Exploring Longformer
Overview
In this blog, we will dive into the world of Longformer, a new and exciting development in language processing. We'll explore how it addresses the challenge of efficiently understanding long pieces of text. Traditional methods struggle with longer texts due to their complexity, but Longformer's innovative global attention approach changes the game. We'll look at why global attention is important, how it works, and its benefits.
Introduction
In the world of natural language processing (NLP), attention mechanisms have played a pivotal role in enabling models to understand the context and relationships within text data. Traditional self-attention mechanisms, while powerful, come with significant computational demands, often making them inefficient for processing long documents. This is where the Longformer comes into the picture, offering a groundbreaking solution to this challenge.
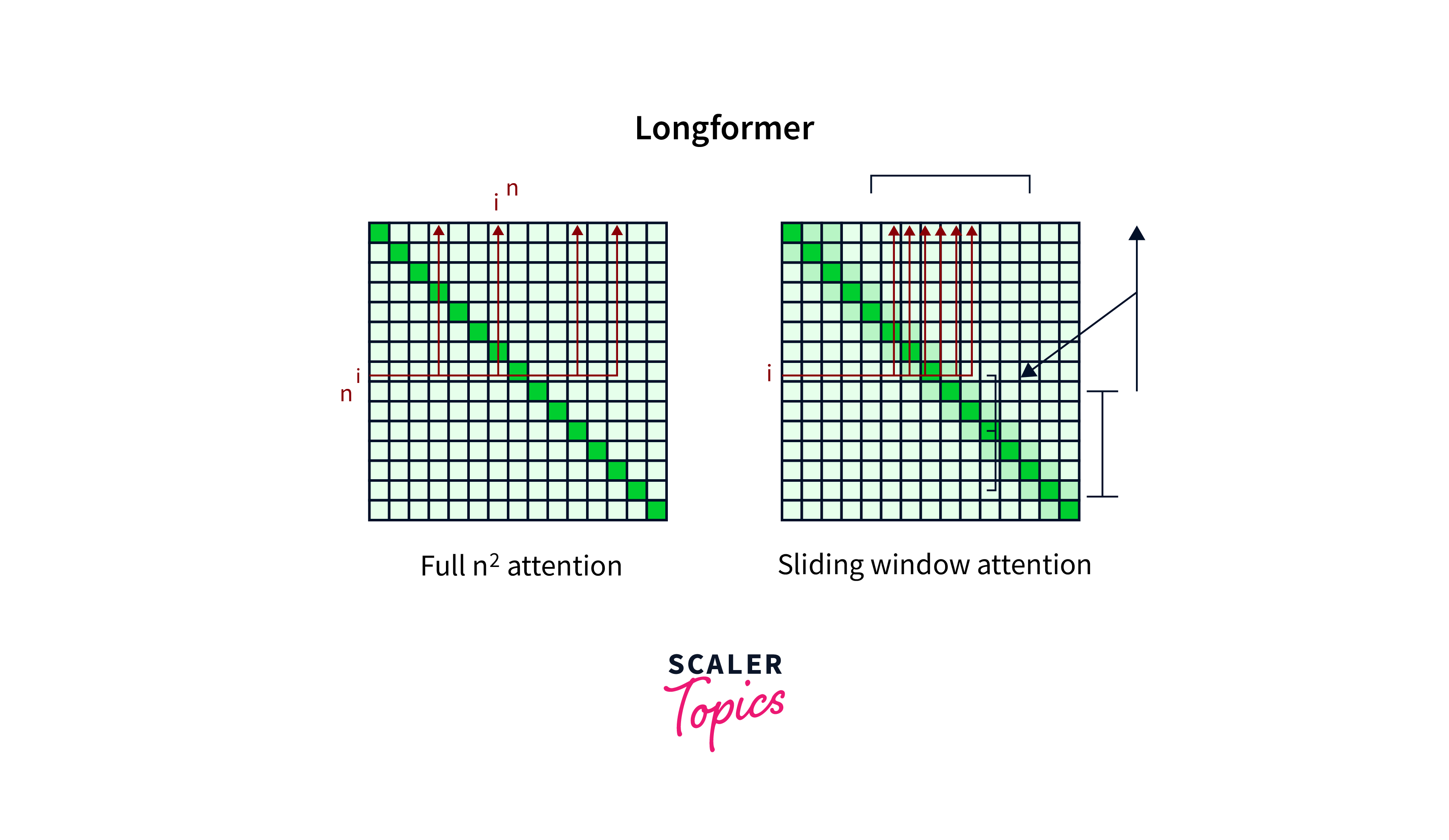
What is Longformer's Global Attention?
Longformer's Global Attention is an innovative mechanism designed to enhance text processing, particularly for longer sequences. Traditional self-attention mechanisms, like those seen in Transformer models, become computationally burdensome as sequence length increases. Longformer addresses this issue by introducing a sparse attention pattern. This means that instead of considering every token equally, it focuses on specific tokens within a fixed window around each token. This approach is crucial for efficiently understanding lengthy documents.
The need for Global Attention arises from the limitations of self-attention mechanisms. While self-attention is powerful for capturing relationships between tokens, its quadratic complexity impedes its performance with long texts. Longformer's approach reduces computation by attending to relevant tokens only, maintaining efficiency without compromising context understanding.
