GloVe in NLP
Overview
The article discusses word embeddings, a method for representing the meaning of words in a numerical format, and specifically focuses on the GloVe (Global Vectors) algorithm for creating glove embeddings. You can use glove embeddings in natural languages processing tasks such as language translation, text classification, and information retrieval.
Introduction
In the context of a GRU network, word embeddings are often used as the input to the network. The embeddings capture the semantic meaning of the words in a numerical format that the network can easily process. These embeddings are typically pre-trained using a method like GloVe and are then used as input to the GRU network, which is trained on the specific task.
Using pre-trained word embeddings can improve the performance of a GRU network because the embeddings already capture a lot of the meaning and context of the words in the dataset. Additionally, pre-trained embeddings can significantly reduce the data and computational resources needed to train the GRU network.
It's worth noting that other techniques like word2vec, and fasttext also can be used to get word embeddings. And now, with the state-of-the-art transformer-based models, like BERT, RoBERTa, or ALBERT, which provide contextualized word embeddings, these are very useful in NLP tasks.
Getting Started with GloVe in NLP
To start with the GloVe algorithm, you can download the code from the GloVe website. The code is available in both C and Python, and it includes tools for training the GloVe algorithm on your datasets and evaluating the performance of the trained model.
Download Pre-trained Word Vectors
Pre-trained word vectors are words trained on a large corpus of text and are made available for download in natural language processing (NLP) tasks. These pre-trained word vectors can be used as a starting point for training a model on a new dataset or as features in a machine learning model.
To download pre-trained word vectors for GloVe (short for Global Vectors), you can visit the GloVe website and select the desired word vector model from the available options. These options may include different sizes of word vectors (e.g., 50, 100, 200, 300 dimensions) and different training corpora (e.g., Wikipedia, Common Crawl).
Once you have selected the desired word vector model, you can download and use the file in your NLP project. Unzip the file and load the word vectors into your program using a library such as gensim or TensorFlow.
Pre-trained word vectors can be a useful resource for NLP tasks, as they provide a strong starting point for learning word representations and can save time and resources that would otherwise be spent on training a model from scratch. However, it is also important to consider whether the pre-trained word vectors are appropriate for your specific task and dataset, as they may only sometimes capture the specific characteristics and relationships of the words in your dataset.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Citing GloVe
If you use the GloVe algorithm in your research, please cite the following paper:
Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP). GloVe: Global Vectors for Word Representation.
It is also worth noting that the pre-trained glove embeddings of the GloVe algorithm and many other algorithms are available to download and use in various research and development tasks. Still, checking their licenses before using them in your projects is always good practice.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Create a Vocabulary Dictionary
Creating a vocabulary dictionary in the GloVe algorithm involves preprocessing the training dataset to identify all the unique words or tokens in the data. Creating the vocabulary dictionary typically involves tokenizing the dataset into individual words, counting the frequency of each word, and then arranging the words in decreasing order of frequency. High-frequency words are usually included at the start of the dictionary, while low-frequency words are placed towards the end. Once the vocabulary dictionary is created, we can filter out infrequent or stop words.
Additionally, this dictionary is used to create a sparse word-word co-occurrence matrix which is used as input to the GloVe algorithm to learn glove embeddings. In this matrix, rows and columns are the words of the dictionary. This matrix captures the co-occurrences of words in a window (usually a fixed size, such as five words) in the corpus. By creating this matrix, the GloVe algorithm can efficiently learn the relationships between words in the dataset, which are important to create word embeddings.
In this example, we start by importing the necessary libraries; then, we create a sample dataset consisting of a text. Then, we tokenize the text using the nltk.word_tokenize() function, which splits the text into individual words.
Output:
The resulting vocab_dictionary is a python dictionary, where keys are the words of the dictionary and the values are their corresponding IDs.
This process will be done on much larger datasets in a real-world scenario.
