spaCy’s Processing Pipeline
Overview
The processing pipeline spaCy first starts by converting our input text into a series of tokens (called the Doc object) and then performing several operations on the Doc object. A typical spaCy-trained pipeline consists of various stages like tokenizer, tagger, lemmatizer, parser, and entity recognizer. In each stage of the pipeline, the input is the Doc object and the output is the processed Doc, so, each stage makes some kind of respective change to the Doc object and feeds it to the subsequent stage of the pipeline. The spaCy library has some predefined trained pipelines for several languages. These packages differ in speed, size, memory usage, data used in them, and accuracy.
Introduction
Before learning about how the processing pipeline spaCy works, let us first learn some basics about the NLP itself and the spaCy library.
NLP stands for Natural Language Processing. In NLP, we perform the analysis and synthesis of the input, and the trained NLP model then predicts the necessary output. NLP is the backbone of technologies like Artificial Intelligence and Deep Learning. In basic terms, we can say that NLP is nothing but the computer program's ability to process and understand the provided human language.
Python provides us with a lot of libraries and modules. It helps us understand and work with large data sets. SpaCy is one of the open-source libraries of Python programming language that is written in Cython (C programming language + Python programming language). The main work of spaCy is to process the data used in the NLP applications. It simply helps us to convert our instruction into machine-understandable instruction.
Now before working with the processing pipeline spaCy, we must install the spaCy library into our local environment using the pip install command:
Pipelining in the spaCy can be seen as the series of processes that a text has to go through in the NLP process. The process first starts by converting our input text into a series of tokens (called the Doc object) and then performing several operations on the Doc object such as lemmatization, parsing, etc.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
What is a Processing Pipeline?
The processing of our text (which is termed as Doc in the spaCy library) is done in various incremental stages. These incremental stages are known as the processing pipeline spaCy. So, whenever we provide the input text to the NLP, the spaCy library first tokenizes it (converts the text into tokens), and then it is converted into an object called Doc.
A typical spaCy trained pipeline consists of stages like: tokenizer, tagger, lemmatizer, parser, and entity recognizer. In every stage of the pipeline, the input is the Doc object and the output is the processed Doc, so, every stage makes some kind of respective change to the Doc object and feeds it to the subsequent stage of the pipeline. The overview of a typical spaCy pipeline is depicted in the below diagram.
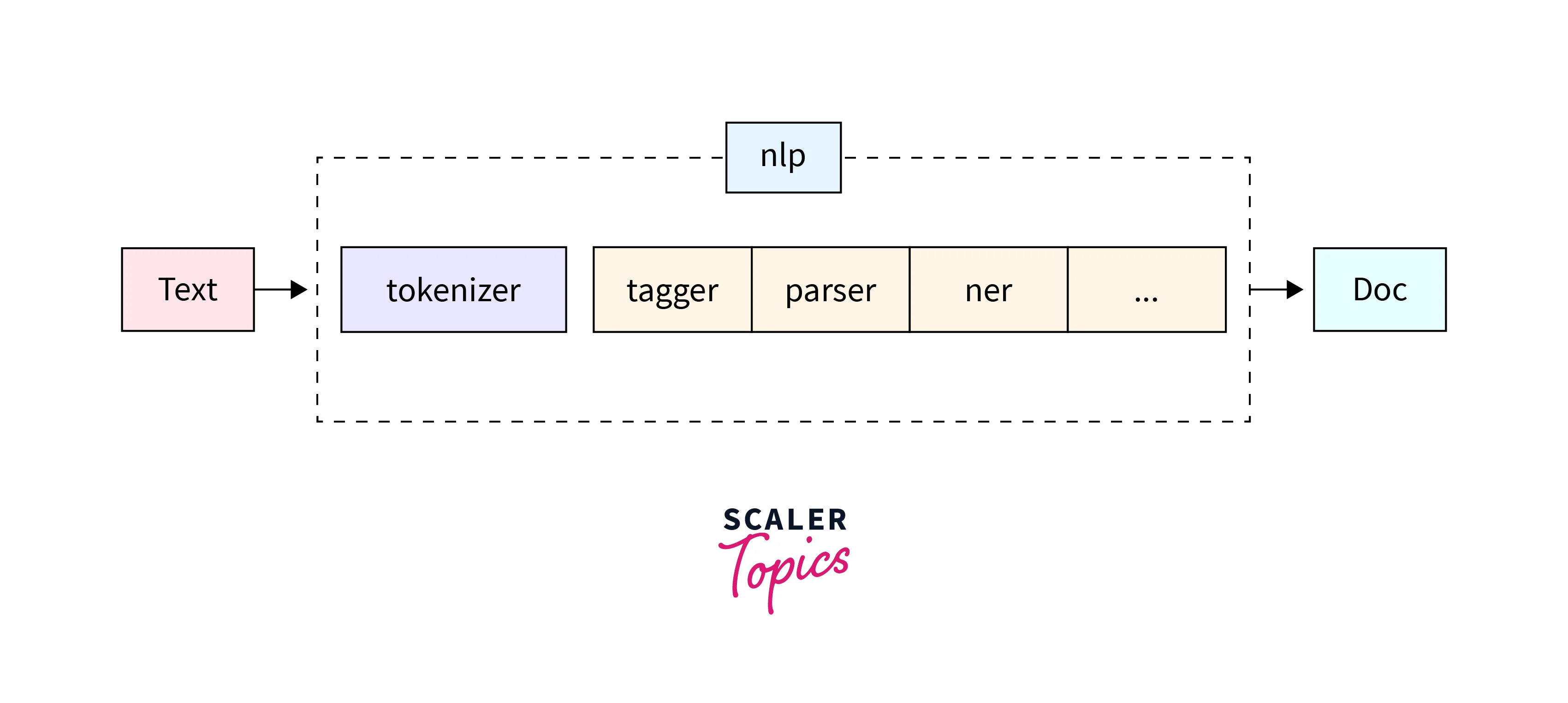
