Masked Language Modeling in BERT
Overview
Language modeling is a massive domain and has many sub-research areas. One such domain involves understanding contextual information about words in a sentence. We can perform this modeling task in many ways, and the masked language model explained it is one such method. In the past few years, Transformer based models have reached SOTA(state of the art) in many NLP domains. BERT is one such model. In this article, we will understand how to train BERT to fill in missing words in a sentence using MLM.
What is Masked Language Modelling?
To a NN model, the word context has no meaning. So, we need to find ways to make the model consider surrounding words to learn which context words appear. This method indirectly teaches a model to look at the word in question and other words.
For example, consider the sentence. I am eating an ice cream.

In the above picture, the words in bold are the current words that we will be masking, and the words in
In this sentence, the ice cream is being eaten. What would an appropriate word be if we now remove the word eating and have the sentence as "I am ___ an ice cream"?
To fill in the blanks, we can consider words like licking, eating, sharing, etc. However, we cannot say drowning, cycle, chair, or other random words.
In the same way, to ensure the model learns which word is appropriate, it needs to understand the structure of language. As modelers, we need to help it do so. Quite simply, all we do is give the model inputs with blanks as a "token" <MASK> along with the word that should be there. We can create data in this format by taking any text and running over it. How to do so will be explained later on.
How is MLM Different From CLM?
The major difference between MLM andCLMis that CLM can only take into account words that occur before it in a sentence, unlike MLM, which is bi-directional. This difference means that CLM does better for generating large amounts of text. However, MLM is better for contextually understanding text (refer to the Masked Language Model Explained section). The bi-directionality of MLM might make it biased, as looking both ways in a sentence can lead MLM to stop being as creative as possible. The uni-directional CLM, on the other hand, excels at being creative.
These differences are summarized in the following table.
| CLM | MLM |
|---|---|
| Takes words occurring before it into account. | Takes words occurring before and after it into account. |
| Uni-Directional. | Bi-Directional. |
| Better for text generation. | Better for contextual understanding. |
| Good for creative uses. | Limits and biases model by providing it bi-directional text. |
How is MLM Different From Word2Vec?
MLM (Masked Language Modeling) and Word2Vec are two different approaches to natural language processing (NLP).
MLM is a language model trained to predict the missing words in a sentence based on the context provided by the surrounding words. This is done by masking some of the words in the input text and training the model to predict the masked words based on the context of the non-masked words. MLM is often used in tasks such as language translation and summarization, where the model needs to understand the context and meaning of the words to generate the output text accurately.
Word2Vec, on the other hand, is a method for learning vector representations of words, where the vectors capture the semantics of the words and the relationships between them. Word2Vec uses a neural network to learn the vector representations of words based on their co-occurrence with other words in large amounts of text data. Word2Vec has been widely used in various NLP tasks, such as text classification, similarity, and information retrieval.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Implementation of MLM in Python.
We will use the Keras and Transformers libraries to implement the MLM model in Python. Before we start, we need to set up these libraries and import some other useful packages.
Requirements
Before starting, the following libraries must be installed using pip install <library>.
- Tensorflow/Keras TF is one of the major DL libraries in Python. We will be using it for training our model.
- Hugging Face Transformers This library is one of the recent developments in the open-source community that has a database of trained models and datasets that we can use in any codebase. They have thousands of tasks, making it extremely easy to get results fast. We will use their pre-trained BERT model.
- NLTK A text processing library that we will use to clean up our text before passing it to the model.
- Seaborn and Matplotlib These libraries are used for plotting our training performance.
Imports
We first import all the required packages. We also download the stopwords and punctuation data from nltk.
Loading And Labeling The Data
For this demo, we use text from the book "Emma" by "Jane Austen". This dataset is a public domain dataset from Project Gutenberg that comes with nltk. We can download it using the following code.
We can also use custom text by creating a text file called "sample.txt" in the same directory as the code and pasting whatever we want. (Make sure it is English text).
Tokenization
We then pre-process the data by removing stopwords and punctuation and converting the words into tokens BERT needs. Since every Transformer model has their configuration of tokens in the pre-trained model, we will use the tokenizer that Hugging face provides us.
Note: Here, we only take the first 1000 lines from the text. Language models take a long time to train; this is just a demo. If we have GPUs, we can use real data.)
Turn Learning into Career Growth
Loading The Masked Language Model
We use the model from the Transformers library directly. The uncased model converts all text into lowercase. Other models do not, and we can use any of them. We chose this one for the sake of this demo.
Creating The Mask
The masked Language Model explained that every sentence needs to be converted to a format with words masked using a special token, <MASK>. We can do that by using the tokenized words and making the model aware of which token number corresponds to this special token. (In this case, it is 103). In the original paper, token numbers 101 and 102 were replaced, but we ignore that here. (It is not relevant for now.)
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Training the Model Using The Loss Function
Now that we have all the required data and the model, we need to train it on our data. If the system does not have a GPU or access to a cloud GPU is unavailable, this model will take a very long time to train. Consider using lesser data.
Considering we have a GPU, we first check if TF can find it.
We use a Sparse Categorical Crossentropy loss with logits enabled. (logits are enabled if the model does not end with a Softmax. BERT does not.). We use a learning rate of 1e-3 for the Adam Optimizer. Finally, we run training for around ten epochs.
