Learning without Supervision in NLP
Overview
When we transfer the knowledge gained by an NLP model to another model, it is known as transfer learning. On the other hand, in self-supervised learning, we train the model using both the input and output labels. Furthermore, we provide the output labels as part of the input label; thus, there is no need for a separate output label. We use self-supervised learning with transfer learning in natural language processing to create more advanced NLP models. For example, if we do not have a pre-trained model, we can train our first model with a data set (a text corpus) and then use the newly trained model to train other models via transfer learning.
Pre-Requisites
Before learning about the topic- learning without supervision in NLP, let us learn some basics about NLP.
- NLP stands for Natural Language Processing. In NLP, we analyze and synthesize the input, and the trained NLP model then predicts the necessary output.
- NLP is the backbone of technologies like Artificial Intelligence and Deep Learning.
- In basic terms, NLP is nothing but the computer program's ability to process and understand the provided human language.
- The NLP process first converts our input text into a series of tokens (called the Doc object) and then performs several operations of the Doc object.
- A typical NLP processing process consists of stages like tokenizer, tagger, lemmatizer, parser, and entity recognizer. In every stage, the input is the Doc object, and the output is the processed Doc.
- Every stage makes some respective change to the Doc object and feeds it to the subsequent stage of the process.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Introduction
Since the world is getting faster day by day and many new technologies are coming into the picture, the need for organizations and technologies to mirror human intelligence and language is also increasing. Humans can understand any concept or task with the help of some examples, but natural language processing models cannot learn y such techniques. So, to train the models, we use the learning techniques like transfer learning, Supervised learning, semi-supervised learning, unsupervised learning, and reinforcement learning etc. In this article, we will learn about transfer and semi-supervised learning in detail.
Transfer Learning
When we transfer the knowledge gained by an NLP model (in learning one task) to another model, it is known as transfer learning. Since these models are already trained, We can do small modifications and apply these models to perform similar tasks. Some examples of pre-trained models used in the transfer learning process are Resnet50, EfficientNet, etc. The models are usually trained by many images and then fine-tuned on our provided data set, for example, the ImageNet dataset.
For more clarity on the transfer learning process, let us take the example of a model that does image classification. Suppose we want to classify Dogs and Cats out of the input images, i.e., a data set of pets. We can use the ResNet50 pre-trained model to classify our images as it has been trained using Imagenet data set with more than 1000 classes. It is an example of image classification that we do in the field of Machine Learning, Artificial Intelligence, and Natural Language Processing.
Now a question that may come to our mind is what is the basic benefit of using this transfer learning as we other types of learning as well? In transfer learning, we are not training our model from scratch, so our entire training span is excluded, and we only use a pre-trained model for the output prediction. In some cases, we can directly use the pre-trained model; in other cases, we only need to fine-tune the model according to our use cases. So, one of the most useful features of transfer learning is that it is fast.