SpaCy’s Processing Pipeline
As we have previously discussed, the spaCy pipeline uses the stages to convert the user input text into a machine-understandable Doc object. The spaCy library has some predefined trained pipelines for several languages. These packages differ in speed, size, memory usage, data used in them, and accuracy. The spaCy library calls the nlp() function with our provided text as its argument.
Before learning about the components involved in the spaCy pipeline, let us first know why we are using the spaCy pipeline for the same.
So, some of the most important features that the spaCy library provides us are Text Classification, and Named Entity Recognition. What are Text Classification and Named Entity Recognition, and how do they play an important role in a spaCy pipeline? Well, Text classification is one of the most important aspects of the spaCy pipeline as it deals with classifying the text into various categories. , For example,, words like Donald Trump and Boris Johnson would be categorized into politics. People like LeBron James and Ronaldo would be categorized into sports. After that, we perform the labeling of the texts or a part of the text. The Named entity recognition is another feature of the spaCy library pipeline that is used to extract the entities from the text document. The extracted entities are then named according to the objects of the real world so that the processing can become easier. Some examples of named entity recognition are location, people, organization, etc.
Let us now learn about the various components involved in spaCy's processing pipeline system.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Components & Description
The spaCy library has several built-in components that perform the task of data processing when we invoke the nlp() function. The components are modifiable according to the text and use case. The components involved in the processing pipeline spaCy are:
- tokenizer: The tokenizer component is the first component that creates the Doc object out of the provided text, and its main work is to convert the large text into segments and then convert them into the form of tokens.
- tagger: The tagger component is the next step in the spaCy pipelining system and it assigns the parts-of-speech tag to the tokens. The tagger component takes the Doc object as input and creates a Token. tag.
- parser: As the name suggests, the parser component parses the tagged tokens and then assigns the dependency labels on them. Some of the examples of the dependency tokens are: Token.head, Token.dep, Doc.sents, Doc.noun_chunks, etc.
- ner: The ner component is used for entity recognition (extracting the entities from the text document). This component detects the labelled tokens and then assigns the label-named entities. Some examples of entity tokens are: Doc.ents, Token.ent_iob, Token.ent_type, etc.
- lemmatizer: The lemmatizer component assigns the base form to the labelled tokens. It takes the tokens and creates the Token. lemma tag to the tokens.
