NLP Text Classification Using Scikit-Learn
Overview
Text classification is the task of using statistical or machine learning models to take some data which is a corpus of sentences or combination of words as input to produce a set of the label(s) which we predefined know beforehand. The number of labels can be two or more.
In many of the text classification problems, the categorization into labels is based primarily on keywords present in the text.
Introduction to Text Classification Using Scikit-Learn
Text classification is a supervised machine learning technique to assign a set of predefined labels / categories to some open-ended text in the dataset.
- Text classifiers are models which use either hand-crafted features or automatically learned rules to organize, structure, and categorize any kind of text from documents and files with data coming from multiple sources.
- Text classification has a variety of applications such as detecting user sentiment from tweets of the user base, classifying an email as spam or ham, classifying blog posts into different categories, automatic tagging of customer queries, etc.
Scikit-learn is one of the most popular machine learning libraries in python for a variety of tasks and gives many useful functionalities as pre-written functions directly, it is also most widely used for building and validating machine learning models.
Let us learn how to do text classification with a sample dataset using scikit-learn.
Prerequisite and Setting Up the Environment.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Setting Up the Jupyter Notebook
Jupyter notebook can be installed from the popular setup of anaconda or jupyter directly. Reference instructions for setting up from the source can be followed from here. Once installed we can spin up an instance of jupyter notebook server and open a python notebook instance and run the following code for setting up basic libraries and functionalities.
Import the libraries for processing data and other utilities
import os, sys, gc, warnings import logging, math, re import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt from IPython.display import display, HTML from IPython.core.interactiveshell import InteractiveShell
The following settings help in proper formatting and display of the output of code we run.
warnings.filterwarnings("ignore") pd.set_option('max_rows', None) pd.set_option('max_columns', None) InteractiveShell.ast_node_interactivity = "all" display(HTML(data=""""""))
Let us also download stop words for cleaning the text in the tweets.
import nltk nltk.download('stopwords')
If a particular library is not found, it can simply be downloaded from within the notebook by running a system command pip install sample_library command. For example to install seaborn, run the command from a cell within jupyter notebook like:
! pip install seaborn
Getting the Dataset
- For this particular text classification problem, we are getting data from Kaggle datasets related to Coronavirus tweets NLP - Text Classification which can be found here nlp text classification with covid tweets.
