Models for IR in NLP
Overview
Information retrieval is the process of obtaining information that is relevant to an information need from a collection of resources. Information Retrieval models (IR models) provide a framework and system of resources for building IR models.
Information retrieval systems differ based on how documents and queries are represented and the methods of matching and arranging the output. Ir models are mainly classified into three groups of models - Boolean IR models, vector-space IR models, and probabilistic IR models.
Information Retrieval Model
Information retrieval is the branch of computer science that can help users find information usually in documents of an unstructured nature that satisfies an information need from within a large collection usually stored on the web or computers.
Information Retrieval Model: The Information Retrieval system needs to have components for the model representing the documents and query statements, and the characteristic matching function which evaluates the relevancy of the documents with respect to the provided user query.

Aspects of information retrieval model: The information retrieval model needs to provide the framework for the system to work and define the many aspects of the retrieval procedure of the retrieval engines
- The IR model has to provide a system for how the documents in the collection and user’s queries are transformed.
- The IR model also needs to ingrain the functionality for how the system identifies the relevancy of the documents based on the query provided by the user.
- The system in the information retrieval model also needs to incorporate the logic for ranking the retrieved documents based on the relevancy.
Types of Information Retrieval Models
Let us look at the two main types of information retrieval systems: The classical information retrieval model and the Non-classical information retrieval model.
Classical Information Retrieval Model
The classical IR systems are designed based on mathematical concepts and are the most widely used, simplest, and easy-to-implement systems for information retrieval models. In this system, the retrieval of information depends on documents containing the defined set of queries and there is no ranking or grading of any kind.
- Classic Information Retrieval models can be easily implemented and updated accordingly.
- The different classical IR models are based on mathematical knowledge that was easily recognized and understood as well and take concepts like Document Representation, Query representation, and Retrieval / Matching function into account in their modeling.
- The term classic in the name of classical IR systems denotes that they use foundational techniques for text documents without extra information about the structure or content of a document.
- Examples of classical Information Retrieval models: Are boolean models, Vector space models, and Probabilistic IR models.
Non-Classical Information Retrieval Model
Non-Classical Information Retrieval models are complete opposite to the classical IR models. They are based on principles other than similarity, probability, and Boolean operations.
- Non-classical IR models differ from classic models in that they are built upon propositional logic, a way to combine documents and queries in some representation and suitable logic.
- Propositional logic (also known as sentential logic) is that branch of logic that studies ways of combining or altering statements or propositions to form more complicated statements or propositions.
- Examples of non-classical Information Retrieval models include Information Logic models, Situation Theory models, and Interaction models.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Alternative Information Retrieval Model
The alternative Information Retrieval Model is the enhancement of the classical IR model that makes use of some specific techniques from some other fields.
- Examples of Alternative IR models: Cluster models, Fuzzy models, and Latent Semantic Indexing (LSI) models.
The Boolean Model
The Boolean model in information retrieval is based on the set theory and boolean algebra. We can pose any query in the form of a Boolean expression of terms where the terms are logically combined using the Boolean operators AND, OR, and NOT in the Boolean retrieval model.
- Using the Boolean operators, the terms in the query and the concerned documents can be combined to form a whole new set of documents.
- The Boolean AND of two logical statements x and y means that both x AND y must be satisfied and will be a set of documents that will smaller or equal to the document set
- while the Boolean OR of these same two statements means that at least one of these statements must be satisfied and will fetch a set of documents that will be greater or equal to the document set otherwise.
- Any number of logical statements can be combined using the three Boolean operators.
- The queries are designed as boolean expressions which have precise semantics and the retrieval strategy is based on binary decision criterion.
- The Boolean model can also be explained well by mapping the terms in the query with a set of documents.
The most famous web search engine in recent times Google also ranks the web page result set based on a two-stage system: In the first step, a Simple Boolean Retrieval model** returns matching documents** in no particular order, and in the next step ranking is done according to some estimator of relevance.
Aspects of Boolean Information Retrieval Model
Indexing: Indexing is one of the core functionalities of the information retrieval models and the first step in building an IR system assisting with the efficient retrieval of information.
- Indexing is majorly an offline operation that collects data about which words occur in the text corpus so that at search time we only have to access the pre-compiled index done beforehand.
- The boolean model builds the indices for the terms in the query considering that index terms are present or absent in a document.
