Introduction to Grammar in NLP
Overview
Grammar in NLP is a set of rules for constructing sentences in a language used to understand and analyze the structure of sentences in text data.
This includes identifying parts of speech such as nouns, verbs, and adjectives, determining the subject and predicate of a sentence, and identifying the relationships between words and phrases.
Introduction
As humans, we talk in a language that is easily understandable to other humans and not computers. To make computers understand language, they must have a structure to follow. Syntax describes a language's regularity and productivity, making sentences' structure explicit. The word syntax here refers to the way the words are arranged together. Regular languages and parts of speech refer to how words are arranged together but cannot support easily, such as grammatical or dependency relations. These can be modeled by grammar. Let us dive deep into Grammar and explore the terms discussed here.
What is Grammar?
Grammar is defined as the rules for forming well-structured sentences. Grammar also plays an essential role in describing the syntactic structure of well-formed programs, like denoting the syntactical rules used for conversation in natural languages.
- In the theory of formal languages, grammar is also applicable in Computer Science, mainly in programming languages and data structures. Example - In the C programming language, the precise grammar rules state how functions are made with the help of lists and statements.
- Mathematically, a grammar G can be written as a 4-tuple (N, T, S, P) where:
- N or VN = set of non-terminal symbols or variables.
- T or ∑ = set of terminal symbols.
- S = Start symbol where S ∈ N
- P = Production rules for Terminals as well as Non-terminals.
- It has the form , where α and β are strings on , and at least one symbol of α belongs to VN
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Syntax
Each natural language has an underlying structure usually referred to under Syntax. The fundamental idea of syntax is that words group together to form the constituents like groups of words or phrases which behave as a single unit. These constituents can combine to form bigger constituents and, eventually, sentences.
- Syntax describes the regularity and productivity of a language making explicit the structure of sentences, and the goal of syntactic analysis or parsing is to detect if a sentence is correct and provide a syntactic structure of a sentence.
Syntax also refers to the way words are arranged together. Let us see some basic ideas related to syntax:
- Constituency: Groups of words may behave as a single unit or phrase - A constituent, for example, like a Noun phrase.
- Grammatical relations: These are the formalization of ideas from traditional grammar. Examples include - subjects and objects.
- Subcategorization and dependency relations: These are the relations between words and phrases, for example, a Verb followed by an infinitive verb.
- Regular languages and part of speech: Refers to the way words are arranged together but cannot support easily. Examples are Constituency, Grammatical relations, and Subcategorization and dependency relations.
- Syntactic categories and their common denotations in NLP: np - noun phrase, vp - verb phrase, s - sentence, det - determiner (article), n - noun, tv - transitive verb (takes an object), iv - intransitive verb, prep - preposition, pp - prepositional phrase, adj - adjective
Stop learning AI in fragments—master a structured AI Engineering Course with hands-on GenAI systems with IIT Roorkee CEC Certification
AI Engineering Course Advanced Certification by IIT-Roorkee CEC
A hands on AI engineering program covering Machine Learning, Generative AI, and LLMs - designed for working professionals & delivered by IIT Roorkee in collaboration with Scaler.
Enrol Now
Types of Grammar in NLP
Let us move on to discuss the types of grammar in NLP. We will cover three types of grammar: context-free, constituency, and dependency.
Context Free Grammar
Context-free grammar consists of a set of rules expressing how symbols of the language can be grouped and ordered together and a lexicon of words and symbols.
- One example rule is to express an NP (or noun phrase) that can be composed of either a ProperNoun or a determiner (Det) followed by a Nominal, a Nominal in turn can consist of one or more Nouns: NP → DetNominal, NP → ProperNoun; Nominal → Noun | NominalNoun
- Context-free rules can also be hierarchically embedded, so we can combine the previous rules with others, like the following, that express facts about the lexicon: Det → a Det → the Noun → flight
- Context-free grammar is a formalism power enough to represent complex relations and can be efficiently implemented. Context-free grammar is integrated into many language applications
- A Context free grammar consists of a set of rules or productions, each expressing the ways the symbols of the language can be grouped, and a lexicon of words
Context-free grammar (CFG) can also be seen as the list of rules that define the set of all well-formed sentences in a language. Each rule has a left-hand side that identifies a syntactic category and a right-hand side that defines its alternative parts reading from left to right. - Example: The rule s --> np vp means that "a sentence is defined as a noun phrase followed by a verb phrase."
