Pre-training the BERT model
Overview
BERT, also known as Bidirectional Encoder Representations from Transformers, is an artificial intelligence (AI) approach to understanding natural language. It was created in 2018 by `Google AI Language researchers and acts as a multipurpose tool for over 11 of the most popular language tasks, including sentiment analysis and named entity recognition.
Introduction
BERT is a free and open-source machine learning framework for dealing with natural language` (NLP). BERT uses the surrounding text to provide the context to help computers understand the meaning of ambiguous words in the text. With the help of question-and-answer datasets, We can adjust the BERT framework after being pre-trained on text from Wikipedia.
BERT is a deep learning model that is based on Transformers. In Transformers, each output element is connected to each input element, and their weightings are dynamically determined based on their connection. This procedure is known as attention in NLP.
In the past, language models could only interpret text input sequentially — either from right to left or from left to right — but not simultaneously. BERT is unique since it can simultaneously read in both directions. Bidirectionality is the name for this capacity, which the invention of Transformers made possible.
What is BERT?
BERT is a deep learning model based on Transformers, which uses Transformer Encoders to learn text representations from unlabeled corpora. It is a particularly well-liked Transformer variant. For the model to learn from, they define a collection of pre-training tasks: Next Sentence Prediction (NSP) and Masked Language Modeling (MLM).
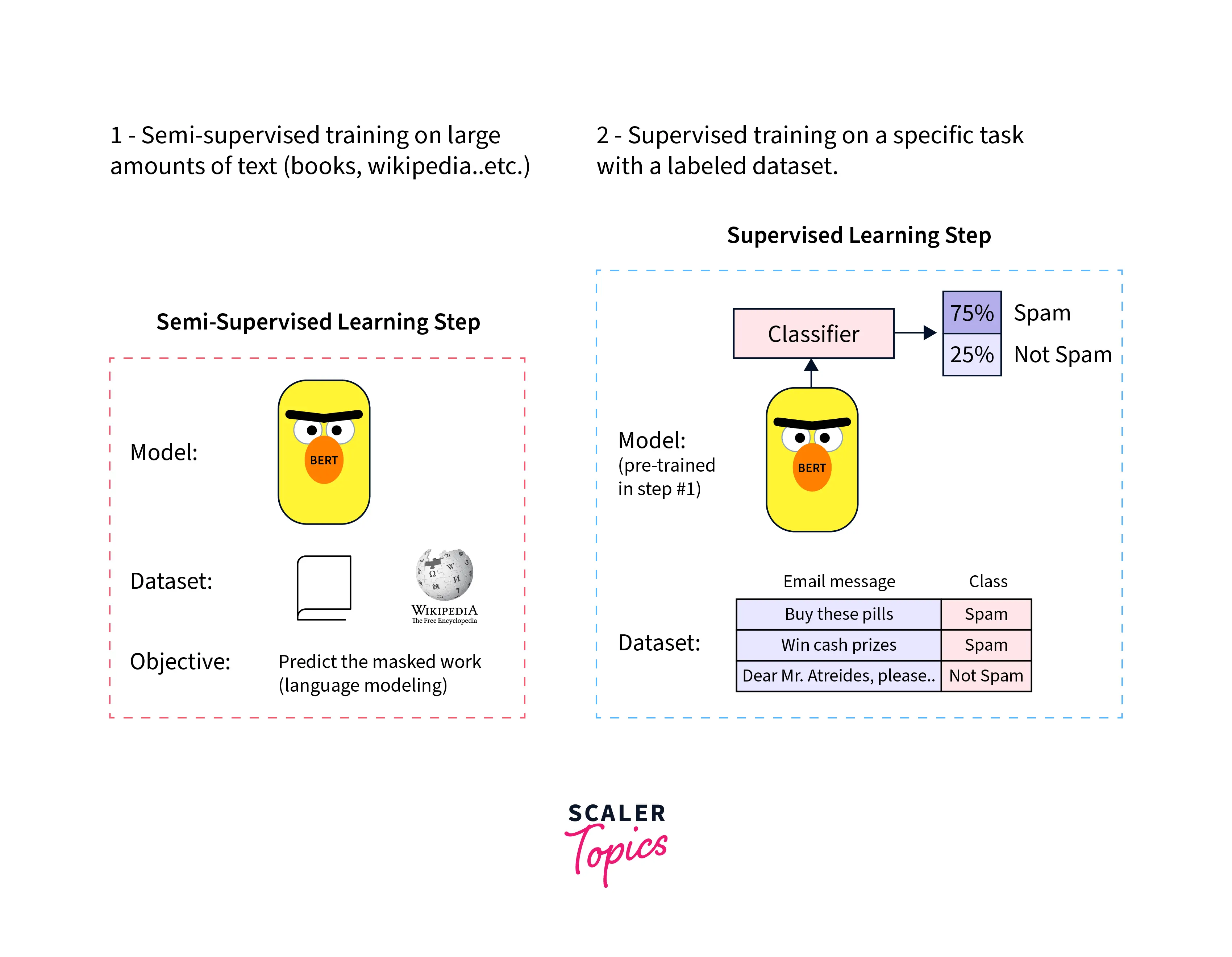
BERT uses Semi-Supervised Learning, which means it trains the model on a specific task where it learns the pattern and acquires the capability to process language, then used to empower other models to perform supervised learning.