- text : The text or the TextCategorizer component is used to assign the document label to the input tokens. This component creates the Doc. cats label on the tokens.
- entity_linker: This component is used to assign the knowledge base ID to the named entity. This is the next component that works after the entity recognizer i.e. ner.
- entity_ruler: This component is used to assign name bases entities according to the prescribed pattern, rules, and dictionaries.
- textcat_multilabel: This component is used to categorize the text-based categories and multi-label settings. For example, a token may have one or more labels as per the document.
- morphologies : As the name suggests, the morphologies component is used to assign the POS tags (coarse-grained), and the morphological features.
- attribute_ruler: This component is used to assign the attribute-specific mapping and some rule-based exceptions.
- centre : The centre component is used to assign the sentence boundaries to the tokens.
- sentence : This component is used to add some rule-based sentence segmentation that does not have any dependency on the parser.
- tok2vec: This component is used to assign or embed the token-to-vector.
- custom: The custom component of the processing pipeline spaCy lets us assign the custom attribute tags, methods, and properties to the tokenized texts. This component creates the Doc._.xxx, Token._.xxx, Span._.xxx, etc. tags to the tokens.
What Happens When You Call nlp()?
The working of the processing pipelines and their capabilities primarily depends on the properties like:
- models used,
- the components involved, and
- how the training of the model has been done.
Now, the very first step of the text conversion takes place when we call the nlp() function of the spaCy library with the input text as its parameter. The nlp() function converts the parameterized text into tokens (and this process is known as tokenization), and then it calls each of the components on the converted object Doc. Here, the order of the components being called is discussed in the previous subsection.
The output of the returned value of the nlp() function is the processed Doc object. Even if our input text is pretty huge, the spaCy library works very efficiently and used the nlp. pipe method and takes the iterable text, and then yields us the processed Doc object in batches. This batching operation is done internally by the spaCy library.
For example, if we want to process the text Hey Scaler Topics!, we can use the nlp() function as:
Once the code is executed, the DocObject is returned and it will have the tokenized text of the input.
Pipeline Attributes
Let us now learn about the pipeline attributes of the spaCy pipelining system.
- nlp.pipe_names: The nlp.pipe_names attribute shows us the list of names of the pipeline components.
- nlp. pipeline: The nlp. pipeline attribute returns us the list of tuples of names and components.
Let us take an example to understand the attributes better.
Output:
Custom Pipeline Components
We have previously discussed all the predefined components provided by the processing pipeline spaCy. We can also create custom components or functions and add them so that they can also get executed after we call the nlp object on the provided text.
A question that comes to our mind is - Why do we need the custom pipeline components if spaCy provided us with so many built-in components? The answer to the question is: The custom component helps us to add some metadata of our own choice to the documents and the tokens. We can even use it to update the already present built-in attributes such as doc. ents.
Some of the major reasons for adding custom pipeline components are:
- It will automatically invoke the defined custom attribute or function when the nlp is invoked.
- To add some metadata of our own choice to the documents and the tokens.
- To update the already present built-in attributes such as doc. ents.
Turn Learning into Career Growth
Anatomy of a Component
If we want to add any custom component to the ongoing pipeline, we can use the nlp.add_pipe() method to do so. We need to provide the component that we want to add as the first parameter to the function. We can also provide the optional argument to specify the component's position. The values of the optional positional argument can be:
- last: After the addition of the last positional argument, the function becomes: nlp.add_pipe(component-name, last=True), and once the function is executed, it will add the custom component to the ending of the component list.
- first: After the addition of the first positional argument, the function becomes: nlp.add_pipe(component-name, first=True), and once the function is executed, it will add the custom component to the starting of the component list.
- before: After the addition of the before positional argument, the function becomes: nlp.add_pipe(component-name, before=True), and once the function is executed, it will add the custom component before the invoked component.
- after: After the addition of the after positional argument, the function becomes: nlp.add_pipe(component-name, after=True), and once the function is executed, it will add the custom component after the invoked component.
Example of a Component
Let us add a custom component to understand the working better.
Output:
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Extension Attributes
Let us now learn how to deal with the extended attributes used in the processing pipeline spaCy.