However, Longformer has its limitations. The fixed-window strategy might not capture long-range dependencies essential for certain tasks. Achieving the right balance between capturing distant relationships and computational efficiency remains a challenge. Nevertheless, Longformer's Global Attention stands as a significant step toward effective and efficient text processing in the realm of natural language understanding.
Longformer Architecture and Modifications
The Longformer architecture is a modified Transformer-based model optimized for long sequence processing. It employs two key modifications: Global Attention and Local Sliding Window Attention.
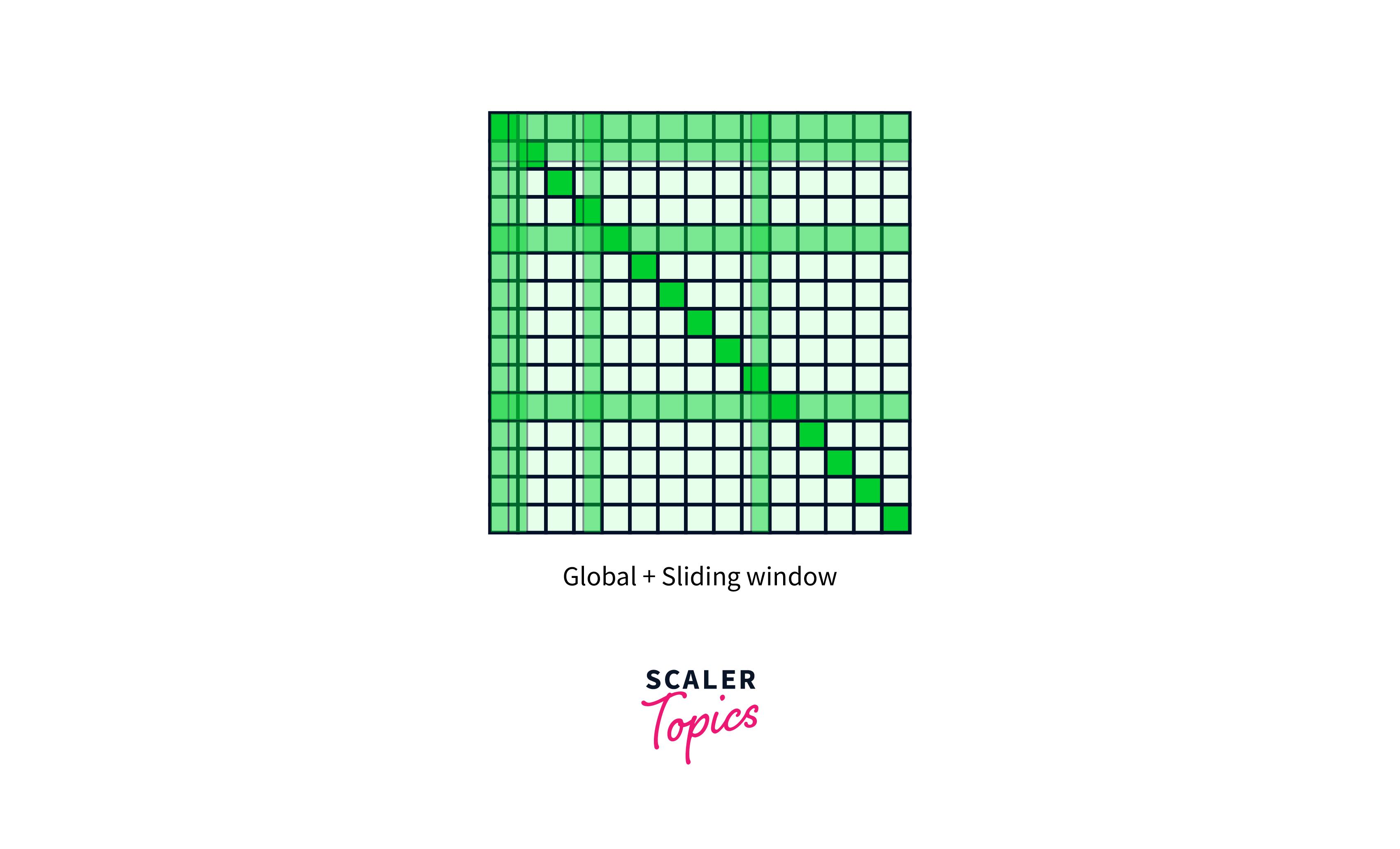
Global Attention in Longformer
Global Attention allows Longformer to attend to a subset of tokens within a fixed window around each token. This means that instead of performing attention computations on the entire sequence, Longformer narrows its focus to the most relevant parts of the text. By doing so, it achieves a remarkable balance between accuracy and efficiency, making it feasible to process documents with hundreds or even thousands of tokens without overwhelming computational demands.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Local Sliding Window Attention
Complementing the Global Attention, Longformer employs the Local Sliding Window Attention mechanism. This mechanism enables the model to capture both local and long-range dependencies within a sequence. By sliding a window across the tokens, Longformer can capture context at varying distances from each token. This allows the model to consider not only the nearby context but also connections that extend further away, enriching its understanding of the text.
The Local Sliding Window Attention adds a dynamic element to Longformer's architecture, facilitating the capture of intricate relationships between tokens.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Implementing Longformer's Sparse Attention Mechanism
Implementing Longformer's sparse attention mechanism involves a streamlined process. These steps include:
- Step 1.