Each BERT training sample consists of two sentences taken from a document. The document can have the two sentences together or not. The first sentence will have a [CLS] token prepended, and each subsequent sentence will have a [SEP] token (as a separator). That will then combine the two sentences to form a training sample by stringing them together as tokens. A small portion of the tokens in the training sample is either replaced with random tokens or masked with a unique token [MASK]. Its pre-training acts as a foundational layer of "knowledge" upon which to build. From there, BERT can be finetuned to a user's needs and adjusted to the ever-expanding body of searchable content and queries.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Two Steps of BERT
Pre-training Bert uses two steps to create a state of the art models for various tasks. They are:
- Pre-training
- Fine-tuning
After the pre-training Bert model, the model can adjust for a wide range of tasks that might not be identical to the task the model was trained on and still produce results that are close to state-of-the-art.
Once the pre-training Bert model is completed, We can fine-tune the model to perform a wide range of downstream tasks. A different model is designed for a certain downstream task. Therefore, a single pre-trained model can produce several downstream task-specific models after fine-tuning.
BERT Architecture
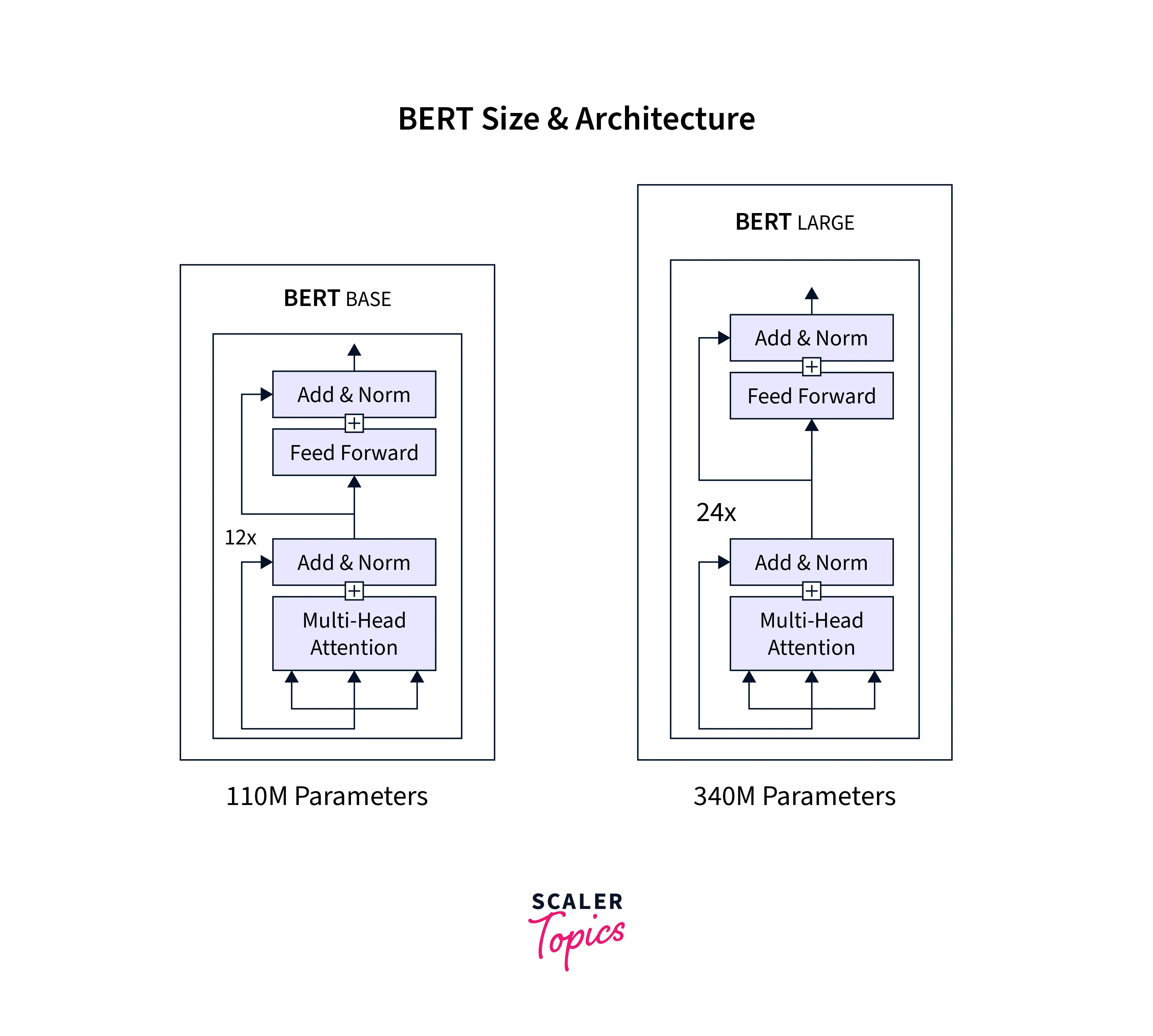
BERT was designed to achieve state-of-the-art accuracy in NLP tasks. It's a stack of the encoder of transformer architecture. In general, a transformer architecture consists of an encoder-decoder structure. BERT was released in two sizes, BERT^BASE and BERT^LARGE, in which the base model was used to compare the architecture's performance to another, and the large mode consists of the state-of-the-model.
Let's consider L = Number of layers, or the Number of encoder blocks for transforms in the stack. H – Hidden size (i.e. the size of q, k, and v vectors). A = Number of attention heads.
- BERT^base: L=12, H=768, A=12
- BERT^large: L=24, H=1024, A=16.
Pre-training BERT
The definition of a prediction target during language model training might take time. Models frequently predict the following word in a sequence (e.g., "The child arrived home from ___"), a directive approach that naturally restricts context learning. BERT employs two training techniques to overcome this obstacle:
Turn Learning into Career Growth
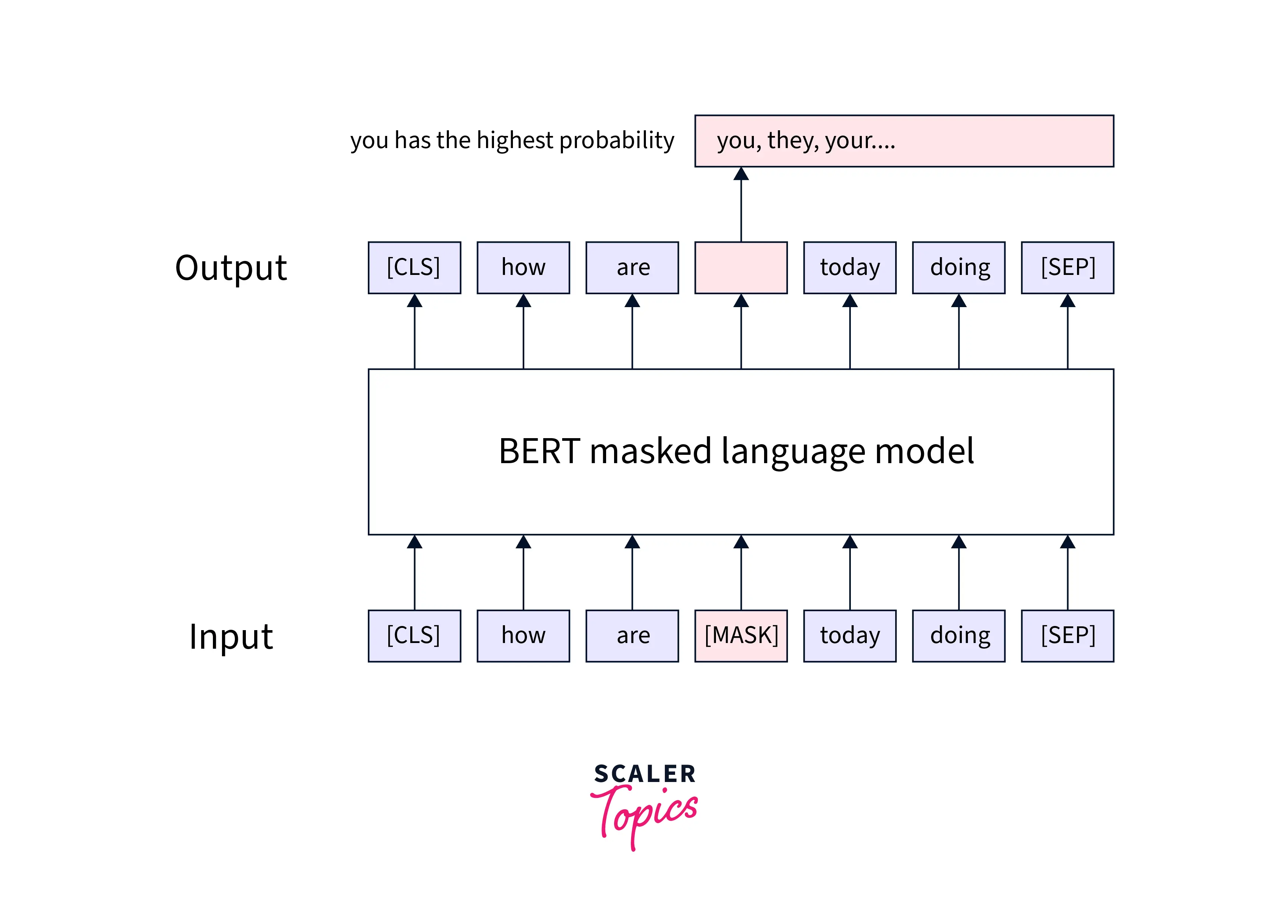
