Understanding GPT-1, GPT-2, and GPT-3
Overview
Language models have made significant advancements in natural language processing (NLP) in recent years, and OpenAI's GPT versions stands as a prominent example of these advancements. The GPT (Generative Pre-trained Transformer) models have revolutionized the field by leveraging deep learning and Transformer architectures. In this article, we will explore the evolution of language models, the significance of language models in NLP tasks, and delve into the three generations of GPT models: GPT-1, GPT-2, and GPT-3. We will examine their features, limitations, use cases, and real-world impact.
Evolution of Language Models
Language models have evolved significantly over the years, from traditional n-gram models to recurrent neural networks (RNNs) and long short-term memory (LSTM) models. These early models lacked the capacity to capture long-term dependencies effectively and struggled with generating coherent and contextually appropriate text.
The breakthrough came with the introduction of the Transformer model in 2017, which replaced sequential processing with parallel attention mechanisms. The Transformer model demonstrated improved performance on various NLP tasks and enabled the development of more sophisticated language models like GPT.
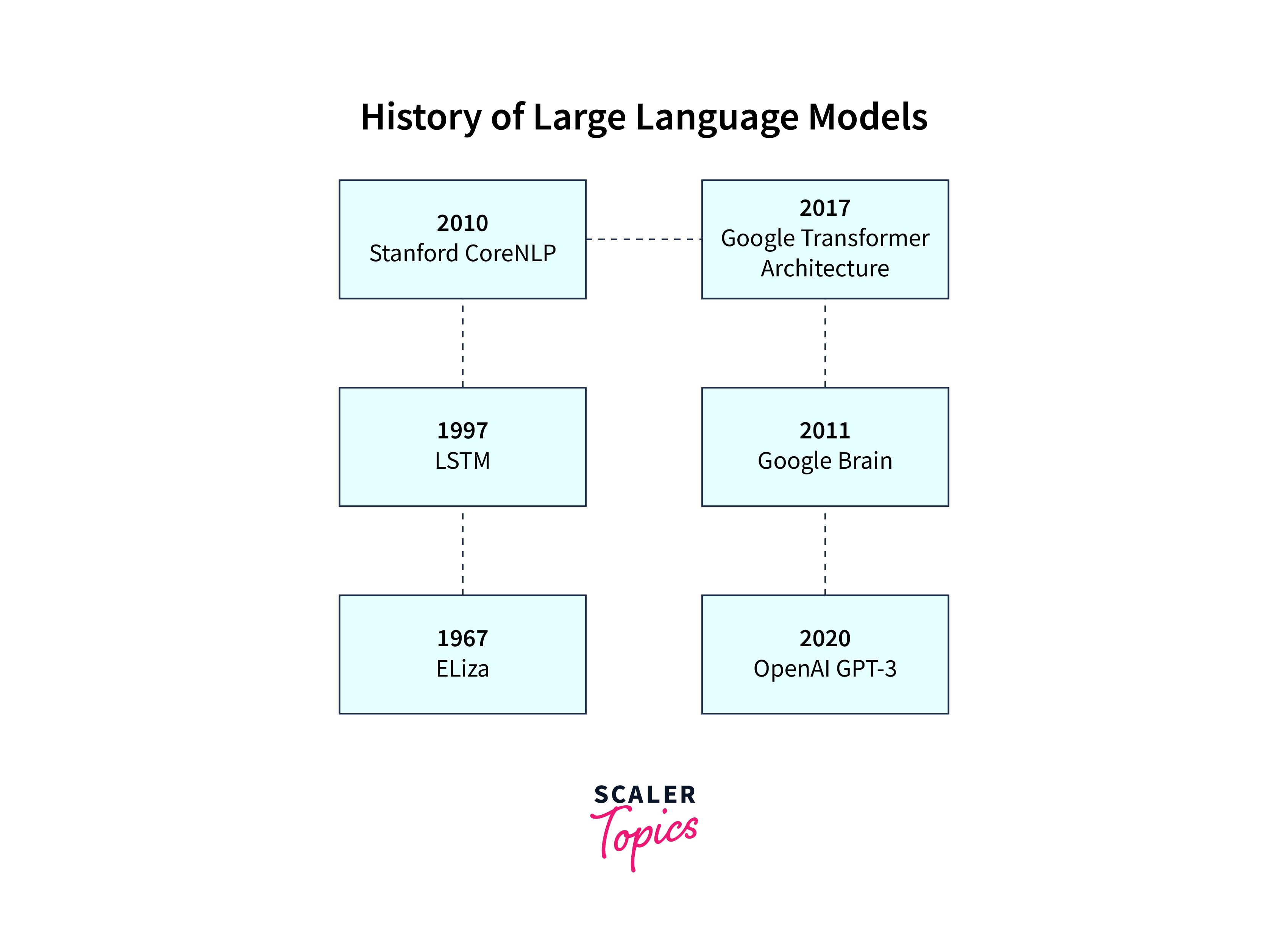
Introduction to OpenAI's GPT Series
OpenAI's GPT versions represents a groundbreaking line of generative language models that have garnered significant attention and acclaim in artificial intelligence and NLP. The series is characterized by its innovative use of Transformer architecture and large-scale pre-training on massive text corpora.