- The dataset is a corpus of tweets that are pulled from Twitter and tagged manually for training models on this tagged variable. The names and usernames that the tweets were pulled from were masked so that there are no privacy concerns.
- There are two datasets one train and one test which need to be downloaded separately and kept in the same location in the place where jupyter notebook with the code which we run here is there.
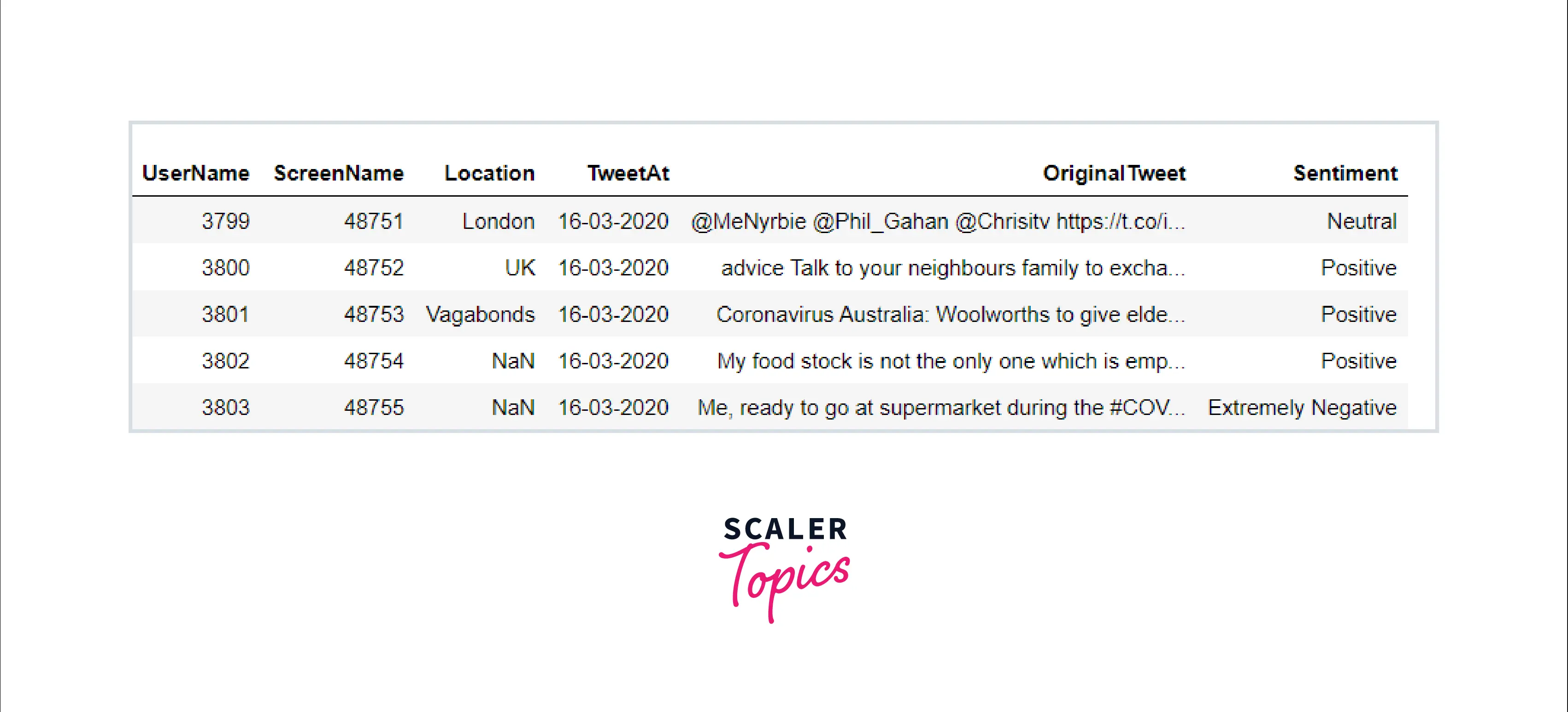
Let us look at sample records from the data:
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Loading the Data Set in Jupyter.
Let us load the dataset and make it ready for preparing the features.
- Since this is a dataset of tweets pulled during covid times, it may contain free-flowing text and needed to be cleaned before constructing features.
- Steps followed to clean the text corpus: Remove urls, html tags, lowercase the text, remove numbers from the text, remove punctuations, remove the stop words, remove all the mentions, remove the hashes, remove spaces
- We then perform stemming and lemmatization on the cleaned text, we make use of the popular nltk python library for these two steps.
- Train and test records are separated for model training and performance evaluation
- Let us read the datasets separately and join together for further operations
- Let us give a tag for each data set as train and test under split column in newly constructed concat dataset
Tag construction for split column happens here
Concat Step
- Get the ingested raw data sets and concat here, we will take only those columns we need here
- The concat will make further processing easier so that we can run code & functions for a single data set instead of two
Let us look at the summary of the input data set after concatenation.
Let us see the percentage of train and test records.
Data Preprocessing
- Let us pre-process the target variable: We will encode the Negative and Extremely Negative as 0, Positive and Extremely Positive as 1, and discard the Neutral records
Summary of value counts after mapping target variable as percentages.
- We can also use the following alternative for value count summary
- df_raw['label'].value_counts(normalize= True)*100 # Other way to find percentage counts
Cleaning the text in the tweets: A series of functions are written below for different pre-processing that can be typically followed for text classification nlp
- Steps so that each can be modified or added individually later and can be wrapped into a single function at the end - The functions are applied successively one by one on the same column constructed initially from the tweet column containing the text
Let us write a function to remove Urls and HTML links
Function for lower casing the text
Remove numbers from the text of the tweet
Function to remove punctuations
Function to remove stopwords from English language
Function to remove mentions
Function to remove hashes mentioned in tweet
Function to remove extra white space left while removing stuff
Get all the stopwords using nltk library after loading the library
from nltk.corpus import stopwords
STOPWORDS = ", ".join(stopwords.words('english')) # alternative code and function for stop words
Let us apply all the functions we have written for pre-processing one by one.
