OpenAI Models
Overview
In this article, we will explore OpenAI models, including GPT (Generative Pre-trained Transformer), GPT-2, GPT-3, Codex, CLIP (Contrastive Language-Image Pre-training), and DALL-E. We will discuss the concepts of Few-Shot, One-Shot, and Zero-Shot Learning in GPT-3. We will provide a small introduction for each model, explain how it works, discuss its applications and use cases, highlight its drawbacks and disadvantages, and provide any other relevant information.
![]()
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
GPT (Generative Pre-trained Transformer)
GPT-1, short for "Generative Pre-trained Transformer 1," is the precursor to the more advanced GPT-2 and GPT-3 models. It was developed by OpenAI and laid the foundation for subsequent improvements in natural language processing and generation.
![]()
Working
At its core, GPT-1 is a language model that aims to generate human-like text. To achieve this, it undergoes a two-phase training process:
- Pre-training:
During the pre-training phase, GPT-1 is exposed to a massive and diverse dataset of text collected from the internet. This dataset contains various textual content, including books, articles, websites, and more. The objective of pre-training is for the model to learn human language's underlying patterns and structures.- Contextual Learning:
GPT-1 learns to predict the next word in a sentence based on the context provided by the preceding words. This process involves analyzing the immediately preceding word and considering the entire sentence or sequence of words leading up to the current point. This equips the model with understanding grammar, syntax, and language structure. For example, when presented with the phrase "The sun is shining, and the _," GPT-1 can predict that the next word will likely be related to weather or the outdoors. - Feature Extraction:
GPT-1 also learns to extract meaningful features and representations from the text it encounters. These features capture semantic relationships between words, allowing the model to understand associations and similarities between words and concepts.
- Contextual Learning:
- Fine-tuning:
GPT-1 can be further fine-tuned on specific tasks or domains once pre-training is complete. Fine-tuning involves exposing the model to a more focused dataset relevant to a particular application. For example, GPT-1 can be fine-tuned for tasks like language translation, text summarization, or sentiment analysis. This fine-tuning process adapts the general language understanding capabilities of the model to excel in specific tasks. Combining pre-training and fine-tuning equips GPT-1 with a versatile understanding of human language. It can generate coherent and contextually relevant text, making it a valuable tool for various natural language processing tasks, such as text completion, generation, and even more specialized applications.
Applications/Use Cases:
- Text Completion and Suggestions:
GPT-1 can suggest the next word or phrase in a given text, making it useful for applications like auto-completion in word processors or predictive text on mobile devices. - Machine Translation:
It can be used for automated text translation from one language to another, although its translation capabilities are more limited than dedicated translation models. - Text Summarization:
GPT-1 can generate concise summaries of longer texts, making it useful for creating abstracts or extracting key information from documents.
Drawbacks/Disadvantages:
- Limited Context Understanding:
GPT-1 has a limited context window, which means it may struggle with understanding long and complex sentences or maintaining context over extended passages of text. - Lack of Fine-tuning:
Unlike GPT-2 and GPT-3, GPT-1 may not perform as well in fine-tuned, specialized tasks because of its smaller model size and training data limitations. - Potential for Inaccurate or Biased Output:
GPT-1, like all openai models, can generate text that is factually incorrect or biased based on the patterns it learned from its training data.
GPT-2
GPT-2, short for "Generative Pre-trained Transformer 2" is an advanced OpenAI model. It gained significant attention and controversy upon its release due to its impressive text-generation capabilities.
![]()
Working:
GPT-2 introduces several key advancements that set it apart:
- Larger Model Size:
One of the most notable differences is the substantial increase in model size. GPT-2 features an impressive 1.5 billion parameters, the tunable elements within the neural network. This increase in model size allows GPT-2 to capture a broader spectrum of linguistic nuances and complexities, making it highly proficient in generating coherent and contextually relevant text. - Transformer Architecture:
GPT-2 retains the transformer architecture, renowned for its effectiveness in handling sequential data, such as language. When making predictions, the transformer architecture relies on "self-attention" to weigh the importance of different words in a sentence. This enables the model to capture long-range dependencies and complex relationships within text. - Training Data:
During its training phase, GPT-2 learns from an extensive and diverse dataset of text sourced from the Web and the internet. This dataset encompasses various textual content, including news articles, academic papers, forums, and more. By training on this rich dataset, GPT-2 acquires a deep understanding of human language patterns, structures, and styles.- Contextual Learning:
GPT-2, like GPT-1, learns to predict the next word in a sentence based on the context provided by preceding words. However, the larger model size and extensive training data of GPT-2 enable it to handle even more intricate and nuanced contexts. For instance, when presented with a sentence like "The sun is shining, and the _," GPT-2 can predict the next word with remarkable accuracy, often inferring the topic and tone or sentiment. - Feature Extraction:
GPT-2 excels at extracting semantic features from text. It learns to understand the meanings and relationships between words and concepts, allowing it to produce text that makes sense in a given context. This ability to capture semantic nuances contributes to the fluency and coherence of its generated text.
- Contextual Learning:
GPT-2's combination of a transformer architecture, a massive model size, and training on a comprehensive internet text corpus equips it to generate text that closely mimics human language.