Term-Document Incidence matrix: This is one of the basic mathematical models to represent text data and can be used to answer Boolean expression queries using the Boolean Retrieval Model. It can be used to answer any query as a Boolean expression.
- It views the document as the set of terms and creates the indexing required for the Boolean retrieval model.
- The text data is represented in the form of a matrix where rows of the matrix represent the sentences and the columns of the matrix represent the word for the data which needs to be analyzed and retrieved and the values of the matrix represent the number of occurrences of the words.
- This model has good precision as the documents are retrieved if the condition is matched but, it doesn't scale well with the size of the corpus, and an inverted index can be used as a good alternative method.
Processing the data for Boolean retrieval model
- We should strip unwanted characters/markup like HTML tags, punctuation marks, numbers, etc. before breaking the corpus into tokens/keywords on whitespace.
- Stemming needs to be done and then common stopwords are to be removed depending on the application need
- The term document incidence matrix or inverted index (with the keyword a list of docs containing it) is built.
- Then the common queries/phrases may be detected using a domain-specific dictionary if needed.
Example of Information Retrieval in Boolean Model
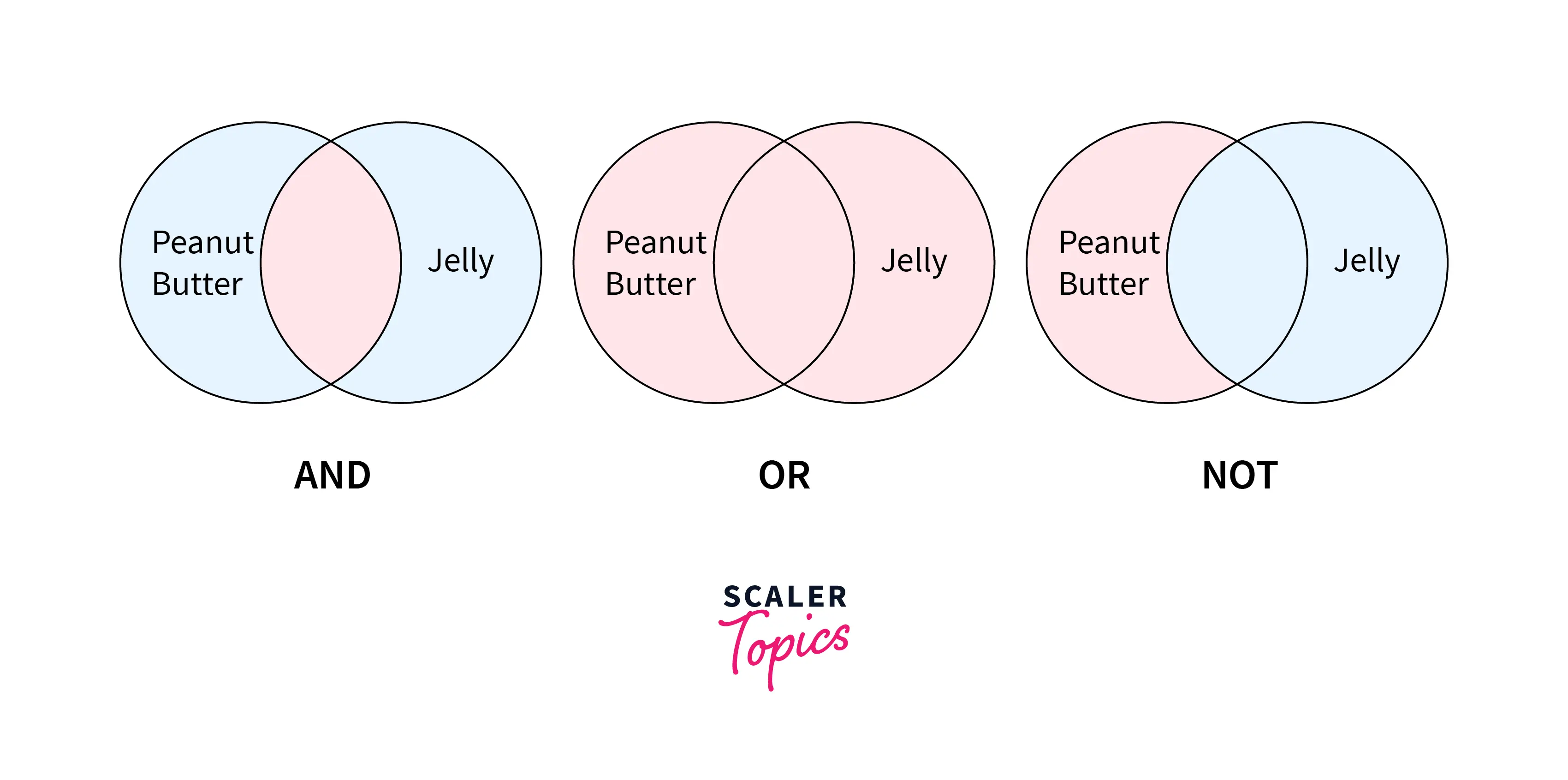
- For example, the term Peanut Butter individually (or Jelly individually) defines all the documents with the term Peanut Butter (or Jelly) alone and indexes them.