Please refer to the image provided below to get a better understanding of the transfer learning process.
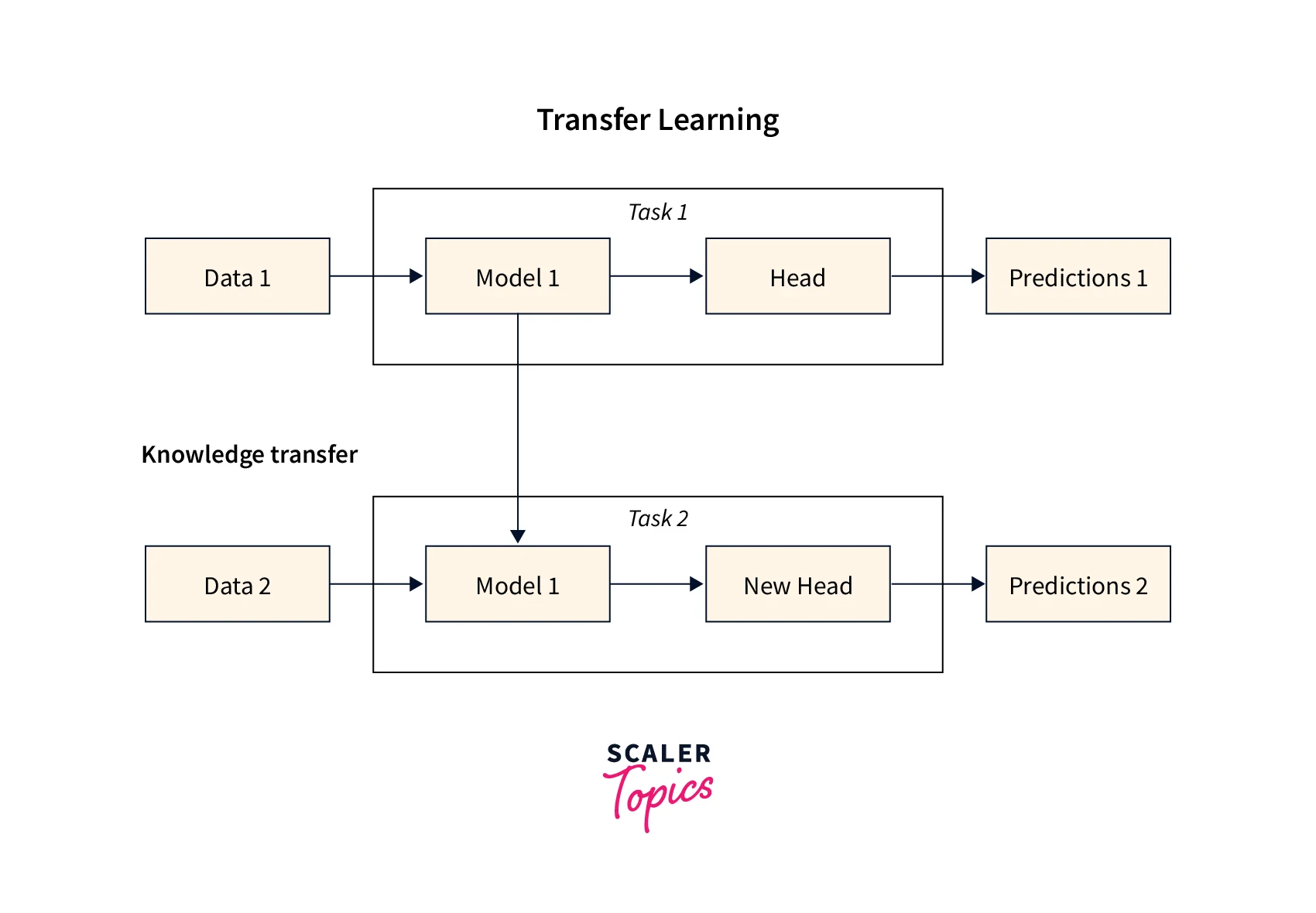
So far, we have discussed the benefits and use cases; let us now see one of the drawbacks of transfer learning. Suppose we want to use a model for some job, and we do not have any previously trained model for the same job; in that case, we cannot use the concept of transfer learning.
Now, in these scenarios, we use the concept of self-supervised learning. In the next section, let us learn about the concept of self-supervised learning in detail.
Self-Supervised Learning
In training a model, we generally provide the input and output data sets. Using these data sets, the model leans to map the input to the output, and ultimately it learns to predict the output using the training provided.
Now, in self-supervised learning, we train the model using both the input and output labels. We provide the output labels as part of the input label; thus, a separate output label is unnecessary. So, self-supervised learning is also known as pretext learning or predictive learning. We are changing the unsupervised learning problem into a supervised learning problem with the help of auto-generated labels.
One of the most common examples of self-supervised learning is learning a language model. The language model learns to predict the output word sequence using the previously provided input sentence. As we provide a complete sentence, the model can easily predict the next word of the sentence; hence, we do not need to provide a separate output label. We can use this data set to fine-tune a trained model for our generic purpose.
We use self-supervised learning with transfer learning in natural language processing to create more advanced NLP models. For example, if we do not have a pre-trained model, we can train our first model with a data set (a text corpus) and then use the newly trained model to train other models via transfer learning. It can easily recognize the pattern and hence learns the basics of matching inputs to outputs.
Apart from self-supervised learning, we have various other types of learning techniques. They are as follows:
- Supervised Learning.
- Semi-supervised Learning.
- Unsupervised Learning.
- Reinforcement Learning.
Let us take an example of self-supervised learning. For our example implementation, we will use a dataset of pairs of English sentences and their French translation, which you can download from manythings.org/anki. The file to download is called fra-eng.zip. We will implement a character-level sequence-to-sequence model, processing the input character-by-character and generating the output character-by-character. Another option would be a word-level model, which tends to be more common for machine translation. At the end of this post, you will find some notes about turning our model into a word-level model using Embedding layers.
-
Turn the sentences into 3 Numpy arrays, encoder_input_data, decoder_input_data, decoder_target_data:
- encoder_input_data is a 3D array of shape - (num_pairs, max_english_sentence_length, num_english_characters) containing a one-hot vectorization of the English sentences.
- decoder_input_data is a 3D array of shape (num_pairs, max_french_sentence_length, num_french_characters) containg a one-hot vectorization of the French sentences.
- decoder_target_data is the same as decoder_input_data but offset by one timestep. decoder_target_data[:, t, :] will be the same as decoder_input_data[:, t + 1, :].
-
Train a basic LSTM-based Seq2Seq model to predict decoder_target_data given encoder_input_data and decoder_input_data. Our model uses teacher forcing.