Applications/Use Cases:
- Content Generation:
GPT-2 generates high-quality content for blogs, news articles, and marketing materials. It can produce coherent and contextually relevant text, reducing the need for manual content creation. - Text Completion and Suggestions:
It excels at suggesting the next words or phrases in a given text, making it a valuable tool for increasing writing efficiency. - Text-based Games and Storytelling:
Game developers and writers utilize GPT-2 to create engaging narratives and dialogues within video games or interactive stories.
Drawbacks/Disadvantages:
- Risk of Misleading or Harmful Content:
GPT-2, like other openai models, can generate content that is biased, misleading, or harmful. It may produce politically biased or inappropriate text if not carefully monitored and controlled. - High Computational Requirements:
Training and deploying GPT-2 requires substantial computational resources, limiting access to smaller organizations and researchers. - Lack of Factual Accuracy:
GPT-2 generates text based on patterns in its training data, which might only sometimes align with factual accuracy. It can create plausible-sounding but incorrect information.
GPT-3
GPT-3, short for "Generative Pre-trained Transformer 3" is one of the most advanced Openai models and influential natural language processing models. It represents a significant leap in AI capabilities, with 175 billion parameters, making it one of the largest and most powerful large language models.
![]()
Generative Pre-trained Transformer 3
Working:
GPT-3 operates on the transformer architecture, like its predecessors GPT-1 and GPT-2. However, its massive size and extensive training data set it apart. During pre-training, GPT-3 learns from a vast corpus of text from the Web/Internet, enabling it to understand and generate text with exceptional fluency, coherence, and context awareness.
- Few-Shot Learning:
Few-shot learning in the context of GPT-3 refers to the model's ability to perform tasks with very limited examples or context. It can generalize from a small set of examples to understand and generate coherent responses. For example, you can provide GPT-3 with a few examples of a text-based task, and it can adapt to that task and generate relevant outputs. - One-Shot Learning:
One-shot learning takes this concept further, allowing GPT-3 to perform tasks based on a single example or a tiny amount of information. This demonstrates the model's remarkable adaptability and ability to generalize from extremely limited input. GPT-3 can make predictions or generate text based on just a single information. - Zero-Shot Learning:
Zero-shot learning involves making predictions or generating text for tasks the model has never encountered during training. GPT-3 can understand and generate responses for new tasks using its pre-trained language understanding and generalization capabilities. This is particularly powerful because it enables the model to be flexible and adaptable to various applications.
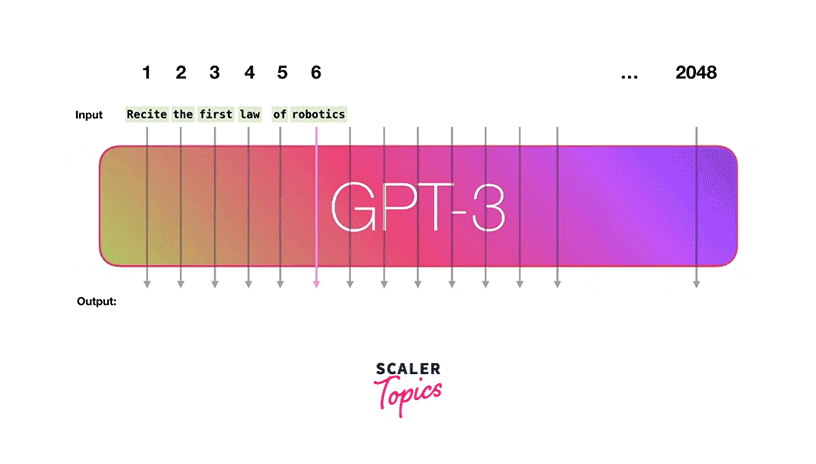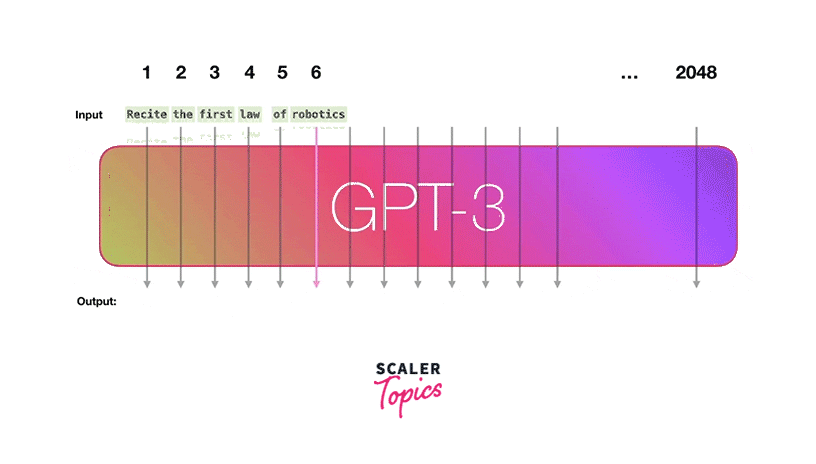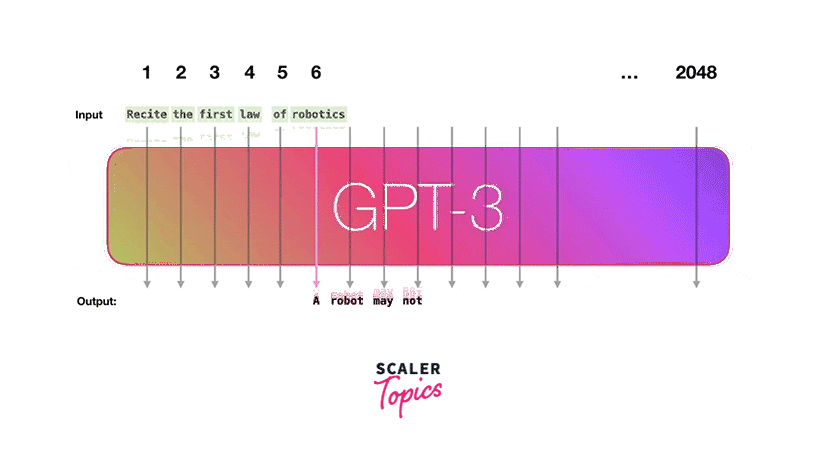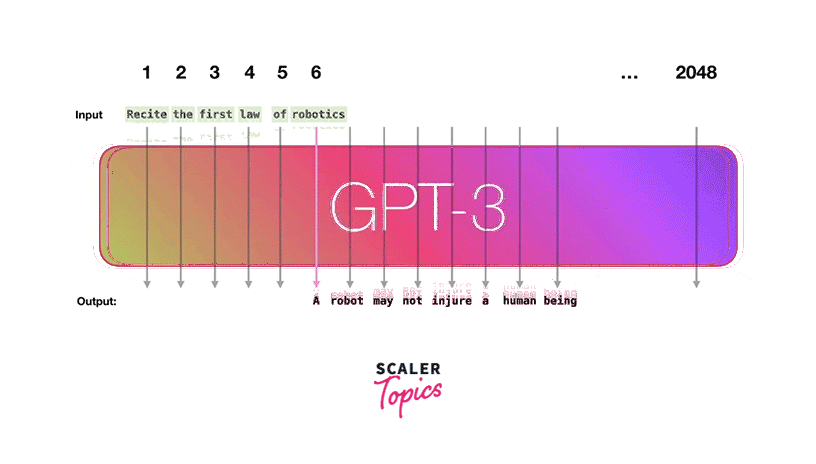
Applications/Use Cases:
- Advanced Chatbots and Virtual Assistants:
GPT-3 can power chatbots and virtual assistants to engage in highly natural and contextually relevant conversations with users. - Natural Language Understanding for Customer Support:
It can understand and respond to user queries more humanistically, improving customer support services. - Content Generation for News and Entertainment:
GPT-3 can automate content creation, such as news articles, stories, and even poetry, with high-quality and engaging output. - Translation and Language Processing:
GPT-3 excels at translation tasks and can aid in language processing applications.
Drawbacks/Disadvantages:
- Lack of Fact-Checking:
GPT-3 does not inherently fact-check the information it generates. This means it can produce factually inaccurate content, potentially spreading misinformation. - Contextual Inconsistencies:
GPT-3 may produce contextually inconsistent responses, as it needs a deeper understanding of long-range dependencies in text. - Computing Resources:
Training GPT-3 or using it for real-time applications demands significant computing resources, making it inaccessible for smaller organizations and researchers with limited budgets.
Turn Learning into Career Growth
Codex
Codex is a revolutionary AI model developed by OpenAI. It is a descendant of the GPT-3 model and is designed specifically for code generation and programming-related tasks. Codex has gained widespread attention for its ability to assist developers in writing, understanding, and working with code.
![]()
Working: Here's a deeper dive into how Codex operates:
- GPT-3 Architecture:
Codex inherits the underlying architecture of GPT-3, a variant of the transformer architecture. As mentioned earlier, the transformer architecture is designed for natural language understanding and generation. This architecture allows Codex to understand and generate human-like text. - Fine-tuning for Programming:
What truly sets Codex apart is its extensive fine-tuning of a vast programming code and documentation dataset. This fine-tuning process exposes Codex to a wide range of programming languages, libraries, frameworks, documentation, and code examples. As a result, Codex has become highly proficient in understanding and generating code in various programming languages, such as Python, JavaScript, Java, C++, and many others.- Semantic Understanding:
Codex learns to understand the semantics of programming languages and the logic behind different code constructs. It can recognize variable declarations, function definitions, loops, conditionals, and other programming concepts. This deep understanding allows Codex to generate code that aligns with the intent and requirements of a given coding task. - Code Generation:
When presented with a prompt or a description of a coding task, Codex leverages its fine-tuned knowledge to generate code snippets, functions, or even entire programs. It can produce code that is not only syntactically correct but also logically sound. This makes Codex a valuable tool for developers to streamline their coding process or explore solutions to programming challenges.
- Semantic Understanding:
Codex's specialization in programming-related tasks makes it a game-changer for software developers, as it can significantly boost productivity and assist in code-related activities.