Imports - Step 2.
Importing pre-trained longformer model - Step 3.
Setup longformer attention - Step 4.
Making Inference and output
Step 1: Imports
We'll start by importing the required libraries and modules.
Step 2: Import a pre-trained Longformer Model
Begin by selecting a pre-trained Longformer model from a library like Hugging Face Transformers. Longformer models are pre-trained on large text corpora and fine-tuned for specific downstream tasks.
- This line creates a Longformer configuration. It loads the pre-trained configuration for the 'allenai/longformer-base-4096' model.
- num_labels=2 specifies that the model will be used for a binary classification task with two output classes.
- This line creates a Longformer model for sequence classification using the configuration defined earlier.
- It loads the pre-trained weights for the 'allenai/longformer-base-4096' model and configures it for sequence classification.
Step 3: Setup Longformer attention mechanism
Sparse attention can be customized to your specific needs. Longformer models provide flexibility in defining attention patterns, such as enabling global attention for certain tokens or setting custom attention windows.
- These lines demonstrate how to set the attention patterns for sparse attention.
- model.config.attention_mode = "global" specifies that you want to use global attention, which means some tokens attend to all other tokens.
- model.config.global_attention_pattern is set to enable global attention for the first token (CLS token) and disable it for the rest. This means that the CLS token attends to all tokens, while other tokens do not have global attention.
Step 4: Inference
Now, we can use our model to make inferences to input tensors:
- These lines demonstrate how to use the Longformer model for sequence classification.
- You provide your input sequences as input_ids, and labels as labels.
- The model processes the input and returns outputs, which include logits (raw scores) for each class.
- This line retrieves the logits (raw scores) for each class from the outputs variable.
- These logits can be used to make predictions or compute loss for training.
Step 5: Output
The logits variable now contains a tensor with the raw scores or logits for each class in the classification task. The number of logits will be equal to the number of classes specified in the num_labels parameter when creating the model's configuration (LongformerConfig).
If you have a binary classification task (two classes), you can access the logits for each class as follows:
If you have a multi-class classification task with more than two classes, you would access the logits for each class accordingly.
Typically, you would then apply a softmax function to the logits to convert them into probabilities and make predictions based on the class with the highest probability. Here's an example of how you might do that:
The predicted_class variable will contain the predicted class label for the input sequence based on the highest probability. This is a common approach for making predictions in classification tasks using the output logits of a model.
Turn Learning into Career Growth
Challenges in Traditional Transformers for Long Inputs
Before the advent of LongFormer and even today, a common approach for handling lengthy documents is the chunking approach. This method involves dividing a lengthy document into smaller 512-token chunks, often with an overlapping window, and processing each chunk separately. While this approach serves as a useful workaround for handling long documents within the constraints of model architecture, it does come with certain limitations. One significant drawback is the potential loss of information due to truncation or cascade errors, which becomes particularly problematic when performing tasks such as Named Entity Recognition (NER) or Span Extraction, where having the entire context is crucial for accurately labeling and understanding the content.
In addition to the chunking approach, researchers have explored task-specific solutions, one of which is sparse attention. Sparse attention patterns define a particular type of attention mechanism that doesn't require computing the entire quadratic attention matrix multiplication, making it more efficient for handling lengthy documents. LongFormer, in particular, stands out as a state-of-the-art solution that leverages these advancements to excel in processing lengthy documents effectively.
Key Pointers:
- Chunking approach:
Divides lengthy documents into 512-token chunks, but may lead to information loss due to truncation or cascade errors, especially in NER and Span Extraction tasks. - Sparse attention:
Offers an efficient attention mechanism that doesn't require computing the entire attention matrix, improving performance for handling lengthy documents. - LongFormer:
Represents a cutting-edge solution that utilizes sparse attention and other innovations to achieve state-of-the-art results in processing lengthy documents
Handling Long Sequences with Longformer
LongFormer suggests a sparsified version of self-attention, in which the entire self-attention matrix is divided into smaller chunks in accordance with a "attention pattern" that designates pairings of input sites that are paying attention to one another. The proposed attention pattern scales linearly with the input sequence, unlike the complete self-attention, making it effective for longer sequences. Let's examine the Attention Pattern's elements.
Sliding Window Attention
The model can examine all the tokens in the input sentence with a fully developed Self-Attention, but it is computationally complex.
Longformer suggests fixed-size window attention surrounding each token in an effort to lessen computational complexity without sacrificing local context. either token attends to 1/2w tokens on either side given a fixed window size of w.