- Formalism in rules for context-free grammar: A sentence in the language defined by a CFG is a series of words that can be derived by systematically applying the rules, beginning with a rule that has s on its left-hand side.
- Use of parse tree in context-free grammar: A convenient way to describe a parse is to show its parse tree, simply a graphical display of the parse.
- A parse of the sentence is a series of rule applications in which a syntactic category is replaced by the right-hand side of a rule that has that category on its left-hand side, and the final rule application yields the sentence itself.
- Example: A parse of the sentence "the giraffe dreams" is: s => np vp => det n vp => the n vp => the giraffe vp => the giraffe iv => the giraffe dreams
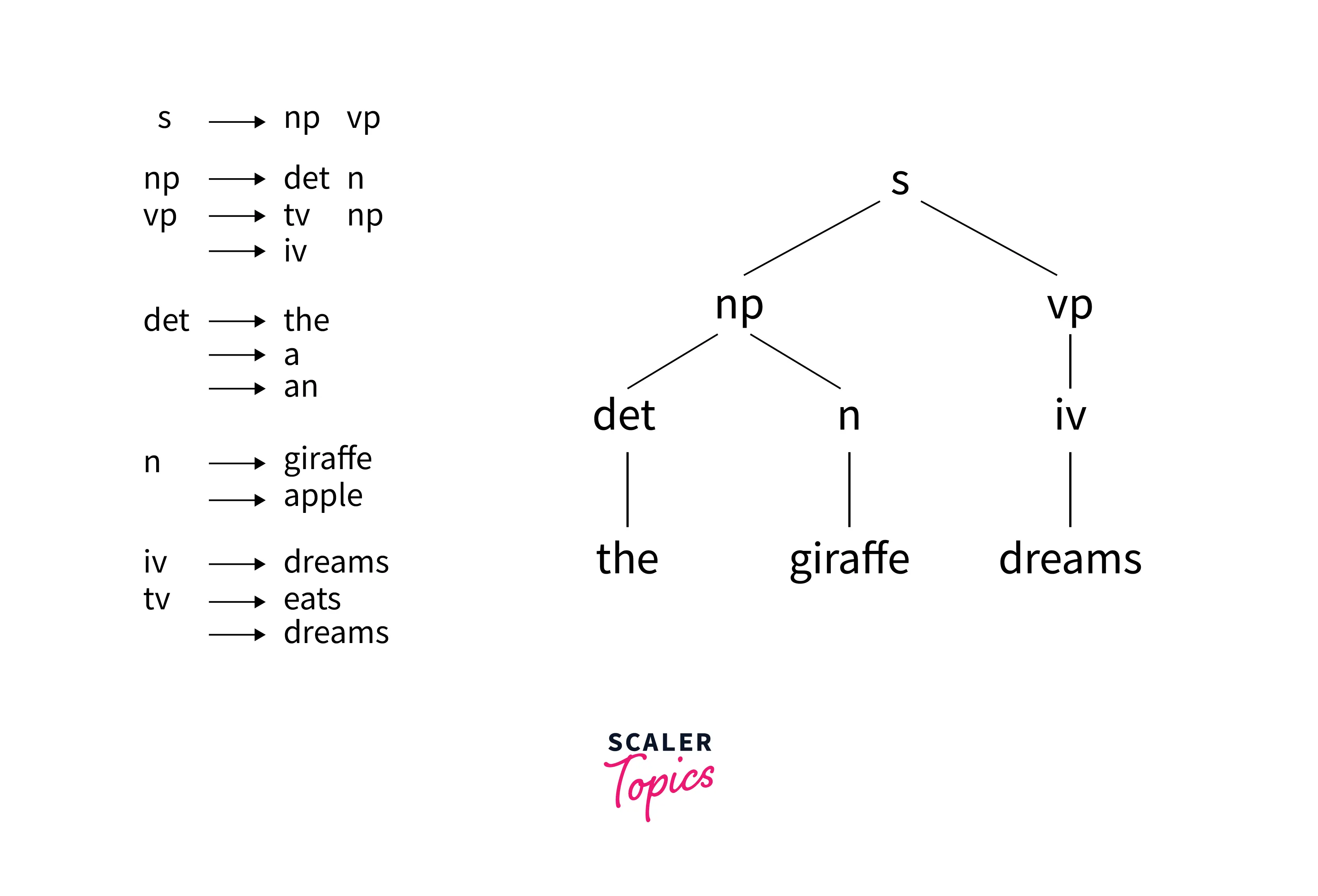
- If we look at the example parse tree for the sample sentence in the illustration the giraffe dreams, the graphical illustration shows the parse tree for the sentence
- We can see that the root of every subtree has a grammatical category that appears on the left-hand side of a rule, and the children of that root are identical to the elements on the right-hand side of that rule.