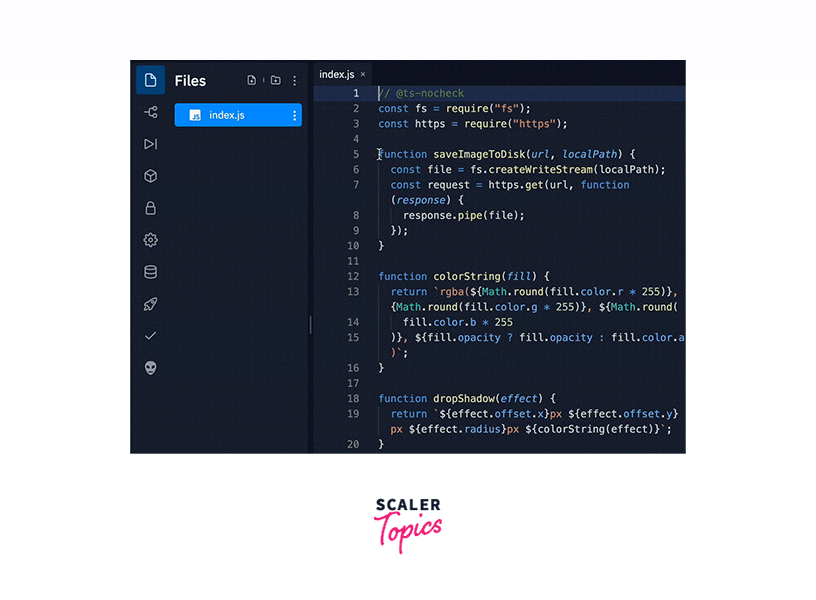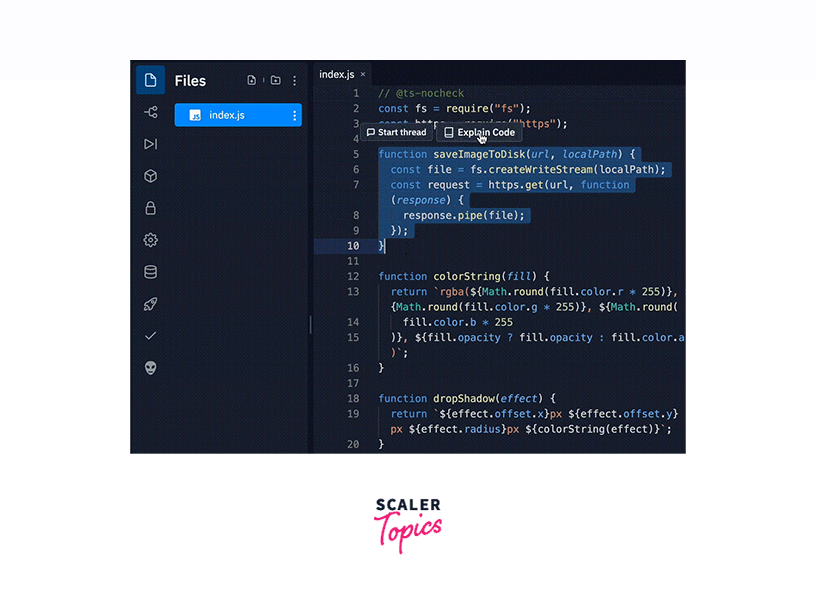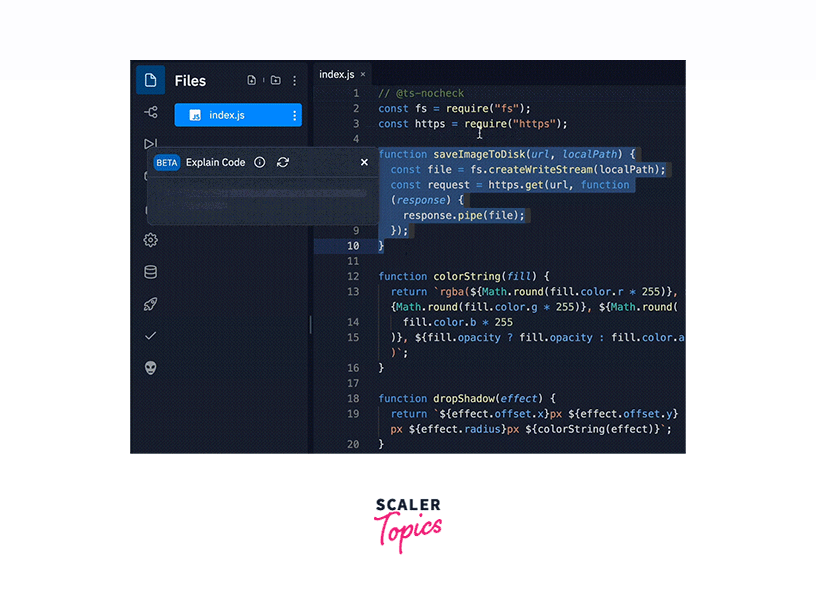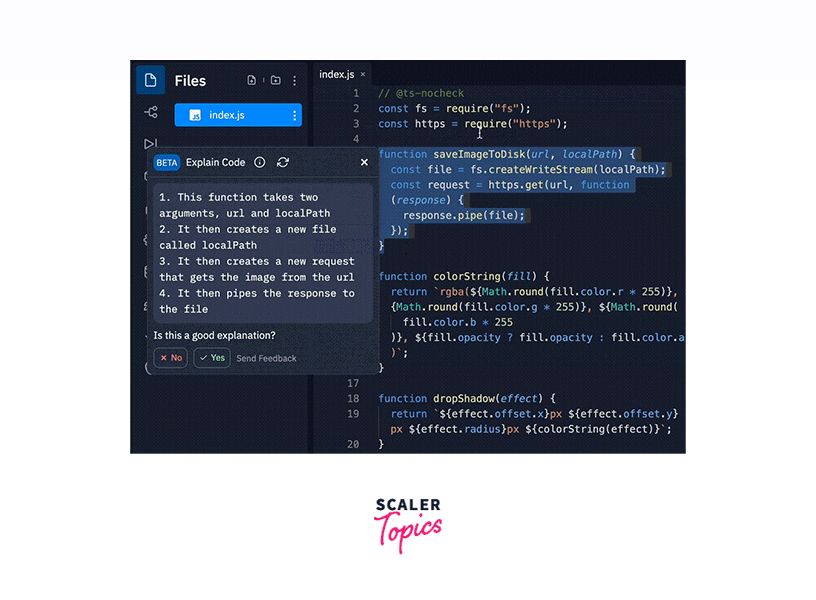
Applications/Use Cases:
- Code Generation:
Codex can generate code snippets, functions, or entire programs in various programming languages based on user descriptions or prompts. - Code Understanding:
Developers can use Codex to help understand and debug code. It can explain, highlight potential issues, or suggest improvements within existing codebases. - Code Translation:
Codex can translate code between programming languages, facilitating interoperability and porting of software.
Drawbacks/Disadvantages:
- Complexity Handling:
While Codex is proficient in many programming languages, it may struggle with complex or domain-specific code scenarios. - Security Concerns:
Codex can generate code based on potentially unsafe or insecure practices if the user's prompt is not carefully crafted. This could lead to security vulnerabilities in the generated code. - Lack of Creativity:
Codex generates code based on existing patterns and examples but may not innovate or find novel solutions to complex problems. It may not replace the creativity of human developers.
CLIP (Contrastive Language-Image Pre-training
