Introduction to TextBlob in NLP
Overview
The technique of understanding and extracting valuable information from human language is called Natural Language Processing(NLP). This is one of the most important topics in machine learning and is used in various aspects of our life. Python language helps us with NLP with its plethora of libraries. One such library is TextBlob, and this article revolves around it.
Introduction
Natural language processing involves various techniques such as tokenization, POS tagging, sentiment analysis, language translation, etc. If programmed the conventional way, these techniques may require hundreds of lines of code, and they may not be as fast as required. Hence, we need predefined libraries to speed up the process. There are libraries, such as scikit-learn, gensim, TextBlob, and many more, that are available for free and are very powerful.
What is TextBlob?
TextBlob is a Python library used to perform NLP tasks like tokenization, POS-Tagging, Words inflection, Noun phrase extraction, lemmatization, N-grams, and sentiment Analysis. If you know about the state-of-the-art NLTK library, TextBlob has a few more features than it, such as Spelling correction, Creating a summary of a text, Translation, and language detection. It is an easy tool that covers all the necessary aspects of natural language processing.
How to Install TextBlob?
The process is quick and simple:-
Next, we import the library in our Python file, and we are good to go.
Why use TextBlob?
- It is quick and simple to implement and use.
- Easily deployable with less computable resources and can be employed where the application has computational constraints.
- Faster than NLTK and has additional functions.
- Can be used for data preprocessing as well.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Tasks With the TextBlob Module:
Creating a TextBlob
Textblob works just like a Python string, and this is how easy it is to create a textblob object.
Let's get the sentences:-
Output:-
Tokenization
Tokenization is the process of separating each word in the sentence into a list so that it can be easily interpreted and manipulated later.
It takes one line of code to implement tokenization.
Output:-
POS Tagging