Turn Learning into Career Growth
Classification of Symbols in CFG
The symbols used in Context-free grammar are divided into two classes.
- The symbols that correspond to words in the language, for example, the nightclub, are called terminal symbols, and the lexicon is the set of rules that introduce these terminal symbols.
- The symbols that express abstractions over these terminals are called non-terminals.
- In each context-free rule, the item to the right of the arrow (→) is an ordered list of one or more terminals and non-terminals, and to the left of the arrow is a single non-terminal symbol expressing some cluster or generalization. - The non-terminal associated with each word in the lexicon is its lexical category or part of speech.
Context Free Grammar consists of a finite set of grammar rules that have four components: a Set of Non-Terminals, a Set of Terminals, a Set of Productions, and a Start Symbol.
CFG can also be seen as a notation used for describing the languages, a superset of Regular grammar.
CFG consists of a finite set of grammar rules having the following four components
- Set of Non-terminals: It is represented by V. The non-terminals are syntactic variables that denote the sets of strings, which help define the language generated with the help of grammar.
- Set of Terminals: It is also known as tokens and is represented by Σ. Strings are formed with the help of the basic symbols of terminals.
- Set of Productions: It is represented by P. The set explains how the terminals and non-terminals can be combined.
Every production consists of the following components:
- Non-terminals are also called variables or placeholders as they stand for other symbols, either terminals or non-terminals. They are symbols representing the structure of the language being described. Non-terminals are a set of production rules specifying how to replace a non-terminal symbol with a string of symbols, which can include terminals, words or characters, and other non-terminals.
- Start Symbol: The formal language defined by a CFG is the set of strings derivable from the designated start symbol. Each grammar must have one designated start symbol, which is often called S.
- Since context-free grammar is often used to define sentences, S is usually interpreted as the sentence node, and the set of strings that are derivable from S is the set of sentences in some simplified version of English.
Issues with using context-free grammar in NLP:
- Limited expressiveness: Context-free grammar is a limited formalism that cannot capture certain linguistic phenomena such as idiomatic expressions, coordination and ellipsis, and even long-distance dependencies.
- Handling idiomatic expressions: CFG may also have a hard time handling idiomatic expressions or idioms, phrases whose meaning cannot be inferred from the meanings of the individual words that make up the phrase.
- Handling coordination: CFG needs help to handle coordination, which is linking phrases or clauses with a conjunction.
- Handling ellipsis: Context-free grammar may need help to handle ellipsis, which is the omission of one or more words from a sentence that is recoverable from the context.
The limitations of context-free grammar can be mitigated by using other formalisms such as dependency grammar which is powerful but more complex to implement, or using a hybrid approach where both constituency and dependency are used together. We can also additionally use machine learning techniques in certain cases.
Master structured AI Engineering + GenAI hands-on, earn IIT Roorkee CEC Certification at ₹40,000
AI Engineering Course Advanced Certification by IIT-Roorkee CEC
A hands on AI engineering program covering Machine Learning, Generative AI, and LLMs - designed for working professionals & delivered by IIT Roorkee in collaboration with Scaler.
Enrol NowScaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Constituency Grammar
Constituency Grammar is also known as Phrase structure grammar. Furthermore, it is called constituency Grammar as it is based on the constituency relation. It is the opposite of dependency grammar.
- The constituents can be any word, group of words or phrases in Constituency Grammar. The goal of constituency grammar is to organize any sentence into its constituents using their properties.
- Characteristic properties of constituency grammar and constituency relation:
- All the related frameworks view the sentence structure in terms of constituency relation.
- To derive the constituency relation, we take the help of subject-predicate division of Latin as well as Greek grammar.
- In constituency grammar, we study the clause structure in terms of noun phrase NP and verb phrase VP.