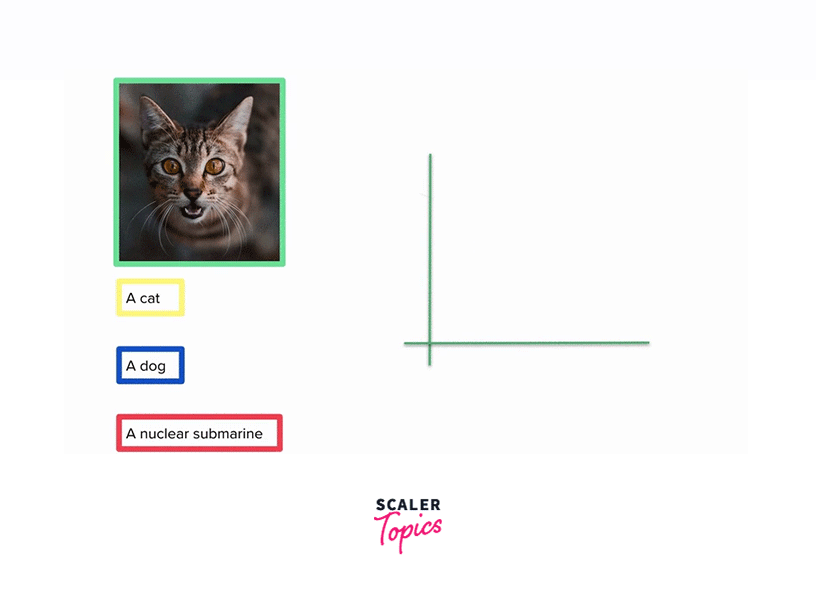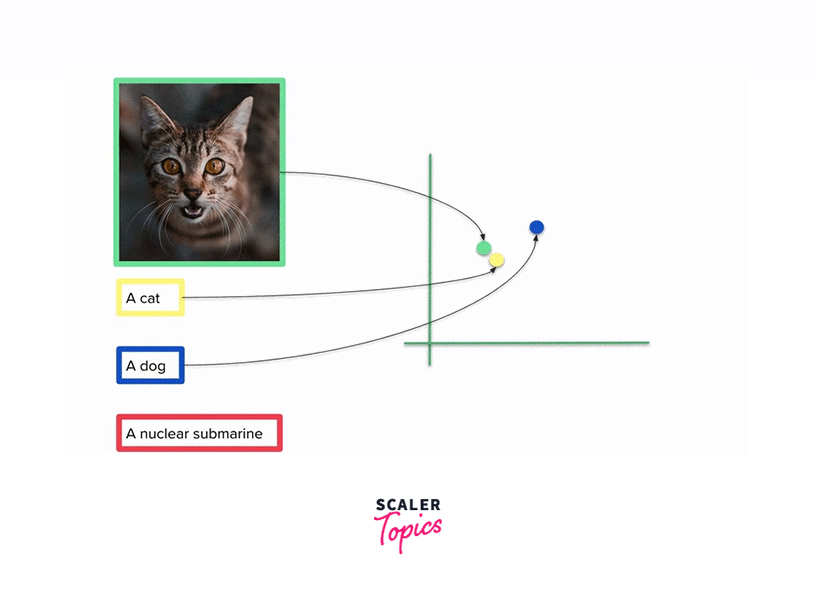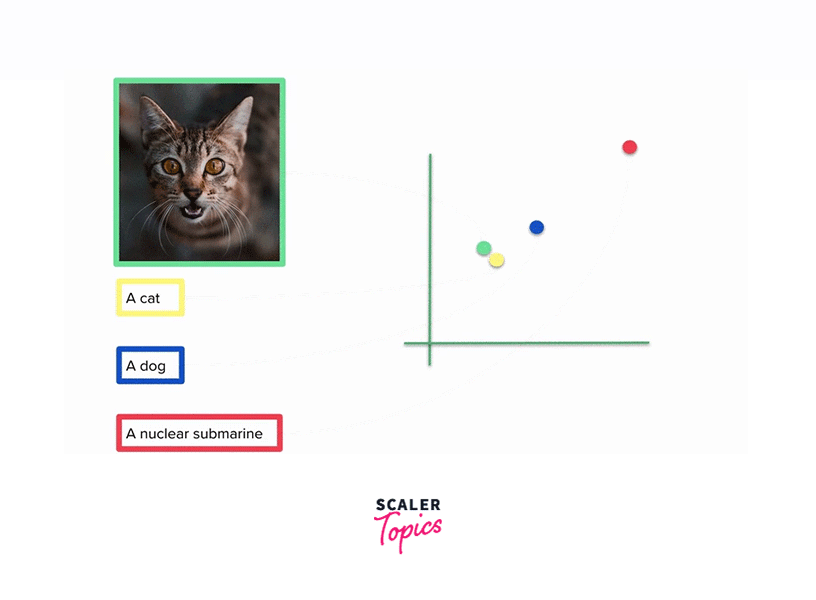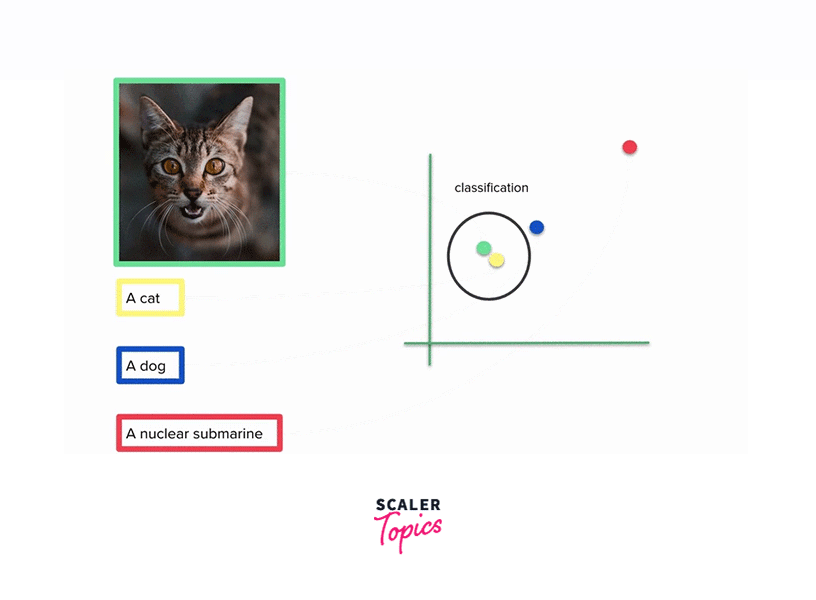
CLIP, short for "Contrastive Language-Image Pre-training," is one of the innovative deep learning openai models. Unlike traditional AI models specialising in processing text or images, CLIP has the unique capability to understand and link information between text and images. It can interpret language semantics in the context of visual data and vice versa.
![]()
Working:
What sets CLIP apart is its unique capability to understand and link information between text and images, allowing it to interpret language semantics in the context of visual data and vice versa.
Here's a deeper dive into how CLIP works:
-
Massive Dataset of Text and Images:
CLIP is trained on an extensive and diverse dataset containing pairs of textual descriptions and corresponding images. This dataset is collected from the internet and encompasses a wide range of textual content and visual imagery. It includes images and their associated textual descriptions from various sources, making it highly representative of the real-world relationship between language and images. -
Pre-training for Semantic Understanding:
During the pre-training phase, CLIP learns to associate textual descriptions with the visual content of images in a semantically meaningful way. This means that CLIP not only learns to recognize that certain words or phrases are related to specific objects or concepts in images, but it also grasps the nuances of how language can describe visual content.- Semantic Mapping:
CLIP develops a sophisticated understanding of the semantic relationships between words and their corresponding visual representations. For instance, it learns that the word "cat" is associated with images of cats, or that phrases like "blue sky" correspond to images featuring clear blue skies. - Cross-Modal Learning:
CLIP excels in cross-modal learning, which means it learns to map words and images into a common embedding space where the semantic relationships are preserved. In this shared space, similar textual descriptions and images are closer together, enabling CLIP to identify associations between text and images. CLIP's ability to understand and link information between text and images in a semantically meaningful way opens up a wide range of possibilities in fields such as computer vision, content generation, and natural language understanding.