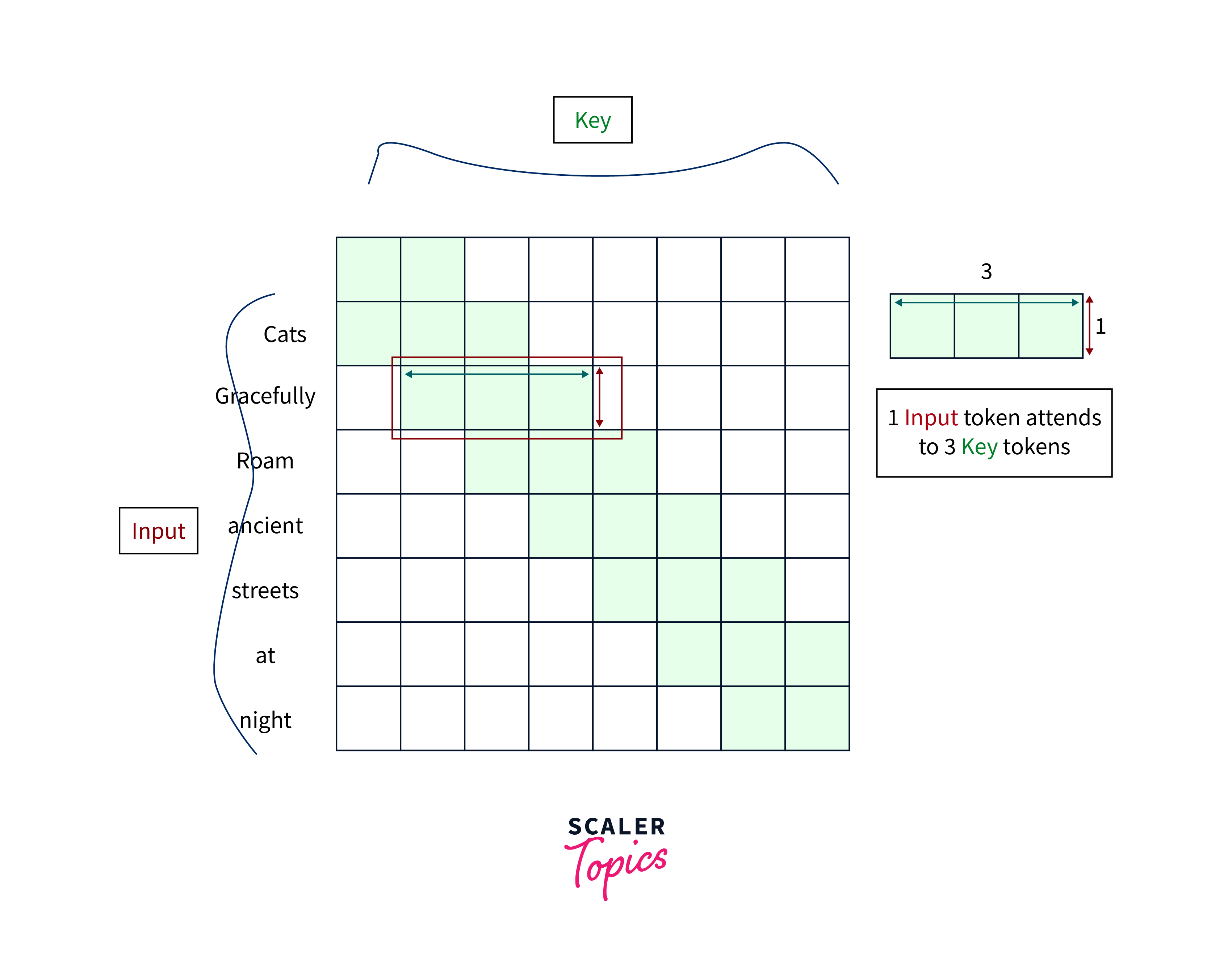
Using multiple stacked layers of such windowed attention results in a large receptive field, where top layers have access to all input locations and can construct representations that incorporate information across the entire input, similar to CNN's (see figure below), because there are n encoder layers stacked on top of each other in a typical Transformer-Base Network.
Since the topmost layers can functionally look at LXW tokens, even though any token in the first layer can only see w/2 tokens on both sides at once, a simple example of this is provided below.
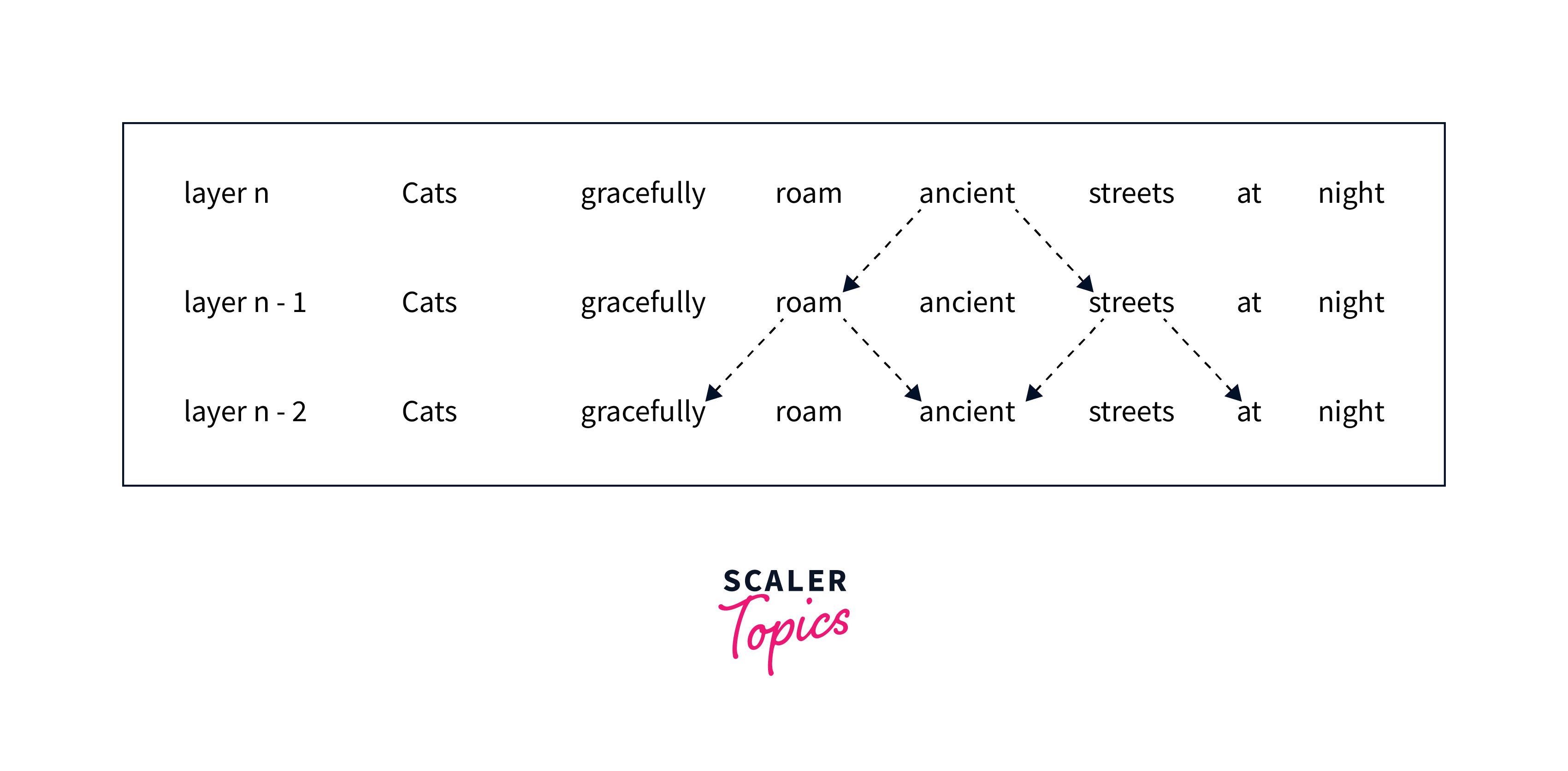
This pattern has O(n w) complexity, scaling linearly with input length. It offers a broad receptive field in top layers. Based on the problem and resources, attention width can be adjusted for more context.
Dilated Sliding Window Attention