Masked Language Model (MLM)
From the word sequence, 15% of the words were masked ([MASK] tokens) before feeding the word into BERT. The model then predicts the original masked words based on the sequence's context of other unmasked words. For prediction, it requires to: The output of the encoder is added to a classification layer. The vocabulary dimension is created by dividing the output vectors by the embedding matrix. Use softmax to determine the likelihood of each word in the lexicon.
Next Sentence Prediction (NSP)
These models receive pairs of sentences and predict if the two sentences are subsequent. While training, 50% of the inputs are paired in which the second sentence is the next one in the original text, and in the remaining 50%, the second sentence is a randomly selected sentence from the corpus. The underlying assumption is that model does not connect the random phrase to the first.
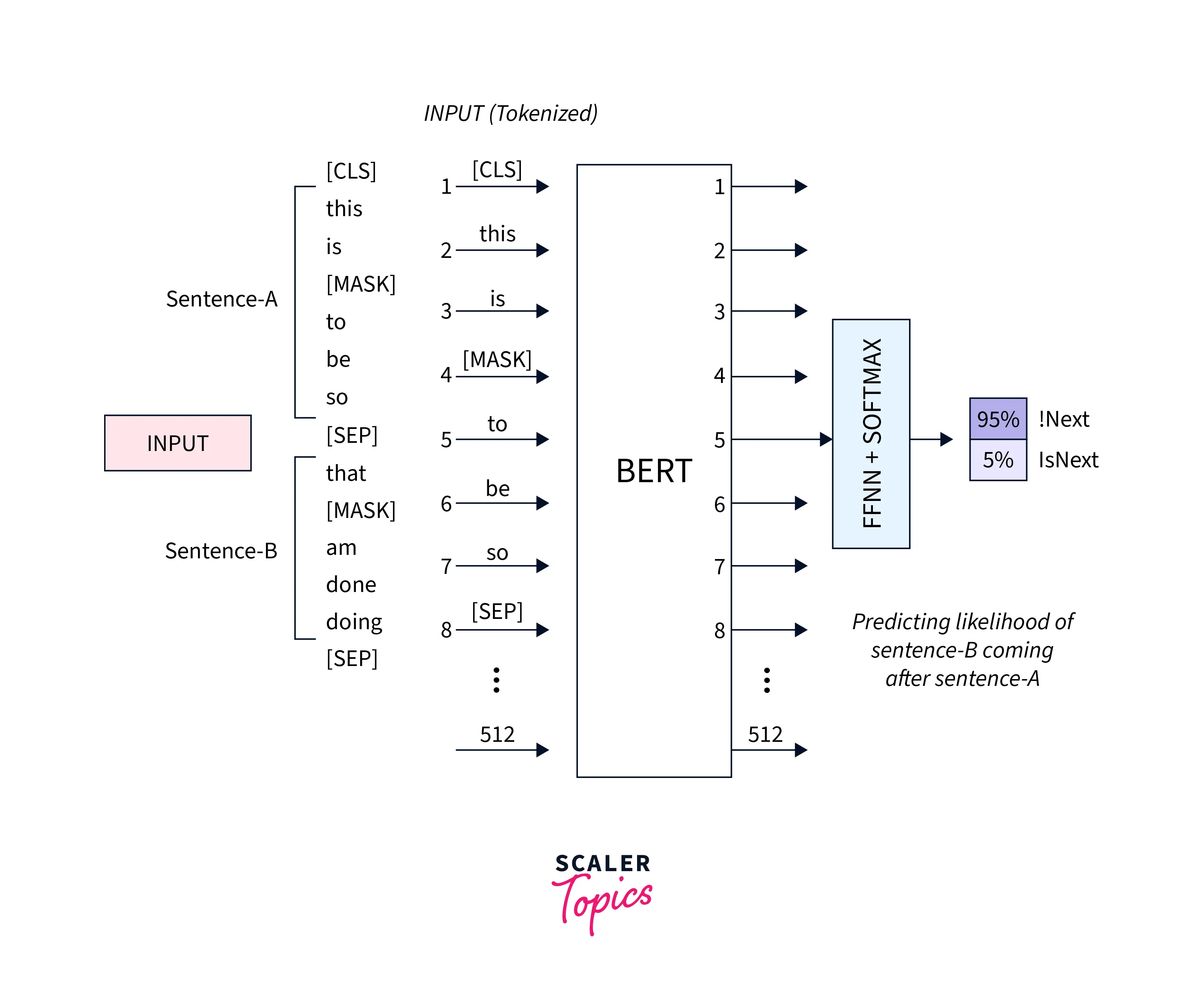
The inputs are processed before entering the model:
- The first sentence has a [CLS] token at the start, and each subsequent sentence has a [SEP] token at the end.
- Each token has a sentence embedding that designates Sentence A or Sentence B. `Token embeddings with a vocabulary of 2 and sentence embeddings share a similar notion.