Key Elements of the GPT Series:
- Transformer Architecture:
The GPT versions are built upon the Transformer architecture, known for its effectiveness in capturing long-range dependencies in sequential data. This architecture serves as the foundation for the impressive capabilities of GPT models. - Pre-training:
One of the defining features of the GPT versions are pre-training. These models are initially exposed to massive amounts of text data from the internet, allowing them to learn language patterns, grammar, and contextual relationships. - Fine-tuning:
GPT models can be fine-tuned on specific NLP tasks after pre-training, making them versatile and adaptable to various applications. This fine-tuning process tailors the model's capabilities to perform well on specific tasks, such as text generation, translation, question answering, and more.

Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
The First Generation Transformer Model - GPT-1
GPT-1, the first iteration of the GPT series, was introduced by OpenAI in 2018. It was one of the earliest language models to leverage the Transformer architecture for natural language understanding and generation. It is a unidirectional language model, meaning it processes the text from left to right and generates text sequentially. It utilizes a multi-layer Transformer architecture with self-attention mechanisms to capture contextual information effectively.
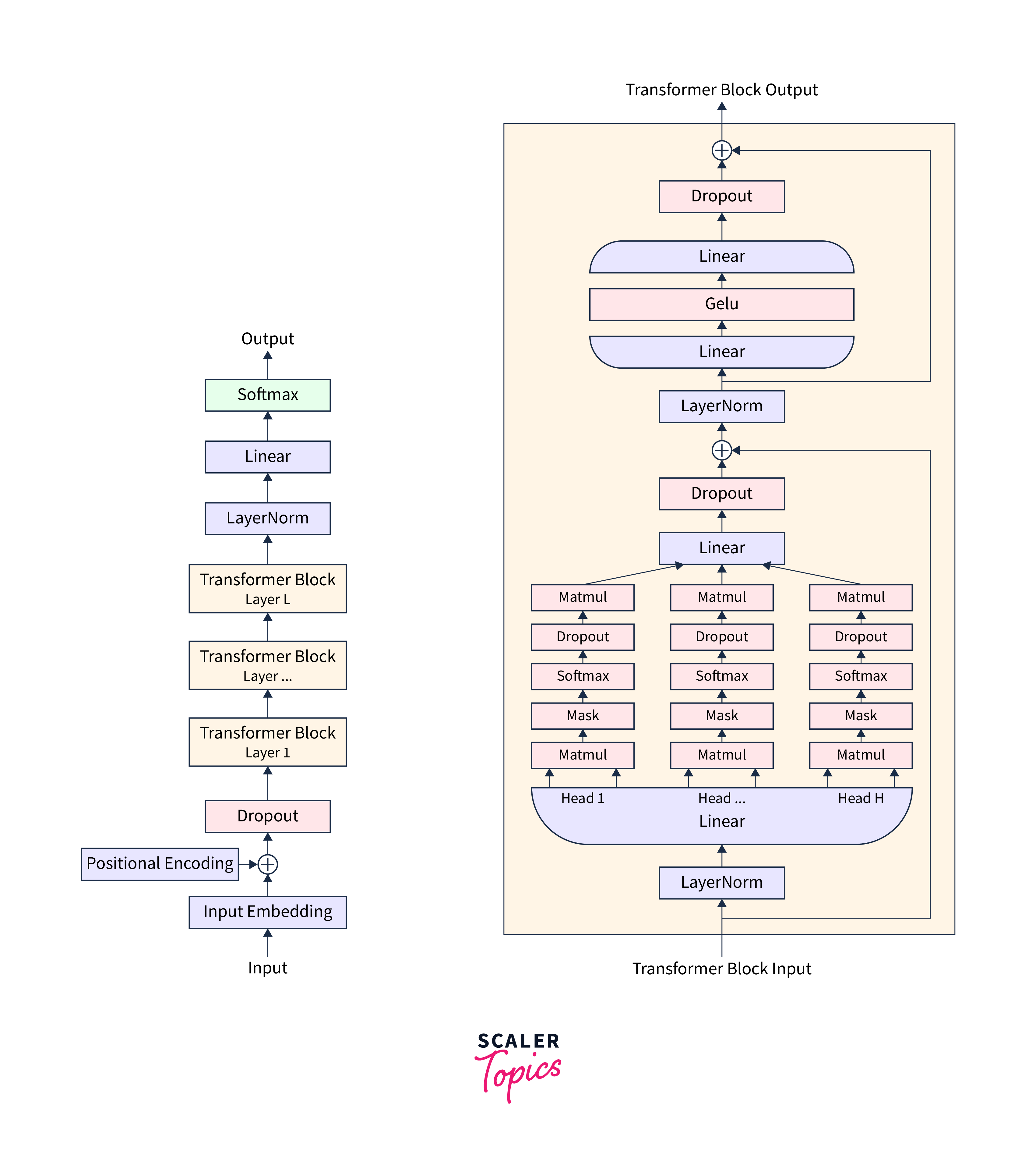
Key Features and Limitations
GPT-1 demonstrated significant progress in language modeling and showed promise in generating coherent and contextually relevant text. Some of its key features and limitations include:
-
Context Window:
GPT-1 had a limited context window due to its unidirectional nature. It could consider only the tokens to the left of the current word, which sometimes affected its understanding of long-range dependencies. -
Parameter Size:
Compared to more recent models, GPT-1 had a smaller parameter size, which limited its capacity to understand complex linguistic structures. -
Fine-Tuning:
GPT-1 could be fine-tuned for specific tasks, but the fine-tuning process required a considerable amount of labeled data to achieve high performance.
Applications of GPT-1
GPT-1 proved valuable in several applications, including:
- Text Generation:
GPT-1 can generate coherent and contextually relevant text, making it a valuable tool for content creation. This includes writing articles, essays, product descriptions, and more. - Translation Assistance:
While more specialized than dedicated translation models, GPT-1 can provide assistance in translating text between languages. It can offer translations for basic sentences and phrases. - Basic QA Tasks:
GPT-1 can answer factual questions to some extent. It can provide information from its pre-trained knowledge but may need to improve at complex reasoning or fact-checking. - Summarizing Content:
GPT-1 can generate concise summaries of lengthy texts, such as news articles or research papers, helping users quickly grasp the main points.
GPT-2 - Advancements in Scale and Performance
GPT-2, the second iteration of the GPT versions, marked a significant leap in scale and performance. Released by OpenAI in 2019, GPT-2 demonstrated the potential of large-scale language models for various NLP tasks. GPT-2 retained the fundamental architecture of GPT-1 but introduced significant improvements in model size and training data.
![]()
One of the key advancements in GPT-2 was the increase in model size and the number of parameters. GPT-2 had a much larger parameter size compared to GPT-1, enabling it to capture more complex linguistic patterns and nuances in the data.
Turn Learning into Career Growth
Applications of GPT-2
GPT-2 showcased impressive performance in various NLP tasks, such as:
- Language Translation:
GPT-2 exhibited improved translation capabilities, making it suitable for machine translation tasks. - Text Summarization:
The model's increased capacity allowed it to generate more informative and concise summaries. - Question-Answering:
GPT-2 further excelled in answering questions based on the provided context.
GPT-2's larger size and improved performance opened new possibilities for using language models in real-world applications.