- If the information needed is based on Peanut Butter AND Jelly, we will be giving a set of documents that contain both the words and so the query with the keywords Peanut Butter AND Jelly will be giving a set of documents that are having the both the words Peanut Butter AND Jelly.
- Using OR the search will return documents containing either Peanut Butter or documents containing Jelly or documents containing both Peanut Butter and Jelly.
Advantages of Boolean Model
- It is easy to implement and it is computationally efficient. Hence, it is the standard model for the current large-scale, operational retrieval systems and many of the major online information services use it.
- It enables users to express structural and conceptual constraints to describe important linguistic features. Users find that synonym specifications (reflected by OR-clauses) and phrases (represented by proximity relations) are useful in the formulation of queries
- The Boolean approach possesses a great expressive power and clarity. Boolean retrieval is very effective if a query requires an exhaustive and unambiguous selection.
- The Boolean method offers a multitude of techniques to broaden or narrow down a query.
- The Boolean approach can be especially effective in the later stages of the search process, because of the clarity and exactness with which relationships between concepts can be represented.
Turn Learning into Career Growth
Shortcomings of Standard Boolean Approach
- Users find it difficult to construct effective Boolean queries for several reasons. Users are using the natural language terms AND, OR, or NOT that have different meanings when used in a query.
- Hence the users will make errors when they form a Boolean query because they resort to their own knowledge of English.
The Vector Space Model
Also called term vector models, the vector space model is an algebraic model for representing text documents (or also many kinds of multimedia objects in general) as vectors of identifiers such as index terms.
The vector space model is based on the notion of similarity between the search document and the representative query prepared by the user which should be similar to the documents needed for information retrieval.

We can represent both documents and queries with vectors with a t-dimensional vector representation:
- dj = (w1,j,w2,j,...,wt,j) for a document with
- q = (w1,q,w2,q,...,wt,q)
- Definition of Terms: The components of each dimension in the document and query representation correspond to a separate term whose terms can be single words, keywords, or longer phrases also.
- If the words of the documents are chosen to be the terms in the above representation, the dimensionality of the vectors is the number of distinct words occurring in the vocabulary of the corpus.
- Computing the values of the Terms: The value of the vector is non-zero if a term or word occurs in the document. Many different schemes can be taken for example count of occurrences, normalized counts, etc. but the most popular and efficient representation is tf-idf term weighing.
- The vector space model represents the documents and queries as vectors in a multidimensional space whose dimensions are the terms further used to build an index to represent the documents.
Notion of Similarity in Vector Space Model
The assumptions of the document similarities theory are used to compute the relevancy rankings of documents and the keywords in the search in vector space models.
- Angle of deviation between query and document: One way is to compare the deviation of angles between each document vector and the original query vector where the query is represented as some kind of vector as the documents.
- Cosine distance as similarity metric: The most popular and easier method in practice is to calculate the cosine of the angle between the vectors - A cosine value of zero means that the query and document vector are orthogonal and have no match at all.
- A zero cosine similarity value implies that the terms in the query do not exist in the document we are considering.
- Ranking the results using a similarity metric: The degree of similarity between the representation of the prepared document and the representations of the documents in the collection is used to rank the search results.