- Each token receives a positional embedding to denote its place in the sequence.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Other pre-training Objectives
Researchers have recently discovered even more effective strategies for pre-training the BERT architecture to promote the learning of stronger textual representations. Other common pre-training strategies will be highlighted in the remaining sections of this article.
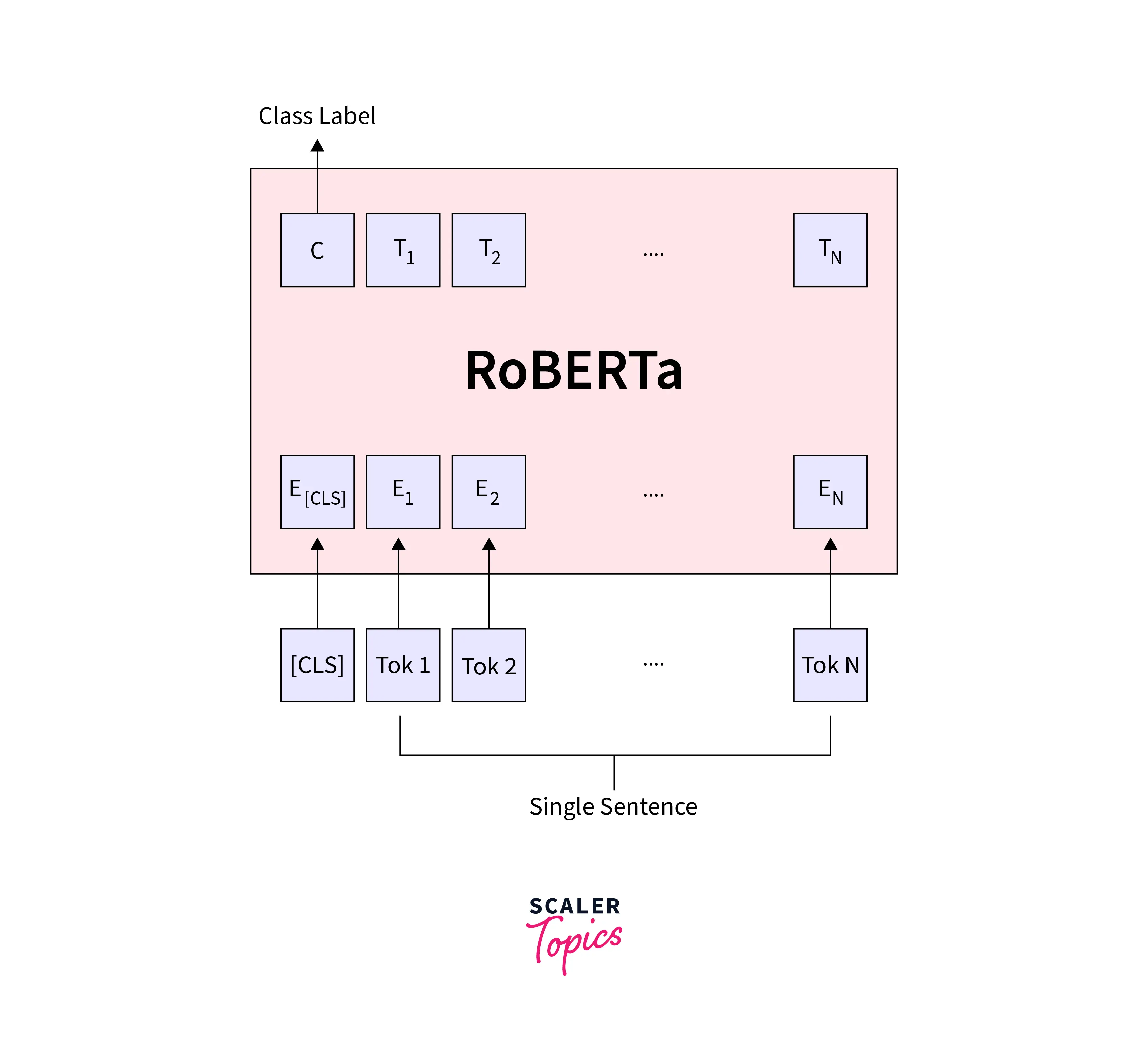
RoBERTa: A Robustly Optimized BERT(RoBERTa) Pretraining Approach is based on the 2018 BERT model from Google. By eliminating the next-sentence pretraining target, training with significantly bigger mini-batches, and changing critical hyperparameters, it improves upon BERT.
-
The author proposed a dynamic mask that masks the words in the sample every time it fed into the model. In the original BERT model, the mask that occurred was static, in which the model duplicated each sample 10 times, where each masked differently. Thus the model sees the same sample masked in 10 different ways over the training epochs. However, the dynamic mask method is more efficient since there is no need to duplicate the sample multiple times.
-