Take a look at the data once
Import library needed for stemming the sentences
from nltk.stem import PorterStemmer
Create an object of class PorterStemmer
Function to do stemming on the cleaned text
Download the library needed for stemming and lemmantizing the sentences
import nltk nltk.download('wordnet')
Import library needed for stemming and lemmantizing the sentences
from nltk.stem import WordNetLemmatizer Create an object of class WordNetLemmatizer
Function to do lemmatization on the cleaned text
See what the text in the data looks like after stemming and lemmatization on the cleaned text.
The data is now ready for creating features from text tweets.
Turn Learning into Career Growth
Extracting Features from Text Files.
- Now that we have a cleaned set of records, we need to represent text with features that models can understand. We do this with bag of words representation using TF IDF vectorizer in sklearn and apply SVD on top of it to efficiently reduce the dimensionality before sending it to models.
- While Bag of Words representation only creates a set of vectors containing the count of word occurrences from document text, TF-IDF vectorization goes a step further to process the text such that more important words are given more weight based on relevance also but not counts alone.
- Applying SVD on top of tf-idf when using text classification nlp algorithms gives a reduced dimensional representation of the feature matrix making a strong emphasis on the strong relationships and removes the noise.
- This helps us retain the best possible reconstruction signal of the feature matrix with the least possible information loss.
- The main hyperparameter to use SVD is to figure out how many dimensions concepts to use when approximating the feature matrix.
Let us import the functions required for processing text
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.decomposition import TruncatedSVD from sklearn.model_selection import train_test_split
Load the cleaned text as a variable
Initialize the model
Transform our tokens to freq based sparse matrix
- Implementing SVD on the BoW matrix (without NGrams) will reduce the columns dim by a factor of over n (sample = 10) but still maintain good results.
- Also, the model files generated are more compact and hold compressed information.
- This is all very useful if we need to load them on a remote device.
Train test split - we already split the data, we will get the indices and slice the data now
- After decomposing the input matrix of all words in our current text classification nlp algorithm using SVD, our feature space was reduced drastically
- Let us look at the shape of all processed datasets after the train test split
Running ML Algorithms.
On the feature matrix we have, let us run some popular algorithms that work well on bag of words feature fed svd representation generally used in text classification nlp models. We shall choose linear support vector machines, logistic regression and random forest classifier from sklearn so that we have three different set of techniques with different foundational assumptions in modelling for our comparison.
- Linear Support Vector Machine for text classification: Support vector machines is an algorithm that determines the best decision boundary between vectors that belong to a given label or category and vectors that do not belong to it.
- Linear support vector machnines have the ability to generalize well in high dimensional feature spaces and also eliminate the need for feature selection, making the application of text categorization considerably easier.
- Another advantage of SVMs over the conventional methods is their robustness and often considered best model among the traditional machine learning models for text classification tasks.
- Logistic regression for text classification in NLP: Logistic regression is one of the supervised machine learning algorithm used for classification purposes. It is used as our data is in the form of binary (0 and 1 meaning means whether the class is from one label or another)
- In the text classification tasks using NLP techniques, it is generally accepted that Logistic Regression is a great starter algorithm for reasonable accuracies.
- Random forest ensemble for text classification:- Random forest is an emsemble technique in machine learning which builds decision trees on different samples and takes their majority vote for classification and average in case of regression.
- Random forest is also a popular technique in text classification tasks owing to the algorithmic simplicity and prominent classification performance for high dimensional data.
Let us implement a set of individual models now on our feature matrix.
Load the functions and libraries required
from sklearn.svm import LinearSVC from sklearn.linear_model import LogisticRegression from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import cross_val_score from sklearn.calibration import CalibratedClassifierCV from sklearn import metrics
Initiate a dictionary to store results of models we run
Run the cross validation for efficiently evaluating the model
- For K fold cross validation (CV), ket us choose 5
- With k fold cross validation we can see how out model is performing across different cuts of dataset rather than one alone.