Algorithm for Word Embedding
To generate glove embeddings using the GloVe algorithm, you will need to follow these steps:
- Step - 1:
Collect a large datasetof words and their co-oc currences. This can be a text corpus, such as documents or web pages. - Step - 2:
Preprocess the dataset by tokenizing the text into individual words and filtering out rare or irrelevant words. - Step - 3:
Construct a co-occurrence matrix that counts the number of times each word appears in the same context as every other word. - Step - 4:
Use the co-occurrence matrix to compute the word embeddings using the GloVe algorithm. This involves training a model to minimize the error between the word vectors' dot product and the co-occurrence counts' logarithm. - Step - 5:
Save the resulting word embeddings to a file or use them directly in your model.
Implementing GloVe in Python
Download Pre-trained Word Vectors for GloVe
This code uses the command line to download pre-trained GloVe word vectors from the internet, then unzips the downloaded file.
Load the GloVe Word Vectors
Output:
The code loads pre-trained GloVe word vectors into a python dictionary where the keys are words, and values are vectors. It reads the file line by line, then assigns the first element as the word and the rest as the vector. The vector is then added to the 'vocab' dictionary. The code prints the number of loaded word vectors at the end.
Turn Learning into Career Growth
Nearest Neighbors
The linguistic or semantic similarity of the matching words can be determined using the Euclidean distance (or cosine similarity) between two-word vectors. This statistic occasionally reveals uncommon but significant words outside the ordinary person's vocabulary. Here are some examples of words most similar to the word cat.
Linear Substructures
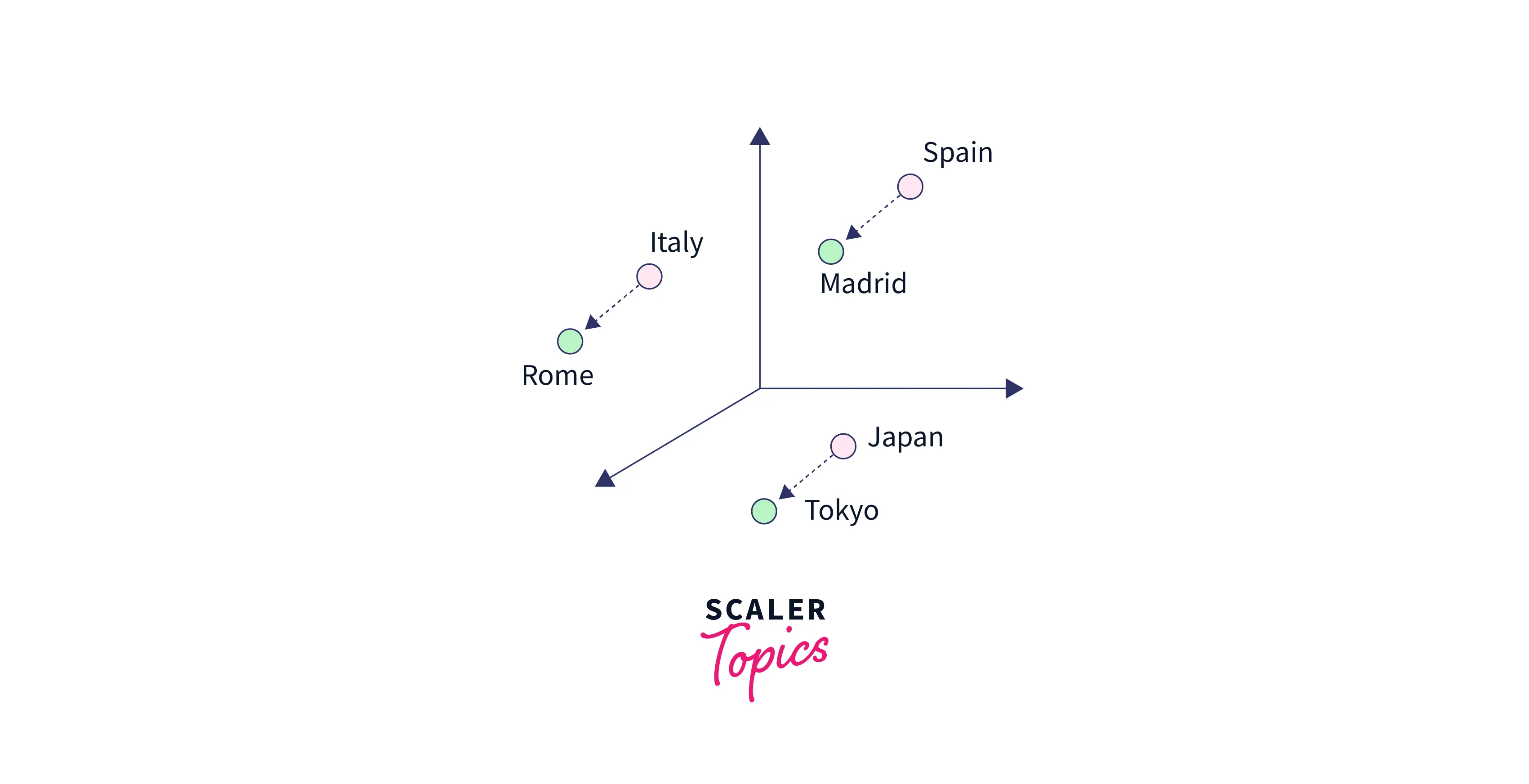