Tagging is a kind of classification that may be defined as the automatic assignment of description to the tokens. Parts of speech tagging, better known as POS tagging, refer to the process of identifying specific words in a document and grouping them as part of speech based on their context. In simple words, we can say that POS tagging is a task of labeling each word in a sentence with its appropriate part of speech, such as nouns, verbs, adverbs, adjectives, pronouns, conjunction, and their sub-categories.
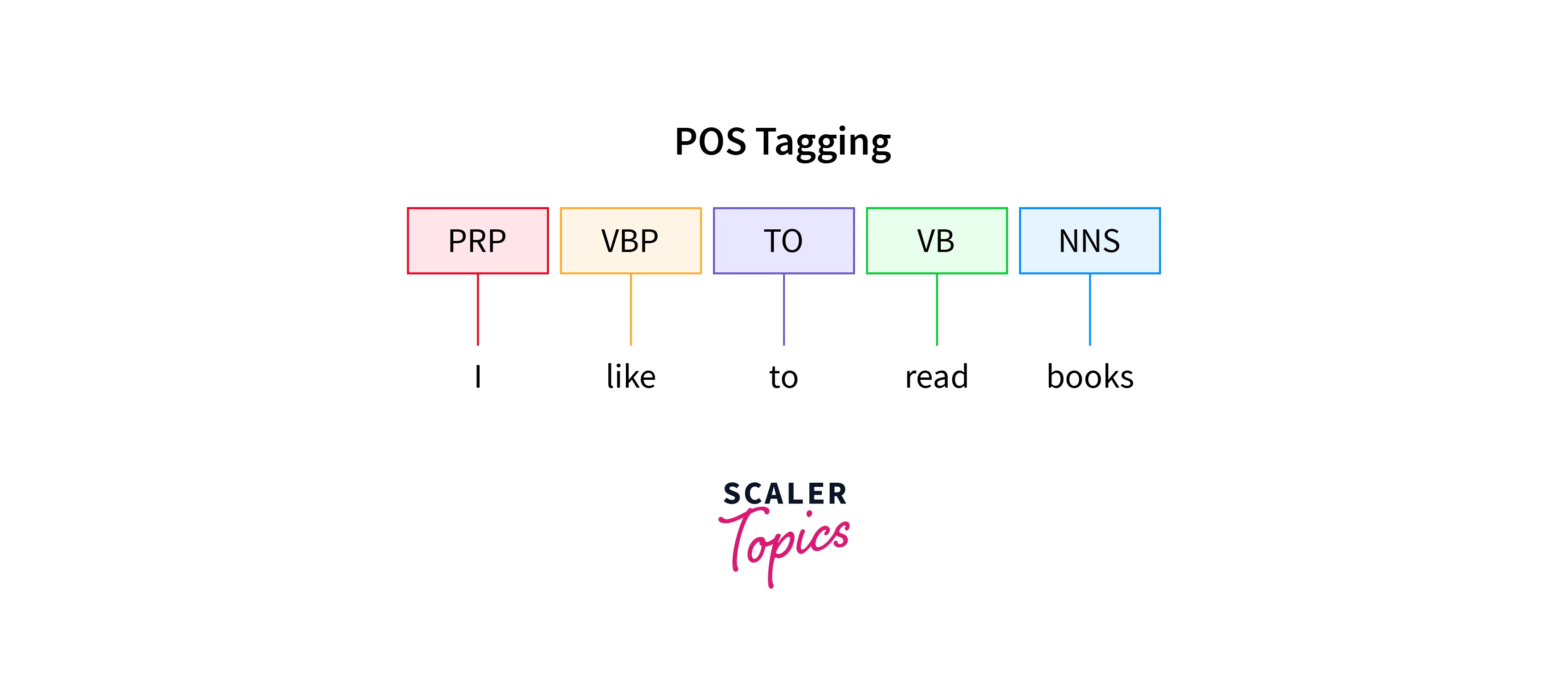
Output:-
Spelling Corrections
This is one of the unique features of the TextBlob library. With the correct method of the TextBlob object, you can correct all the spelling mistakes in your text.
Output:-
Turn Learning into Career Growth
Language Translation
Another powerful feature of the TextBlob library is to translate from one language to another. On the backend, the TextBlob language translator uses the Google Translate API. We use the translation method for this purpose. The language that you want your text to be translated to is passed as a parameter to the method.
Output:-
Noun Phrase Extraction
A noun phrase is a word or group of words that can function as the subject, the object, or the complement in a sentence. Example: The big, warm coat. The little, pretty cottage. The shoes with ruby jewels. Hannah's bowl of melon. It is sometimes necessary to get the noun phrases of the sentence sometimes to know more about the context.
Output:-
Lemmatization
Lemmatization refers to reducing the word to its root form, as found in a dictionary. Lemmatization considers the context and converts the word to its meaningful base form. It is responsible for grouping different inflected forms of words into the root form, having the same meaning. For instance, stemming the word ‘Caring‘ would return ‘Car‘ whereas lemmatizing the word ‘Caring‘ would return ‘Care‘.
To perform lemmatization via TextBlob, you have to use the Word object from the textblob library, pass it the word that you want to lemmatize, and then call the lemmatize method.
Output:-
n-Grams
N-Grams refer to n combination of words in a sentence. In TextBlob, N-grams can be obtained by passing the number of N-Grams to the n-grams method of the TextBlob object.
