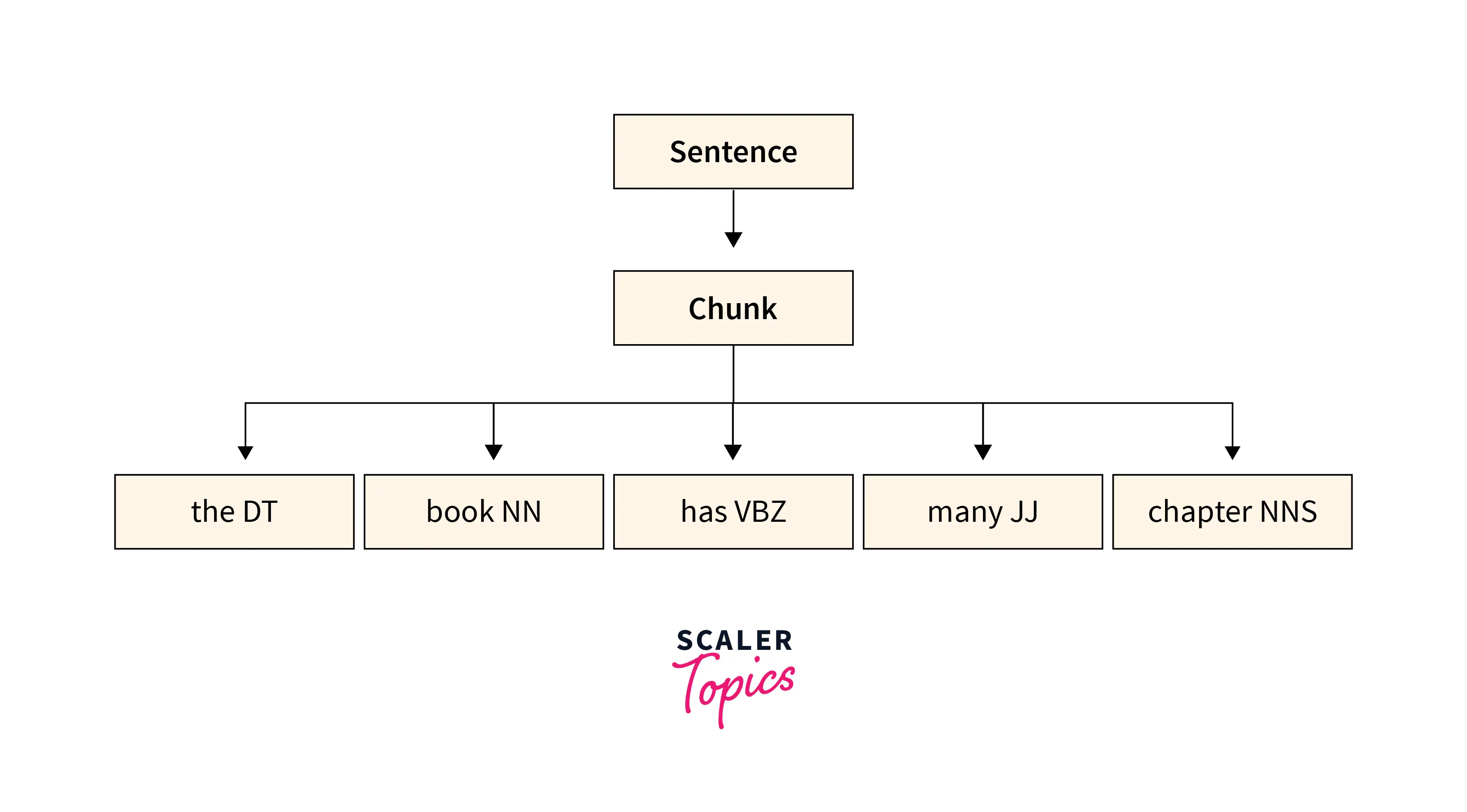
Find the chunk words(labeled words) using nltk.ne_chunk
Output:-
With only a few lines of code, our model recognizes the organizations and the geographical locations present in the text data.
Conclusion
If you want a career in NLP or you want to build interesting projects in NLP, then NLTK will be your greatest asset. The key takeaways from this article are:-
- Natural Language Tool Kit or NLTK is a Python package of the English language that has a collection of libraries and packages for symbolic and statistical natural language processing.
- NLTK has primarily been used in data preprocessing tasks.
- For tokenization we use word_tokenize and sent_tokenize.
- For stopwords removal we use nltk.corpus.stopwords.words(‘english’)
- PorterStemmer and WordNetLemmatizer help us with stemming and lemmatization, respectively.
- Finally, we implemented POS tagging and Named Entity Recognition using various combinations of operations in NLTK.