The sliding window can be "dilated" to further expand the receptive field without adding computation. The window in this case has gaps of size dilatation d, similar to dilated CNNs. The number of tokens the model can view at once can be increased by using window attention with dilation d, which entails attending to words with a difference of d within a window of w+d. The receptive field is Ldw, which can approach tens of thousands of tokens even for modest values of d, assuming fixed d and w for all layers.
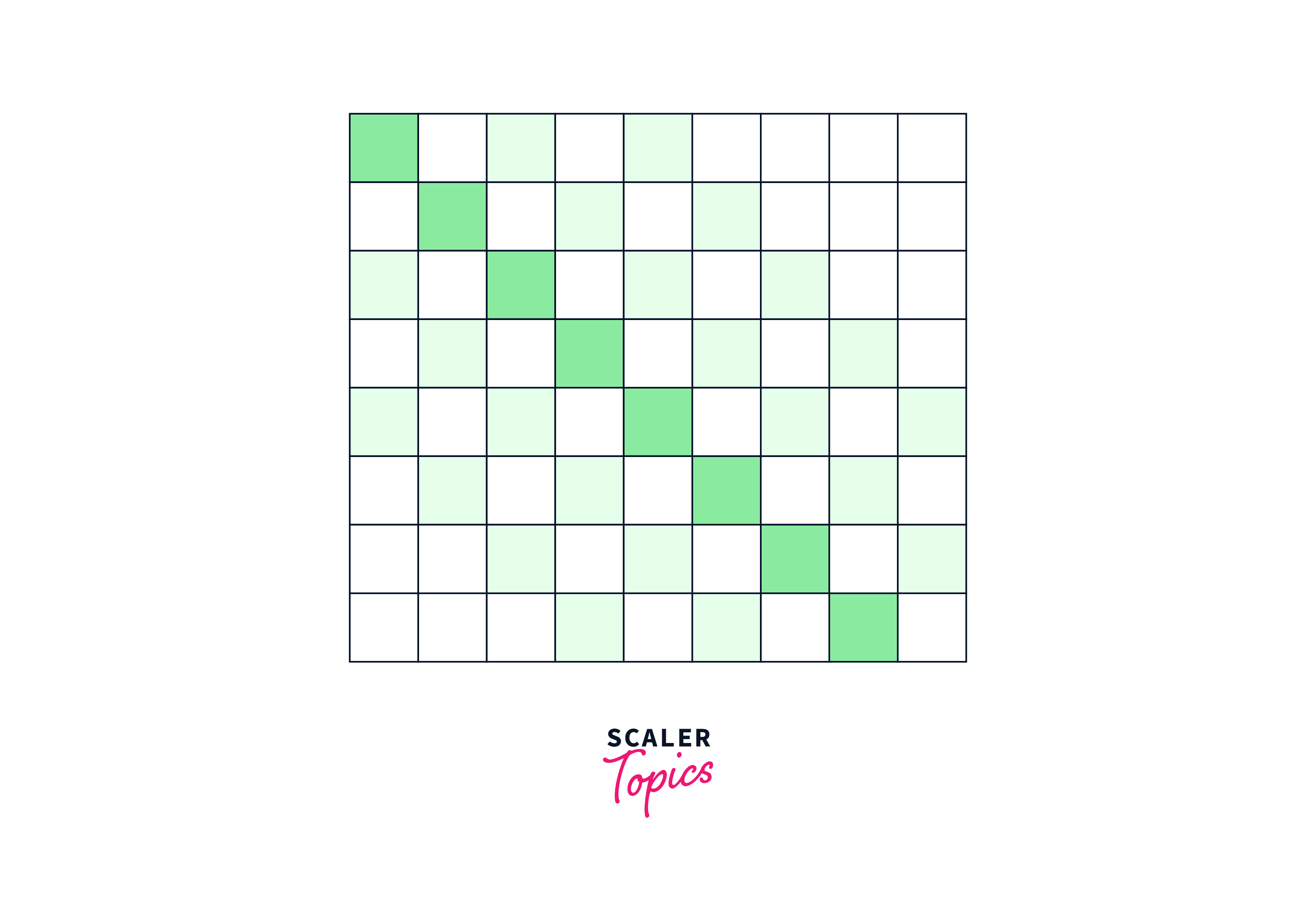
Global Attention
Windowed attention overcomes the complexity issue and retains local context, but it is still unable to adapt to learning task-specific representations. As a result, Longformer enables a small number of tokens to attend worldwide in a symmetrical manner, whereby a token with global attention attends to all tokens throughout the sequence and is attended to by all other tokens in the sequence.
Global attention is utilized, for instance, in categorization for the [CLS] token, whereas in quality assurance for all question tokens. Although specifying global attention is task-specific, it provides a simple technique to give the model's attention inductive bias.