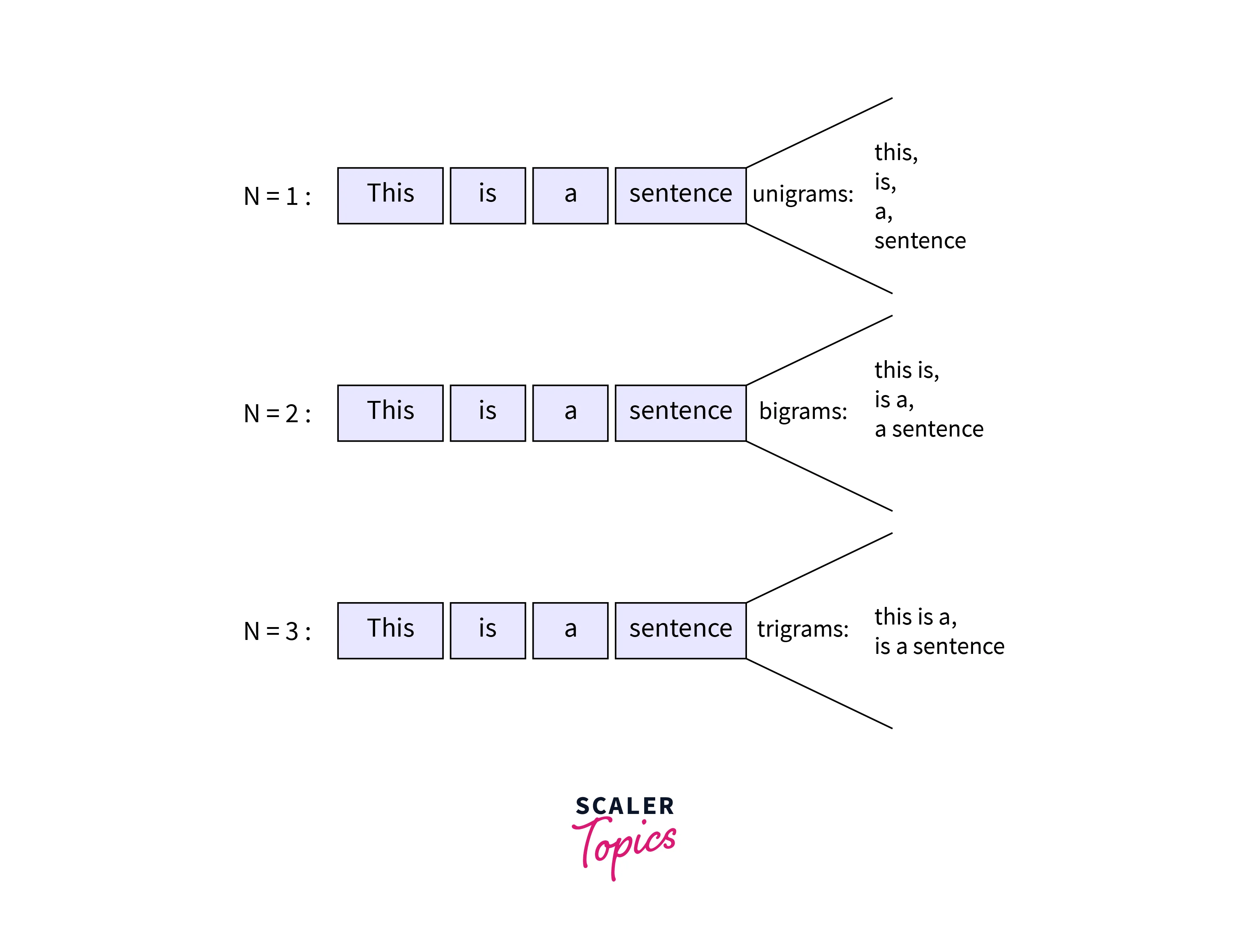
Output:-
Sentiment Analysis
Sentiment analysis, also referred to as opinion mining, is an approach to natural language processing (NLP) that identifies the emotional tone behind a body of text. This is a popular way for organizations to determine and categorize opinions about a product, service, or idea. We use the textblob's NaiveBayesAnalyzer for this purpose.
Output:-
'pos' indicates positive as the p_pos score is higher than the p_neg score.
Simple Classifier with TextBlob
It is very simple to build a classifier with TextBlob. The in-built functions make the process quick and simple.
The first thing we need is a training dataset and test data. The classification model will be trained on the training dataset and will be evaluated on the test dataset.
Let's see the data:-
Now we use TextBlob's NaiveBayesClassifier for classification.
Next, we see the results!
Output:-
and
Output:-
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Conclusion
The key takeaways from this article are:-
- TextBlob is quick and simple to implement and use.
- It is faster than NLTK and has additional functions.
- Tasks like tokenization, POS-Tagging, word inflection, Noun phrase extraction, lemmatization, N-grams, and Sentiment Analysis are performed with few lines of code with TextBlob.
- TextBlob is easily deployable with less computable resources.