GPT-3: Breakthroughs in Language Understanding
GPT-3, released in 2020, represents a significant breakthrough in language understanding and generation. It introduced unprecedented scale and capabilities, propelling language models to new heights. GPT-3 continued to leverage the Transformer architecture but was trained on an even larger dataset and had a substantially larger number of parameters compared to GPT-2.
![]()
GPT-3's unprecedented scale with over 175 billion parameters allowed it to capture complex linguistic patterns and understand human language at a remarkable level. The model exhibited impressive capabilities in natural language understanding and generation tasks.
Few-Shot and Zero-Shot Learning
One of the most remarkable aspects of GPT-3 was its ability to perform few-shot and zero-shot learning. Few-shot learning refers to learning from only a few examples of a task, while zero-shot learning allows the model to perform tasks for which it has not been explicitly trained.
GPT-3's few-shot and zero-shot learning capabilities demonstrated its generalization and adaptability to diverse tasks without the need for extensive fine-tuning.
Applications of GPT-3
GPT-3's capabilities have been harnessed in various real-world applications, including:
- Language Translation:
GPT-3 showcased remarkable performance in translating text between languages. - Content Generation:
The model's ability to generate coherent and contextually appropriate text made it valuable for content creation in various domains. - Chatbots and Dialogue Systems:
GPT-3's natural language understanding and generation capabilities have been applied in developing advanced chatbots and dialogue systems.
GPT-3's breakthroughs have had a profound impact on NLP and AI as a whole, sparking new possibilities and driving research in language models and related fields.
Comparison of GPT Models
Let's compare the three generations of GPT models based on various factors:
-
Model Architecture and Training Data:
GPT-1, GPT-2, and GPT-3 all share the Transformer architecture, but with increasing model sizes and more parameters in subsequent generations. GPT-1 was trained on a smaller dataset compared to GPT-2 and GPT-3, which had access to more extensive and diverse datasets. -
Size and Computational Requirements:
As we progress from GPT-1 to GPT-3, the model size and computational requirements increase significantly. GPT-1 had the smallest parameter size, followed by GPT-2 and GPT-3, with the latter being the largest. -
Language Generation Quality and Coherence:
With the increase in model size, GPT-2 and GPT-3 demonstrated improved language generation quality and coherence compared to GPT-1. GPT-3, in particular, achieved unprecedented levels of language understanding and generation. -
Use Case Suitability and Trade-offs:
Each generation of GPT models has its strengths and trade-offs. GPT-1 is suitable for various text generation tasks, but its smaller size limits its performance in complex applications. GPT-2 strikes a balance between model size and performance, while GPT-3's immense scale enables it to handle even more challenging language tasks.
| Feature | GPT-1 | GPT-2 | GPT-3 |
|---|---|---|---|
| Model Architecture | Transformer | Transformer | Transformer |
| Parameter Size | Small | Large | Very Large |
| Language Generation Quality | Good | Improved | Remarkable |
| Computational Requirements | Moderate | High | Very High |
| Few-Shot and Zero-Shot Learning | No | Limited | Yes |
Importance of Language Models
Language models are essential for various NLP tasks, such as:
- Machine Translation:
Language models enable accurate translation between different languages, facilitating communication and breaking language barriers. - Text Generation:
Language models can generate coherent and contextually appropriate text, making them valuable for content creation and creative writing. - Question-Answering Systems:
Language models aid in understanding questions and providing relevant and accurate answers based on the context. - Text Summarization:
Language models can summarize lengthy documents and articles, extracting key information for easy comprehension. - Sentiment Analysis:
Language models help in determining the sentiment and emotions conveyed in a piece of text, providing valuable insights for businesses and decision-making.
Language models have wide-ranging applications and have become crucial tools in advancing various aspects of NLP.
Conclusion
- The GPT versions, consisting of GPT-1, GPT-2, and GPT-3, has ushered in a new era of language models and transformed the landscape of natural language processing.
- From the early unidirectional GPT-1 to the breakthroughs of GPT-3 with its unparalleled scale and capabilities, each generation has pushed the boundaries of language understanding and generation.
- The continuous evolution of language models like GPT promises exciting opportunities and advancements in various NLP applications, making them indispensable tools for researchers, developers, and businesses across diverse domains.