The NSP job utilized in BERT is essentially redundant, as demonstrated by Roberta, and its removal can enhance performance. Since the binary classification test asks, "sentences B which follows sentences A" or "not". BERT uses the loss from this categorization job to direct training.
BART In simple words, Bidirectional Auto-Regressive Transformers (BART) mean the addition of an autoregressive decoder such as GPT-2 to the BERT model. However, the model acquires more flexibility to attain the pretraining objectives.
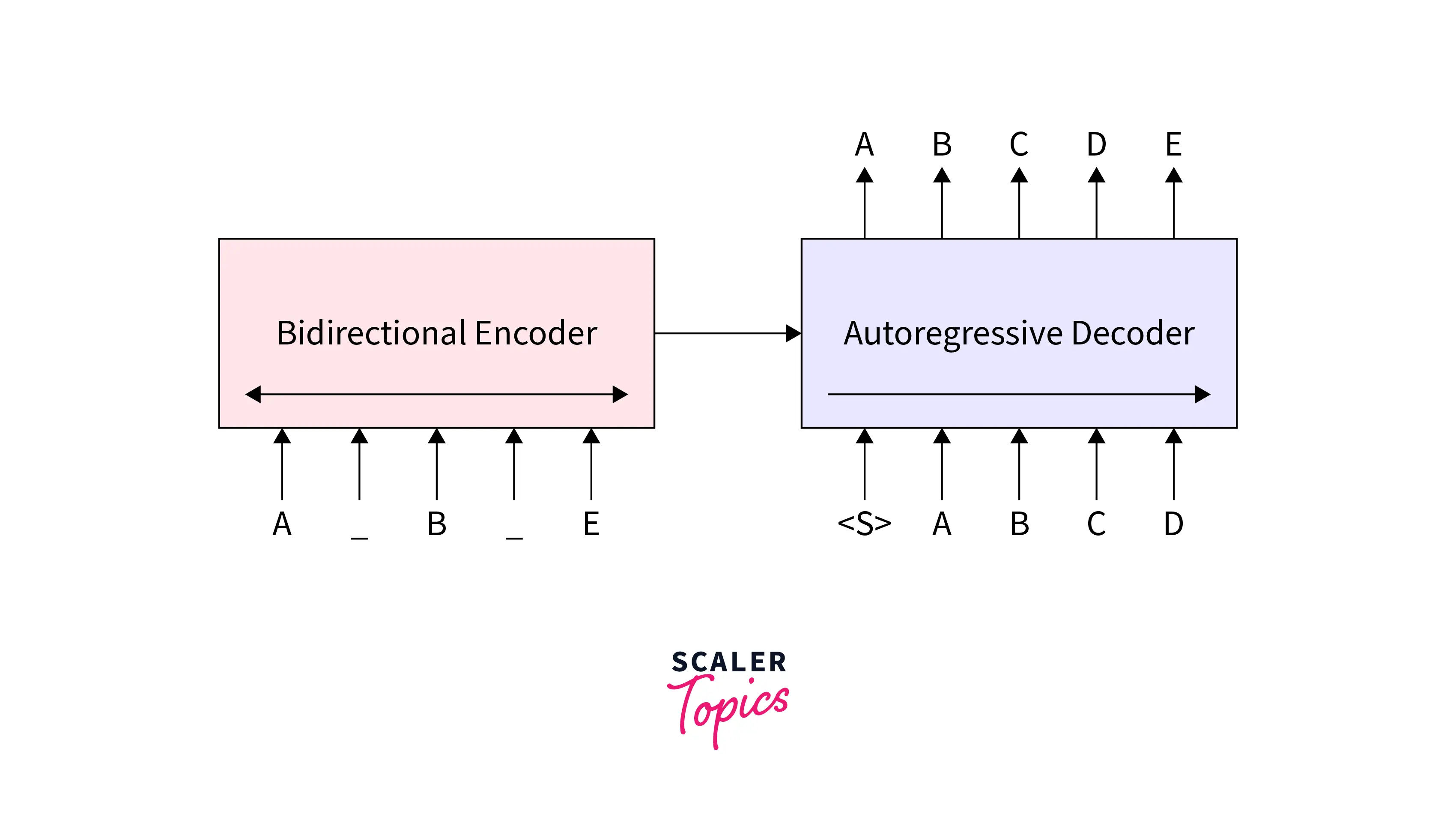
The model was trained as follows:
- Corrupted sentence in the input.
- Use BERT to encode it.
- Crack the output of the BERT
- Compare the decoded sentence to the original one. It is a sophisticated denoising auto-encoder, as you can see.
Text corruption strategies
BART decided to use both established and novel noise reduction techniques for pretraining. They employ Token Masking, Token Deletion, Text Infilling, Sentence Permutation, and Document Rotation as noise reduction techniques. Investigating each of these changes:
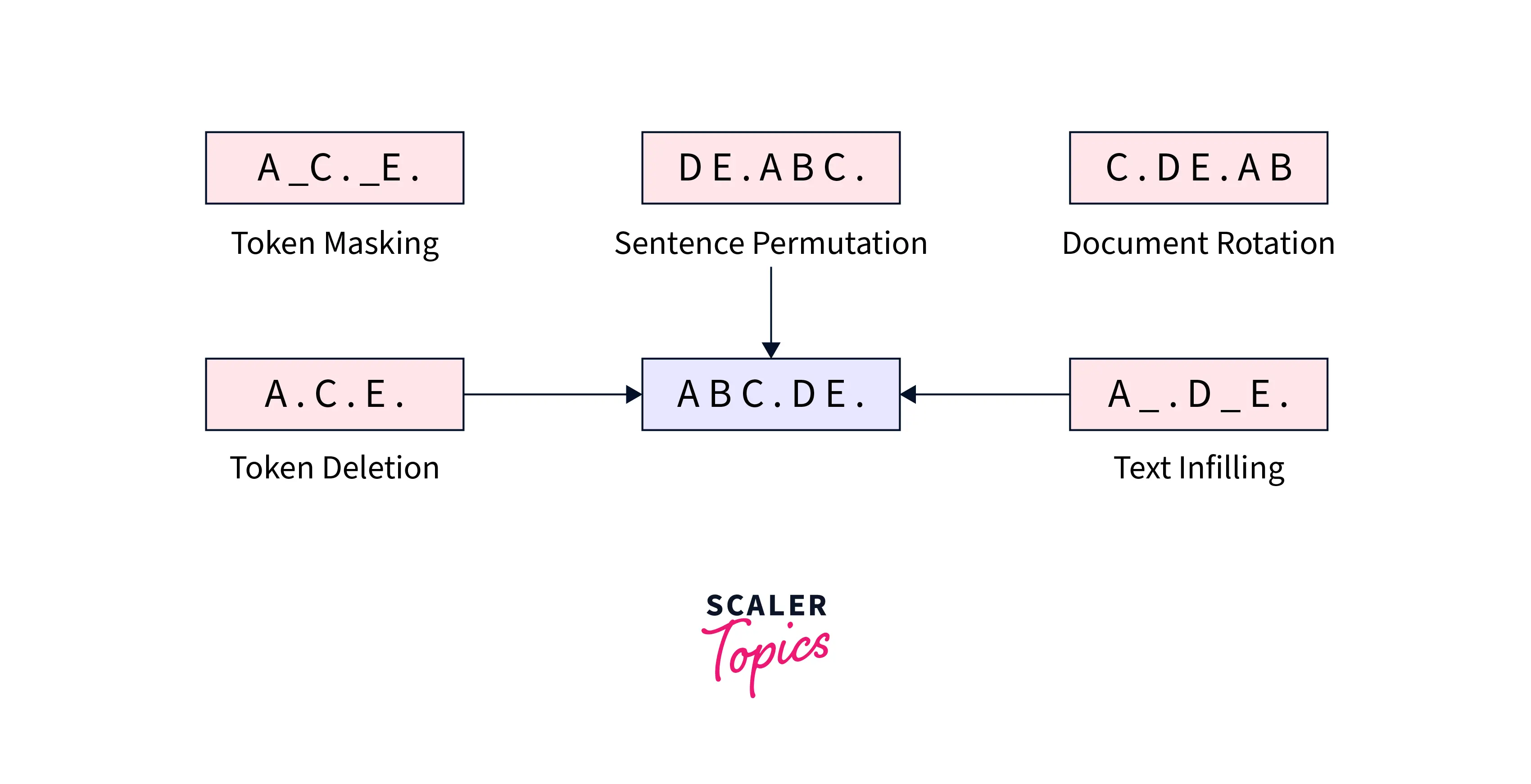
- Token Masking Token masking is the same as in BERT. In the BART model, a few tokens in the input were masked, and they tried to predict the missing words by the decoder.