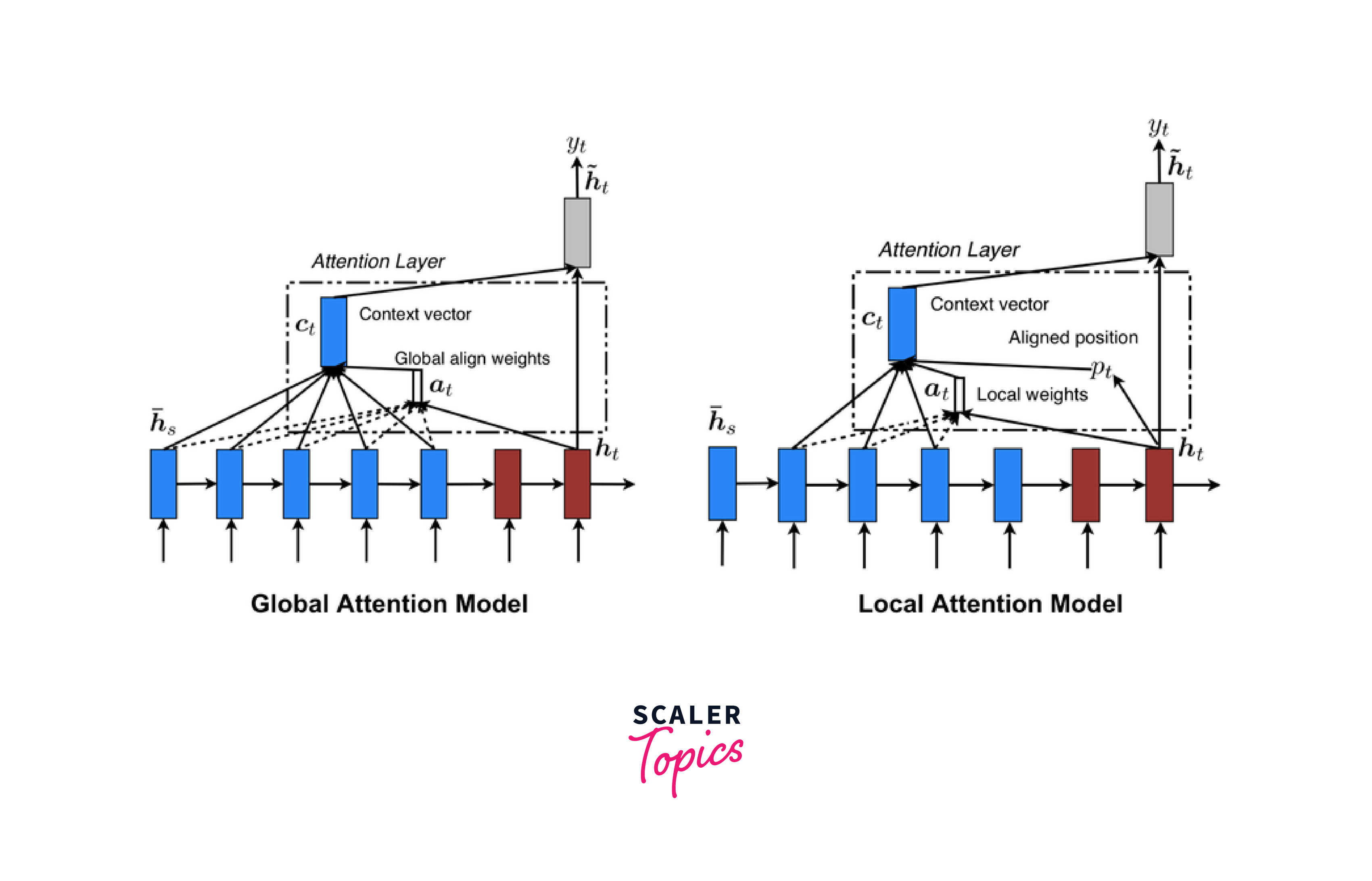
LongFormer Attention
We shall examine its implementation now that we have a solid understanding of all of LongFormer Attention's components and its pattern. The following is how the transformer model calculates attention scores:
In order to calculate the attention scores for sliding window attention and global attention, respectively, Longformer employs two sets of projections: Qs, Ks, and Vs and Qg, Kg, and Vg. For best performance on subsequent tasks, the additional projections give flexibility to simulate the various types of attention. Because both Q and K have projections with n (sequence length), the matrix multiplication QKT in Equation (1) is the expensive operation. Only a predetermined number of the QKT diagonals are computed for Longformer by the dilated sliding window attention. As a result, memory consumption increases linearly as opposed to quadratically when full self-attention is used.