- The properties are derived generally with the help of other NLP concepts like part of speech tagging, a noun or Verb phrase identification, etc. For example, Constituency grammar can organize any sentence into its three constituents - a subject, a context, and an object.
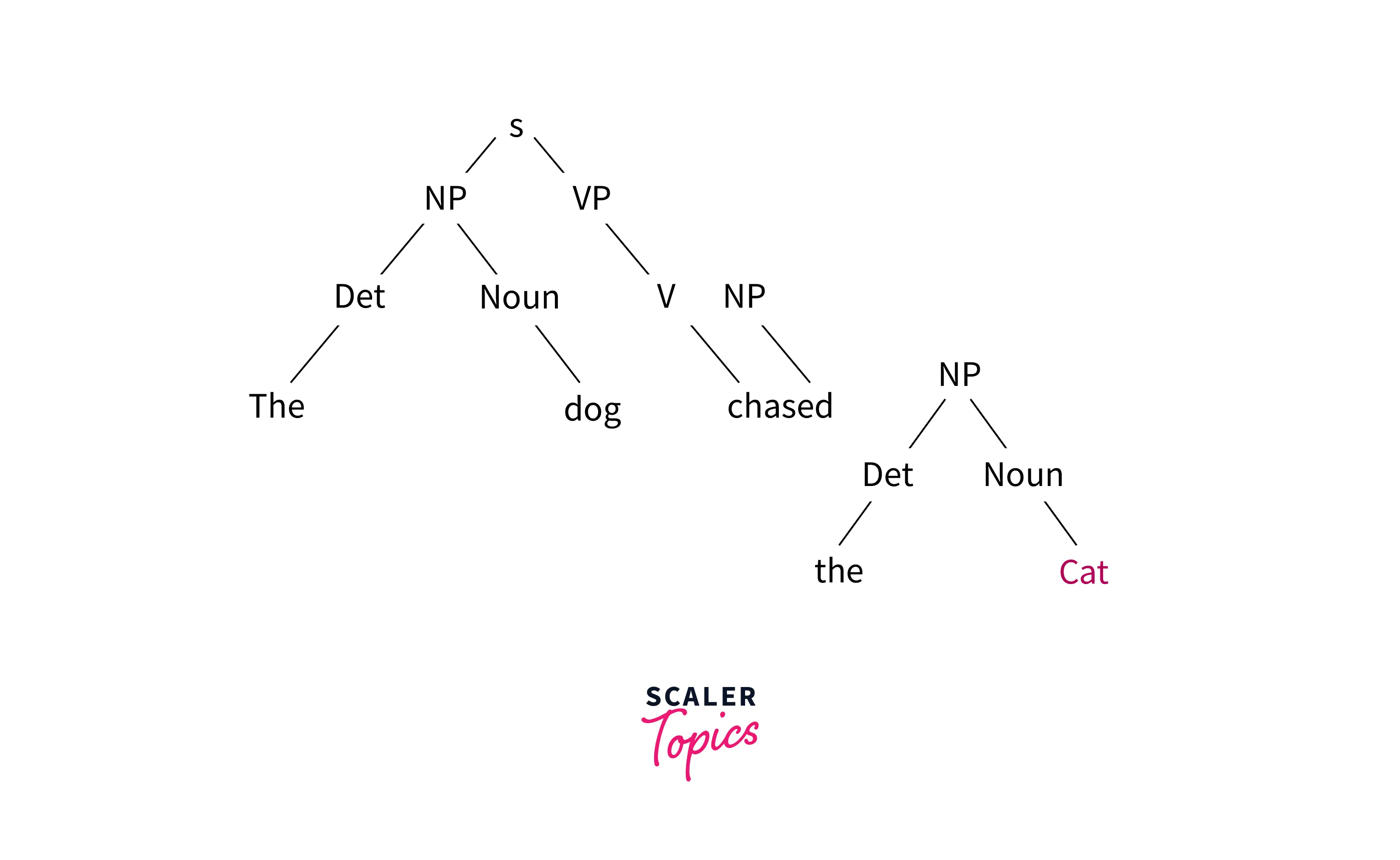
Look at a sample parse tree: Example sentence - "The dog chased the cat."
- In this parse tree, the sentence is represented by the root node S (for sentence). The sentence is divided into two main constituents: NP (noun phrase) and VP (verb phrase).