A single scalar that measures how closely two words are connected is produced by the similarity metrics used for nearest neighbor evaluations. The problem with this simplicity is that two given words nearly always reveal more complex relationships than can be expressed by a single number. Man and woman, for instance, could be seen as similar in that they both describe human beings, yet they are frequently seen as opposites because they draw attention to a key way in which people differ from one another.
Output:
Training
Here are the general steps to train a GloVe model:
- Prepare the training corpus:
The first step is to prepare a large corpus of text that we will use to train the GloVe model. This corpus should be representative of the text that the model will be used on. - Tokenize the corpus:
The next step is to tokenize the text in the corpus. Tokenization is the process of breaking the text into individual words or tokens. This step is necessary because we will train the GloVe model on individual words. - Create the word-word co-occurrence matrix:
Once the text is tokenized, the next step is to create a word-word co-occurrence matrix. This matrix tracks how frequently words occur alongside one another in the corpus. The matrix is typically sparse, which means that most entries are zero. - Collect co-occurrence statistics:
This step is the most computationally expensive part of the process because the algorithm goes through the whole corpus once to collect the statistics for the matrix; however, this step is only required once. - Train the GloVe model:
Once the co-occurrence statistics are collected, we can start training. The GloVe algorithm learns the word vectors by solving an optimization problem on the co-occurrence matrix. This process is done iteratively, adjusting the vectors after each iteration until it reaches a satisfactory solution. - Use the trained model:
Once the model is trained, we can use it for various natural languages processing tasks such as text classification, information retrieval, and language translation.
Model Overview
A weighted least-squares objective log-bilinear model is what GloVe is. The basic finding is that ratios of word-to-word co-occurrence probabilities used to encode some meaning are the main intuition behind the model. Consider, for instance, the likelihood that the vocabulary terms ice and steam will occur together with different probing words. Here are some precise probabilities drawn from a corpus of 6 billion words:
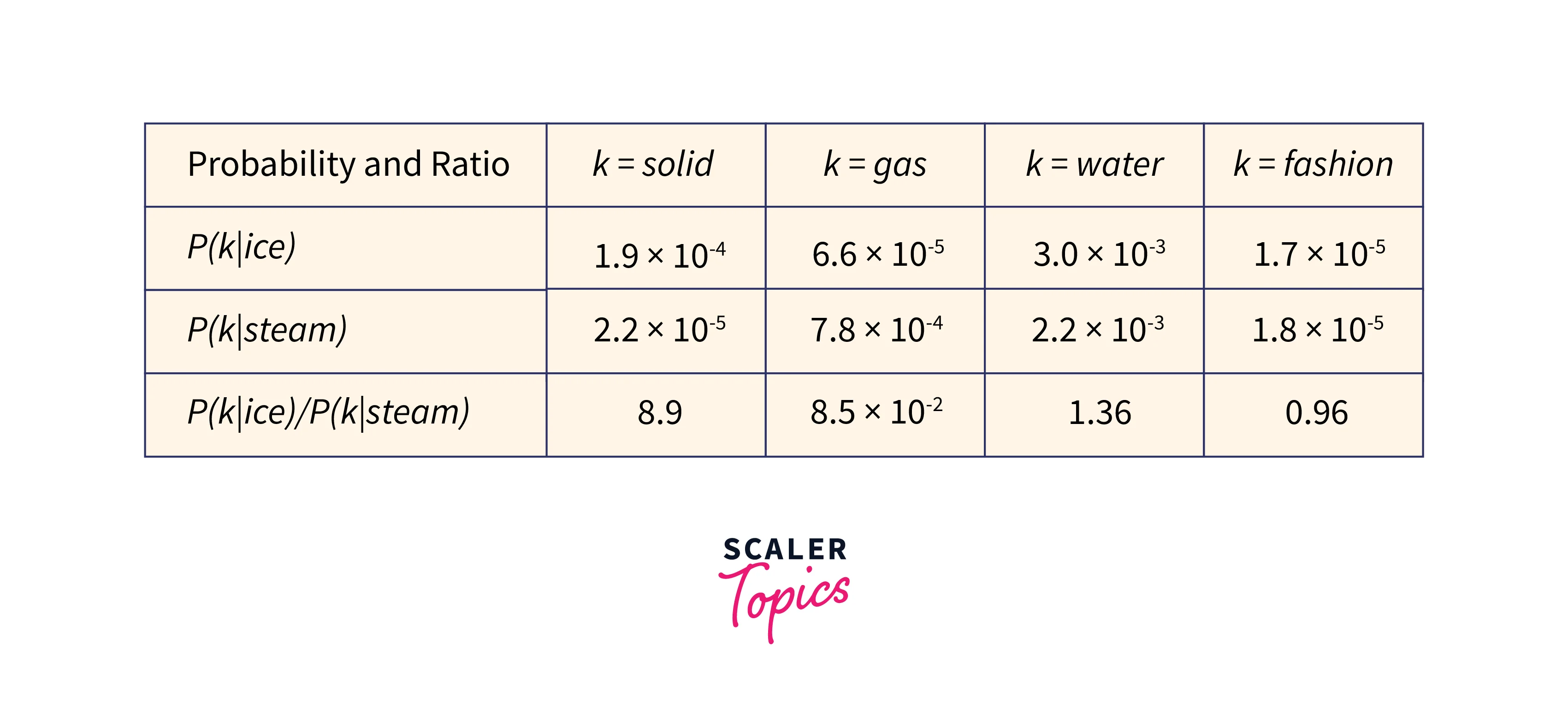
The GloVe algorithm is designed to create word embeddings, or numerical representations of the meanings of words, by analyzing the co-occurrence of words in a corpus. The algorithm uses a co-occurrence matrix to learn the relationships between words, where the values in the matrix represent the probabilities of the words occurring together.
The training goal of the algorithm is to acquire word vectors whose dot product equals the logarithm of the probability of the words occurring together. This links the logarithm of ratios of co-occurrence probability with vector differences in the word vector space and helps the word vectors excel at word analogy tasks like those studied by the word2vec algorithm.
Visualization
The output of this code is a 2D scatter plot that shows the relationships between the words in the vocabulary based on their word vectors. The word vectors are trained word representations learned by the GloVe algorithm and capture the meaning of words.
Visualizing them in the 2D space can give a sense of how similar or dissimilar the words are in their meanings. The t-SNE algorithm maps the high-dimensional vectors to a 2D space, where similar vectors are mapped to nearby points, and different vectors are mapped to farther points.