Applications of Longformer in NLP Tasks
Longformer's unique attention mechanism has paved the way for its application in various natural language processing (NLP) tasks. Let's explore some key applications and their significance
- Long Document Understanding and Summarization
Long documents pose a challenge for traditional models due to computational complexities. Longformer excels in this domain by efficiently processing extensive documents while preserving context. It enhances document summarization by extracting essential information for creating concise summaries. Longformer's ability to handle lengthy texts enables more accurate and coherent document understanding and summarization. - Contextual Embeddings for Large Text Corpora:
Generating contextual embeddings for large text corpora requires considerable computational resources. Longformer addresses this challenge by offering an efficient way to process extensive texts. This makes it valuable for applications like sentiment analysis, topic modeling, and clustering, where the quality of contextual embeddings plays a crucial role in accurate analysis. - Multi-task Learning with Longformer:
Longformer's ability to process long sequences efficiently lends itself well to multi-task learning scenarios. In multi-task learning, models are trained to perform multiple related tasks simultaneously. Longformer's attention mechanism allows it to process varying input lengths efficiently, enabling models to handle different tasks that involve long texts. - Question Answering and Document Retrieval:
Longformer's proficiency in understanding lengthy documents makes it ideal for question answering and document retrieval tasks. In question answering, the model can extract answers from extensive texts, and in document retrieval, it can efficiently match queries with relevant documents. Its global attention mechanism enables it to capture both local and long-range dependencies, contributing to accurate and comprehensive results. - Named Entity Recognition in Long Texts:
Named Entity Recognition (NER) involves identifying and classifying entities like names, dates, and locations in text. Long documents often contain numerous entities that need to be recognized accurately. Longformer's efficiency in processing extensive texts benefits NER tasks by handling the complexity of long documents while preserving the context necessary for accurate entity recognition.
Longformer's advantages extend to other tasks such as sentiment analysis, topic modeling, and language generation. Its unique attention mechanism addresses challenges associated with long texts, enhancing the accuracy, efficiency, and scalability of various NLP applications.
Evaluating Longformer's Performance
Evaluating the performance of the Longformer model, or any NLP (Natural Language Processing) model for that matter, involves several key steps and considerations.
Here's how you can go about evaluating its performance:
To evaluate the Longformer's performance:
Quantitative Metrics:
- Measure accuracy, precision, recall, and F1-score on tasks.
- Compare token processing speed and inference time.
- Plot F1-score/accuracy against varying document lengths.
Qualitative Analysis:
- Analyze outputs of representative long documents.
- Visualize attention patterns to assess context capture.
- Compare predictions with baseline models.
Domain-Specific:
- Tailor evaluation to task relevance.
- Use diverse datasets with varied document lengths.
- Check attention patterns' interpretability.
Compare with other models for context and uniqueness. Adapt methods based on your use case and goals.