- Semantic Mapping:
Applications/Use Cases:
- Image Captioning:
CLIP can generate descriptive captions for images, which is useful for accessibility, content indexing, and generating metadata for image datasets. - Zero-Shot Object Recognition:
CLIP can identify objects or concepts in images even if it hasn't been explicitly trained on those objects. This is particularly powerful for image classification tasks without needing a specific labeled dataset. - Text-to-Image Generation:
It can also generate images from textual descriptions, bridging the gap between natural language and visual content creation.
Drawbacks/Disadvantages:
- Computational Demands:
CLIP training can be computationally intensive, requiring substantial resources for training and deployment. - Data Bias:
Like many AI models, CLIP can reflect biases in its training data. This can result in biased or potentially problematic outputs. - Interpretability:
Understanding why CLIP makes specific predictions can be challenging due to the complex nature of deep learning openai models. This can hinder debugging and transparency.
DALL-E (Creating Images from Text)
DALL-E is one of the groundbreaking artificial intelligence OpenAI models. It is designed to generate images from texts, allowing users to create visual content simply by describing it in natural language. DALL-E is a fusion of natural language understanding and image generation, enabling various creative possibilities.

Working:
Its primary focus is on generating images rather than text. This specialization allows DALL-E to create visual content based on textual prompts, creating new possibilities for creative content generation. Here's a more detailed explanation of how DALL-E works:
- Architecture Similar to GPT-3:
DALL-E is built upon an architecture similar to that of GPT-3, which is based on the transformer architecture. This architecture excels in handling sequential data, making it well-suited for processing text and images. - Training on Text-Image Pairs:
DALL-E is trained on a vast and diverse dataset that includes pairs of textual descriptions and corresponding images. This dataset is carefully curated to contain various textual prompts and the images they describe. Combining text and image data enables DALL-E to understand the relationships between words and visuals.- Text-to-Image Association:
During training, DALL-E learns to associate textual descriptions with specific visual features and content. This association allows the model to comprehend how text corresponds to the visual elements it describes. For example, it learns that phrases like "a blue cat with wings" correspond to images of blue cats with wings. - Semantic Mapping:
DALL-E also captures semantic relationships between words and images. It understands the literal connections between words and visuals and the nuances of how different words and concepts can be visually represented.
- Text-to-Image Association:
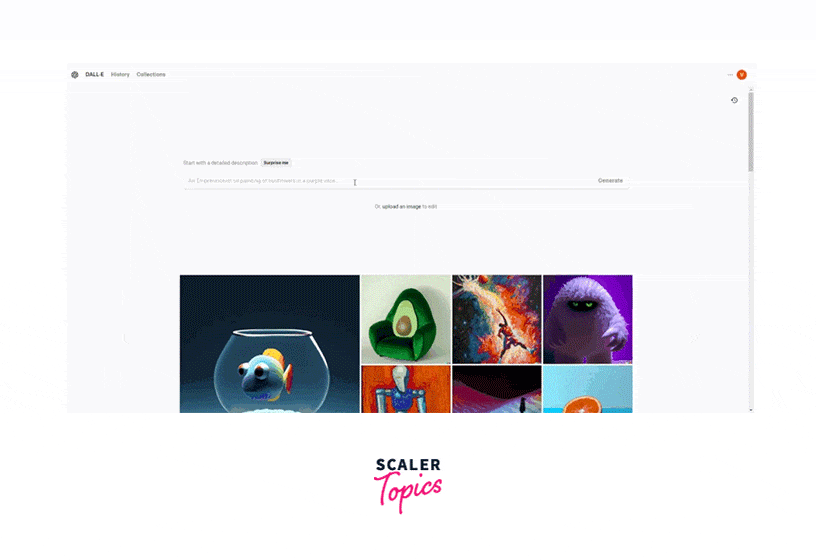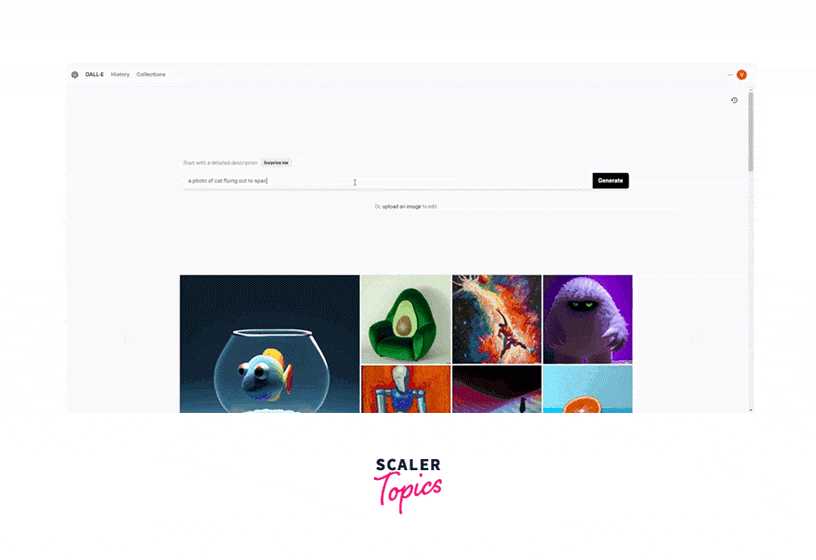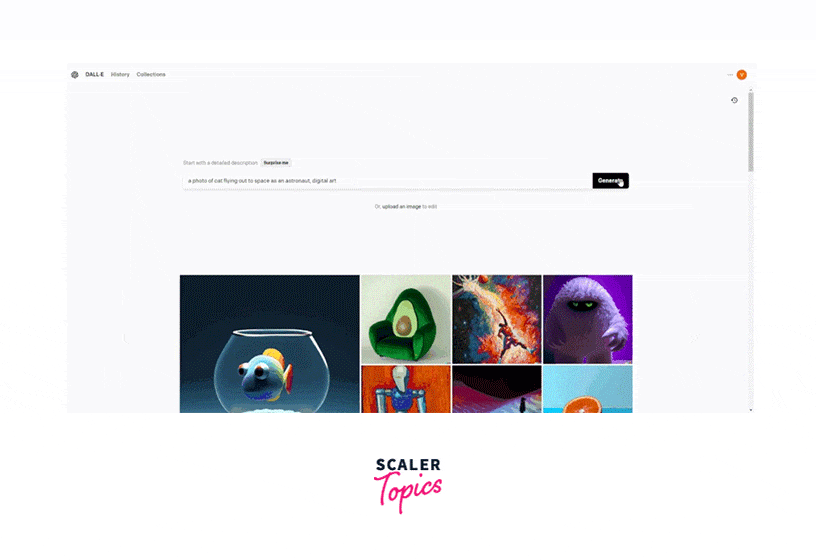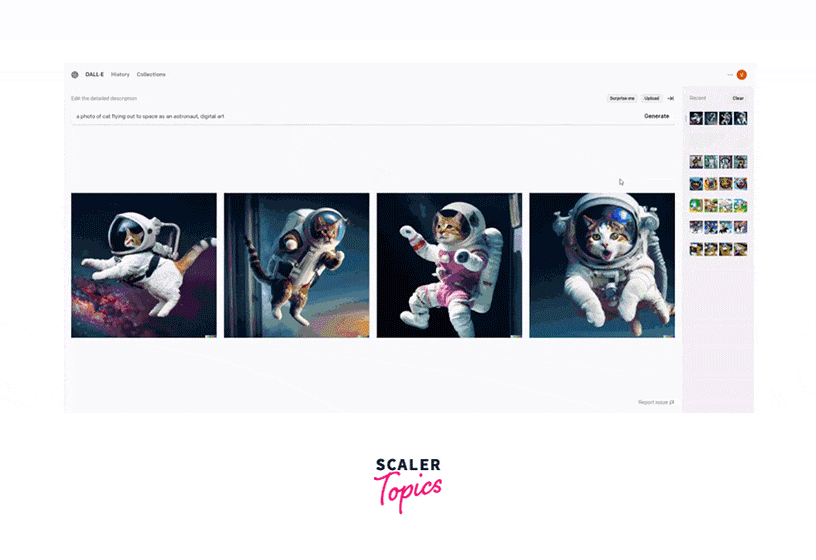
Applications/Use Cases:
- Creative Content Generation:
DALL-E can be used to create artwork, illustrations, and graphics based on textual descriptions. This is particularly useful for artists and designers looking for inspiration or quick visual prototypes. - Product Design:
It can assist in generating design concepts for products, interiors, fashion, and more by visualizing ideas described in text. - Storyboarding:
DALL-E can generate storyboards for film and animation projects based on script descriptions, helping in the pre-visualization of scenes.
Drawbacks/Disadvantages:
- Limited Realism:
While DALL-E can generate impressive and creative visuals, it may only sometimes produce highly realistic images. The quality of generated images may vary and may not match the fidelity of human-generated artwork. - Ambiguity in Textual Descriptions:
The accuracy of generated images depends on the clarity and specificity of the textual descriptions. Ambiguous or imprecise prompts can lead to unexpected results. - Ethical Considerations:
As with other AI models, DALL-E can potentially generate content that raises ethical concerns, such as generating inappropriate or harmful images if not used responsibly.
Conclusion
- OpenAI has developed a series of influential models, including GPT-1, GPT-2, and GPT-3, which have transformed natural language processing.
- Few-Shot, One-Shot, and Zero-Shot Learning in GPT-3 showcase its adaptability and generalization capabilities for various tasks.
- Codex is a specialized model designed for code generation and programming-related tasks, improving developer productivity.
- CLIP bridges the gap between language and vision, allowing models to understand and generate text and images in a semantically meaningful way.
- DALL-E is a creative model that generates images from textual descriptions, offering endless possibilities for artists, designers, and content creators.