Plotting the Loss
We plot the loss per epoch to see if our model is learning anything.
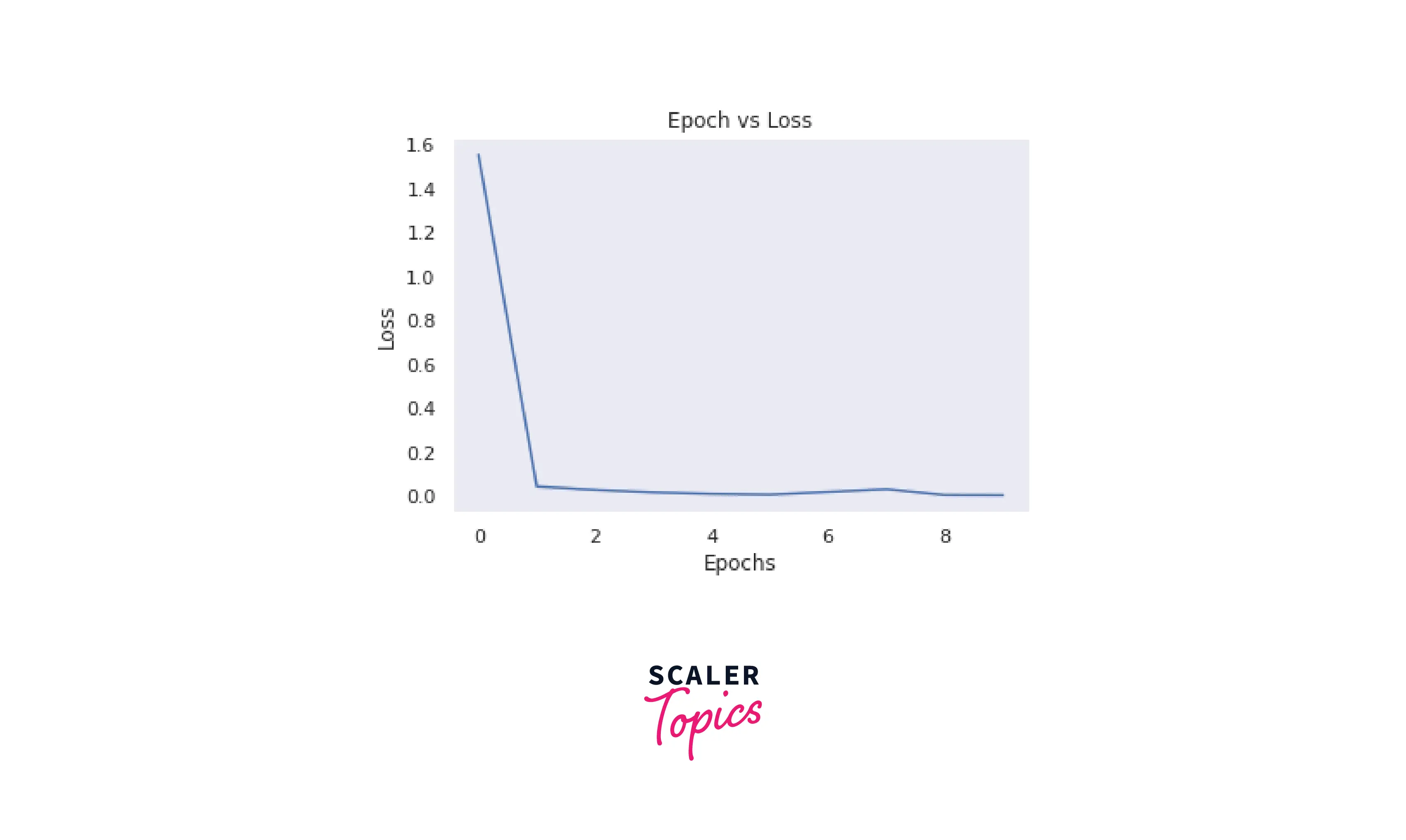
We can see that the loss has decreased, which is a good sign! Our model is learning. More data and longer training will help the model be better than before.
Prediction
Just training a model is useless. We need to be able to use it for Prediction. To do that, we need to define a few functions. We need to be able to find the <MASK> tokens in the sentence; we need to tokenize the sentence and pass it into the model for Prediction. And finally, we need to do this for multiple sentences. The following functions do exactly these.
Multiple Predictions
After training, we can finally give the model a practice exam! Since we fine-tuned it on the book "Emma", we give it the following sentences. ["too well [MASK] for her", "nice to [MASK] her", "Emma [MASK] a girl who wanted a [MASK]"]
As an output, we get the following. We see that it performs quite well even with such short training!
Optimizing the Implementation Further
- Language models are generally very heavy to use. If possible, using Mixed Precision training helps
- Having more GPU memory is more useful than having a faster GPU for language models
- Multiple GPUs are useful for expanding available memory
- There are smaller variants of BERT that use less memory.
- Hugging Face has a huge list of models that we can use. Trying them might lead to better results.
- To get over the overwhelming number of pre-trained models, pick the task and find benchmarks in that task. PaperswithCode is a great place to start.
Conclusion
This article showed us the masked language model explained. We learned the following:
- What MLM is and when to use it.
- How to pre-process our data for MLM
- How to fine-tune pre-trained BERT models for MLM
- How to perform predictions over multiple sentences with our fine-tuned models.