-
Decode some sentences to check that the model is working (i.e. turn samples from encoder_input_data into corresponding samples from decoder_target_data). Because the training and inference processes (decoding sentences) are quite different, we use different models for both, albeit they all leverage the same inner layers.
This is our training model. It leverages three key features of Keras RNNs:
The return_stateconstructor argument, configures an RNN layer to return a list where the first entry is the outputs and the next entries are the internal RNN states. This is used to recover the states of the encoder. The inital_state call argument, specifies the initial state(s) of an RNN. This is used to pass the encoder states to the decoder as initial states. The return_sequences constructor argument, configures an RNN to return its full sequence of outputs (instead of just the last output, which is the defaults behavior). This is used in the decoder.
Code:
We train our model in two lines while monitoring the loss on a held-out set of 20% of the samples.
Output:
Turn Learning into Career Growth
Why was Self-Supervised Learning Introduced?
So far, we have discussed self-supervised learning and its advantages. Let us now see why self-supervised learning was introduced when we had other types of learning techniques available.
Some of the most important reasons for the introduction of self-supervised learning are as follows:
- High Cost: We know that for training a new model, we need to use a huge set of high-quality pf labelled data sets, which requires a high cost to gather such data sets. It is also a time-consuming and tedious job.
- Generic Artificial Intelligence: Self-supervised learning is also related to artificial intelligence as we use human cognition with the machines closely in self-supervised learning.
- Lengthy lifecycle: The time required to prepare data is quite important in the model learning process, and this data preparation phase requires a lot of time. Hence, it is a lengthy process. In the data preparation phase, we go through several phases:
- filtration of data,
- annotation of data,
- reviewing annotated data,
- cleaning of data, and
- restructuring the final data before putting it into the model.
Some other reasons for introducing self-supervised learning are the flexibility and integrity of data maintained by the self-supervised learning process.
Applications of Self-Supervised Learning
Let us now learn about the various applications of the self-supervised learning technique. SSL or self-supervised learning is used in the fields like text suggestion, sentence completion, application documentation processing, etc. The self-supervised learning is one of the most widely used learning techniques in natural language processing.
BERT or Bidirectional Encoder Representations from Transformers also use self-supervised learning. For example, BERT is a bi-directional learning algorithm Google developed in 2018. BERT learns to predict the text that might come before or after the other text. The main aim of the development of the BERT was to improve the contextual understanding of the unlabeled text. BERT uses a transformer to learn the contextual relations between a text's provided words or sub-words. BERT models are pre-trained with large volumes of data that help it to understand the relationship better.
Next Sentence Prediction
We have previously discussed the concept of next-word prediction, and the next-sentence prediction is an extension. In the next sentence prediction, first, we pick two concurrent sentences from a set of sentences (present in the form of a document). After that, we pick one unsupervised sentence from the document (the document can be the same or different). After picking up those three sentences, we provide them to the self-supervised learning model. We also provide the relative positions of the sentences (for example, the position of sentence 1 concerning sentence 2, etc.). Using these inputs, the model will predict whether the sentence is the next (IsNotNextSentence or IsNextSentence).
Auto-Regressive Language Modeling
We use auto-encoding models like BERT from transformers and self-supervised learning techniques to perform functions like sentence classification. GPT, or Generative Pre-trained Transformers, is an example of an auto-regressive language model that works on the modelling task of vintage languages. After reading the preceding words, we can use the model to forecast or predict the next work.
For performing such tasks, the GPT and other models respond to the decoder part of the mask and the transformer at the top to complete the sentence.
Supervised Fine-tuning
To understand the concept of fine-tuning, let us take a scenario. Suppose we have a labelled data set C and every instance of C data set contains an input token set (i.e., x1, . . . . . , xm) along with a label y.
Now, we will pass the input through the pre-trained model to obtain the final block of the transformer parameters (represented by Wy).
Please refer to the image provided below for the formula.

We want to fine-tune the model for the auxiliary purpose. In that case, it will help to understand that improving the generality of the supervised learning model and increasing the convergence proves to be the best choice.
We use an extra variable, i.e., Wy for fine-tuning.
Conclusion
- Transferring the knowledge gained by an NLP model (in learning one task) to another model is known as transfer learning. Since these models are already trained, we can do small modifications and apply these models to perform similar tasks.
- In transfer learning, we are not training our model from scratch, so our entire training span is excluded, and we only use a pre-trained model for the output prediction.
- In the case of self-supervised learning, we train the model using both the input and output labels. We provide the output labels as part of the input label; thus, a separate output label is unnecessary.
- In natural language processing, we use self-supervised learning with transfer learning to create more advanced NLP models.
- The SSL or self-supervised learning is used in the fields like text suggestion, sentence completion, application documentation processing, etc.
- BERT or Bidirectional Encoder Representations from Transformers also uses self-supervised learning. BERT is a bi-directional learning algorithm that Google developed in the year 2018.