Output:
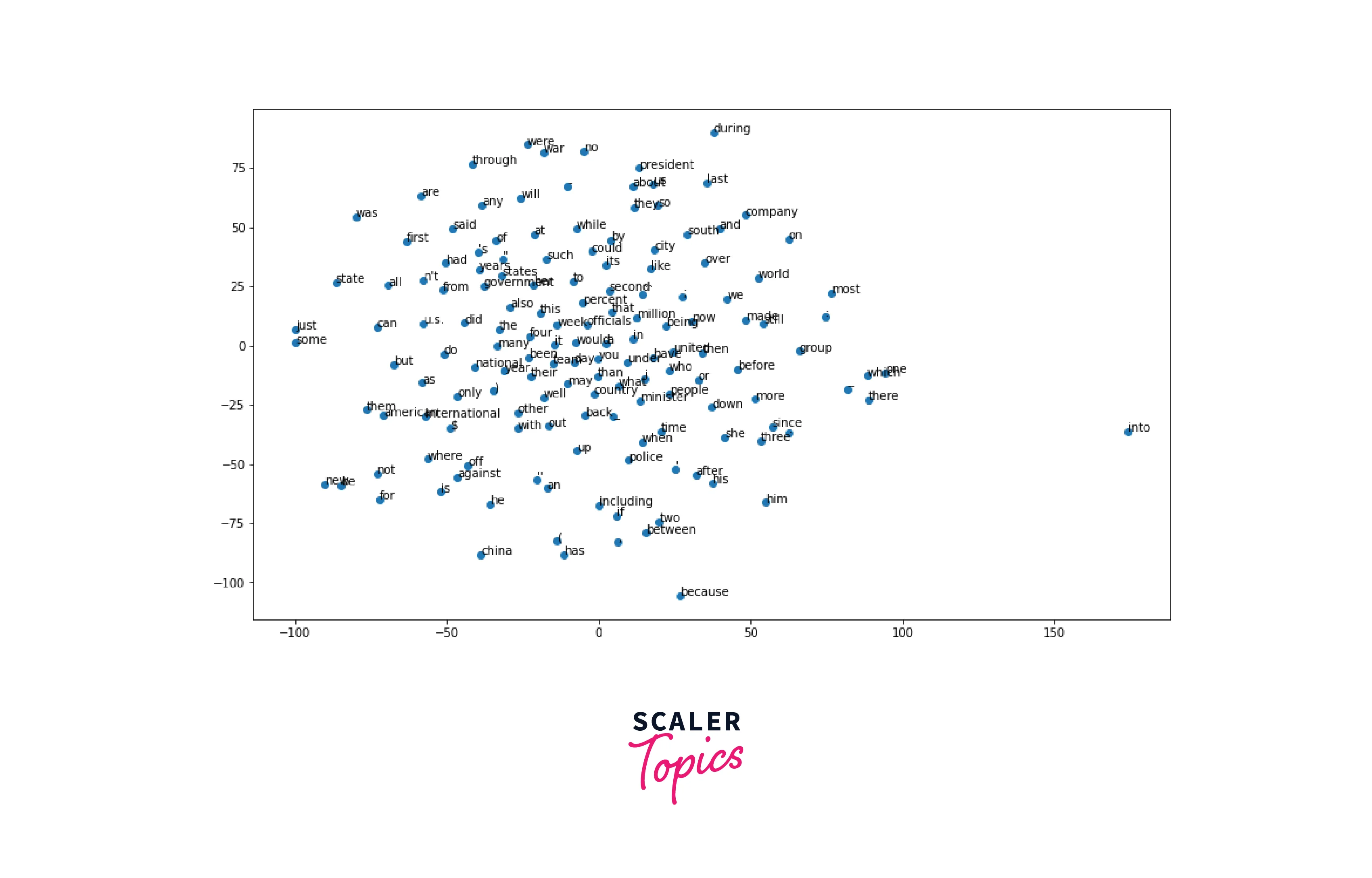
On the scatter plot, each point represents a word, and the position of the point in the 2D space represents the word's meaning according to the GloVe model. Each dish is labeled at the corresponding point on the scatter plot.
Conclusion
- In conclusion, the GloVe algorithm is a powerful tool for creating word glove embeddings, which are numerical representations of the meanings of words.
- You can use these glove embeddings in natural languages processing tasks such as language translation, text classification, and information retrieval.
- The GloVe algorithm uses a co-occurrence matrix to learn the relationships between words, and it can be trained on large datasets to learn rich and accurate embeddings.
- The glove embeddings learned using the GloVe algorithm can also be used to find nearest neighbors and identify linear substructures.
- Overall, the GloVe algorithm is a valuable resource for anyone working with natural language data.