- Token Deletion Randomly delete tokens in the input sentence. That forces the model not only to predict missing tokens but to predict where they are.
- Text Infilling Substitute a single mask token for each piece of the input sentence that needs to be deleted. The model is compelled to learn how many words [MASK] need to be broken down.
- Document Rotation Choose a token at random from the input, then rotate or wrap it so that it begins with the token you chose at random.
- Sentence Permutation The order of the document is changed, to begin with, a chosen token. The material that came before the token is added at the end of the document. That provides information on the general organization of the document as well as what a document's beginning or ending looks like.
Fine-tuning BERT
To fine-tune a pre-trained model such as BERT. We ensure that we use the same tokenization, vocabulary, and index mapping during training. We extend the pre-trained BERT with an additional output layer and then fine-tune the resulting model's entire set of parameters to train task-specific models. A benefit of adding input/output layers while leaving the BERT model alone is that fewer parameters must be learned from scratch, making the process quick, inexpensive, and resource-effective.
A start (S) and an end (E) vector are added during fine-tuning in Question Answering tasks. Sentence A represents the query, and sentence B represents the response. Dot products between Ti (the end state corresponding to the ith input token) and S (the start vector) are used to calculate the chance that word I will be the first word in the answer span, which is then multiplied by the softmax over the entire paragraph. For end span, a similar technique is employed.
The greatest scoring span where the prediction j >= i is employed defines a candidate's score for the range from position I to position j as STi + ETj.
Conclusion
- BERT is expected to significantly influence text-based and voice searches, which have historically'historically'historically been prone to errors when using Google's NLP methods.
- Its ability to comprehend context allows it to interpret shared patterns among languages without needing to fully comprehend them, which is projected to enhance international SEO significantly.
- There are numerous BERT variations available, which are being refined by numerous other companies, academic institutions, and divisions of Google through supervised training to increase its efficiency.