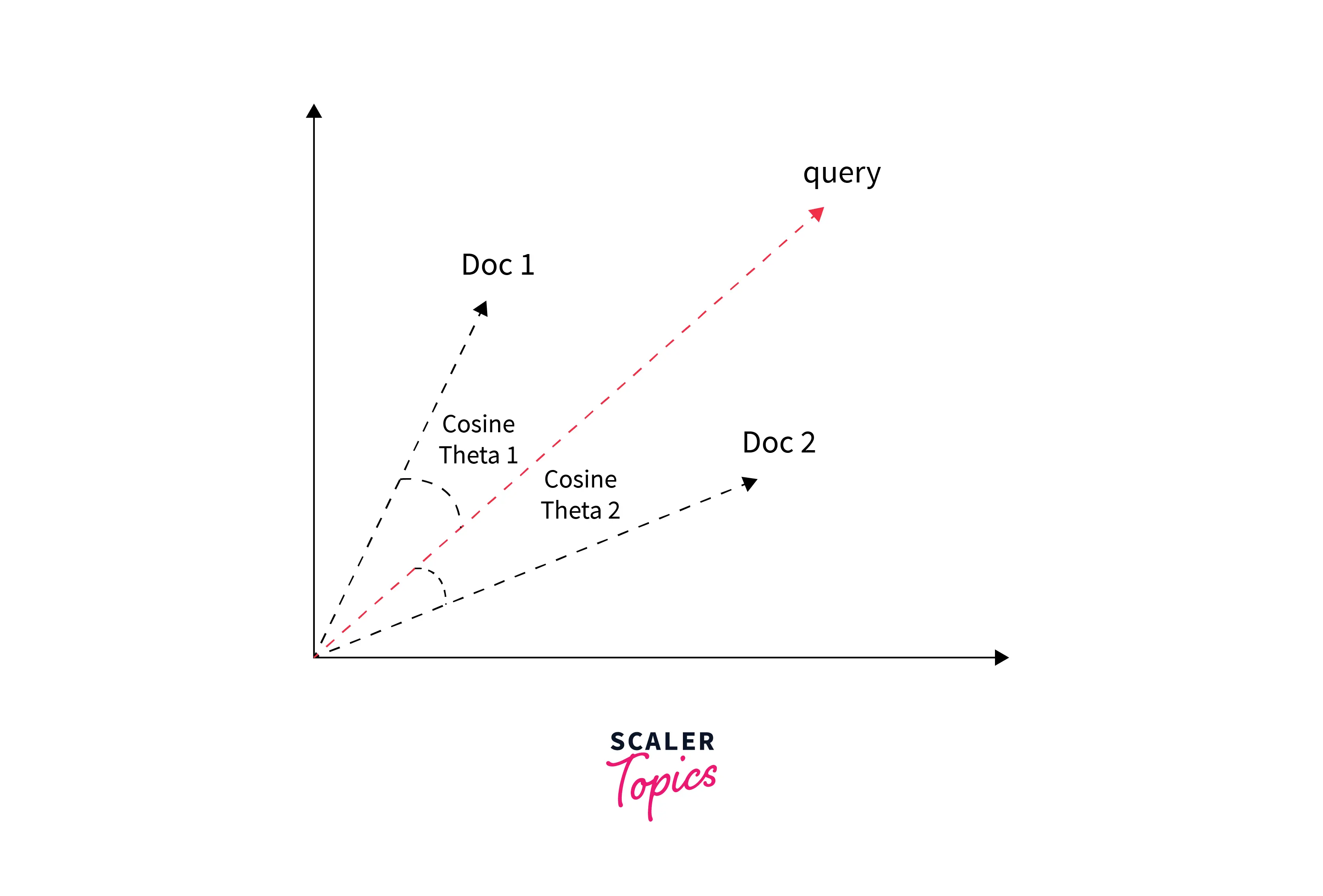
One other way of looking at the similarity criterion in the vector space model is that - the more the two representations of search documents and the user-prepared query agree in the given elements and their distribution, the higher would the probability of their representing similar information.
Index Creation for Terms in the Vector Space Model
The creation of the indices for the vector space model involves lexical scanning, morphological analysis, and term value computation.
- Lexical scanning is the creation of individual word documents to identify the significant terms and morphological analysis reduces to reduce different word forms to common stems and then compute the values of terms on the basis of stemmed words.
- The terms of the query are also weighted to take into account their importance, and they are computed by using the statistical distributions of the terms in the collection and in the documents.
- The vector space model assigns a high ranking score to a document that contains only a few of the query terms if these terms occur infrequently in the collection of the original corpus but frequently in the document.