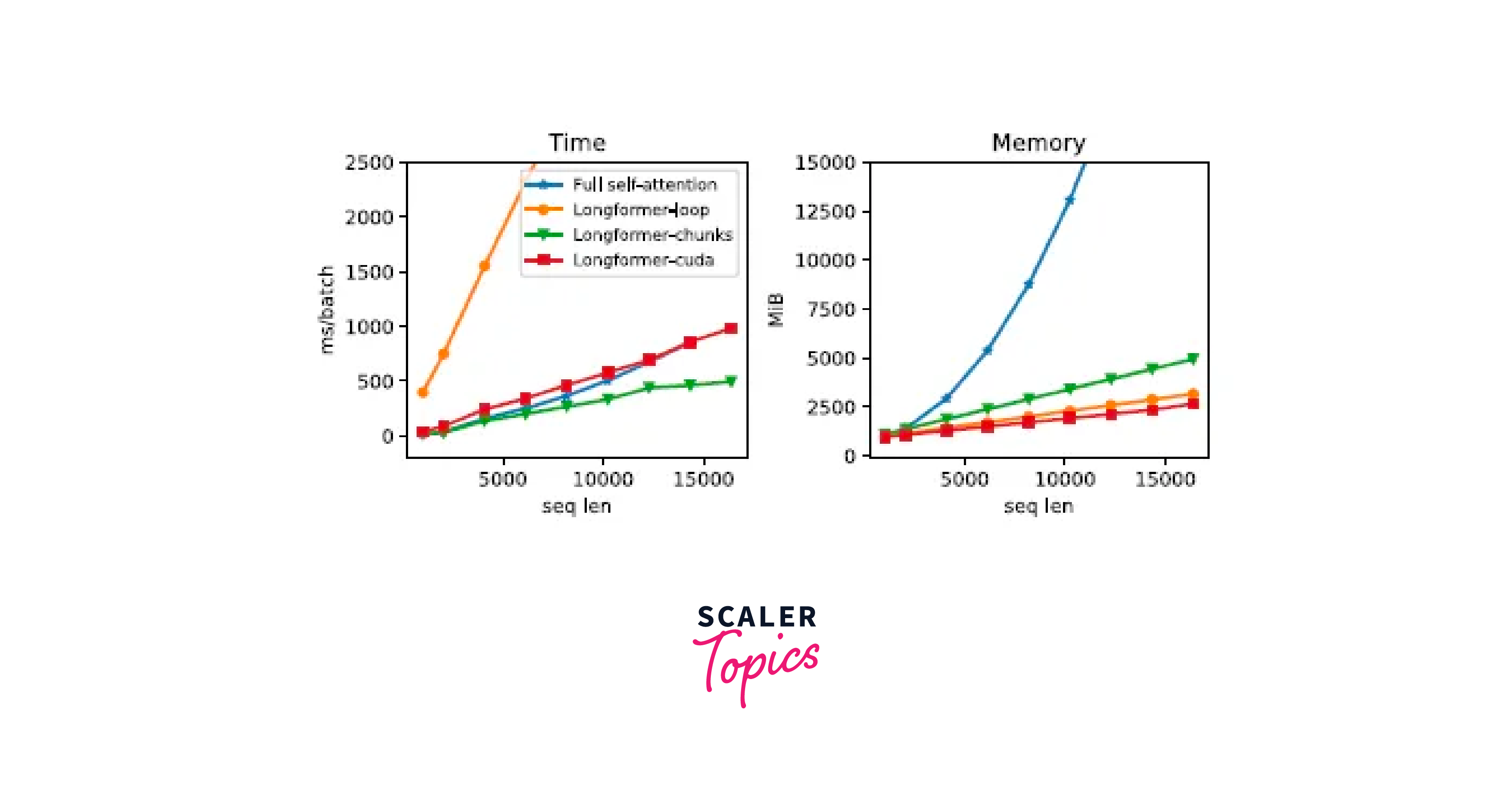
Longformer Variants and Model Sizes
It's important to choose a Longformer variant based on the specific needs of your task and available resources. Larger variants generally offer better context understanding but come with increased computational demands.
Let's discuss few Longformer variants, including their architectures, along with their pros and cons:
1. Longformer-base:
- Architecture:
The base variant of Longformer retains the transformer architecture but introduces global attention patterns that allow it to efficiently handle long documents. - Pros:
- Efficient processing of long documents due to global attention mechanism.
- Suitable for tasks requiring context beyond local windows.
- Generally requires fewer computational resources compared to larger variants.
- Cons:
- Limited context compared to larger variants.
- Might not perform as well on extremely long documents.
2. Longformer-large:
- Architecture:
Longformer-large is an extended version with a larger model size, allowing it to capture even more global context. - Pros:
- Improved context capture due to larger model size.
- Better performance on tasks demanding extensive context understanding.
- Can handle even longer documents effectively.
- Cons:
- Higher computational and memory requirements.
- Longer training times and potentially slower inference.
3. Longformer with Hierarchical Structure:
- Architecture:
This variant combines Longformer's global attention with a hierarchical structure, allowing it to process both local and global information more effectively. - Pros:
- Balanced approach for capturing both local and global context.
- Potential to excel in tasks with varying context scales.
- Improved efficiency compared to a fully global attention model.
- Cons:
- Requires careful design to balance local and global attention.
4. Longformer with Sparse Attention Patterns:
- Architecture:
This variant further optimizes Longformer's attention patterns using sparse attention mechanisms, which can lead to more efficient computation. - Pros:
- Enhanced computational efficiency, especially for long documents.
- Reduced memory footprint due to sparsity.
- Can be used in conjunction with other Longformer variants.
- Cons:
- Complex implementation due to sparse attention patterns.
- May require tuning to balance efficiency and performance.
5. Longformer with Task-Specific Modifications:
- Architecture:
Modifying Longformer's architecture to suit specific tasks, such as document classification or summarization. - Pros:
- Customization for particular tasks can lead to improved performance.
- Can leverage Longformer's context handling for task-specific benefits.
- Cons:
- Requires task-specific expertise and experimentation.
- Might not generalize well across different tasks.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Conclusion
- Longformer efficiently handles long texts, reducing computational demands and making it practical for real-world applications.
- By capturing both local and long-range dependencies, Longformer enhances contextual understanding, leading to improved performance in tasks such as summarization and sentiment analysis.
- Longformer's benefits extend across various NLP tasks, including document understanding, multi-task learning, and content generation.
- It strikes a balance between efficiency gains and task-specific performance, addressing the challenges posed by lengthy texts without sacrificing quality.