Setting Custom Attributes
We can add the metadata or the custom attributes to the Doc, Span, and Token objects. The ._ property contains the custom attributes so that they can be easily distinguished from the built-in attributes. We need to register the attributes to the Doc, Token, or the Span classes with the help of the set_extension method.
The extension attribute is of three types namely- Attribute extensions, Property extensions, and Method extensions. Let us learn about them.
Attribute Extensions
The attribute extension is used to set an over-writeable default value.
For example, if we have first set an attribute with a default value of True then we can change it to False.
Example:
Property Extensions
The property extension is similar to the properties concept of Python programming language. We can even define a getter as well as optional setter functions. One thing to note here is that the getter function is only called when we are retrieving the attribute value.
Examples of getters and setters:
Code:
Output:
Refer to the image provided below to get an idea about getters and setters in Python.
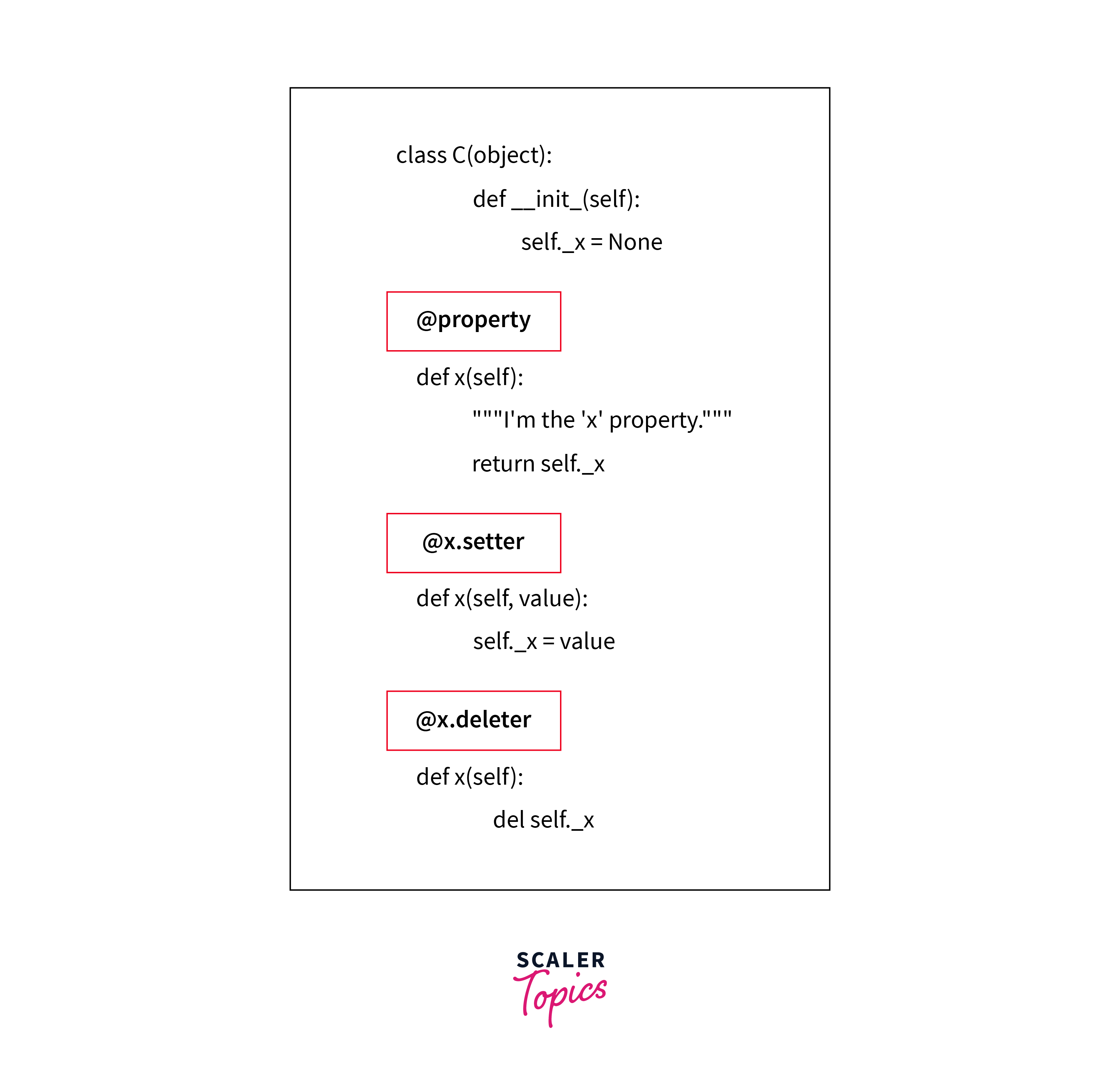
Example of property extension:
Code:
Output:
Method extensions
The method extension is used to make the extension attributes callable method. In Python, when a subclass defines a function that already exists in its superclass to add some other functionality in its way, the function in the subclass is said to be an extended method and the mechanism is known as extending. Let us take an example to understand how method extension works in Python.