Assumptions of the Vector Space Model
- The more similar a document vector is to a query vector, the more likely it is that the document is relevant to that query.
- The words used to define the dimensions of the space are orthogonal or independent.
- The similarity assumption is an approximation and realistic whereas the assumption that words are pairwise independent doesn't hold true in realistic scenarios.
Disadvantages of Vector Space Model
- Long documents are poorly represented because they have poor similarity values due to a small scalar product and a large dimensionality of the terms in the model.
- Search keywords must be precisely designed to match document terms and the word substrings might result in a false positive match.
- Semantic sensitivity: Documents with similar context but different term vocabulary won't be associated resulting in false negative matches.
- The order in which the terms appear in the document is lost in the vector space representation.
- Weighting is intuitive but not represented formally in the model.
- Issues with implementation: Due to the need for the similarity metric calculation and in turn storage of all the values of all vector components, it is problematic in case of incremental updates of the index
- Adding a single new document changes the document frequencies of terms that occur in the document, which changes the vector lengths of every document that contains one or more of these terms.
Probabilistic Model
Probabilistic models provide the foundation for reasoning under uncertainty in the realm of information retrieval.
Let us understand why there is uncertainty while retrieving documents and the basis for probability models in information retrieval.
Uncertainty in retrieval models: The probabilistic models in information retrieval are built on the idea that the process of retrieval is inherently uncertain from multiple standpoints:
- There is uncertainty in the understanding of user’s information needs - We can not sure that the user mapped their needs into the query they have presented.
- Even if the query represents the need well, there is uncertainty in the estimation of document relevance for the query which stems from either the uncertainty from the selection of the document representation or the uncertainty from matching the query and documents.
Basis of probabilistic retrieval model: Probabilistic model is based on the Probability Ranking Principle which states that an information retrieval system is supposed to rank the documents based on their probability of relevance to the query given all the other pieces of evidence available.
- Probabilistic information retrieval models estimate how likely it is that a document is relevant for a query.
- There may be a variety of sources of evidence that are used by the probabilistic retrieval methods and the most common one is the statistical distribution of the terms in both the relevant and non-relevant documents.
- Probabilistic information models are also among the oldest and best performing and most widely used IR models.
Types of Probabilistic information retrieval models: The classic probabilistic models (BIM, Two Poisson, BM11, BM25), The Language models for information retrieval, and the Bayesian networks-based models for information retrieval.
Language Models for Information Retrieval
Language modeling is a formal probabilistic retrieval framework based on concepts in speech recognition and natural language processing. However, language models have been used for speech recognition and natural language processing tasks (machine translation) for more than thirty years. They have been used in the IR domain since the 2000s with great success in recent times.
- The language models for information retrieval are based on the idea that a query is considered generated from an ideal document that satisfies the information need and the IR system’s job is then to estimate the likelihood of each document in the collection being the ideal document and rank the documents in ascending or decreasing order.
- Each document is viewed as a language sample, each query as a generation process. The retrieved documents are ranked based on the probabilities of producing a query from the corresponding language models of these documents.
- Many research studies have also confirmed that language modeling techniques are preferred over tf-idf (term frequency-inverse document frequency) weights because of empirical performance as well as the probabilistic meaning that can be formally derived from a language modeling framework.
The majority of language modeling approaches to information retrieval can be categorized into one of four groups:
- The generative query likelihood approach, which ranks based on the likelihood of a document language model generating the query
- The generative document likelihood approach, which ranks based on the likelihood of a query language model generating a document
- The comparative approach, which ranks based on the similarity between the query language model and document language model
- The translation models, which rank based on the likelihood of the query being viewed as a translation of a document
- The cluster-based language models.
Conclusion
- `Information Retrieval systems are software systems that provide access to books, journals, many kinds of documents, and multimedia objects. Web search engines are the most visible IR applications.
- Information Retrieval models provide the framework for collecting, storing, managing, matching, and ranking the documents and building many aspects of IR models.
- There are mainly three classes of IR models - Boolean, Vector space, and Probabilistic.
- Documents and queries are represented as sets of index terms based on set theory rules in the Boolean retrieval model.
- In the vector model, documents and queries are represented as vectors in a t-dimensional space and modeled on algebraic rules.
- The framework for modeling document and query representations is based on probability theory in the probabilistic information retrieval models.