Let us run Linear support vector machine model
Let us run logistic regression model now
Let us finally run random forest classifier for comparison now
Comapre the results here
We can see that what model yields the best score, let us run the same on our test set and see the performance plots on a sample model for reference.
Accuracy Visualization and Plotting Model Results
Let us pick random forest for test accuracy plots: We wil get the predicted classes and associated probabilities from the model.
Get the metrics for confusion matrix: Confusion matrix is a very popular measure used while solving classification problems. It can be applied to binary classification as well as for multiclass classification problems and gives all the necessary measures needed to compute metrics precision, recall, accuracy etc.
Plot the confusion matrix
Let us plot the RoC-AUC curve: ROC curve is a performance measurement for the classification problems at various threshold settings.
- ROC is a probability curve and AUC represents the degree or measure of separability.
- It tells how much the model is capable of distinguishing between classes.
Let us plot precision-recall curve here: Precision-Recall curve shows the tradeoff between precision and recall for different settings of threshold. Also a high area under the curve represents both high recall and high precision, where high precision relates to a low false positive rate, and high recall relates to a low false negative rate.
Let us look at the sample performance comparison from the models we have run:
Output:
Grid Search for Parameter Tuning.
Generally just running a set of algorithms for comparison is not enough as there may be some hyper-parameters where some models in the text classification nlp arsenal may perform better. To get such a set of parameters where there is optimal performance, we need to tune the models with a suitable strategy. Here let us use grid search for tuning the random forest model for reference.
We will use the cross validation version of grid search in scikit-learn. We will specify parameters and distributions to sample from for the grid search at the start. Let us load the libraries and functions required
from sklearn.model_selection import GridSearchCV from sklearn.ensemble import RandomForestClassifier
The above variable contain the keys based on which we can look at the performance across different paramters of the model. And this will also give a list of model parameters for which we get the best performance on the train test set.
Useful Tips and a Touch of NLTK.
Natural Language Toolkit (NLTK) is an open source Python library for Natural Language Processing.
- It has functionality for almost all text processing techniques and a suite of text processing libraries like classification, tokenization, stemming, tagging, parsing, and semantic reasoning, lemmatization, POS Tagging and also wrappers for industrial-strength NLP libraries
- The syntax of this toolkit is relatively simple and easy to learn as well.
Let us look at some basic functions in NLTK and implement them with code that are useful for text classification nlp tasks.
Command to install and setup nltk in jupyter notebook
! pip install nltk import nltk nltk.download()
Tokenisation and POS tagging on a simple sample senetnce Load the lbraries and required functions
from nltk.tokenize import word_tokenize from nltk import pos_tag
Get stop words for english language Load the lbraries and required functions
from nltk.corpus import stopwords
Let us remove the stop words using the list of words we have
Remove punctuation from text Load the lbraries and required functions
from nltk.tokenize import RegexpTokenizer
Identify named entities
Display the parsed tree, load the lbraries and required functions
from nltk.corpus import treebank
Similaryly we can remove most frequent words, stem and lemmatize the input text and do most text processing tasks simply using nltk.
Conclusion
- Text classification is one of the important tasks in NLP which is process of classifying text strings or documents into different categories / labels depending on the contents of the input data.
- Scikit-learn is one of the most popular libraries in python with functionality for processing text data and further model the data with many machine learning algorithms.
- We can run python programs and code to process text directly in jupyter notebooks which can be installed using Anaconda or direct installation.
- We need to pre-process and clean the data to construct features from the text data.
- Bag of words & tf-idf vectorization are primary ways to represent text as features.
- Dimensionality reduction of tf-idf can reduce the size of dataset drastically while retaining performance, SVD is a powerful implementation that can be used off the shelf.
- Once features are constructed from text, a variety of algorithms in text classification nlp like naive bayes, logistic regression, SVM, random forest can be used to compare model performance.
- Most models need parameter tuning on hyper paramters of the model, grid-search is a simple way to achieve the same.
- NLTK is a powerful text processing python library with functionality for cleaning, feature extraction and data analysis in NLP.