- The NP is further broken down into Det (determiner) and Noun, and the VP is further broken down into V (verb) and NP.
- Each of these constituents can be further broken down into smaller constituents.
Constituency grammar is better equipped to handle context-free and dependency grammar limitations. Let us look at them:
- Constituency grammar is not language-specific, making it easy to use the same model for multiple languages or switch between languages, hence handling the multilingual issue plaguing the other two types of grammar.
- Since constituency grammar uses a parse tree to represent the hierarchical relationship between the constituents of a sentence, it can be easily understood by humans and is more intuitive than other representation grammars.
- Constituency grammar also is simple and easier to implement than other formalisms, such as dependency grammar, making it more accessible for researchers and practitioners.
- Constituency grammar is robust to errors and can handle noisy or incomplete data.
- Constituency grammar is also better equipped to handle coordination which is the linking of phrases or clauses with a conjunction.
Dependency Grammar
Dependency Grammar is the opposite of constituency grammar and is based on the dependency relation. It is opposite to the constituency grammar because it lacks phrasal nodes.
Let us look at some fundamental points about Dependency grammar and dependency relation.
- Dependency Grammar states that words of a sentence are dependent upon other words of the sentence. These Words are connected by directed links in dependency grammar. The verb is considered the center of the clause structure.
- Dependency Grammar organizes the words of a sentence according to their dependencies. Every other syntactic unit is connected to the verb in terms of a directed link. These syntactic units are called dependencies.
- One of the words in a sentence behaves as a root, and all the other words except that word itself are linked directly or indirectly with the root using their dependencies.
- These dependencies represent relationships among the words in a sentence, and dependency grammar is used to infer the structure and semantic dependencies between the words.
Dependency grammar suffers from some limitations; let us understand them further.
- Ambiguity: Dependency grammar has issues with ambiguity when it comes to interpreting the grammatical relationships between words, which are particularly challenging when dealing with languages that have rich inflections or complex word order variations.
- Data annotation: Dependency parsing also requires labeled data to train the model, which is time-consuming and difficult to obtain.
- Handling long-distance dependencies: Dependency parsing also has issues with handling long-term dependencies in some cases where the relationships between words in a sentence may be very far apart, making it difficult to accurately capture the grammatical structure of the sentence.
- Handling ellipsis and coordination: Dependency grammar also has a hard time handling phenomena that are not captured by the direct relationships between words, such as ellipsis and coordination, which are typically captured by constituency grammar.
The limitations of dependency grammar can be mitigated by using constituency grammar which, although less powerful, but more intuitive and easier to implement. We can also use a hybrid approach where both constituency and dependency are used together, and it can be beneficial.
- Comparing Constituency grammar with Dependency grammar: Constituency grammar focuses on grouping words into phrases and clauses, while dependency grammar focuses on the relationships between individual words. Each word in a sentence is represented by a node in a dependency graph, and the edges between nodes represent the grammatical relationships between the words.
- Dependency grammar is typically more powerful for some languages and NLP tasks as it captures the relationships between the words more accurately, but also more complex to implement and less intuitive.
- Constituency grammar is more intuitive and easier to implement but can be less expressive.
Become the Ai engineer who can design, build, and iterate real AI products, not just demos with an IIT Roorkee CEC Certification
AI Engineering Course Advanced Certification by IIT-Roorkee CEC
A hands on AI engineering program covering Machine Learning, Generative AI, and LLMs - designed for working professionals & delivered by IIT Roorkee in collaboration with Scaler.
Enrol NowConclusion
- Grammar is defined as the rules for forming well-structured sentences and plays an essential role in denoting the syntactical rules that are used for conversation in natural languages.
- Syntax is the branch of grammar dealing with the structure and formation of sentences in a language governing how words are arranged to form phrases, clauses, and sentences.
- Context-free grammar is a formal grammar used to recognize the set of strings in a language using a set of production rules describing how to replace non-terminals with another string of symbols called terminals and non-terminals.
- Constituency grammar is another type of formal grammar to analyze the structure of sentences in a language using the idea that sentences can be broken down into smaller units called constituents with a specific grammatical function.
- Dependency grammar is formal grammar to analyze the grammatical relationships in nlp using dependencies between words to form the structure of the sentence.