Example:
Code:
Output:
Scaling and Performance
Many times in NLP, we need to work on large-scale data, so the processing of the large data set in a faster and more effective way is also necessary. If the pipelining process is faster, then the resultant output is also achieved faster.
The spaCy library also makes sure that the processing of large volumes of data is done efficiently. Now, to process large data sets, we use the nlp. pipe function. This function processes the provided text as streams of input text and thus yields the Doc objects.
The nlp.pipe() function can be called as:
In the above example, we provided a large volume of input to the nlp. pipe() function, and then the returned Doc object is converted into a list.
This process is much faster than calling the nlp() function on each text of the input data set. We can also alternatively use the below method but it is much much slower and not recommended.
Example:
Code:
Output:
For passing the context, we have two ways: Option 1: Firstly we first need to update the setting and set the as_tuples attribute to True as: as_tuples = True. Apart from this, we need to pass (text, context) as tuples in the nlp. pipe() method.
The function will now yield the tuples of the form: (doc, context). Alternatively, we can also make the changes in the set_extension method or by only using the tokenizer.
FAQs
Let us now look at some of the most frequently asked questions related to the processing pipeline spaCy.
Q: Does the Order of Components in the Pipeline Matter?
A: As we have discussed earlier that the components work one after the other, but in real scenarios, we have some statistical components such as tagger or parser. These components are independent of each other and do not share any data between them.
The components may work after one another, but the actual sequence does not matter. So, we can swap the components or remove one from the pipelining process. The components can, however, share the token-to-vector. If we create a custom component, then the custom component may be dependent on the other annotations set by the other components.
Q: Why is the Tokenizer Special?
A: The tokenizer is one of the most useful and special components involved in the entire pipelining process. The tokenizer component does not come in the nlp.pipe_names but its work is very important.
Example:
Code:
Output:
All the components use the Doc object but this Doc object is generated from the input text by the tokenizer. Hence, it is very important. It is the first thing that should be done to execute the entire pipelining process.
The input to the tokenizer is the string of text and it returns a Doc object after converting the text into tokens. The tokenizer component is built-in but we can also customize it according to the use case. We can even create the whole tokenizer component from scratch or even develop a custom function to work as a tokenizer.
Conclusion
- The processing pipeline spaCy first starts by converting our input text into a series of tokens (called on the Doc object) and then performing several operations on the Doc object.
- A typical spaCy-trained pipeline consists of stages like a tokenizer, tagger, lemmatizer, parser, and entity recognizer.
- The tokenizer is one of the most useful and special components involved in the entire pipelining process. The tokenizer component does not come in the nlp.pipe_names but its work is very important.
- The spaCy library has some predefined trained pipelines for several languages. These packages differ in speed, size, memory usage, data used in them, and accuracy.
- Text classification is one of the most important aspects of the spaCy pipelining as it deals with classifying the text into various categories and then labelling the texts or a part of the text.
- The Named entity recognition is another feature of the spaCy library pipeline that is used to extract the entities from the text document. The extracted entities are then named according to the objects of the real world so that the processing can become easier.
- The custom component helps us to add some metadata of our own choice to the documents and the tokens. We can even use it to update the already present built-in attributes such as doc. ents.
- The spaCy library also takes care that the processing of large volumes of data is done efficiently. So, to process large data sets, we use the nlp. pipe function.